capsule networks
1.0.0
A Barebones Cuda-fähige Pytorch-Implementierung der Capsnet-Architektur in der Arbeit "Dynamisches Routing zwischen Kapseln" von Kenta Iwasaki im Namen von Gram.ai.
Das Training für das Modell erfolgt mit Torchnet mit MNIST -Datensatzlast und Vorverarbeitung mit Torchvision.
Eine Kapsel ist eine Gruppe von Neuronen, deren Aktivitätsvektor die Instanziationsparameter einer bestimmten Art von Entität wie einem Objekt- oder Objektteil darstellt. Wir verwenden die Länge des Aktivitätsvektors, um die Wahrscheinlichkeit darzustellen, dass die Entität existiert, und ihre Orientierung, um die Instanziparamter darzustellen. Aktive Kapseln auf einer Ebene machen Vorhersagen über Transformationsmatrizen für die Instanziationsparameter von Kapseln auf höherer Ebene. Wenn mehrere Vorhersagen übereinstimmen, wird eine Kapsel auf höherer Ebene aktiv. Wir zeigen, dass ein diskriminativ ausgebildetes, mehrschichtiges Kapselsystem eine modernste Leistung für MNIST erzielt und erheblich besser ist als ein Faltungsnetz bei der Erkennung hochlappender Ziffern. Um diese Ergebnisse zu erzielen, verwenden wir einen iterativen Routing-by-Agreement-Mechanismus: Eine Kapsel auf niedrigerer Ebene zieht es vor, seine Ausgabe auf höhere Kapseln zu senden, deren Aktivitätsvektoren ein großes skalares Produkt haben, wobei die Vorhersage aus der Kapsel der unteren Ebene stammt.
Papier von Sara Sabour, Nicholas Frost und Geoffrey E. Hinton. Weitere Informationen finden Sie in der Zeitung hier.
Schritt 1 Passen Sie die Anzahl der Trainings -Epochen, Stapelgrößen usw. in capsule_network.py an.
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3Schritt 2 Beginnen Sie mit dem Training. Der MNIST -Datensatz wird heruntergeladen, wenn Sie ihn noch nicht im selben Verzeichnis haben, in dem das Skript ausgeführt wird. Stellen Sie sicher, dass der Visdom -Server ausgeführt wird!
$ sudo python3 -m visdom.server & python3 capsule_network.py Die höchste Genauigkeit betrug 99,7% in der 443. Epoche. Das Modell kann eine höhere Genauigkeit erzielen, wie der Trend der folgenden Testgenauigkeit/Verlustdiagramme gezeigt.
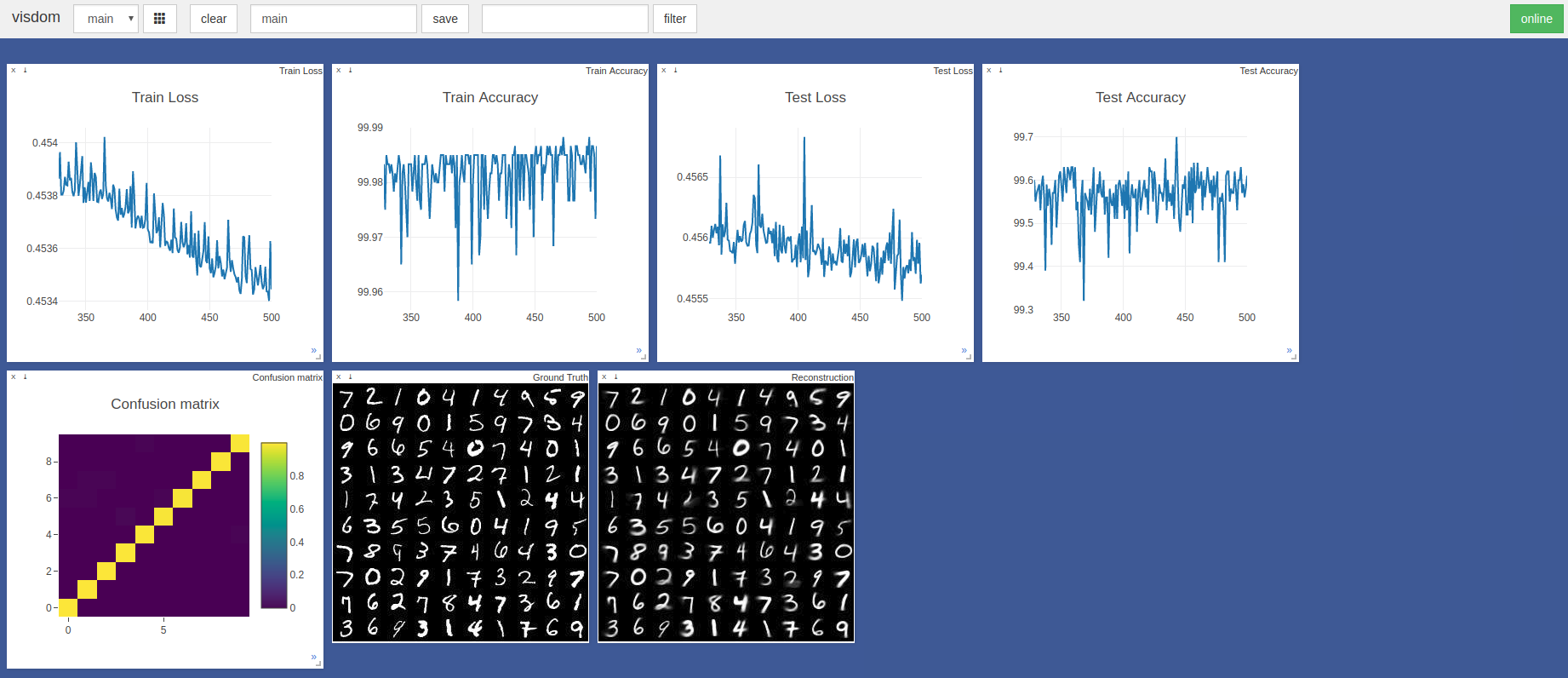
Standard -Pytorch Adam Optimizer Hyperparameter wurden ohne Planung der Lernrate verwendet. Epochen mit einer Chargengröße von 100 dauert ~ 3 Minuten auf einer Razer -Klinge mit GTX 1050 und ~ 2 Minuten auf einem Nvidia Titan XP
In erster Linie verwies diese beiden Tensorflow- und Keras -Implementierungen:
Vielen Dank an @Innerpeace-wu für eine Diskussion über das im Papier beschriebene dynamische Routing-Verfahren.
Gram.ai entwickelt derzeit stark eine Vielzahl von KI-Modellen, die entweder offen oder kostenlos für die Community freigegeben werden können. Deshalb können wir diese Arbeit nicht garantieren.
Wenn Probleme jedoch die Verwendung dieser Implementierung aufnehmen oder wenn Sie in irgendeiner Weise einen Beitrag leisten möchten, können Sie eine E-Mail an [email protected] senden oder ein neues Github-Problem in diesem Repository eröffnen.


