capsule networks
1.0.0
Una implementación de Pytorch habilitada para CUDA Barebones de la arquitectura Capsnet en el documento "Enrutamiento dinámico entre cápsulas" por Kenta Iwasaki en nombre de Gram.AI.
El entrenamiento para el modelo se realiza utilizando TorchNet, con la carga y el preprocesamiento del conjunto de datos MNIST realizado con TorchVision.
Una cápsula es un grupo de neuronas cuyo vector de actividad representa los parámetros de instanciación de un tipo específico de entidad, como un objeto o parte del objeto. Utilizamos la longitud del vector de actividad para representar la probabilidad de que la entidad exista y su orientación para representar los parámetros de instancia. Las cápsulas activas en un nivel hacen predicciones, a través de matrices de transformación, para los parámetros de instancia de las cápsulas de nivel superior. Cuando están de acuerdo múltiples predicciones, una cápsula de nivel superior se activa. Mostramos que un sistema de cápsulas de múltiples capas capacitadas discriminativamente logra un rendimiento de última generación en MNIST y es considerablemente mejor que una red convolucional para reconocer dígitos altamente superpuestos. Para lograr estos resultados, utilizamos un mecanismo iterativo de enrutamiento por acumulación: una cápsula de nivel inferior prefiere enviar su salida a cápsulas de nivel superior cuyos vectores de actividad tienen un producto escalar grande con la predicción proveniente de la cápsula de nivel inferior.
Documento escrito por Sara Sabour, Nicholas Frosst y Geoffrey E. Hinton. Para obtener más información, consulte el documento aquí.
Paso 1 Ajuste el número de épocas de entrenamiento, tamaños de lotes, etc. dentro de capsule_network.py .
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3Paso 2 Comience al entrenamiento. El conjunto de datos MNIST se descargará si no lo tiene en el mismo directorio en el que se ejecuta el script. ¡Asegúrese de que Visdom Server se ejecute!
$ sudo python3 -m visdom.server & python3 capsule_network.py La mayor precisión fue del 99.7% en la época 443. El modelo puede lograr una mayor precisión como se muestra en la tendencia de las gráficos de precisión/pérdida de prueba a continuación.
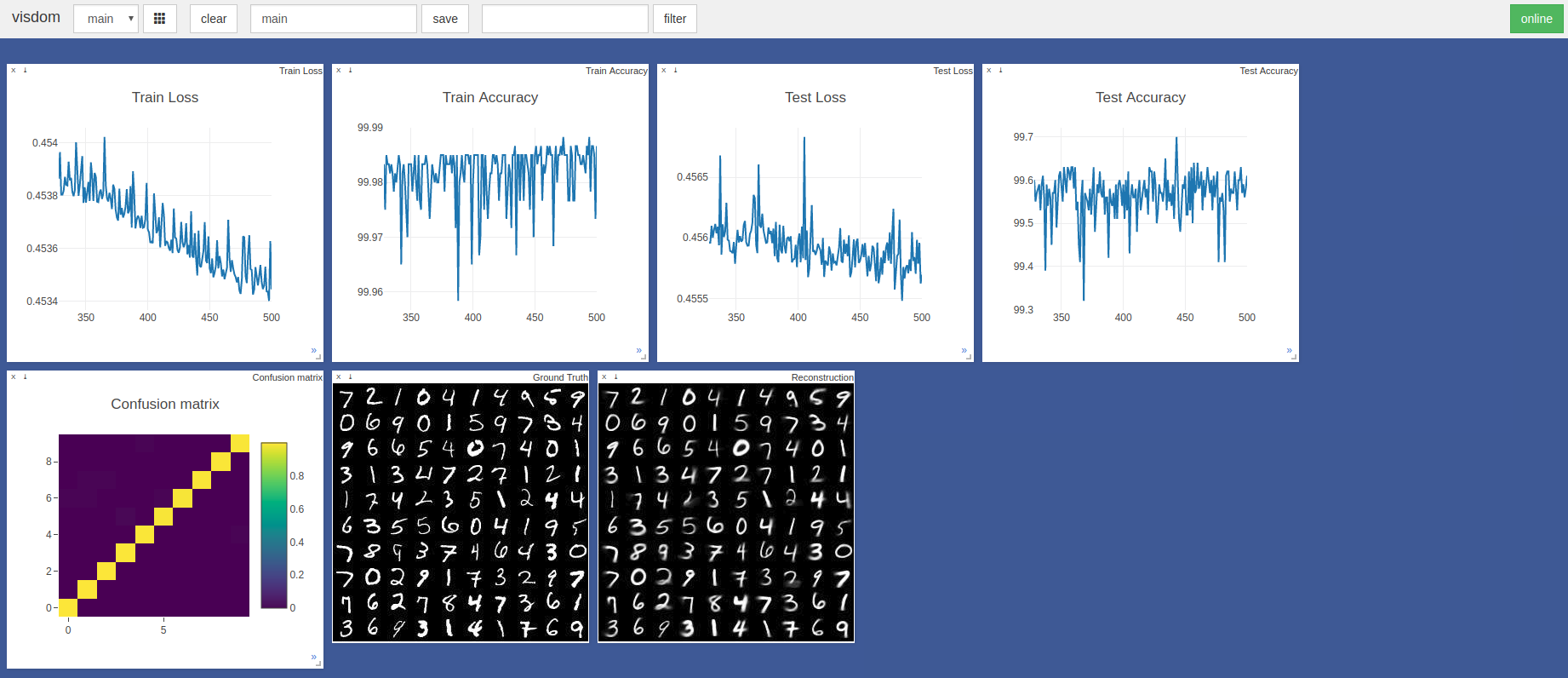
Se usaron hiperparametros Pytorch Adam Optimizer predeterminados sin programación de tasas de aprendizaje. Las épocas con tamaño por lotes de 100 tardan ~ 3 minutos en una cuchilla Razer con GTX 1050 y ~ 2 minutos en un Nvidia Titan XP
Principalmente referencia a estas dos implementaciones de TensorFlow y Keras:
Muchas gracias a @innerpeace-wu por una discusión sobre el procedimiento de enrutamiento dinámico descrito en el documento.
Gram.ai actualmente está desarrollando en gran medida un amplio número de modelos de IA para ser de código abierto o liberado de forma gratuita para la comunidad, por lo que no podemos garantizar un apoyo completo para este trabajo.
Sin embargo, si algún problema presenta el uso de esta implementación, o si desea contribuir de alguna manera, no dude en enviar un correo electrónico a [email protected] o abrir un nuevo problema de GitHub en este repositorio.


