capsule networks
1.0.0
Une mise en œuvre pytorch compatible Barebones Cuda de l'architecture Capsnet dans l'article "Route dynamique entre les capsules" de Kenta Iwasaki au nom de Gram.ai.
La formation du modèle se fait à l'aide de Torchnet, avec le chargement de données MNIST et le prétraitement effectué avec TorchVision.
Une capsule est un groupe de neurones dont le vecteur d'activité représente les paramètres d'instanciation d'un type spécifique d'entité tel qu'un objet ou une partie d'objet. Nous utilisons la longueur du vecteur d'activité pour représenter la probabilité que l'entité existe et son orientation pour représenter les paramètres d'instanciation. Les capsules actives à un niveau font des prédictions, via des matrices de transformation, pour les paramètres d'instanciation des capsules de niveau supérieur. Lorsque plusieurs prédictions sont d'accord, une capsule de niveau supérieur devient active. Nous montrons qu'un système de capsule multicouches formé discriminant atteint des performances de pointe sur MNIST et est considérablement meilleur qu'un filet convolutionnel pour reconnaître des chiffres très chevauchants. Pour obtenir ces résultats, nous utilisons un mécanisme de routage itératif par agression: une capsule de niveau inférieur préfère envoyer sa sortie à des capsules de niveau supérieur dont les vecteurs d'activité ont un grand produit scalaire avec la prédiction provenant de la capsule de niveau inférieur.
Document écrit par Sara Sabour, Nicholas Frosst et Geoffrey E. Hinton. Pour plus d'informations, veuillez consulter le document ici.
Étape 1 Ajustez le nombre d'époches de formation, tailles de lots, etc. à l'intérieur capsule_network.py .
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 3Étape 2 Commencez une formation. L'ensemble de données MNIST sera téléchargé si vous ne l'avez pas déjà dans le même répertoire dans lequel le script est exécuté. Assurez-vous que le serveur de Visdom en cours d'exécution!
$ sudo python3 -m visdom.server & python3 capsule_network.py La précision la plus élevée était de 99,7% sur la 443e époque. Le modèle peut atteindre une précision plus élevée comme le montre la tendance des graphiques de précision / perte de test ci-dessous.
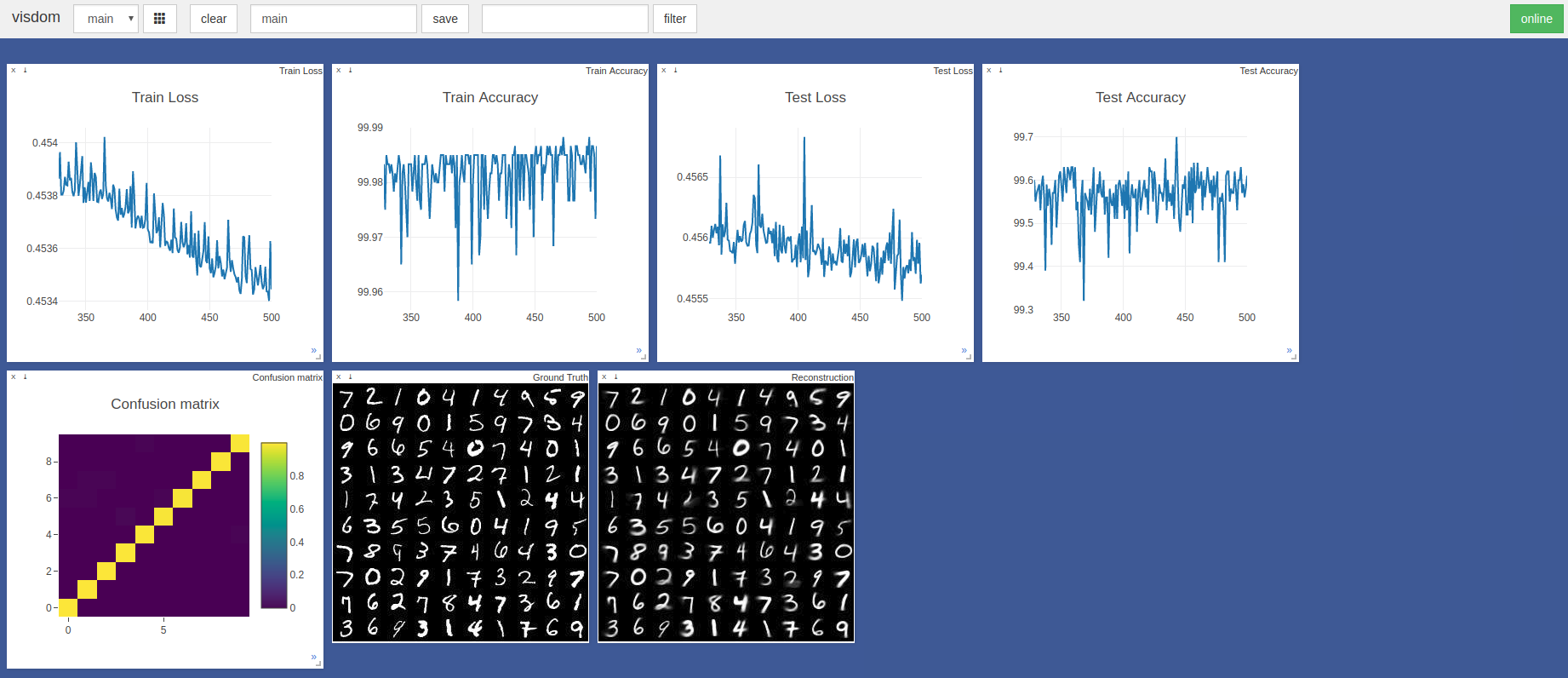
Les hyperparamètres par défaut Pytorch ADAM Optimizer ont été utilisés sans planification du taux d'apprentissage. Les époques avec une taille de lot de 100 prennent ~ 3 minutes sur une lame Razer avec GTX 1050 et ~ 2 minutes sur un Nvidia Titan XP
Référencé principalement ces deux implémentations TensorFlow et Keras:
Un grand merci à @ InnerPeace-WU pour une discussion sur la procédure de routage dynamique décrite dans l'article.
Gram.ai développe actuellement fortement un grand nombre de modèles d'IA pour être open source ou publié gratuitement à la communauté, d'où la raison pour laquelle nous ne pouvons garantir un soutien complet à ce travail.
Cependant, si des problèmes sont utilisés avec l'utilisation de cette implémentation, ou si vous souhaitez contribuer de quelque manière que ce soit, n'hésitez pas à envoyer un e-mail à [email protected] ou à ouvrir un nouveau problème GitHub sur ce référentiel.


