rzv_data_engineering_series_s01e01
1.0.0

Hier ist eine offene Episode des Schulungskurs für RZV Data Engineering Series. Wählen Sie heute Abend aus, welche Serie Sie einschalten werden - eine, die Sie vom Leben ablenkt, oder eine, die Ihnen die Möglichkeit gibt, Fähigkeiten zu erlernen und zu schaffen!
Der Kurs geht in einem selbstgeprägten Format, die Infrastruktur wird lokal in Docker-Containern eingesetzt. Ich gehe davon aus, dass Sie nach Materialien suchen, um Ihre Fragen selbst zu beantworten und sie im allgemeinen Chat zu besprechen. Eine Lösung wird auf die Aufgabe auf mittlerer Ebene angewendet. Die Aufgaben sind in unterschiedliche Schwierigkeitsgrade unterteilt. Beginnen Sie mit dem Ort, an dem Sie sich am wohlsten fühlen, und arbeiten Sie sich nach oben. Je höher die Klasse, desto abstrakter ist die Problemaussage - es ist genau wie im Leben.
Die Fähigkeiten, die Sie während des Kurses erwerben, können fast mühelos in die Arbeitspraxis übertragen werden. Und im Gegensatz zu den meisten Kursen arbeiten Sie hier mit „Live“ -Daten, die in Echtzeit (in vereinfachter Weise) generiert werden. Am Ende der ersten Staffel der Serie können Sie in der Praxis Daten -Engineering -Probleme erleben und die Lösungen selbst schreiben.
Je weiter am Kurs, desto mehr Module werden nach der „Geschäftsentwicklung“ beigefügt:
PS Überprüfen Sie die übersetzten Readme.md -Versionen in der Wurzel der Hauptverzeichnisse: [Ru] ist verfügbar.
Dies ist die erste Episode, die über die Funktionen des inkrementellen Ladens durch Apache Airstrom abdeckt. Bei der Ausführung von Aufgaben auf mittlerer und älterer Ebene werden Sie auf viele Schwierigkeiten stoßen, die in der realen Arbeitspraxis vorhanden sind. Gleichzeitig werden Sie selbst Junior- und Praktikanten in neue Konzepte vorstellen und Sie schrittweise auf komplexere Aufgaben vorbereiten.
Ich ermutige Sie, zuerst zu versuchen, das Problem selbst zu lösen und dann meine Version zu betrachten.
Sie werden lernen:
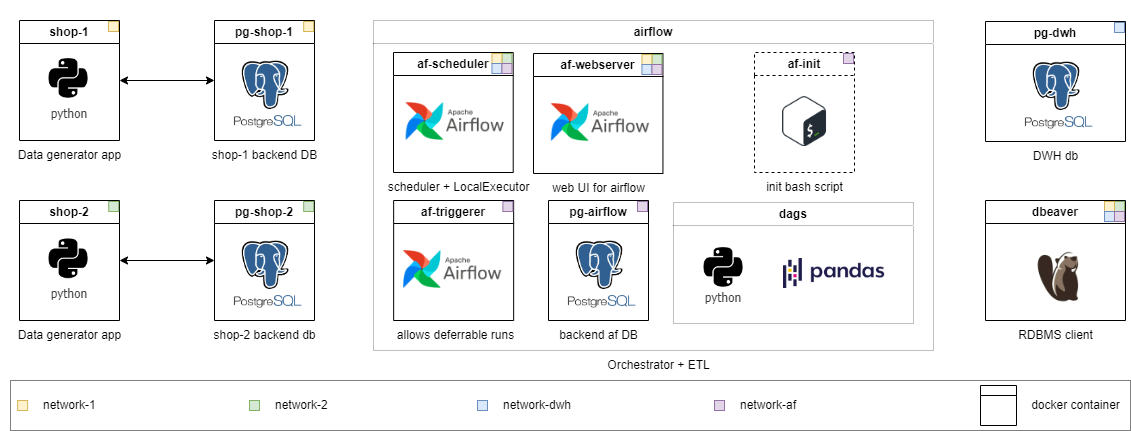
Jede Ebene hat ein eigenes Verzeichnis. Mit jeder Stufe reduziere ich die Menge an befristeten Code und erhöht die Komplexität der Aufgabe. Der Inhalt der Verzeichnisse ist etwas unterschiedlich, aber die Infrastruktur ist überall einsatzbereit. Detaillierte Aufgaben sind in README.md jeder Klasse beschrieben. Wählen Sie Ihre aus und können Sie bei Bedarf das Level senken.
