rzv_data_engineering_series_s01e01
1.0.0

Voici un épisode ouvert du cours de formation de la série RZV Data Engineering. Choisissez la série que vous allez activer ce soir - une série qui vous distrait de la vie, ou une série qui vous donnera l'occasion d'apprendre des compétences et de créer!
Le cours se déroule dans un format auto-rythmé, l'infrastructure est déployée localement dans des conteneurs Docker. Je m'attends à ce que vous recherchiez du matériel pour répondre par vous-même à vos questions et en discutez-en dans le chat général. Une solution est appliquée à la tâche au niveau intermédiaire. Les tâches sont divisées en différents niveaux de difficulté. Commencez par où vous vous sentez le plus à l'aise et progressez. Plus la note est élevée, plus la déclaration de problème est abstraite - c'est comme dans la vie.
Les compétences que vous acquérez pendant le cours peuvent être transférées à la pratique du travail presque sans effort. Et, contrairement à la plupart des cours, vous travaillez ici avec des données «en direct» générées en temps réel (de manière simplifiée). À la fin de la première saison de la série, vous pourrez rencontrer des problèmes d'ingénierie des données dans la pratique et écrire les solutions vous-même.
Plus le cours, plus les modules seront attachés après le «développement des affaires»:
PS Vérifiez les versions ReadMe.md traduites à la racine des répertoires principaux: [RU] est disponible.
Il s'agit du premier épisode couvrant les caractéristiques de la charge incrémentielle via le flux d'air Apache. Dans le processus d'exécution des tâches au niveau intermédiaire et senior, vous rencontrerez de nombreuses difficultés qui existent dans la pratique réelle du travail. Dans le même temps, même les tâches juniors et stagiaires vous présenteront de nouveaux concepts et vous prépareront progressivement à des tâches plus complexes.
Je vous encourage à essayer d'abord de résoudre le problème vous-même, puis à regarder ma version.
Vous apprendrez:
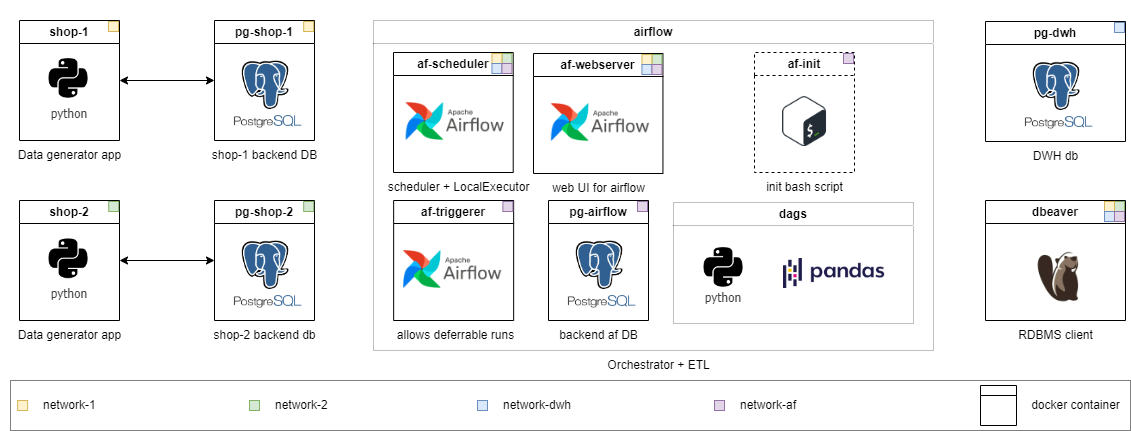
Chaque niveau a son propre répertoire. À chaque niveau, je réduit la quantité de code prêt à l'emploi et augmente la complexité de la tâche. Le contenu des répertoires est légèrement différent, mais l'infrastructure est prête à être utilisée partout. Les tâches détaillées sont décrites dans README.md de chaque grade. Choisissez le vôtre et n'hésitez pas à abaisser le niveau si nécessaire.
STADENE : Tout le code a déjà été mis en œuvre pour le problème de niveau intermédiaire. Il suffit de le lancer et d'explorer. Vous pouvez également trouver des notes expliquant pourquoi j'ai implémenté la solution de cette façon.
Stagiaire : étendez la configuration existante afin que le DAG écrit commence à charger des données à partir d'une nouvelle source et de nouvelles tables. Écrivez un DAG simple pour travailler avec le système de fichiers pour nettoyer les fichiers temporaires à l'aide de bashoperator.
