rzv_data_engineering_series_s01e01
1.0.0

Вот открытый эпизод учебного курса RZV Data Engineering Course. Выберите, в какую серию вы включите сегодня вечером - тот, который отвлечет вас от жизни, или тот, который даст вам возможность изучать навыки и создать!
Курс идет в самостоятельном формате, инфраструктура развернута локально в контейнерах Docker. Я ожидаю, что вы будете искать материалы, чтобы ответить на свои вопросы самостоятельно и обсудить их в общем чате. Решение применяется к задаче на среднем уровне. Задачи делятся на разные уровни сложности. Начните с того, где вы чувствуете себя наиболее комфортно, и проходите свой путь. Чем выше оценка, тем абстрактно это заявление проблемы - это как в жизни.
Навыки, которые вы приобретаете во время курса, могут быть перенесены на работу практически без усилий. И, в отличие от большинства курсов, здесь вы работаете с «живыми» данными, которые генерируются в режиме реального времени (упрощенным образом). К концу первого сезона серии вы сможете испытать проблемы с разработкой данных на практике и написать решения самостоятельно.
Чем дальше по ходу, тем больше модулей будет прикреплено после «развития бизнеса»:
PS Проверьте переведенные версии readme.md в корне основных каталогов: [RU] доступен.
Это первый эпизод, охватывающий функции инкрементной загрузки через воздушный поток Apache. В процессе выполнения задач на среднем и старшем уровне вы столкнетесь с множеством трудностей, которые существуют в реальной рабочей практике. В то же время, даже юношеские и стажировки познакомит вас с новыми концепциями и постепенно подготовят вас к более сложным задачам.
Я призываю вас сначала попытаться решить проблему самостоятельно, а затем посмотреть на мою версию.
Вы узнаете:
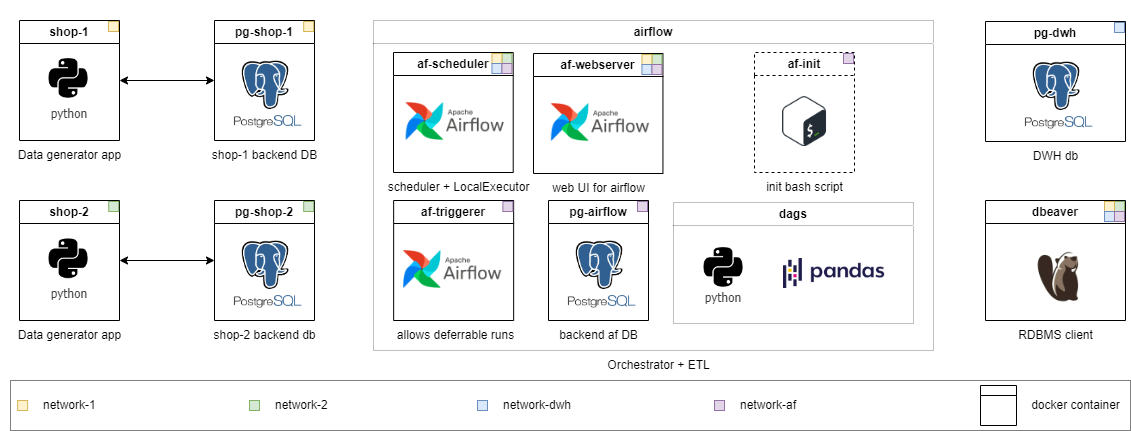
Каждый уровень имеет свой собственный каталог. С каждым уровнем я уменьшаю объем готового кода и поднимаю сложность задачи. Содержание каталогов немного отличается, но инфраструктура готова к использованию повсюду. Подробные задачи описаны в README.md каждого класса. Выберите свой и не стесняйтесь снизить уровень, если это необходимо.
Стажер : Весь код уже реализован для проблемы среднего класса. Просто запустите и исследуйте это. Также вы можете найти заметки, объясняющие, почему я реализовал решение таким образом.
Стажер : расширяйте существующую конфигурацию так, чтобы письменный DAG начинает загружать данные из нового источника и новых таблиц. Напишите простой DAG для работы с файловой системой для очистки временных файлов с помощью Bashoperator.
Младший : Напишите постепенную загрузку, не учитывая историческое хранилище. Данные на источнике не обновлены.
