xtts2 ui
1.0.0
이 저장소에는 텍스트 만 사용하여 모든 음성을 복제하기위한 필수 코드와 Target Voice의 10 초 오디오 샘플이 포함되어 있습니다. XTTS-2-UI는 설정 및 사용이 간단합니다. 예제 결과?
16 개 언어로 작동하며 음성 녹음/업로드가 내장되어 있습니다. 참고 : EL 레벨 품질을 기대하지 마십시오. 아직 없습니다.
사용 된 모델은 tts_models/multilingual/multi-dataset/xtts_v2 입니다. 자세한 내용은 Hugging Face-XTTS-V2 및 특정 버전 XTTS-V2 버전 2.0.2를 참조하십시오.
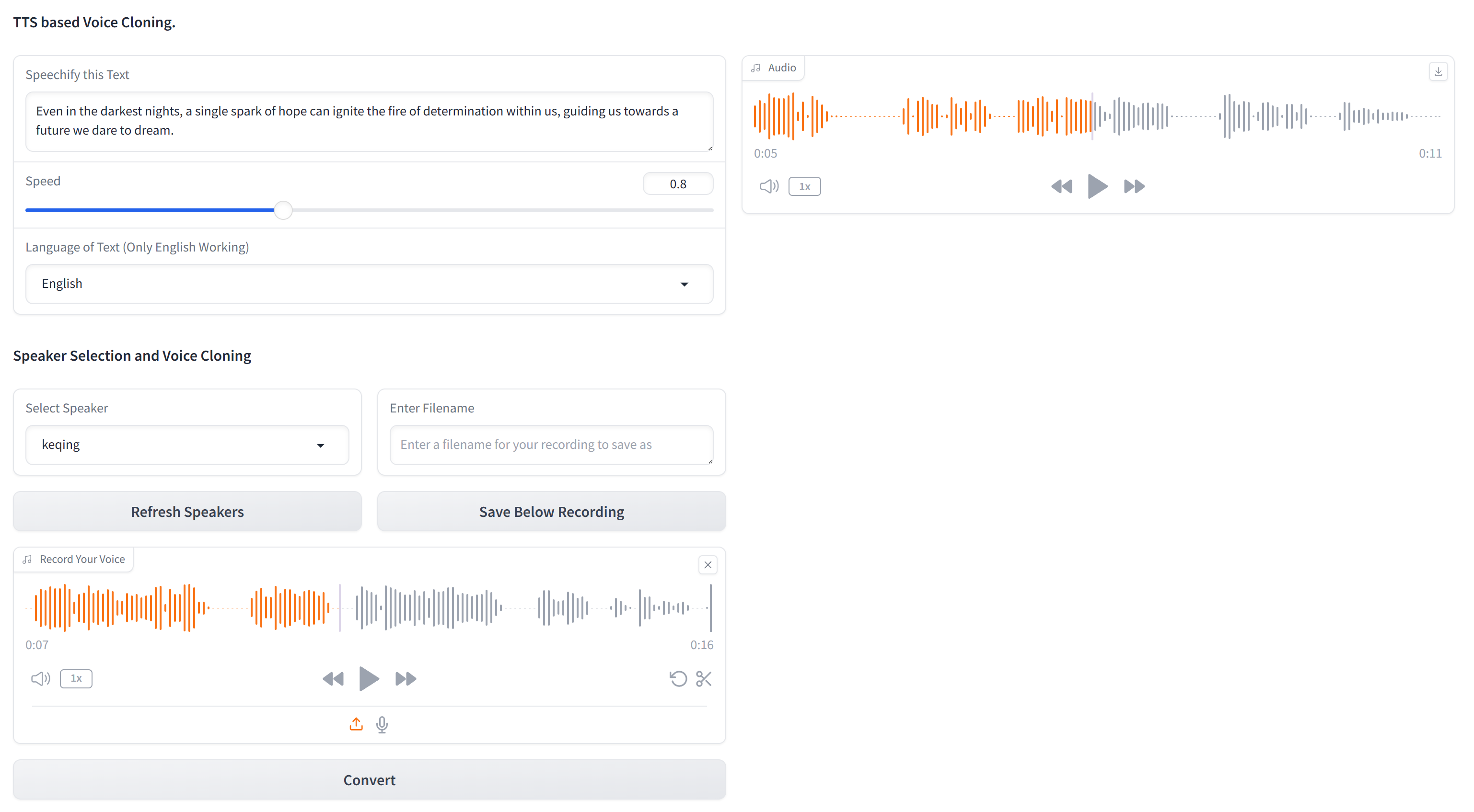
이 프로젝트를 설정하려면 터미널의 다음 단계를 따르십시오.
