xtts2 ui
1.0.0
Este repositório contém o código essencial para clonar qualquer voz usando apenas texto e uma amostra de áudio de 10 segundos da voz de destino. XTTS-2-UI é simples de configurar e usar. Exemplo de resultados?
Funciona em 16 idiomas e possui gravação/upload de voz em construção. NOTA: Não espere qualidade do nível de EL, ainda não está lá.
O modelo usado é tts_models/multilingual/multi-dataset/xtts_v2 . Para obter mais detalhes, consulte o Face Hugging-XTTS-V2 e sua versão específica XTTS-V2 versão 2.0.2.
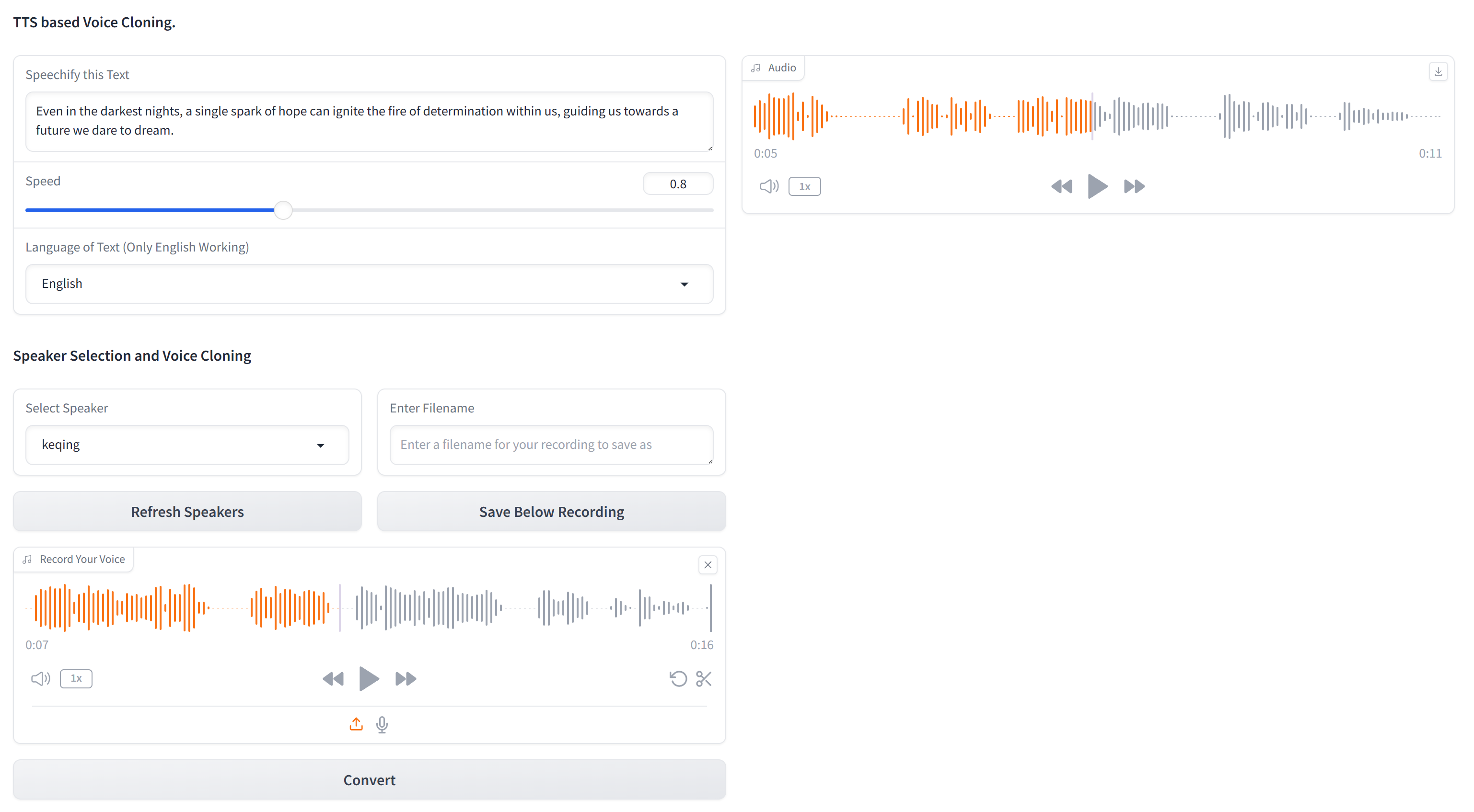
Para configurar este projeto, siga estas etapas em um terminal:
Clone o repositório
git clone https://github.com/pbanuru/xtts2-ui.git
cd xtts2-uiCrie um ambiente virtual:
python -m venv venvWindows:
# cmd prompt
venv S cripts a ctivateou
# git bash
source venv/Scripts/activateLinux/Mac:
source venv/bin/activateInstale Pytorch:
nvcc --versionpip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118Instale outros pacotes necessários:
pip install -r requirements.txtpip install --upgrade TTSDepois de concluir essas etapas, sua configuração deve estar completa e você pode começar a usar o projeto.
Os modelos serão baixados automaticamente após o primeiro uso.
Baixar caminhos:
/Users/USR/Library/Application Support/tts/tts_models--multilingual--multi-dataset--xtts_v2C:Users YOUR-USER-ACCOUNT AppDataLocalttstts_models--multilingual--multi-dataset--xtts_v2/home/${USER}/.local/share/tts/tts_models--multilingual--multi-dataset--xtts_v2 /tts_models--multilingual--multi-dataset --tts_v2 Para executar o aplicativo:
python app.py
OR
streamlit run app2.py
Ou você também pode ser executado a partir do próprio terminal, fornecendo textos de entrada de amostra em textos.json e gerar vários áudios com vários alto -falantes (pode ser necessário ajustar no appminal.py)
python appTerminal.py
No uso inicial, você precisará concordar com os termos:
[XTTS] Loading XTTS...
> tts_models/multilingual/multi-dataset/xtts_v2 has been updated, clearing model cache...
> You must agree to the terms of service to use this model.
| > Please see the terms of service at https://coqui.ai/cpml.txt
| > "I have read, understood and agreed to the Terms and Conditions." - [y/n]
| | >
Se o seu modelo estiver baixando novamente cada execução, consulte a edição 4723 no GitHub.
O conjunto de dados consiste em uma única pasta denominada targets , pré-populada com várias vozes para fins de teste.
Para adicionar mais vozes (se você não quiser passar pela GUI), crie um arquivo WAV de 24kHz de aproximadamente 10 segundos e coloque -o na pasta targets . Você pode usar o YT-DLP para baixar uma voz do YouTube para clonagem:
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?"
| Linguagem | Link de amostra de áudio |
|---|---|
| Inglês | |
| russo | |
| árabe |
Árabe, chinês, tcheco, holandês, inglês, francês, alemão, húngaro, italiano, japonês (ver configuração), coreano, polonês, português, russo, espanhol, turco
Se você deseja selecionar japonês como idioma de destino, deve instalar um dicionário.
# Lite version
pip install fugashi[unidic-lite]ou para um processamento mais sério:
# Full version
pip install fugashi[unidic]
python -m unidic downloadMais detalhes aqui.


