capsule networks
1.0.0
Gram.aiに代わって、Kenta Iwasakiによる「Capsules間の動的ルーティング」の紙のCapsnetアーキテクチャのCuda対応Pytorchの実装。
モデルのトレーニングは、TorchNetを使用して行われ、MNISTデータセットの読み込みとTorchVisionで行われます。
カプセルは、オブジェクトやオブジェクトパーツなどの特定のタイプのエンティティのインスタンス化パラメーターを表すアクティビティベクトルを表すニューロンのグループです。アクティビティベクトルの長さを使用して、エンティティが存在する確率とその方向を表して、インスタンス化パラメーターを表します。 1つのレベルのアクティブカプセルは、高レベルのカプセルのインスタンス化パラメーターについて、変換行列を介して予測します。複数の予測が同意すると、より高いレベルのカプセルがアクティブになります。差別的に訓練された多層カプセルシステムが、MNISTで最先端のパフォーマンスを達成し、非常に重複する数字を認識する畳み込みネットよりもかなり優れていることを示しています。これらの結果を達成するために、繰り返しのルーティングメカニズムを使用します。下位レベルのカプセルは、アクティビティベクターが低レベルのカプセルからの予測を備えた大きなスカラー積を持つ高レベルのカプセルにその出力を送信することを好みます。
サラ・サブール、ニコラス・フロススト、ジェフリー・E・ヒントンが書いた論文。詳細については、こちらの論文をご覧ください。
ステップ1 capsule_network.py内のトレーニングエポック、バッチサイズなどの数を調整します。
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3ステップ2トレーニングを開始します。 MNISTデータセットは、スクリプトが実行されているのと同じディレクトリにまだ存在しない場合は、ダウンロードされます。VisomServerを実行してください。
$ sudo python3 -m visdom.server & python3 capsule_network.py 最も高い精度は、443番目のエポックで99.7%でした。モデルは、以下のテスト精度/損失グラフの傾向に示されているように、より高い精度を達成する場合があります。
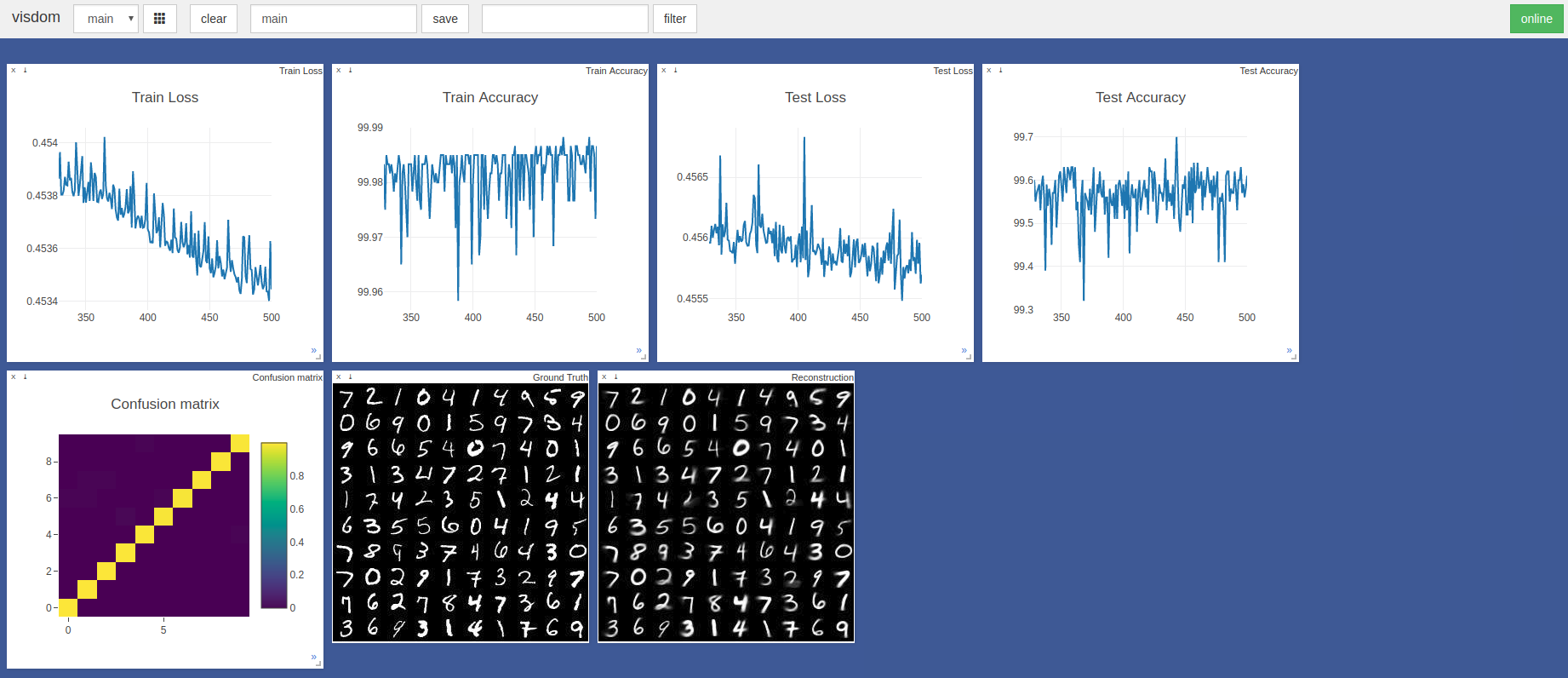
デフォルトのPytorch Adam Optimizer HyperParametersは、学習率のスケジューリングなしで使用されました。 100のバッチサイズのエポックは、GTX 1050を備えたRazerブレードで約3分かかり、NvidiaTitan XPで約2分かかります
主にこれら2つのTensorflowとKerasの実装を参照しました。
@innerpeace-wuに、論文で概説されている動的なルーティング手順についての議論に感謝します。
Gram.aiは現在、コミュニティにオープンソースまたは無料でリリースされるように、多数のAIモデルを大量に開発しているため、この作業の完全なサポートを保証できない理由です。
ただし、この実装の使用が発生した場合、または何らかの方法で貢献したい場合は、[email protected]に電子メールを送信するか、このリポジトリで新しいgithub号を開きます。