저장소를 복제하십시오
git clone https://github.com/pbanuru/xtts2-ui.git
cd xtts2-ui가상 환경 생성 :
python -m venv venvWindows :
# cmd prompt
venv S cripts a ctivate또는
# git bash
source venv/Scripts/activateLinux/Mac :
source venv/bin/activatePytorch 설치 :
nvcc --versionpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118다른 필수 패키지 설치 :
pip install -r requirements.txtpip install --upgrade TTS이 단계를 완료하면 설정이 완료되어 프로젝트 사용을 시작할 수 있습니다.
처음 사용하면 모델이 자동으로 다운로드됩니다.
다운로드 경로 :
/Users/USR/Library/Application Support/tts/tts_models--multilingual--multi-dataset--xtts_v2C:Users YOUR-USER-ACCOUNT AppDataLocalttstts_models--multilingual--multi-dataset--xtts_v2/home/${USER}/.local/share/tts/tts_models--multilingual--multi-dataset--xtts_v2 /$ {User }/.local/share/tts/tts_models ---multilegual-multi-dataset- xtts_v2 응용 프로그램을 실행하려면 :
python app.py
OR
streamlit run app2.py
또는 Texts.json에 샘플 입력 텍스트를 제공하고 여러 스피커로 여러 오디오를 생성하여 터미널 자체에서 실행할 수도 있습니다 (Appterminal.py에서 조정해야 할 수도 있음).
python appTerminal.py
초기 용도로는 다음과 같은 용어에 동의해야합니다.
[XTTS] Loading XTTS...
> tts_models/multilingual/multi-dataset/xtts_v2 has been updated, clearing model cache...
> You must agree to the terms of service to use this model.
| > Please see the terms of service at https://coqui.ai/cpml.txt
| > "I have read, understood and agreed to the Terms and Conditions." - [y/n]
| | >
모델이 각 실행을 다시 다운로드하는 경우 GitHub에서 4723 문제를 참조하십시오.
데이터 세트는 targets 라는 단일 폴더로 구성되며 테스트 목적으로 몇 가지 음성으로 사전 인구가 있습니다.
더 많은 목소리를 추가하려면 (GUI를 통과하지 않으려면) 약 10 초의 24kHz wav 파일을 만들고 targets 폴더 아래에 배치하십시오. YT-DLP를 사용하여 클로닝을 위해 YouTube에서 음성을 다운로드 할 수 있습니다.
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?"
| 언어 | 오디오 샘플 링크 |
|---|---|
| 영어 | |
| 러시아인 | |
| 아라비아 말 |
아랍어, 중국어, 체코, 네덜란드어, 영어, 프랑스어, 독일어, 헝가리어, 이탈리아어, 일본어 (설정 참조), 한국, 폴란드어, 포르투갈어, 러시아어, 스페인어, 터키어
대상 언어로 일본어를 선택하려면 사전을 설치해야합니다.
# Lite version
pip install fugashi[unidic-lite]또는보다 심각한 처리를 위해 :
# Full version
pip install fugashi[unidic]
python -m unidic download자세한 내용은 여기를 참조하십시오.


