rzv_data_engineering_series_s01e01
1.0.0

Here is an open episode of the rzv Data engineering series training course. Choose which series you will turn on tonight - one that will distract you from life, or one that will give you the opportunity to learn skills and create!
The course is going in a self-paced format, the infrastructure is deployed locally in Docker containers. I expect that you will look for materials to answer your questions on your own and discuss them in the general chat. A solution is applied to the task at the Middle level. The tasks are divided into different difficulty levels. Start with where you feel most comfortable and work your way up. The higher the grade, the more abstract the problem statement -- it’s just like in life.
The skills you acquire during the course can be transferred to work practice almost effortlessly. And, unlike most courses, here you work with “live” data that is generated in real time (in a simplified manner). By the end of the first season of the series, you will be able to experience data engineering problems in practice and write the solutions yourself.
The further along the course, the more modules will be attached following the “business development”:
p.s. Check the translated readme.md versions in the root of main directories: [ru] is available.
This is the first episode covering the features of incremental loading through Apache Airflow. In the process of performing tasks at the Middle and Senior level, you will encounter many difficulties that exist in real work practice. At the same time, even Junior and Intern tasks will introduce you to new concepts and gradually prepare you for more complex tasks.
I encourage you to first try to solve the problem yourself, and then look at my version.
You will learn:
Each level has its own directory. With each level I reduce the amount of ready-to-run code and raise the task's complexity. The contents of the directories are slightly different, but the infrastructure is ready for use everywhere. Detailed tasks are described in README.md of each grade. Choose yours and feel free to lower the level if necessary.
Trainee: All code has already been implemented for the middle grade problem. Just launch and explore it. Also you can find notes explaining why I've implemented the solution this way.
Intern: Extend the existing configuration so that the written DAG starts loading data from a new source and new tables. Write a simple dag for working with the file system to clean-up temporary files using BashOperator.
Junior: Write incremental loading without taking into account historical storage. The data on the source is not updated.
Middle: Write an incremental load into SCD2 tables. Please note that the data may be updated at the source.
Senior: Assignment as for Middle + setup Write-Audit-Publish pattern to ensure data quality and conduct load testing of the written solution.
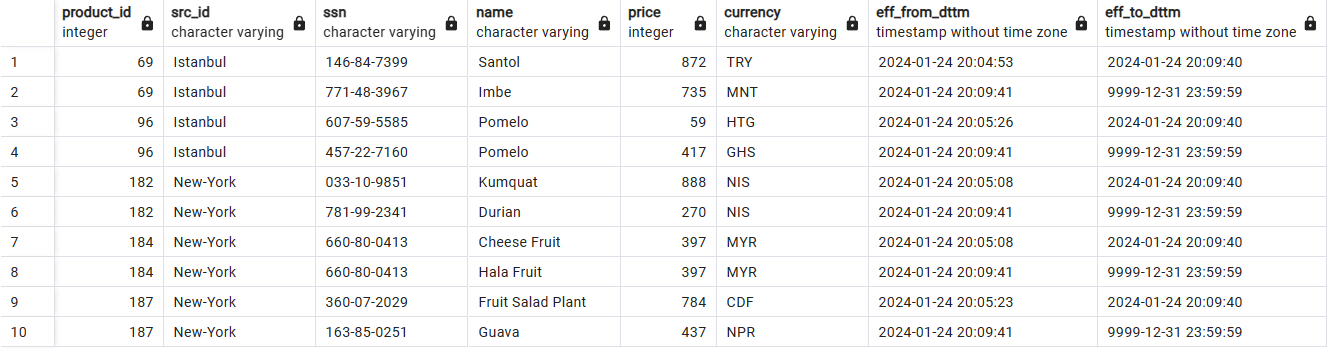
Historical data storage with SCD2:
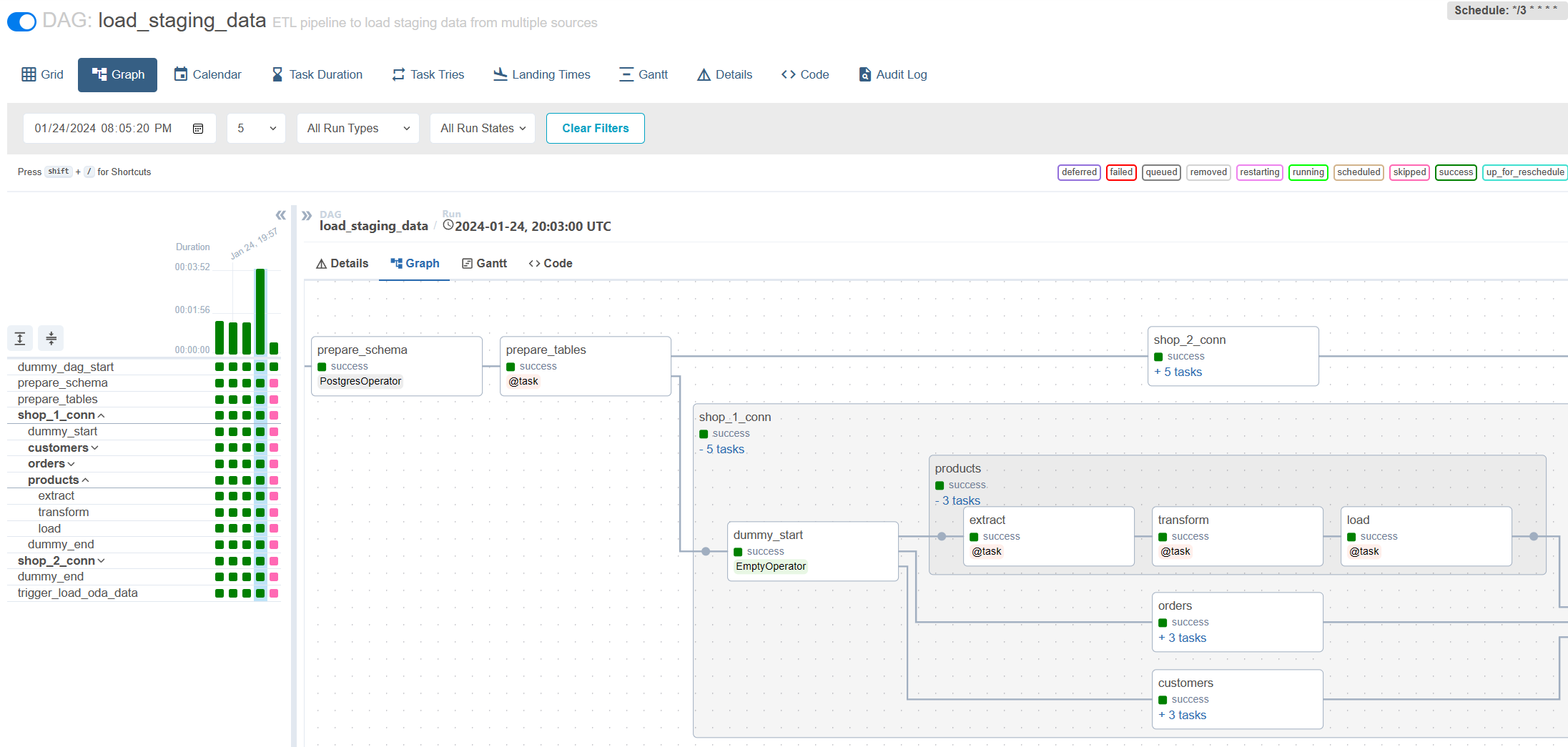
Incremental loading via Airflow:
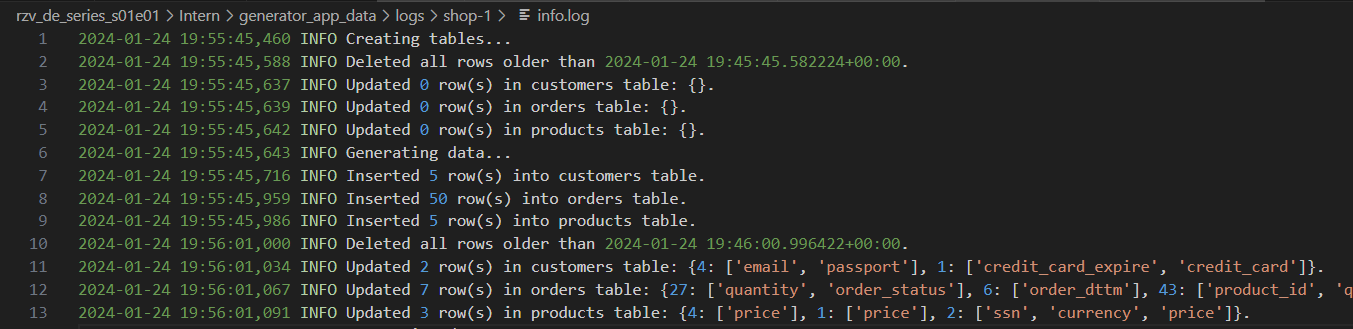
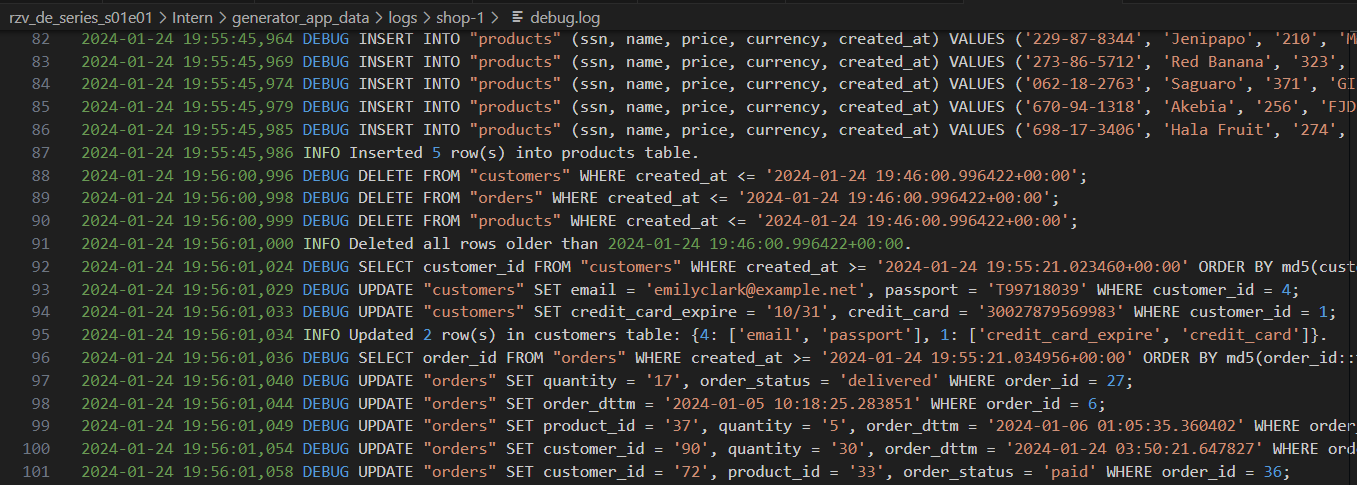
Generator logs with varying levels of detail:
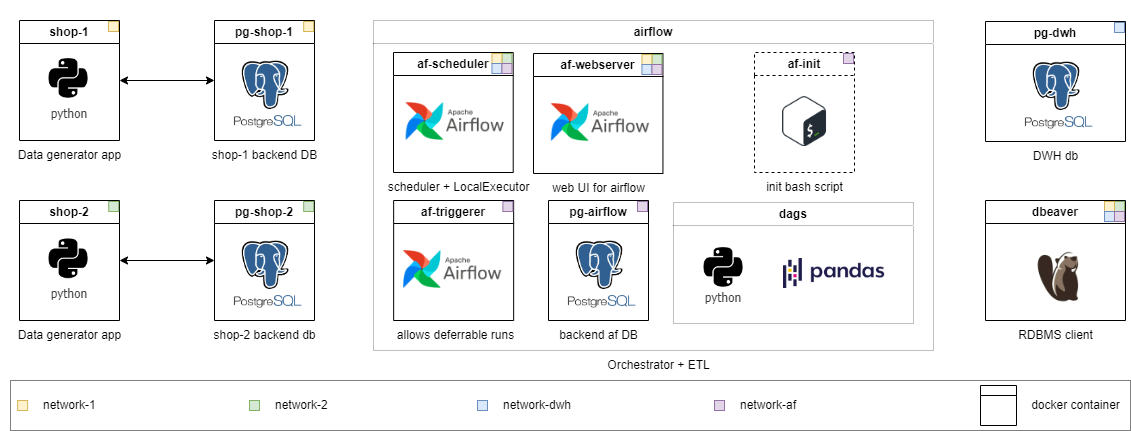
Completely local infrastructure with everything you need:
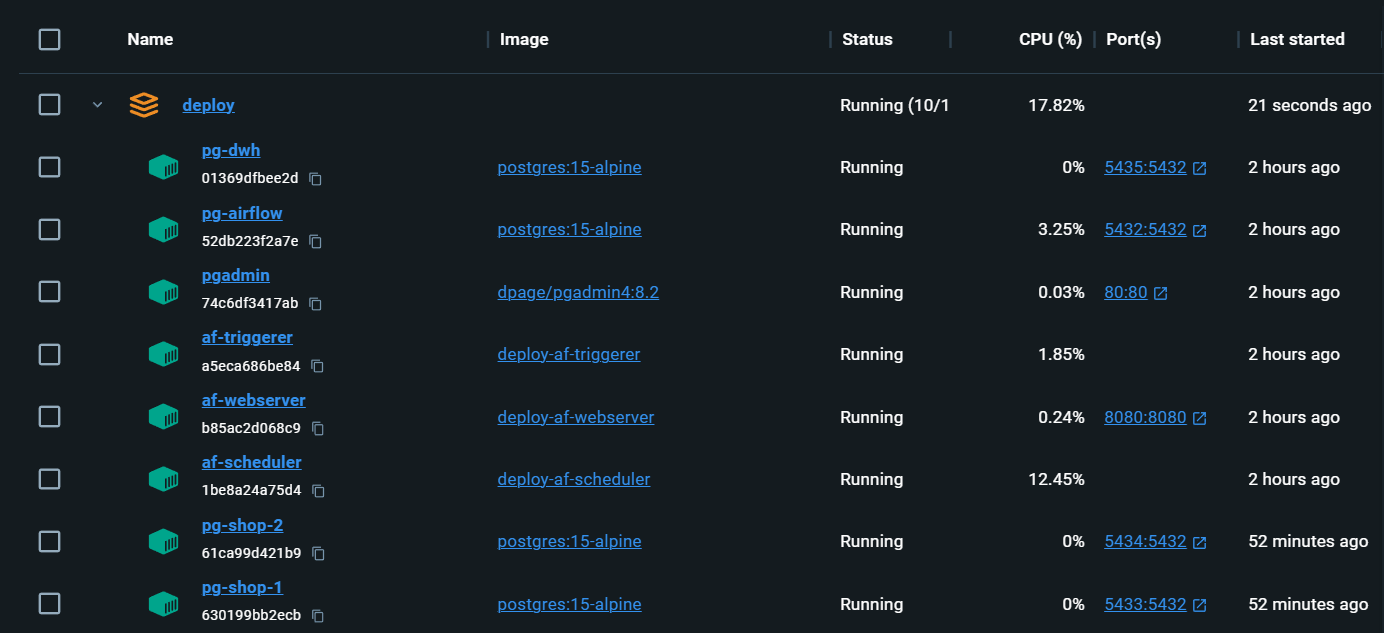
localhost:80/#/admin, log in, then go back to the main page localhost/#/docker compose up airflow is re-initialized. The dags are saved, but Connections and Variables need to be filled-in again.Aleksei Razvodov, Data engineer with 5+ years of experience in the industry. I strive to convey my understanding of the work of a data engineer and help those who are developing along this path.
If this repository helped you and you liked it, give it a and subscribe to the social networks.