Auszubildender : Alle Code wurde bereits für das Middle -Grade -Problem implementiert. Starten Sie einfach und erkunden Sie es. Sie können auch Notizen finden, die erklären, warum ich die Lösung auf diese Weise implementiert habe.
Praktikant : Erweitern Sie die vorhandene Konfiguration, damit die schriftliche DAG Daten aus einer neuen Quelle und neuen Tabellen lädt. Schreiben Sie eine einfache DAG für die Arbeit mit dem Dateisystem, um temporäre Dateien mithilfe von Bashoperator aufzuräumen.
Junior : Schreiben Sie inkrementelles Laden ohne Berücksichtigung des historischen Speichers. Die Daten auf der Quelle werden nicht aktualisiert.
Mitte : Schreiben Sie eine inkrementelle Last in SCD2 -Tabellen. Bitte beachten Sie, dass die Daten an der Quelle aktualisiert werden können.
Senior : Zuordnung wie für Middle + Setup Write-Edual-Publish-Muster, um die Datenqualität zu gewährleisten und Lasttests der schriftlichen Lösung durchzuführen.
Historische Datenspeicherung mit SCD2: 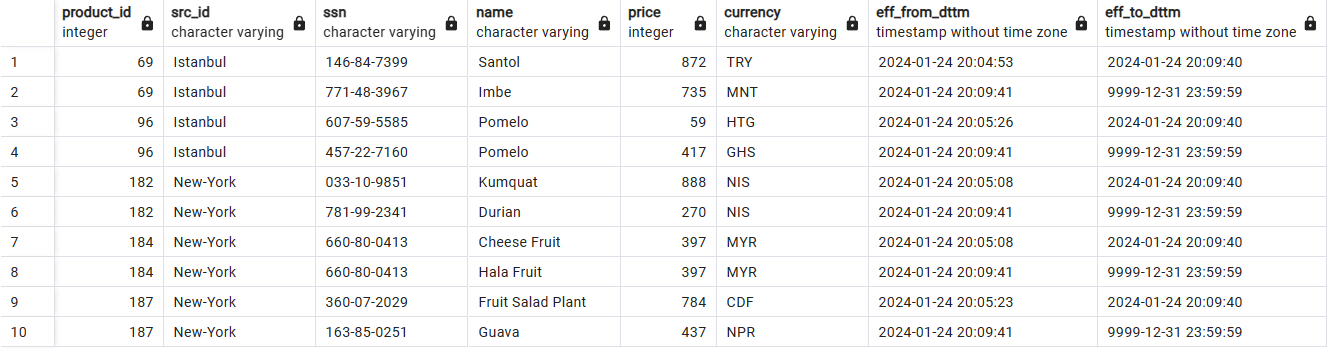
Inkrementelle Belastung über den Luftstrom: 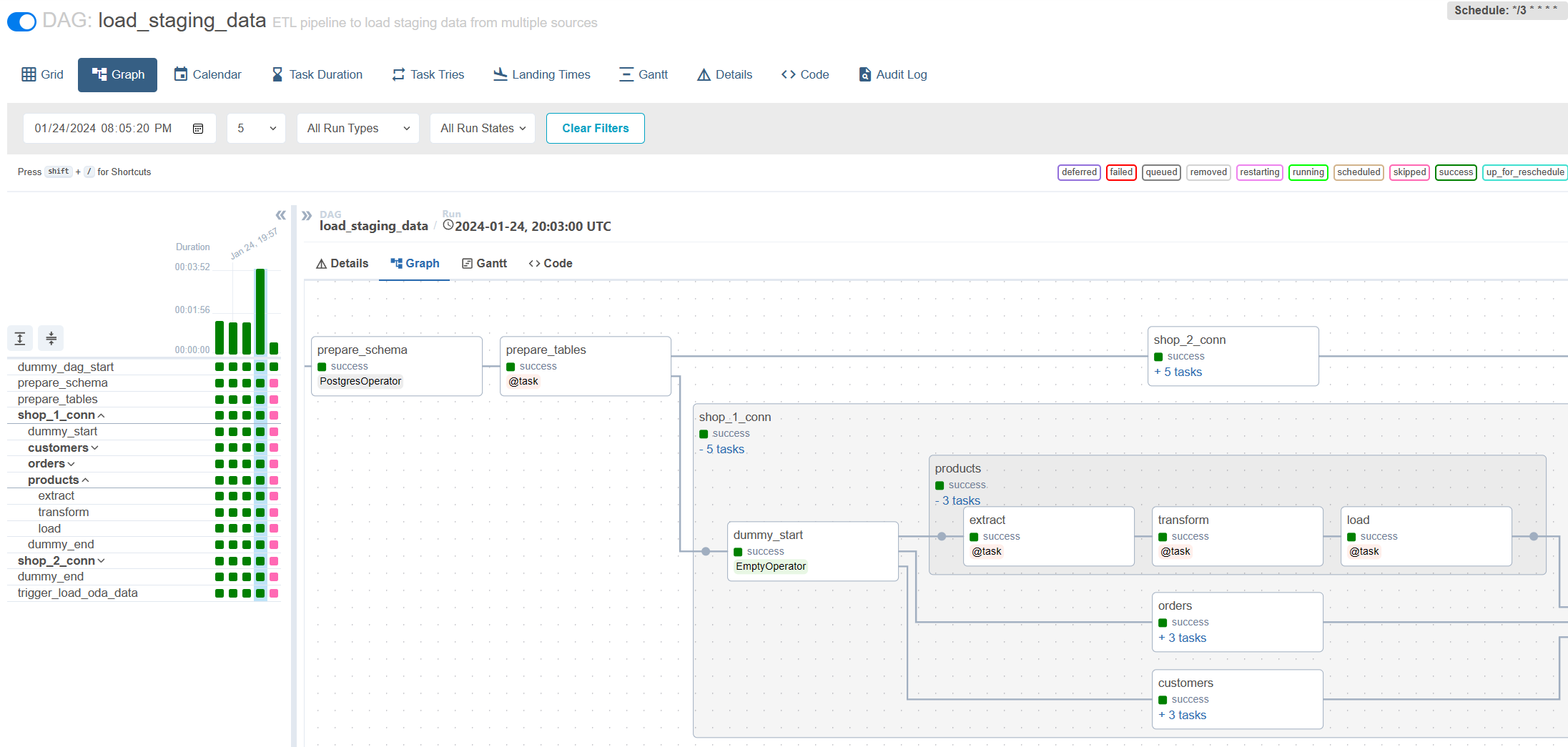
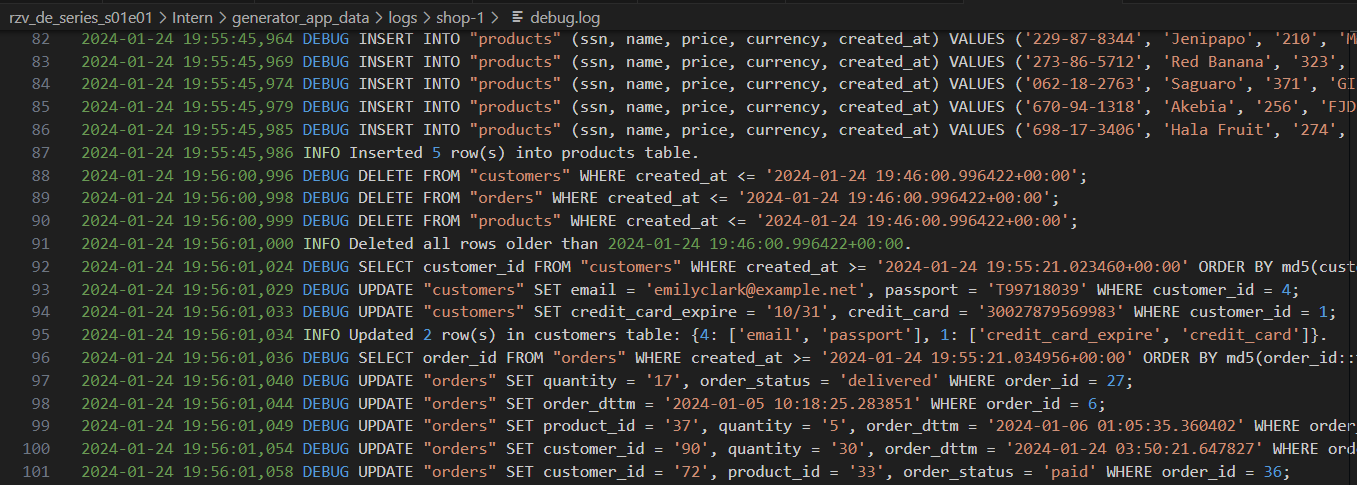
Generatorprotokolle mit unterschiedlichem Detailniveau: 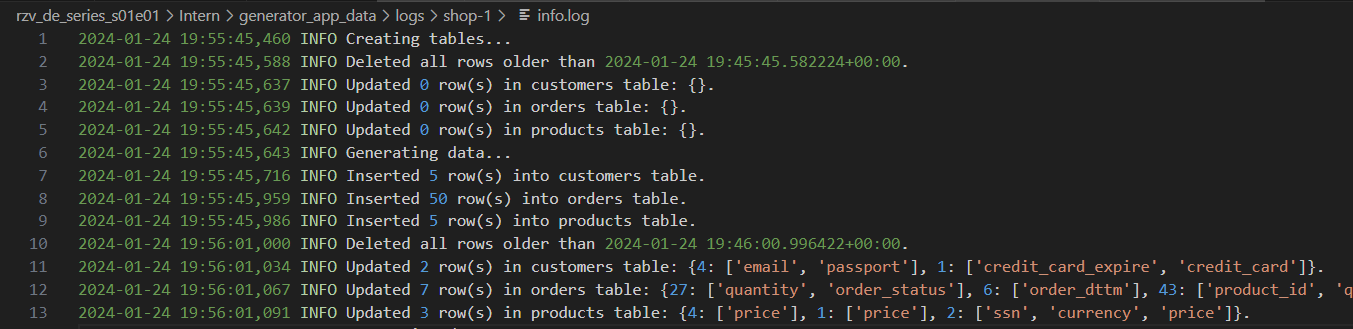
Ganz lokale Infrastruktur mit allem, was Sie brauchen: 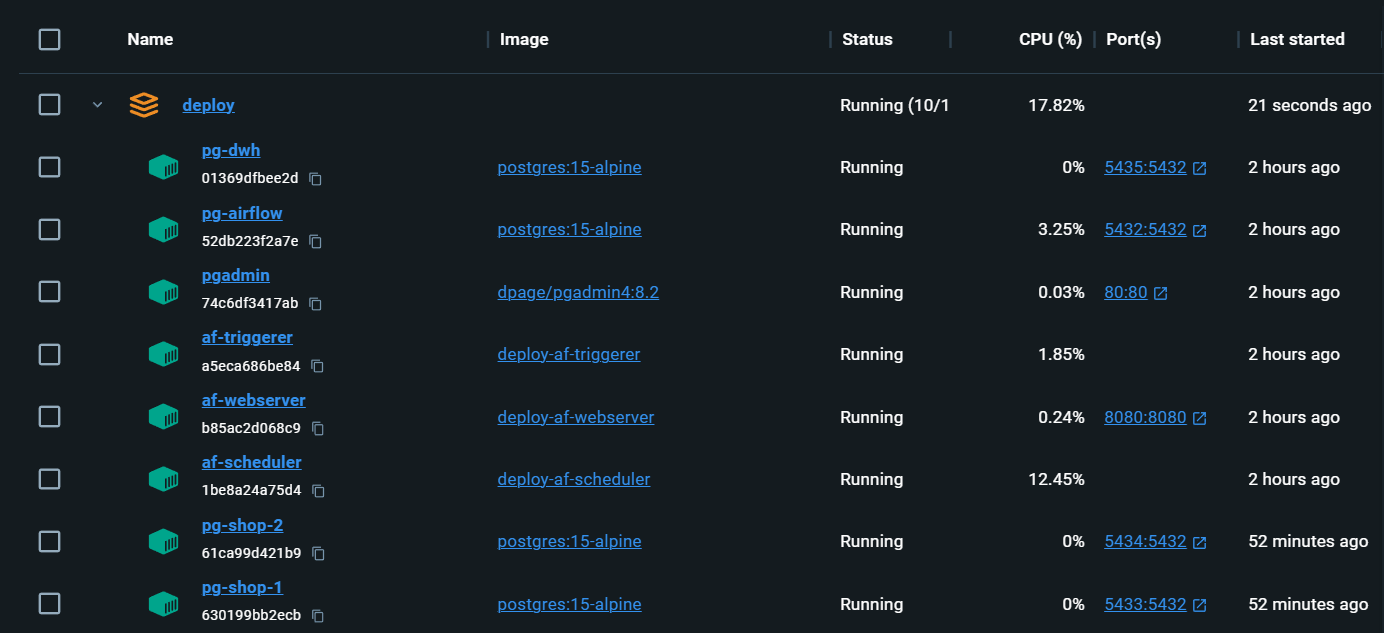
localhost:80/#/admin , melden Sie sich an und kehren Sie dann zur Hauptseite localhost/#/ zurück zurück docker compose up wird der Luftstrom erneut initialisiert. Die DAGs werden gespeichert, aber Connections und Variables müssen erneut ausgefüllt werden. Aleksei Razvodov, Dateningenieur mit mehr als 5 Jahren Erfahrung in der Branche. Ich bemühe mich, mein Verständnis der Arbeit eines Dateningenieurs zu vermitteln und denen zu helfen, die sich auf diesem Weg entwickeln.
Wenn dieses Repository Ihnen geholfen hat und es Ihnen gefallen hat, geben Sie es ein und abonnieren Sie die sozialen Netzwerke.



