rzv_data_engineering_series_s01e01
1.0.0

Aqui está um episódio aberto do curso de treinamento da série de engenharia de dados da RZV. Escolha qual série você ligará hoje à noite - que o distrairá da vida ou que lhe dará a oportunidade de aprender habilidades e criar!
O curso está em um formato de ritmo próprio, a infraestrutura é implantada localmente em contêineres do Docker. Espero que você procure materiais para responder suas perguntas por conta própria e discuti -las no bate -papo geral. Uma solução é aplicada à tarefa no nível médio. As tarefas são divididas em diferentes níveis de dificuldade. Comece com onde você se sente mais confortável e trabalhe. Quanto maior a nota, mais abstrata a afirmação do problema - é exatamente como na vida.
As habilidades que você adquire durante o curso podem ser transferidas para a prática de trabalho quase sem esforço. E, diferentemente da maioria dos cursos, aqui você trabalha com dados "ao vivo" que são gerados em tempo real (de maneira simplificada). No final da primeira temporada da série, você poderá enfrentar problemas de engenharia de dados na prática e escrever as soluções.
Quanto mais adiante, mais módulos serão anexados após o "desenvolvimento de negócios":
PS Verifique as versões readme.md traduzidas na raiz dos diretórios principais: [RU] está disponível.
Este é o primeiro episódio que abrange os recursos da carga incremental através do fluxo de ar Apache. No processo de executar tarefas no nível médio e sênior, você encontrará muitas dificuldades que existem na prática real de trabalho. Ao mesmo tempo, mesmo as tarefas juniores e estagiárias apresentarão novos conceitos e gradualmente o prepararão para tarefas mais complexas.
Encorajo você a primeiro tentar resolver o problema e depois olhar para minha versão.
Você vai aprender:
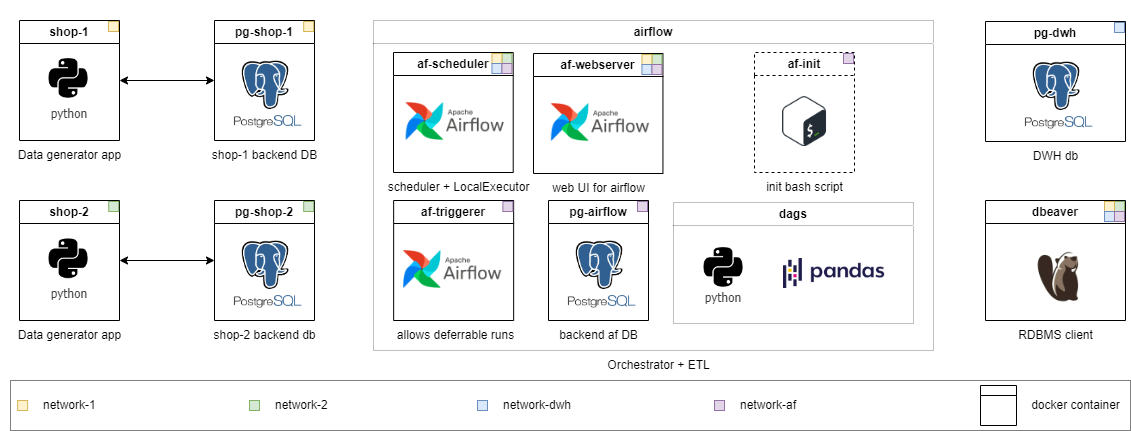
Cada nível tem seu próprio diretório. Com cada nível, reduzi a quantidade de código pronto para executar e aumentar a complexidade da tarefa. O conteúdo dos diretórios é um pouco diferente, mas a infraestrutura está pronta para uso em todos os lugares. Tarefas detalhadas são descritas no README.md de cada série. Escolha o seu e sinta -se à vontade para diminuir o nível, se necessário.
Treinee : Todo o código já foi implementado para o problema de nível médio. Basta lançá -lo e explorar. Além disso, você pode encontrar notas explicando por que implementei a solução dessa maneira.
Estagiário : estenda a configuração existente para que o DAG escrito comece a carregar dados de uma nova fonte e novas tabelas. Escreva um DAG simples para trabalhar com o sistema de arquivos para limpar arquivos temporários usando o Bashoperator.
Junior : Escreva o carregamento incremental sem levar em consideração o armazenamento histórico. Os dados da fonte não são atualizados.
