capsule networks
1.0.0
A implementação de Pytorch, habilitada para Cuda, habilitada para Cuda, da arquitetura Capsnet no artigo "Rotamento dinâmico entre cápsulas" de Kenta Iwasaki em nome de Gram.ai.
O treinamento para o modelo é realizado usando a Torchnet, com o carregamento do conjunto de dados MNIST e o pré -processamento feito com a Torchvision.
Uma cápsula é um grupo de neurônios cujo vetor de atividade representa os parâmetros de instanciação de um tipo específico de entidade, como um objeto ou parte do objeto. Utilizamos o comprimento do vetor de atividade para representar a probabilidade de que a entidade exista e sua orientação para representar os parâmetros de instanciação. As cápsulas ativas em um nível fazem previsões, através de matrizes de transformação, para os parâmetros de instanciação de cápsulas de nível superior. Quando várias previsões concordam, uma cápsula de nível superior se torna ativa. Mostramos que um sistema de cápsula multi-camada treinado discriminativamente atinge o desempenho de ponta no MNIST e é consideravelmente melhor do que uma rede convolucional no reconhecimento de dígitos altamente sobrepostos. Para alcançar esses resultados, usamos um mecanismo de roteamento por agitação: uma cápsula de nível inferior prefere enviar sua saída para cápsulas de nível superior cujos vetores de atividade têm um grande produto escalar com a previsão proveniente da cápsula de nível inferior.
Artigo escrito por Sara Sabour, Nicholas Frosst e Geoffrey E. Hinton. Para mais informações, consulte o jornal aqui.
Etapa 1 Ajuste o número de épocas de treinamento, tamanhos de lote, etc. Inside capsule_network.py .
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3Etapa 2 Inicie o treinamento. O conjunto de dados MNIST será baixado se você ainda não o tiver no mesmo diretório em que o script será executado. Certifique -se de ter o Visdom Server em execução!
$ sudo python3 -m visdom.server & python3 capsule_network.py A maior precisão foi de 99,7% na 443ª época. O modelo pode atingir uma precisão mais alta, conforme mostrado pela tendência dos gráficos de precisão/perda de teste abaixo.
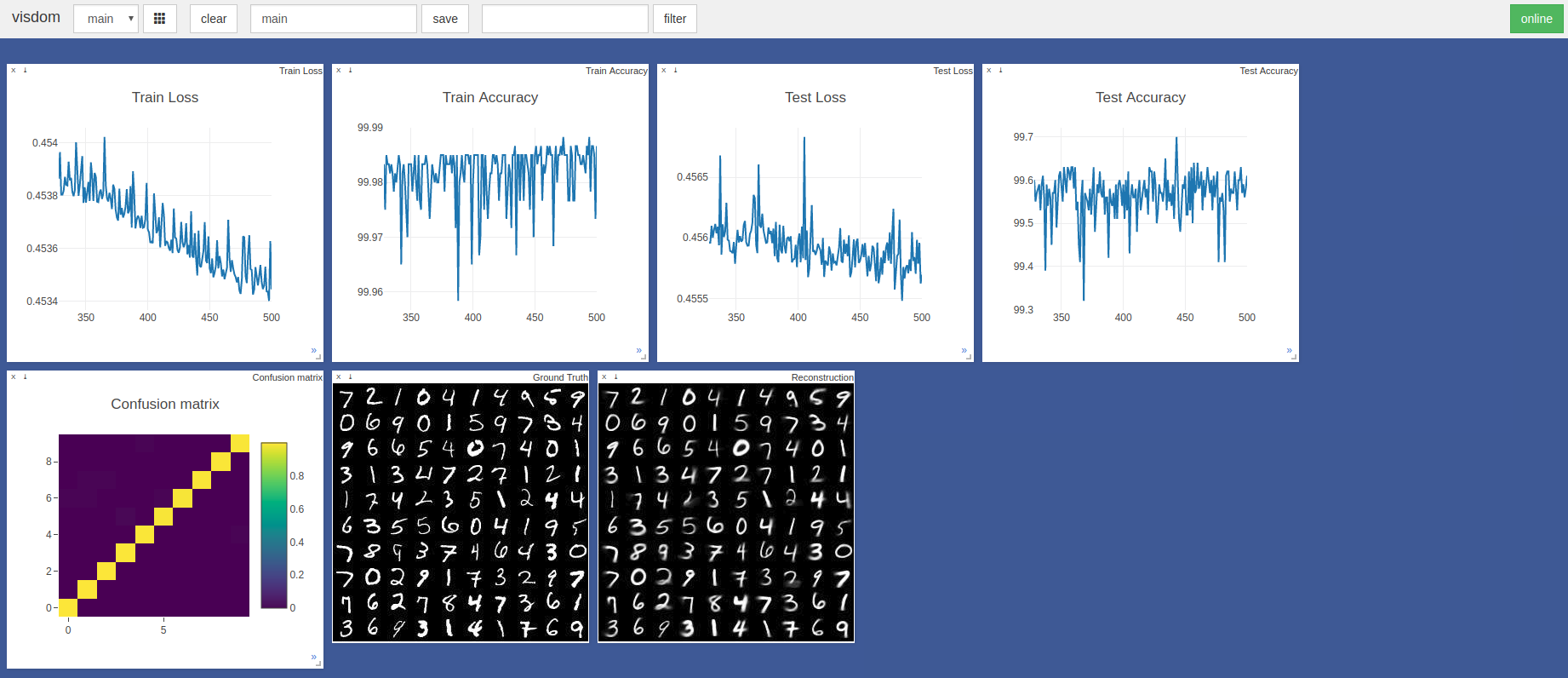
Os hiperparâmetros padrão do Pytorch Adam Optimizer foram usados sem agendamento de taxas de aprendizado. Épocas com tamanho de lote de 100 leva ~ 3 minutos em uma lâmina Razer com GTX 1050 e ~ 2 minutos em um Nvidia Titan XP
Referenciado principalmente essas duas implementações Tensorflow e Keras:
Muito obrigado a @innerpeace-wu por uma discussão sobre o procedimento de roteamento dinâmico descrito no artigo.
Atualmente, o Gram.ai está desenvolvendo um grande número de modelos de IA para serem de origem aberta ou liberados gratuitamente para a comunidade, daí o motivo pelo qual não podemos garantir um suporte completo para este trabalho.
Se algum problema apresentar algum problema com o uso desta implementação, ou se você quiser contribuir de alguma forma, sinta-se à vontade para enviar um e-mail para [email protected] ou abrir um novo problema no GitHub neste repositório.


