xtts2 ui
1.0.0
Этот репозиторий содержит основной код для клонирования любого голоса, используя только текст и 10-секундную аудиобрацию целевого голоса. XTTS-2-UI прост в настройке и использовании. Пример результатов?
Работает на 16 языках и имеет встроенную голосовую запись/загрузку. Примечание: не ожидайте качества EL, его еще нет.
Используемая модель- tts_models/multilingual/multi-dataset/xtts_v2 . Для получения более подробной информации обратитесь к обнимающему лицу-XTTS-V2 и его конкретной версии XTTS-V2 версии 2.0.2.
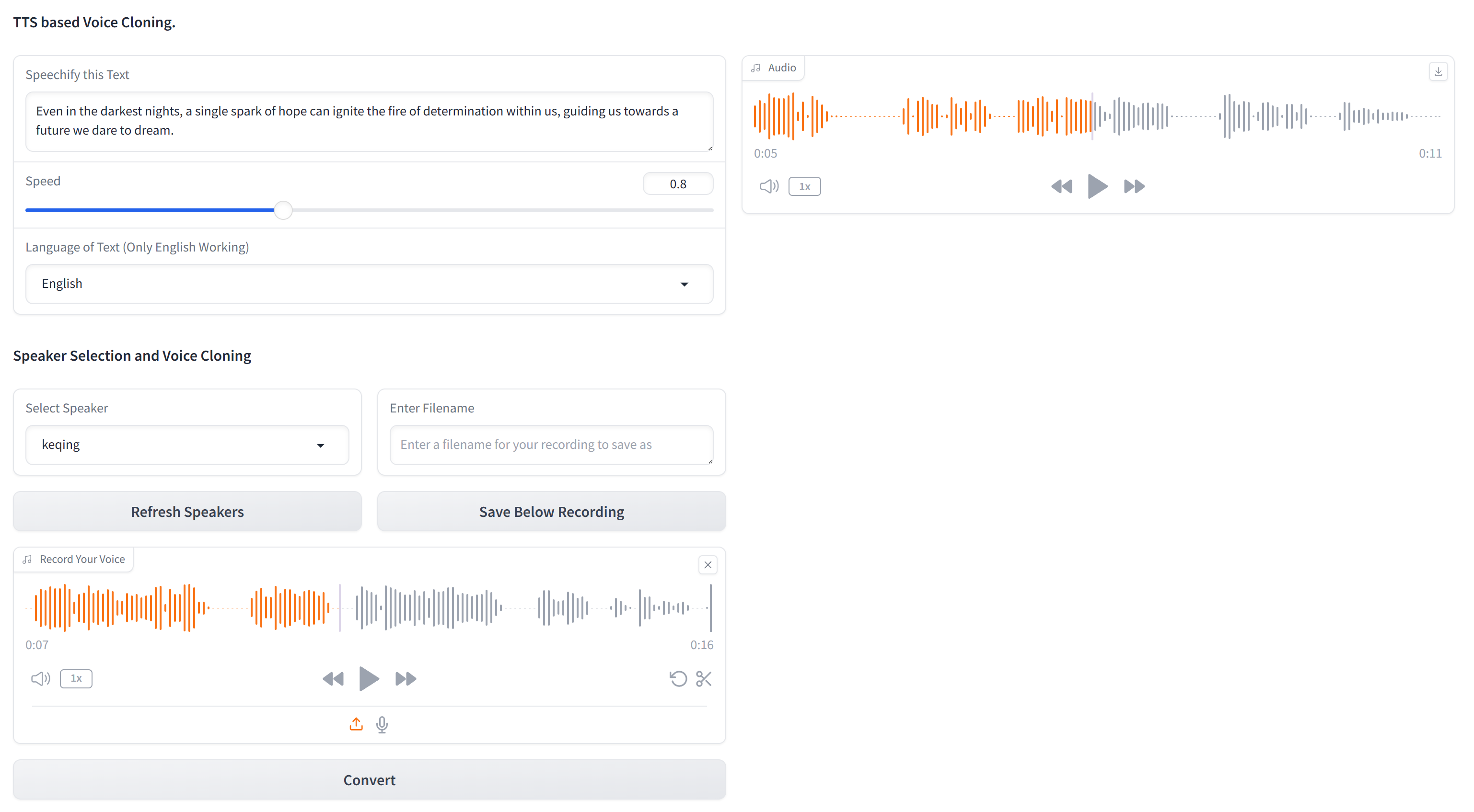
Чтобы настроить этот проект, следуйте этим шагам в терминале:
Клонировать репозиторий
git clone https://github.com/pbanuru/xtts2-ui.git
cd xtts2-uiСоздайте виртуальную среду:
python -m venv venvWindows:
# cmd prompt
venv S cripts a ctivateили
# git bash
source venv/Scripts/activateLinux/Mac:
source venv/bin/activateУстановите Pytorch:
nvcc --versionpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Установите другие необходимые пакеты:
pip install -r requirements.txtpip install --upgrade TTSПосле завершения этих шагов ваша настройка должна быть завершена, и вы можете начать использовать проект.
Модели будут загружены автоматически при первом использовании.
Скачать пути:
/Users/USR/Library/Application Support/tts/tts_models--multilingual--multi-dataset--xtts_v2C:Users YOUR-USER-ACCOUNT AppDataLocalttstts_models--multilingual--multi-dataset--xtts_v2/home/${USER}/.local/share/tts/tts_models--multilingual--multi-dataset--xtts_v2 home/$, useer )/.local/share/tts/tts_models-multingual ---multi-dataset-xtts_v2 Чтобы запустить приложение:
python app.py
OR
streamlit run app2.py
Или вы также можете работать от самого терминала, предоставив образцы входных текстов на текстах.
python appTerminal.py
При первоначальном использовании вам нужно будет согласиться с условиями:
[XTTS] Loading XTTS...
> tts_models/multilingual/multi-dataset/xtts_v2 has been updated, clearing model cache...
> You must agree to the terms of service to use this model.
| > Please see the terms of service at https://coqui.ai/cpml.txt
| > "I have read, understood and agreed to the Terms and Conditions." - [y/n]
| | >
Если ваша модель повторно загружает каждый запуск, обратитесь к выпуску 4723 на GitHub.
Набор данных состоит из одной папки с названием targets , предварительно заполненных несколькими голосами для целей тестирования.
Чтобы добавить больше голосов (если вы не хотите проходить GUI), создайте файл WAV 24 кГц приблизительно 10 секунд и поместите его под папку targets . Вы можете использовать YT-DLP для загрузки голоса с YouTube для клонирования:
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?"
| Язык | Ссылка на аудио |
|---|---|
| Английский | |
| Русский | |
| арабский |
Арабский, китайский, чешский, голландский, английский, французский, немецкий, венгерский, итальянский, японский (см. Установка), корейский, польский, португальский, русский, испанский, турецкий
Если вы хотите выбрать японский язык в качестве целевого языка, вы должны установить словарь.
# Lite version
pip install fugashi[unidic-lite]или для более серьезной обработки:
# Full version
pip install fugashi[unidic]
python -m unidic downloadПодробнее здесь.