Médio : Escreva uma carga incremental nas tabelas SCD2. Observe que os dados podem ser atualizados na fonte.
Senior : Tarefa como para o Middle + Setup Write-Audit-Publish Pattern para garantir a qualidade dos dados e conduzir testes de carga da solução escrita.
Armazenamento de dados históricos com SCD2: 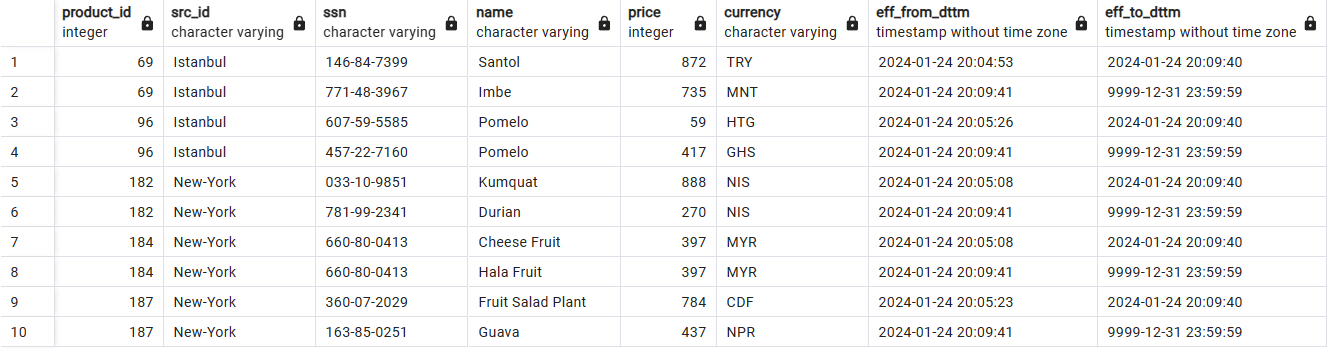
Carga incremental via fluxo de ar: 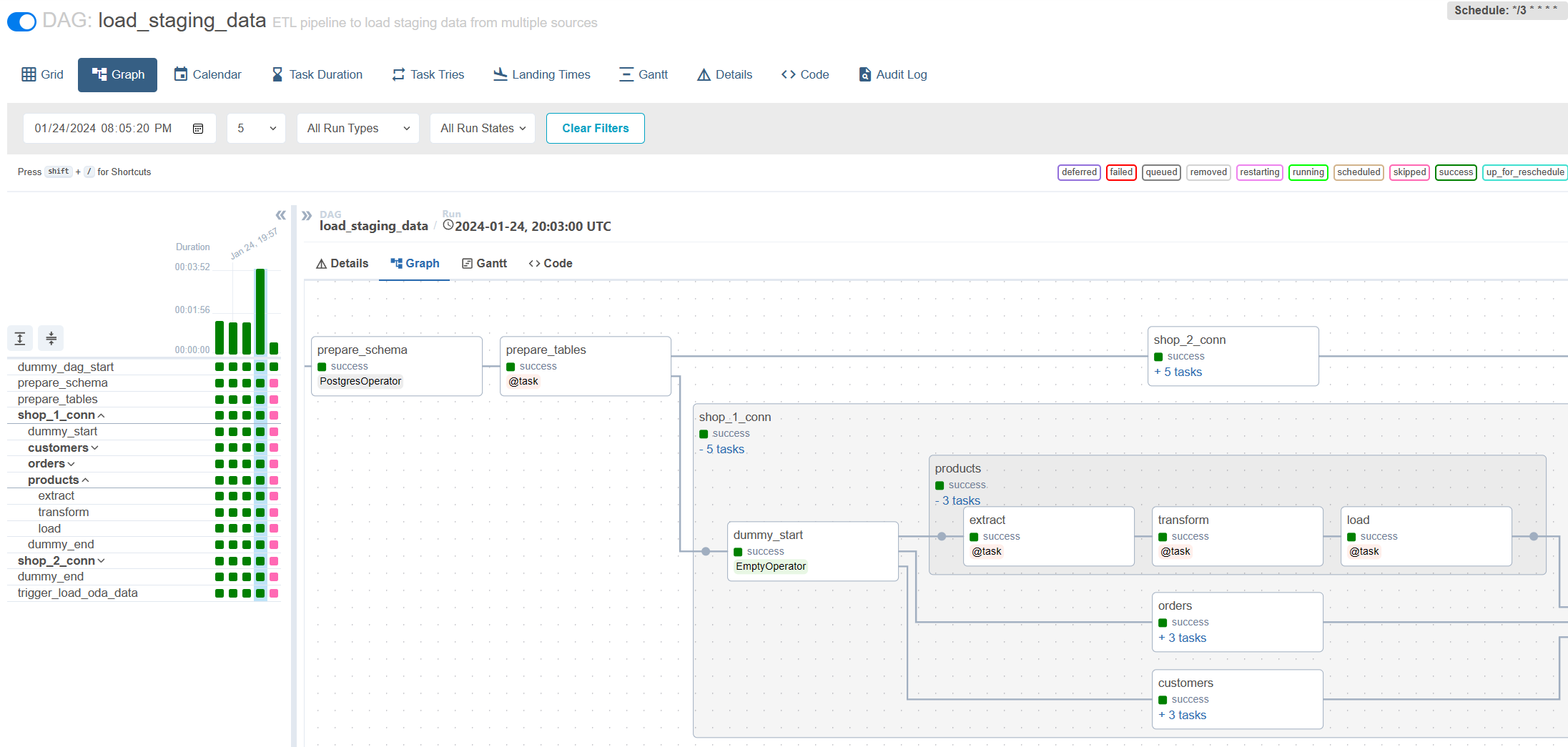