Средняя : Напишите постепенную нагрузку в таблицы SCD2. Обратите внимание, что данные могут быть обновлены на источнике.
Старший : Назначение как для среднего + настройка записи Audit-Publish, чтобы обеспечить качество данных и провести тестирование нагрузки письменного решения.
Историческое хранение данных с SCD2: 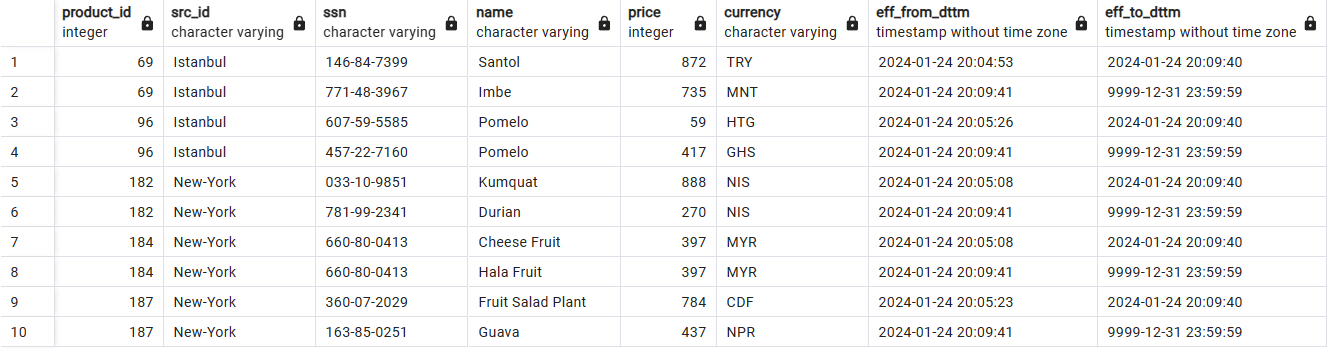
