xtts2 ui
1.0.0
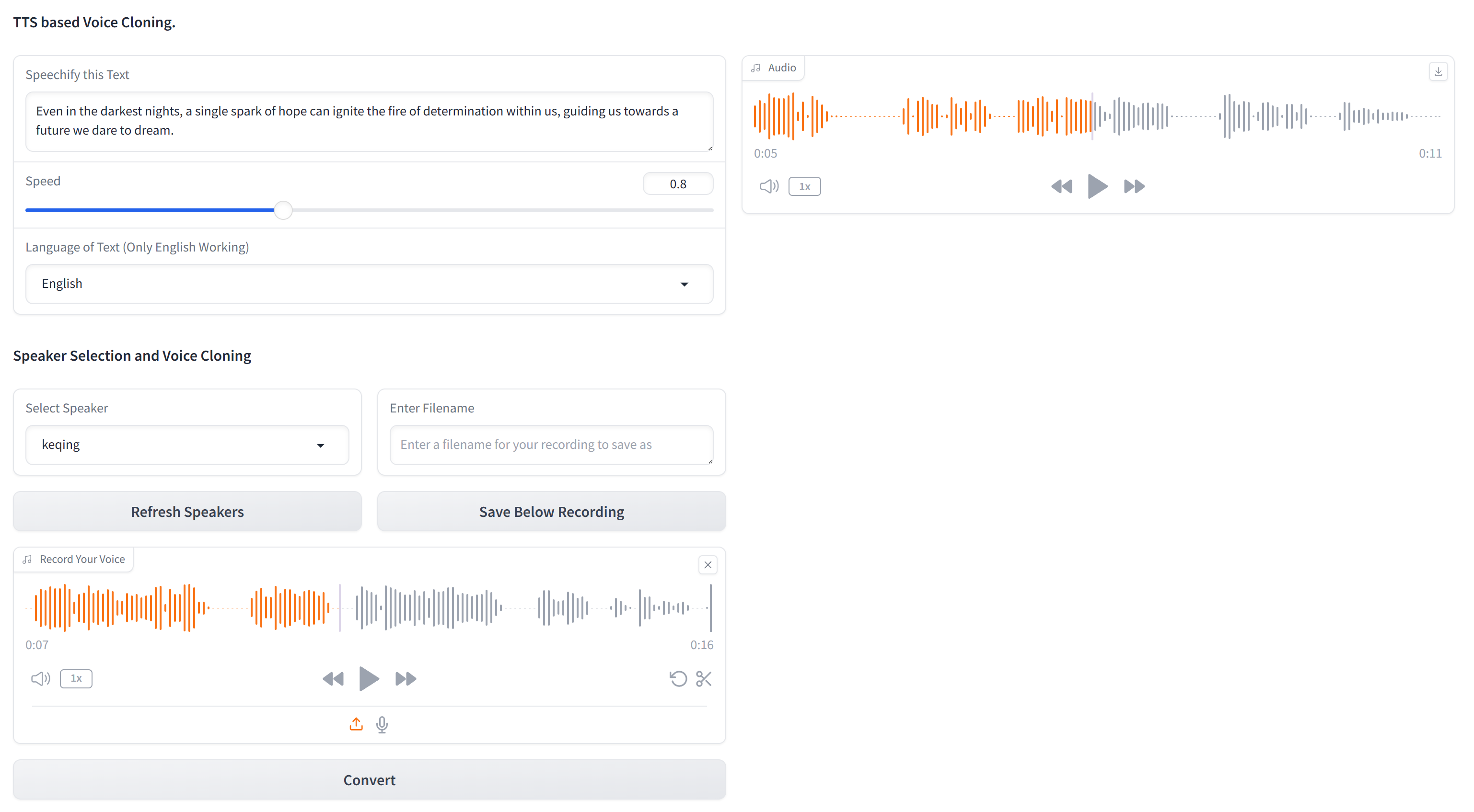
Ce référentiel contient le code essentiel pour le clonage de toute voix en utilisant uniquement du texte et un échantillon audio de 10 secondes de la voix cible. XTTS-2-UI est simple à configurer et à utiliser. Exemple de résultats?
Fonctionne dans 16 langues et a un enregistrement / téléchargement vocal intégré. Remarque: ne vous attendez pas à la qualité du niveau EL, ce n'est pas encore là.
Le modèle utilisé est tts_models/multilingual/multi-dataset/xtts_v2 . Pour plus de détails, reportez-vous à Hugging Face - XTTS-V2 et à sa version spécifique XTTS-V2 version 2.0.2.
Pour configurer ce projet, suivez ces étapes dans un terminal:
Cloner le référentiel
git clone https://github.com/pbanuru/xtts2-ui.git
cd xtts2-uiCréer un environnement virtuel:
python -m venv venvWindows:
# cmd prompt
venv S cripts a ctivateou
# git bash
source venv/Scripts/activateLinux / Mac:
source venv/bin/activateInstaller Pytorch:
nvcc --versionpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Installez les autres packages requis:
pip install -r requirements.txtpip install --upgrade TTSAprès avoir terminé ces étapes, votre configuration doit être terminée et vous pouvez commencer à utiliser le projet.
Les modèles seront téléchargés automatiquement lors de la première utilisation.
Télécharger les chemins:
/Users/USR/Library/Application Support/tts/tts_models--multilingual--multi-dataset--xtts_v2C:Users YOUR-USER-ACCOUNT AppDataLocalttstts_models--multilingual--multi-dataset--xtts_v2/home/${USER}/.local/share/tts/tts_models--multilingual--multi-dataset--xtts_v2 /$ nos ;auser }/.local/share/tts/TTS_Models --Multilingal - Multi-Dataset - TXTS_V2 Pour exécuter l'application:
python app.py
OR
streamlit run app2.py
Ou, vous pouvez également courir à partir du terminal lui-même, en fournissant des exemples de textes d'entrée sur des textes.
python appTerminal.py
Lors d'une utilisation initiale, vous devrez accepter les conditions:
[XTTS] Loading XTTS...
> tts_models/multilingual/multi-dataset/xtts_v2 has been updated, clearing model cache...
> You must agree to the terms of service to use this model.
| > Please see the terms of service at https://coqui.ai/cpml.txt
| > "I have read, understood and agreed to the Terms and Conditions." - [y/n]
| | >
Si votre modèle relève chaque exécution, veuillez consulter le numéro 4723 sur GitHub.
L'ensemble de données se compose d'un seul dossier nommé targets , pré-suppléés avec plusieurs voix à des fins de test.
Pour ajouter plus de voix (si vous ne voulez pas passer par l'interface graphique), créez un fichier WAV de 24 kHz d'environ 10 secondes et placez-le sous le dossier targets . Vous pouvez utiliser YT-DLP pour télécharger une voix depuis YouTube pour le clonage:
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?"
| Langue | Lien d'échantillonnage audio |
|---|---|
| Anglais | |
| russe | |
| arabe |
Arabe, chinois, tchèque, néerlandais, anglais, français, allemand, hongrois, italien, japonais (voir configuration), coréen, polonais, portugais, russe, espagnol, turc
Si vous souhaitez sélectionner le japonais comme langue cible, vous devez installer un dictionnaire.
# Lite version
pip install fugashi[unidic-lite]ou pour un traitement plus sérieux:
# Full version
pip install fugashi[unidic]
python -m unidic downloadPlus de détails ici.


