capsule networks
1.0.0
Основная внедрение Pytorch внедренной CUDA Pytorch архитектуры Capsnet в статье «Динамическая маршрутизация между капсулами» Кента Ивасаки от имени Грам.
Обучение для модели проводится с использованием Torchnet, с загрузкой набора данных MNIST и предварительной обработкой с TOCHVISION.
Капсула - это группа нейронов, вектор активности которых представляет параметры экземпляра определенного типа объекта, такого как объект или часть объекта. Мы используем длину вектора деятельности, чтобы представить вероятность того, что сущность существует и его ориентация для представления параметров экземпляров. Активные капсулы на одном уровне делают прогнозы посредством матриц преобразования, для параметров экземпляра капсул более высокого уровня. Когда несколько прогнозов согласуются, капсула более высокого уровня становится активной. Мы показываем, что дискриминационно обученная многослойная капсульная система достигает современной производительности на MNIST и значительно лучше, чем сверточная сеть, при распознавании сильно перекрывающихся цифр. Для достижения этих результатов мы используем итеративный механизм маршрутизации за активом: капсула более низкого уровня предпочитает отправлять свой выход на капсулы более высокого уровня, векторы активности которых имеют большой скалярный продукт с прогнозом, поступающим из капсулы нижнего уровня.
Бумага, написанная Сарой Сабур, Николасом Фросстом и Джеффри Э. Хинтоном. Для получения дополнительной информации, пожалуйста, ознакомьтесь с бумагой здесь.
Шаг 1 Отрегулируйте количество тренировочных эпох, размеров партий и т. Д. Внутри capsule_network.py .
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3Шаг 2 Начните обучение. Набор данных MNIST будет загружен, если у вас еще нет его в том же каталоге, в котором работает скрипт. Убедитесь, что Server Visdom Server!
$ sudo python3 -m visdom.server & python3 capsule_network.py Самая высокая точность составила 99,7% в 443 -й эпохе. Модель может достичь более высокой точности, как показано на тренде графических графов точности/потерь.
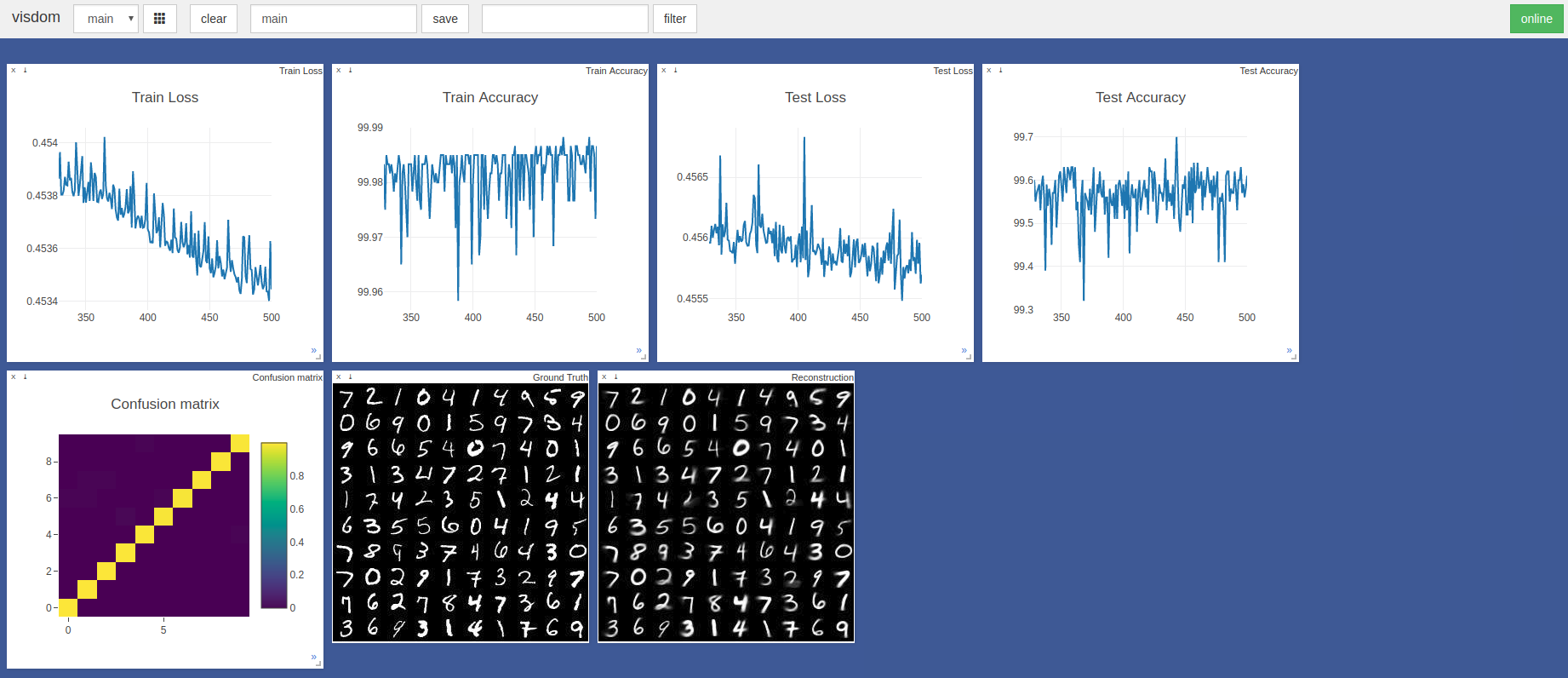
По умолчанию Pytorch Adam Optimizer Hypparameters использовались без планирования скорости обучения. Эпохи с размером партии 100 занимает ~ 3 минуты на лезвии Razer с GTX 1050 и ~ 2 минутами на NVIDIA Titan XP
В первую очередь ссылались на эти две реализации Tensorflow и Keras:
Большое спасибо @Innerpeace-Wu за обсуждение процедуры динамической маршрутизации, изложенной в статье.
Gram.ai в настоящее время значительно разрабатывает широкое количество моделей искусственного интеллекта, которые будут либо бесплатно, или выпущены бесплатно для сообщества, поэтому мы не можем гарантировать полную поддержку этой работы.
Если какие-либо проблемы возникнут с использованием этой реализации, однако, или если вы хотите внести свой вклад каким-либо образом, пожалуйста, не стесняйтесь отправлять электронное письмо по адресу [email protected] или открыть новый вопрос Github в этом хранилище.