Покрементная нагрузка через воздушный поток: 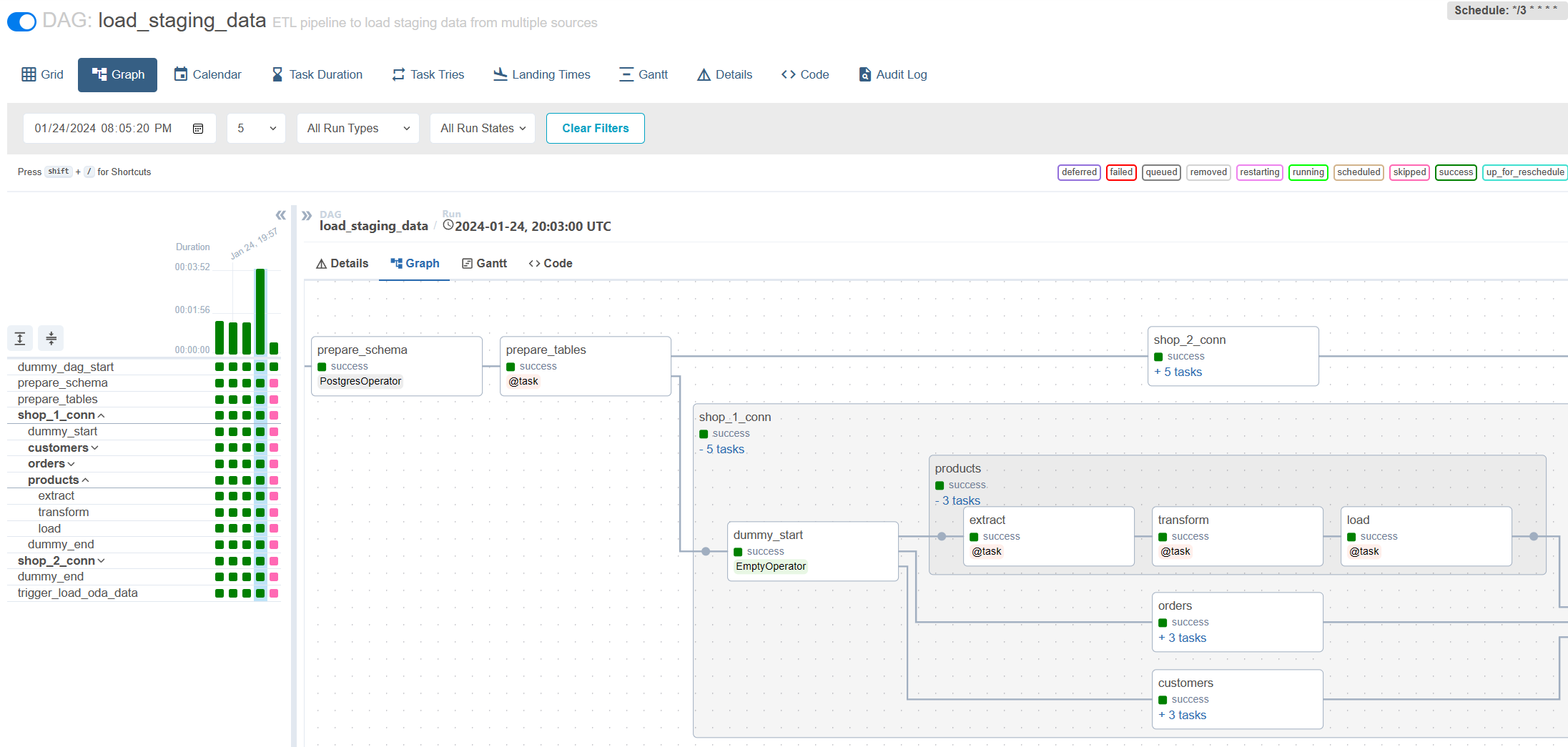
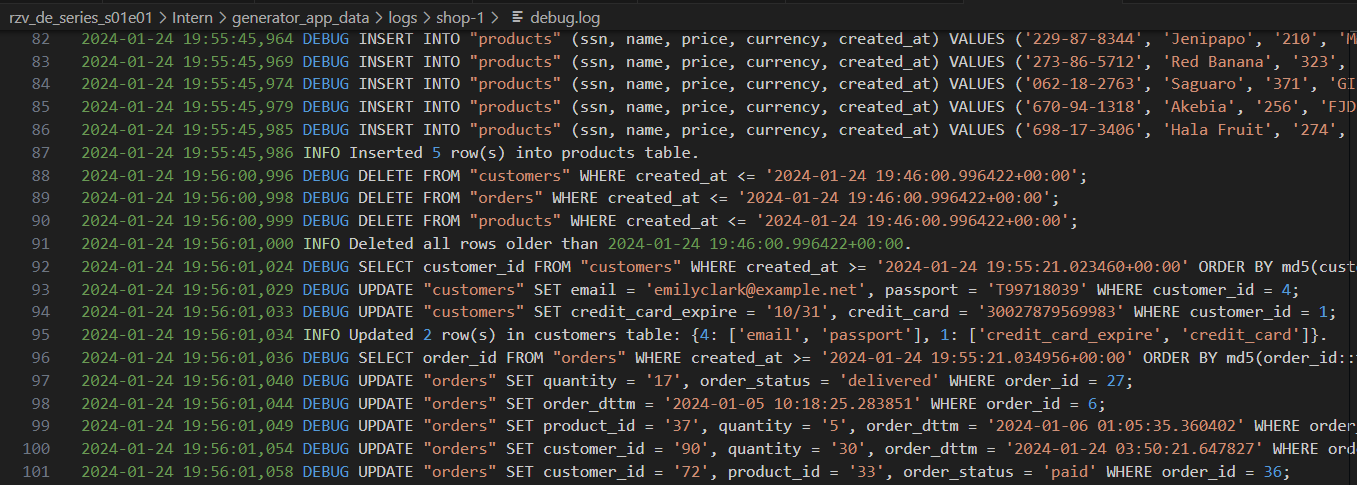
Генератор журналов с различными уровнями детализации: 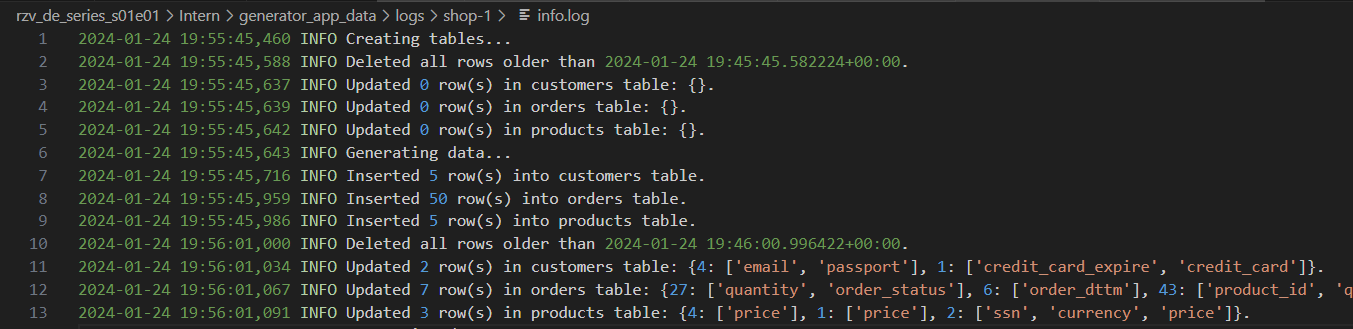
Полностью местная инфраструктура со всем необходимым: 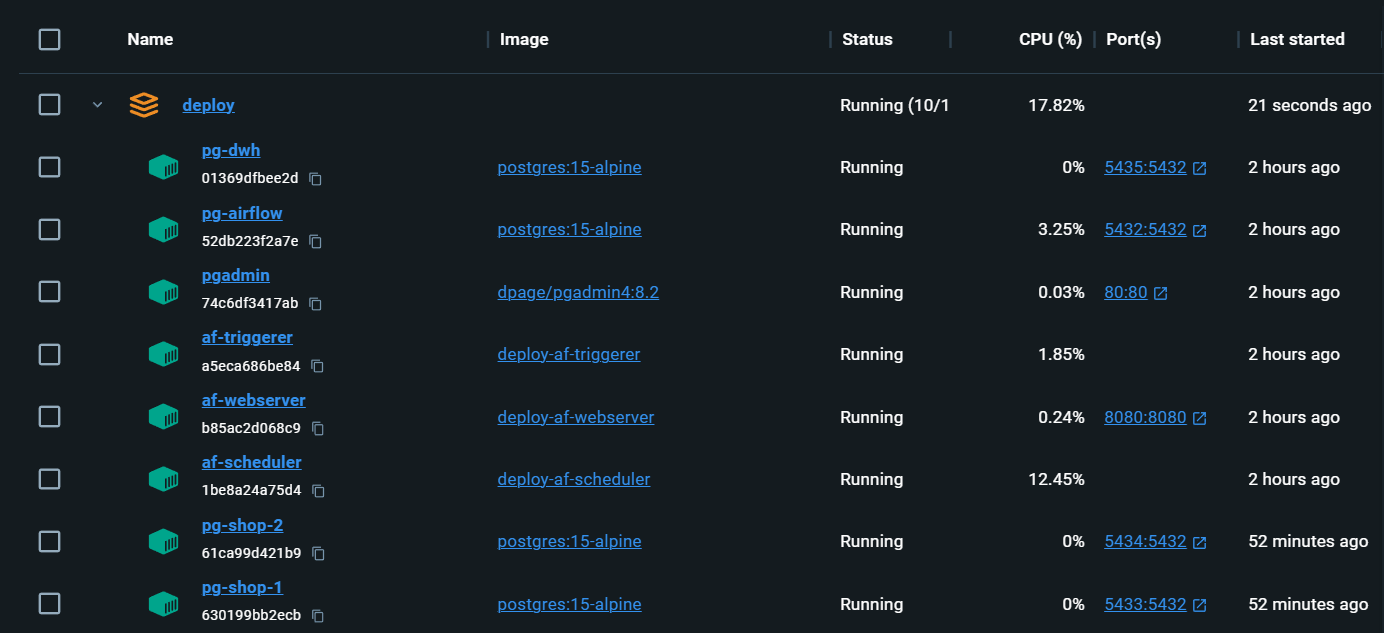
localhost:80/#/admin , войдите, затем вернитесь на главную страницу localhost/#/ docker compose up воздушный поток, повторно инициализируется. Даги сохраняются, но Connections и Variables должны быть снова заполнены. Aleksei Razvodov, инженер данных с более чем 5 -летним опытом работы в отрасли. Я стремлюсь передать свое понимание работы инженера -инженера и помочь тем, кто развивается на этом пути.
Если этот репозиторий помог вам, и вам понравилось, дайте ему и подпишитесь на социальные сети.