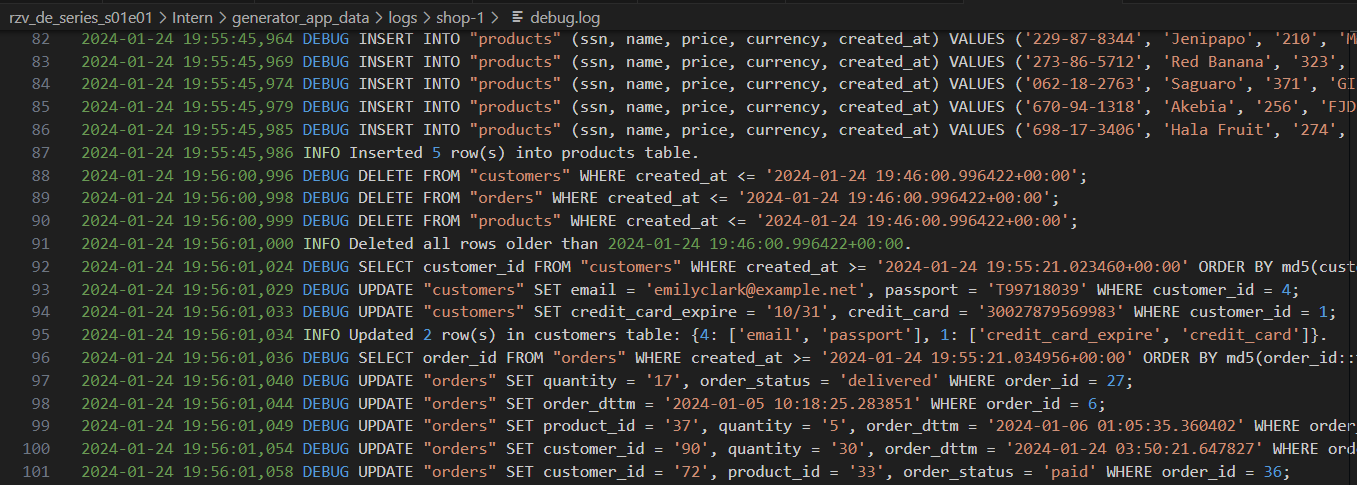
Toras geradoras com níveis variados de detalhes: 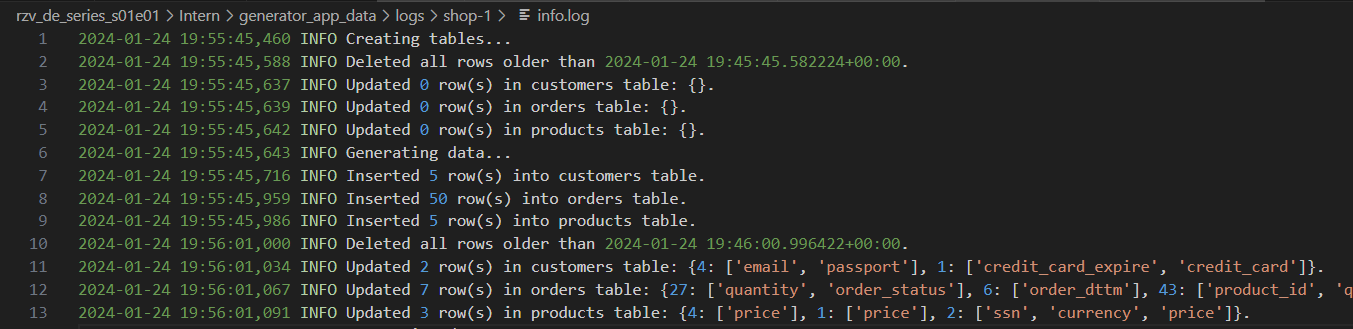
Infraestrutura completamente local com tudo o que você precisa: 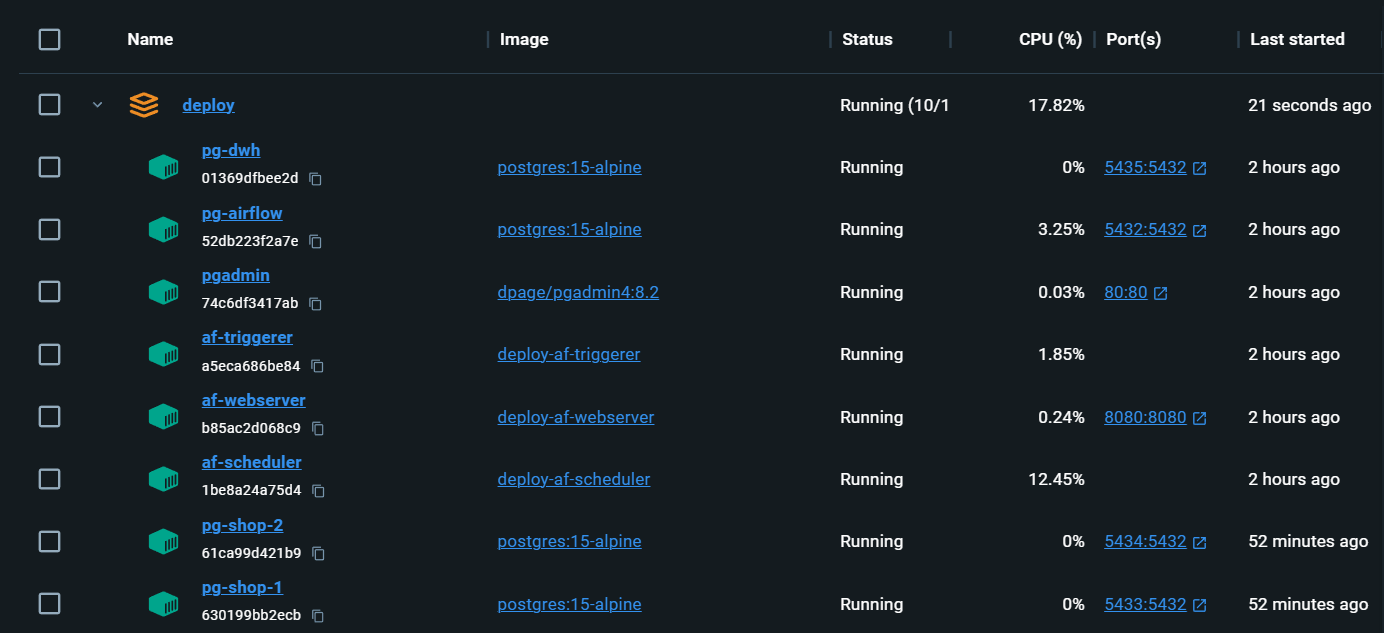
localhost:80/#/admin , faça login e depois volte para a página principal localhost/#/ docker compose up o fluxo de ar é reinicializado. Os DAGs são salvos, mas Connections e Variables precisam ser preenchidas novamente. Aleksei Razvodov, engenheiro de dados com mais de 5 anos de experiência no setor. Eu me esforço para transmitir minha compreensão do trabalho de um engenheiro de dados e ajudar aqueles que estão se desenvolvendo nesse caminho.
Se esse repositório ajudou você e você gostou, dê um e assine as redes sociais.