Junior : Écrivez un chargement incrémentiel sans prendre en compte le stockage historique. Les données sur la source ne sont pas mises à jour.
Milieu : Écrivez une charge incrémentielle dans les tables SCD2. Veuillez noter que les données peuvent être mises à jour à la source.
Senior : Affectation comme pour le modèle Middle + Configuration de l'écriture d'écriture de l'écriture pour garantir la qualité des données et effectuer des tests de charge de la solution écrite.
Stockage de données historique avec SCD2: 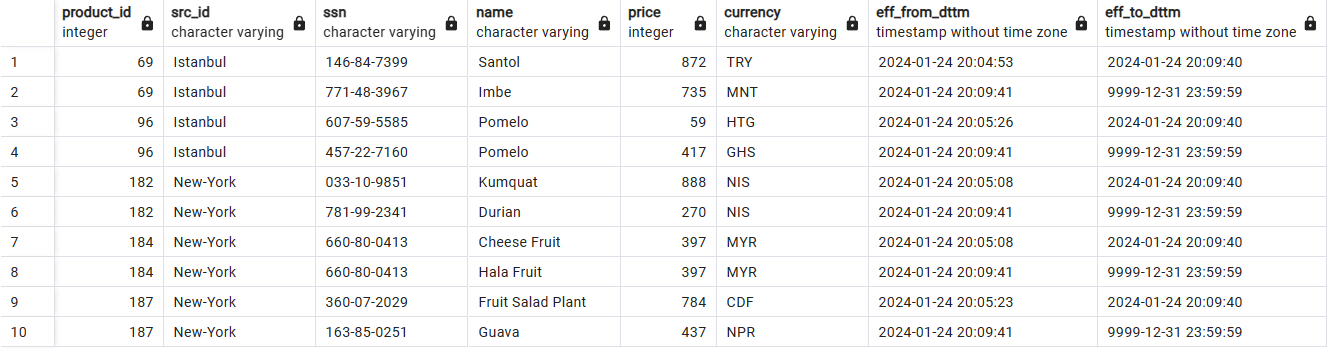
Charge incrémentielle via le flux d'air: 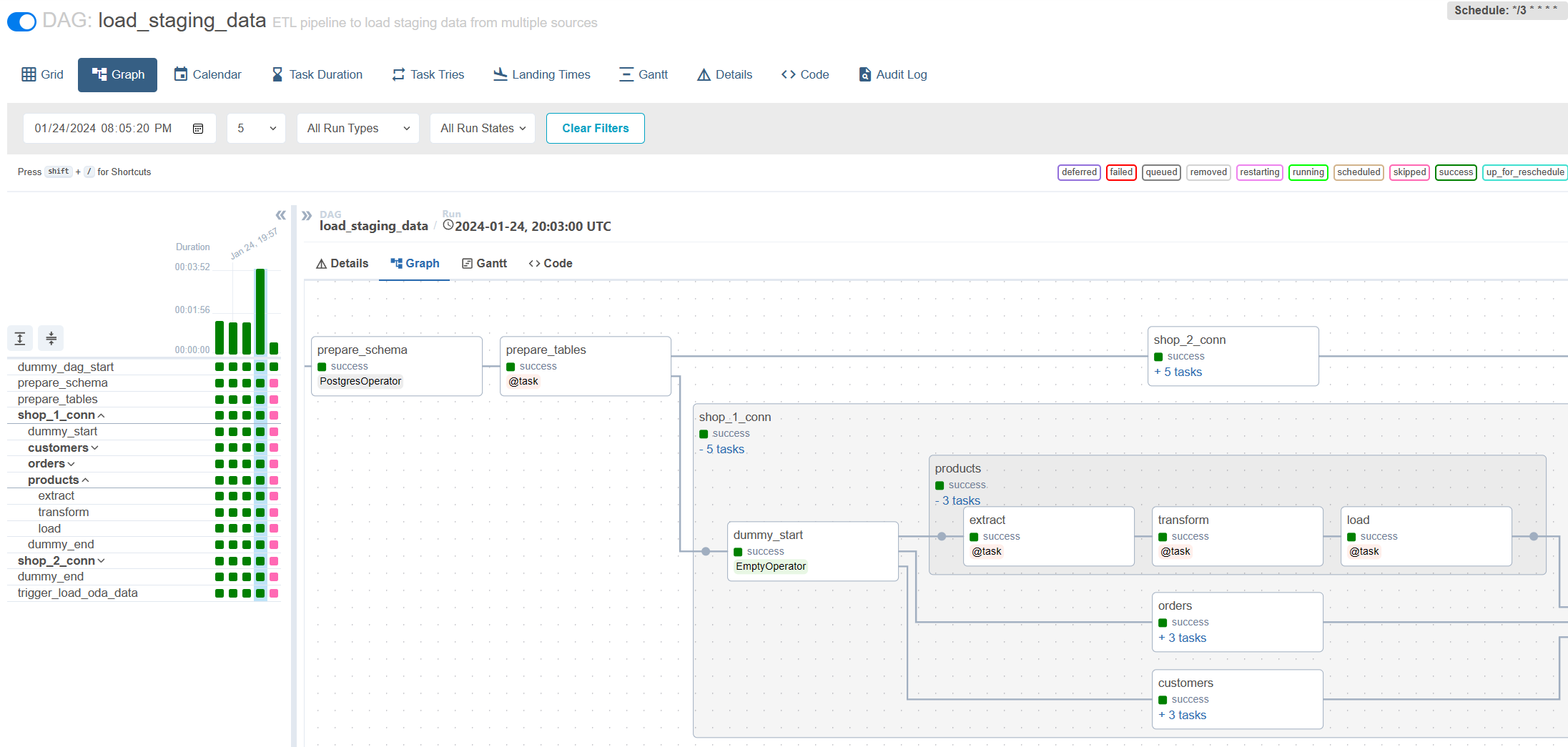
Journaux du générateur avec différents niveaux de détail: 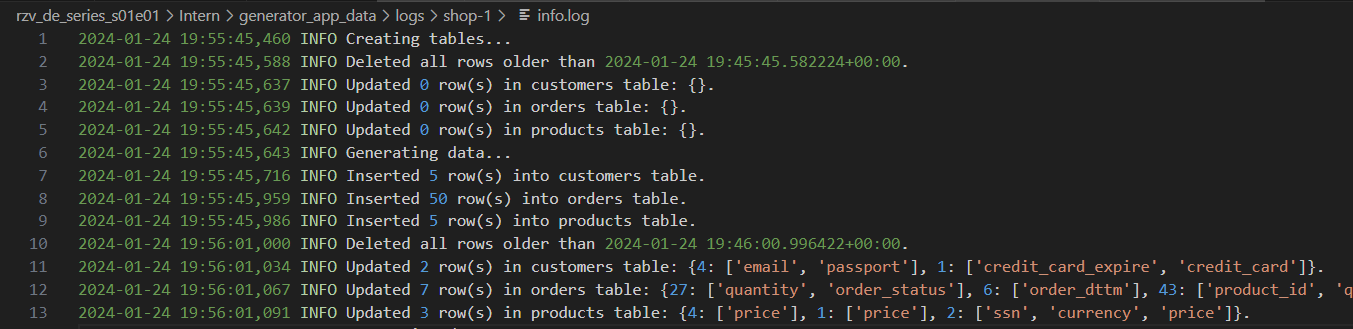
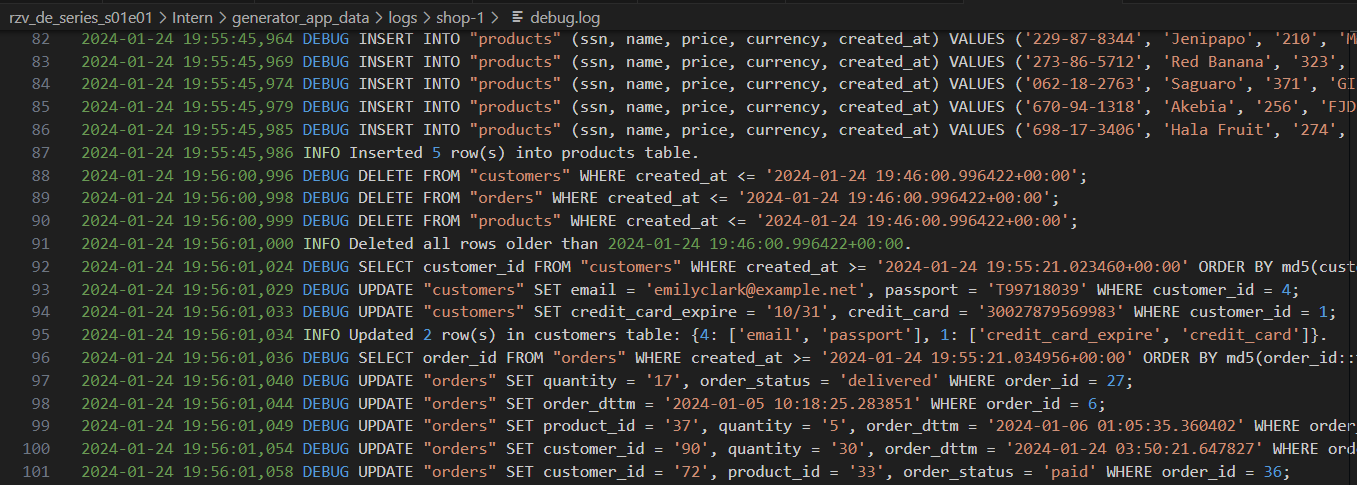
Infrastructure entièrement locale avec tout ce dont vous avez besoin: 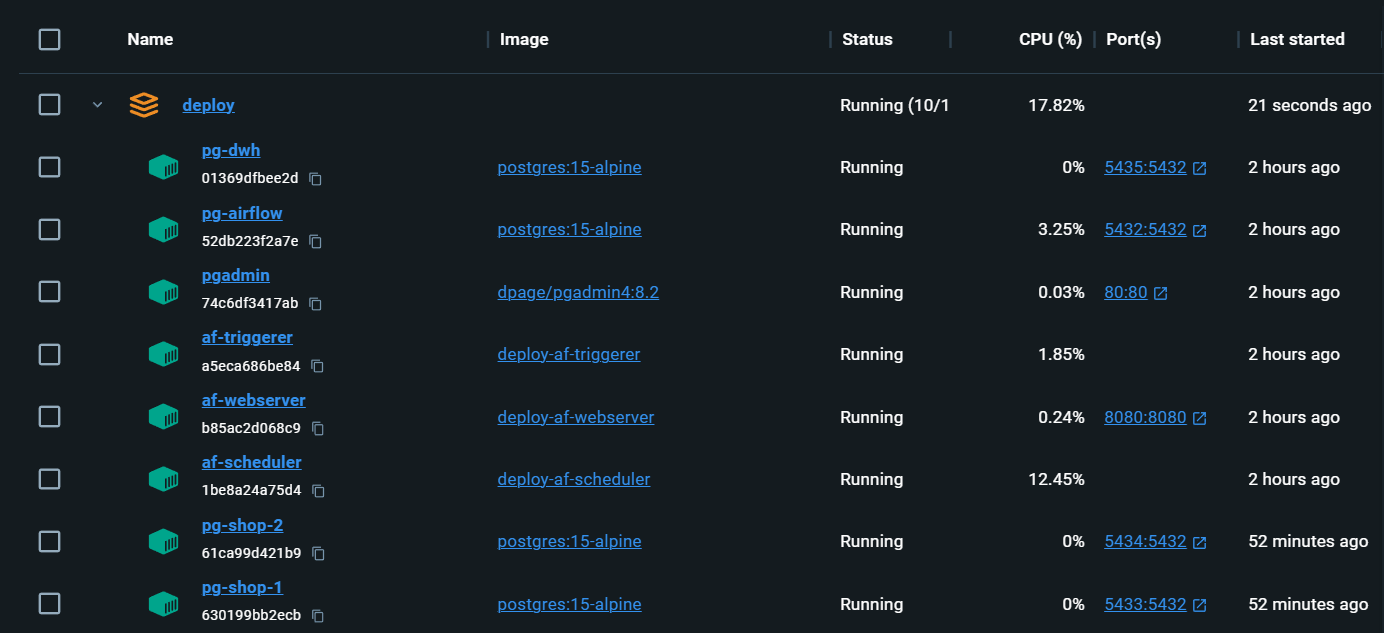
localhost:80/#/admin , connectez-vous, puis revenez à la page principale localhost/#/ docker compose up du flux d'air est réinitialisée. Les Dags sont enregistrés, mais Connections et Variables doivent être remplies à nouveau. Aleksei Razvodov, ingénieur de données avec plus de 5 ans d'expérience dans l'industrie. Je m'efforce de transmettre ma compréhension du travail d'un ingénieur de données et d'aider ceux qui se développent sur cette voie.
Si ce référentiel vous a aidé et vous l'avez aimé, donnez-le et abonnez-vous aux réseaux sociaux.



