capsule networks
1.0.0
gram.ai를 대신하여 Kenta Iwasaki의 "Capsules 간의 동적 라우팅"에서 Capsnet 아키텍처의 Barebones Cuda 지원 Pytorch 구현.
Torchvision으로 MNIST 데이터 세트로드 및 전처리를 사용하여 Torchnet을 사용하여 모델에 대한 교육이 수행됩니다.
캡슐은 활동 벡터가 객체 또는 객체 부분과 같은 특정 유형의 엔티티의 인스턴스화 매개 변수를 나타내는 뉴런 그룹입니다. 우리는 활동 벡터의 길이를 사용하여 엔티티가 존재할 확률과 인스턴스화 매개 변수를 나타내는 방향을 나타냅니다. 한 레벨의 활성 캡슐은 변환 행렬을 통해 예측, 고급 캡슐의 인스턴스화 매개 변수를 예측합니다. 다중 예측이 동의하면 더 높은 레벨 캡슐이 활성화됩니다. 우리는 차별적으로 훈련 된 다층 캡슐 시스템이 MNIST에서 최첨단 성능을 달성하고 겹치는 숫자를 인식 할 때 컨볼 루션 그물보다 상당히 우수하다는 것을 보여줍니다. 이러한 결과를 달성하기 위해 우리는 반복적 인 라우팅 거주 메커니즘을 사용합니다. 하위 레벨 캡슐은 출력을 더 높은 레벨 캡슐로 보내는 것을 선호합니다.
Sara Sabour, Nicholas Frosst 및 Geoffrey E. Hinton이 작성한 논문. 자세한 내용은 여기에서 논문을 확인하십시오.
1 단계 capsule_network.py 내부의 교육 에포크, 배치 크기 등의 수를 조정하십시오.
BATCH_SIZE = 100
NUM_CLASSES = 10
NUM_EPOCHS = 30
NUM_ROUTING_ITERATIONS = 32 단계 훈련 시작. 스크립트가 실행중인 동일한 디렉토리에 아직 없으면 MNIST 데이터 세트가 다운로드됩니다. Visdom Server가 실행되도록하십시오!
$ sudo python3 -m visdom.server & python3 capsule_network.py 가장 높은 정확도는 443 번째 에포크에서 99.7%였습니다. 이 모델은 아래 테스트 정확도/손실 그래프의 추세에 표시된 바와 같이 더 높은 정확도를 달성 할 수 있습니다.
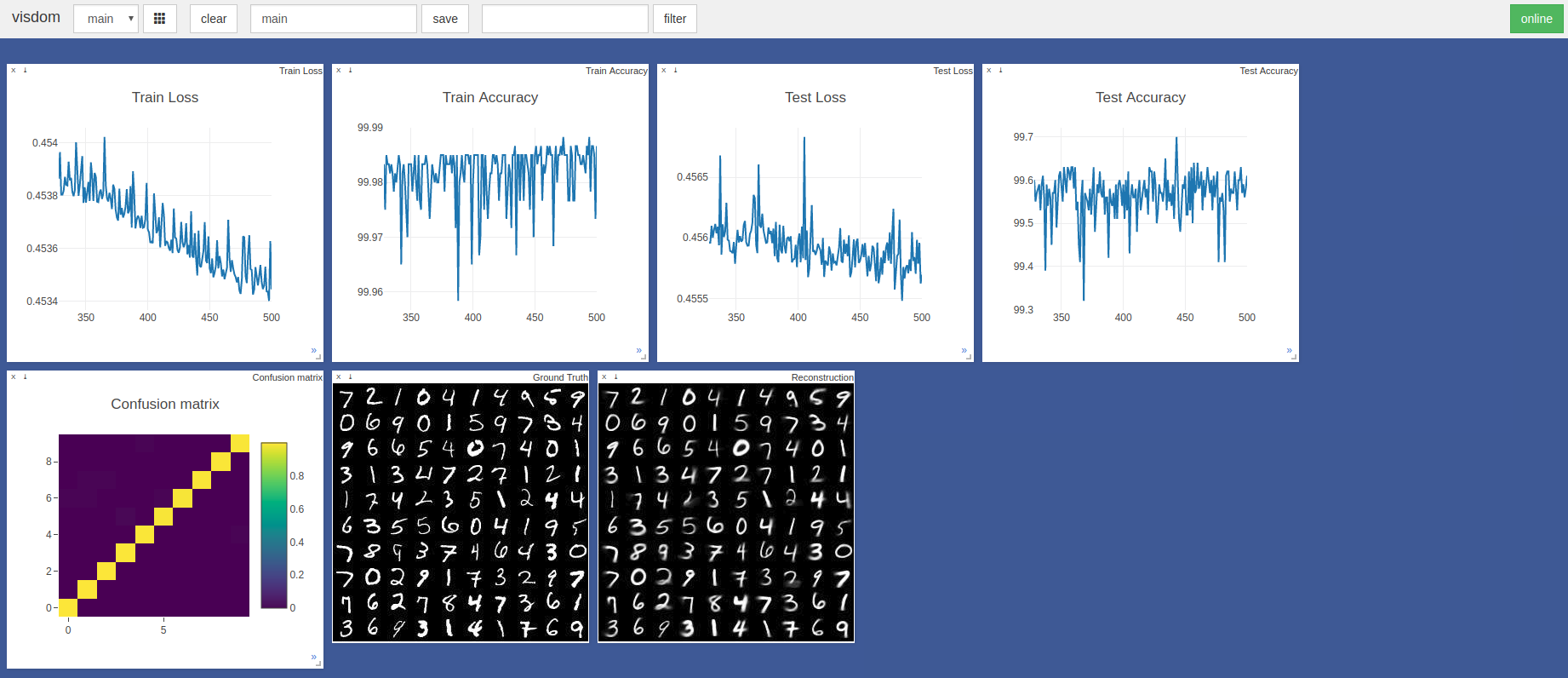
기본 Pytorch Adam Optimizer Hyperparameters는 학습 속도 예약없이 사용되었습니다. 배치 크기가 100 인 에포크는 Razer 블레이드에서 ~ 3 분, GTX 1050에서 3 분, NVIDIA TITAN XP에서 ~ 2 분이 걸립니다.
주로이 두 개의 텐서 플로 및 케라 구현을 참조했습니다.
논문에 요약 된 동적 라우팅 절차에 대한 토론에 대해 @Innerpeace-Wu에게 감사드립니다.
Gram.ai는 현재 오픈 소스 또는 커뮤니티에 무료로 출시 될 광범위한 AI 모델을 크게 개발하고 있으므로이 작업에 대한 완전한 지원을 보장 할 수없는 이유.
그러나이 구현의 사용법이 발생하거나 어떤 식 으로든 기여하고 싶다면 [email protected]에 이메일을 보내 거나이 저장소에서 새로운 Github 문제를 열어주십시오.


