capsule networks
1.0.0
Implementasi Pytorch yang diaktifkan oleh Cuda dari Arsitektur Capsnet di koran "Routing Dinamis Antara Kapsul" oleh Kenta Iwasaki atas nama Gram.ai.
Pelatihan untuk model dilakukan dengan menggunakan Torchnet, dengan pemuatan dataset MNIST dan preprocessing dilakukan dengan TorchVision.
Kapsul adalah kelompok neuron yang vektor aktivitasnya mewakili parameter instantiasi dari jenis entitas tertentu seperti bagian objek atau objek. Kami menggunakan panjang vektor aktivitas untuk mewakili probabilitas bahwa entitas ada dan orientasi untuk mewakili paramter instantiasi. Kapsul aktif pada satu tingkat membuat prediksi, melalui matriks transformasi, untuk parameter instantiasi kapsul tingkat lebih tinggi. Ketika beberapa prediksi setuju, kapsul level yang lebih tinggi menjadi aktif. Kami menunjukkan bahwa sistem kapsul multi-lapisan yang terlatih secara diskriminatif mencapai kinerja canggih pada MNIST dan jauh lebih baik daripada jaring konvolusional dalam mengenali angka yang sangat tumpang tindih. Untuk mencapai hasil ini, kami menggunakan mekanisme routing-by-agreement berulang: kapsul tingkat rendah lebih suka mengirim outputnya ke kapsul tingkat yang lebih tinggi yang vektor aktivitasnya memiliki produk skalar besar dengan prediksi yang berasal dari kapsul tingkat bawah.
Makalah yang ditulis oleh Sara Sabour, Nicholas Frosst, dan Geoffrey E. Hinton. Untuk informasi lebih lanjut, silakan lihat kertas di sini.
Langkah 1 Sesuaikan jumlah zaman pelatihan, ukuran batch, dll. Di dalam capsule_network.py .
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3Langkah 2 Mulai Pelatihan. Dataset MNIST akan diunduh jika Anda belum memilikinya di direktori yang sama dengan skrip dijalankan. Pastikan Visdom Server berjalan!
$ sudo python3 -m visdom.server & python3 capsule_network.py Akurasi tertinggi adalah 99,7% pada zaman ke -443. Model dapat mencapai akurasi yang lebih tinggi seperti yang ditunjukkan oleh tren grafik akurasi/kerugian uji di bawah ini.
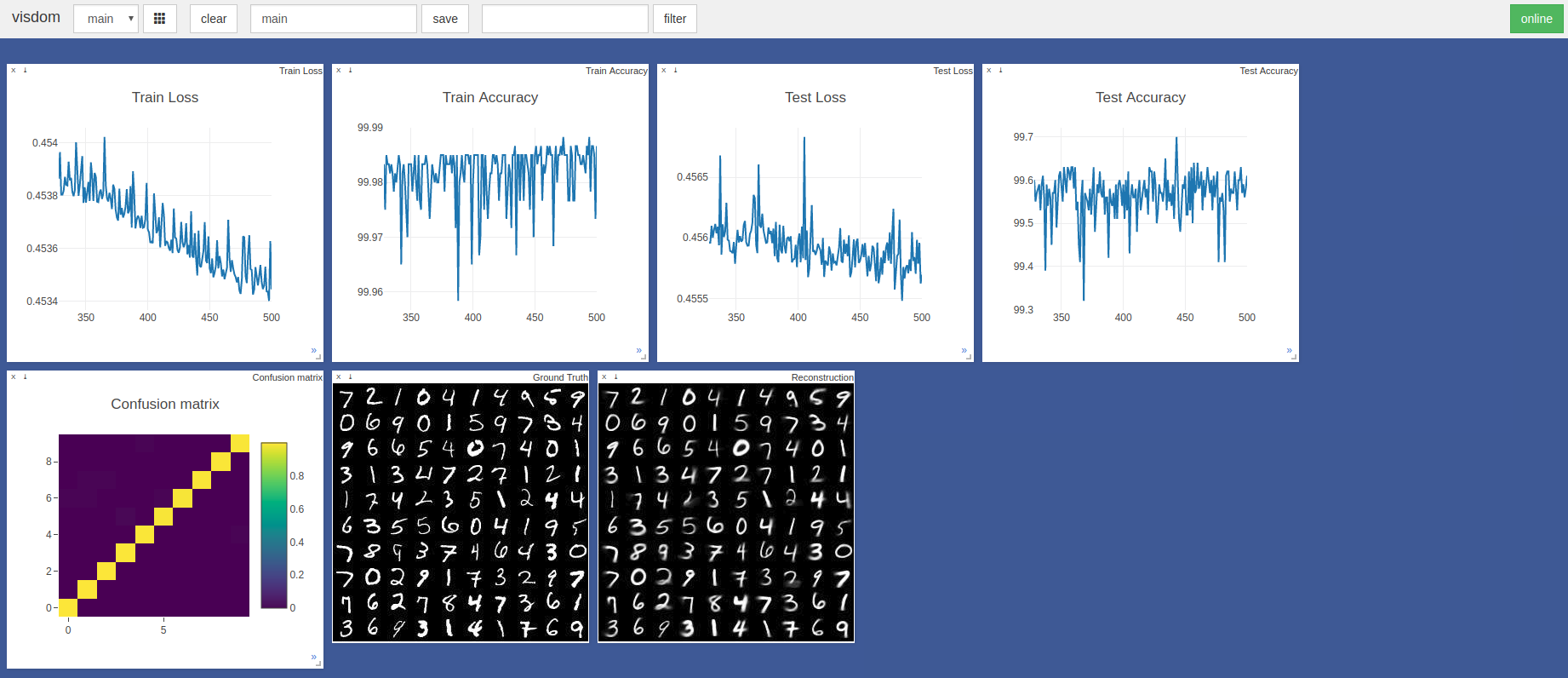
Hyperparameters Pytorch Adam Optimizer default digunakan tanpa penjadwalan tingkat pembelajaran. Zaman dengan ukuran batch 100 memakan waktu ~ 3 menit pada blade razer dengan GTX 1050 dan ~ 2 menit pada nvidia titan XP
Terutama mereferensikan dua implementasi TensorFlow dan Keras ini:
Terima kasih banyak kepada @innerpeace-wu untuk diskusi tentang prosedur perutean dinamis yang diuraikan dalam makalah.
Gram.ai saat ini banyak mengembangkan sejumlah besar model AI untuk dibebaskan atau dirilis secara gratis ke masyarakat, maka mengapa kami tidak dapat menjamin dukungan lengkap untuk pekerjaan ini.
Namun, jika ada masalah yang muncul dengan penggunaan implementasi ini, atau jika Anda ingin berkontribusi dengan cara apa pun, jangan ragu untuk mengirim email ke [email protected] atau buka masalah GitHub baru di repositori ini.


