rzv_data_engineering_series_s01e01
1.0.0

これは、RZVデータエンジニアリングシリーズトレーニングコースのオープンエピソードです。今夜どのシリーズをオンにするかを選択してください。人生から気を散らすもの、またはスキルを学び、創造する機会を与えるものを選択してください!
コースは自己ペースの形式で行われ、インフラストラクチャはDockerコンテナにローカルに展開されます。自分で質問に答え、一般的なチャットで話し合うための資料を探すことを期待しています。ソリューションは、中間レベルのタスクに適用されます。タスクは異なる難易度に分割されます。あなたが最も快適に感じるところから始めて、あなたの道を歩んでください。グレードが高いほど、問題のステートメントが抽象的です。それは人生のようなものです。
コース中に獲得したスキルは、作業練習にほとんど楽に移動できます。そして、ほとんどのコースとは異なり、ここでは、リアルタイムで生成される(単純化された方法で)生成される「ライブ」データを使用します。シリーズの最初のシーズンの終わりまでに、実際にデータエンジニアリングの問題を経験し、自分でソリューションを書くことができます。
コースに沿って遠くなるほど、「ビジネス開発」に続いてより多くのモジュールが添付されます。
PSメインディレクトリのルートで翻訳されたreadme.mdバージョンを確認してください:[ru]が利用可能です。
これは、Apache気流を介した増分荷重の特徴をカバーする最初のエピソードです。中期および上級レベルでタスクを実行する過程で、実際の練習に存在する多くの困難に遭遇します。同時に、ジュニアタスクとインターンタスクでさえ、新しい概念を紹介し、より複雑なタスクに徐々に準備します。
最初に自分で問題を解決してから、私のバージョンを見ることをお勧めします。
あなたは学ぶでしょう:
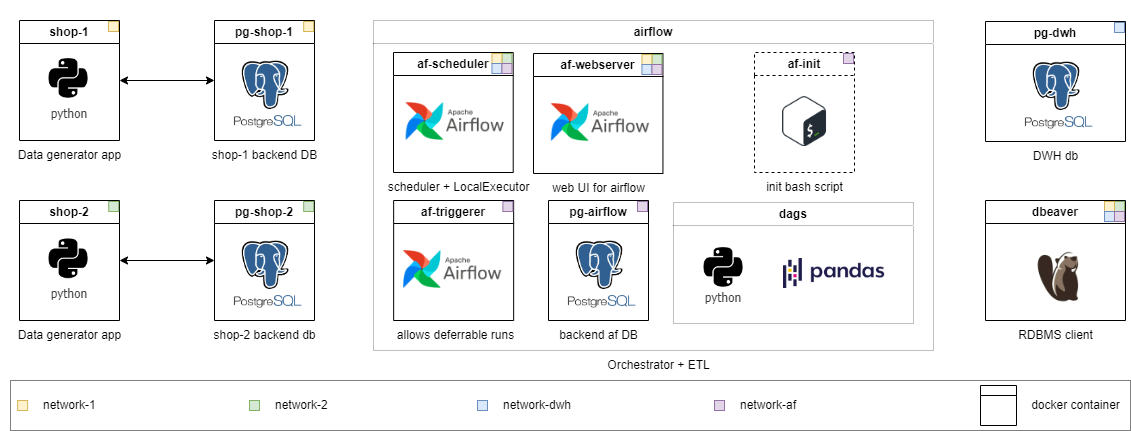
各レベルには独自のディレクトリがあります。各レベルでは、すぐに実行できるコードの量を減らし、タスクの複雑さを上げます。ディレクトリの内容はわずかに異なりますが、インフラストラクチャはどこでも使用する準備ができています。詳細なタスクは、各グレードのREADME.mdで説明されています。自分のものを選択して、必要に応じてレベルを下げてください。
研修生:すべてのコードは、中級の問題のためにすでに実装されています。開始して探索してください。また、このようにソリューションを実装した理由を説明するメモを見つけることができます。
インターン:既存の構成を拡張して、書かれたDAGが新しいソースと新しいテーブルからデータの読み込みを開始するようにします。ファイルシステムを操作して、Bashoperatorを使用して一時ファイルをクリーンアップするためのシンプルなDAGを作成します。
ジュニア:履歴ストレージを考慮せずに、増分荷重を記述します。ソース上のデータは更新されません。
中央:SCD2テーブルに増分負荷を書き込みます。データはソースで更新される場合があることに注意してください。
シニア:中間 +セットアップの割り当てwrite-audit-publishパターンのように、データの品質を確保し、書かれたソリューションの負荷テストを実施します。
SCD2を使用した履歴データストレージ: 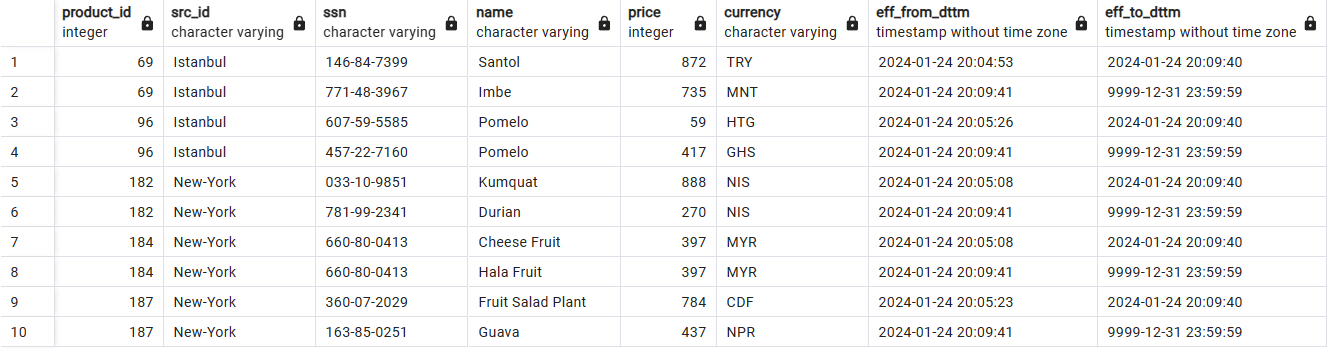
気流による増分荷重: 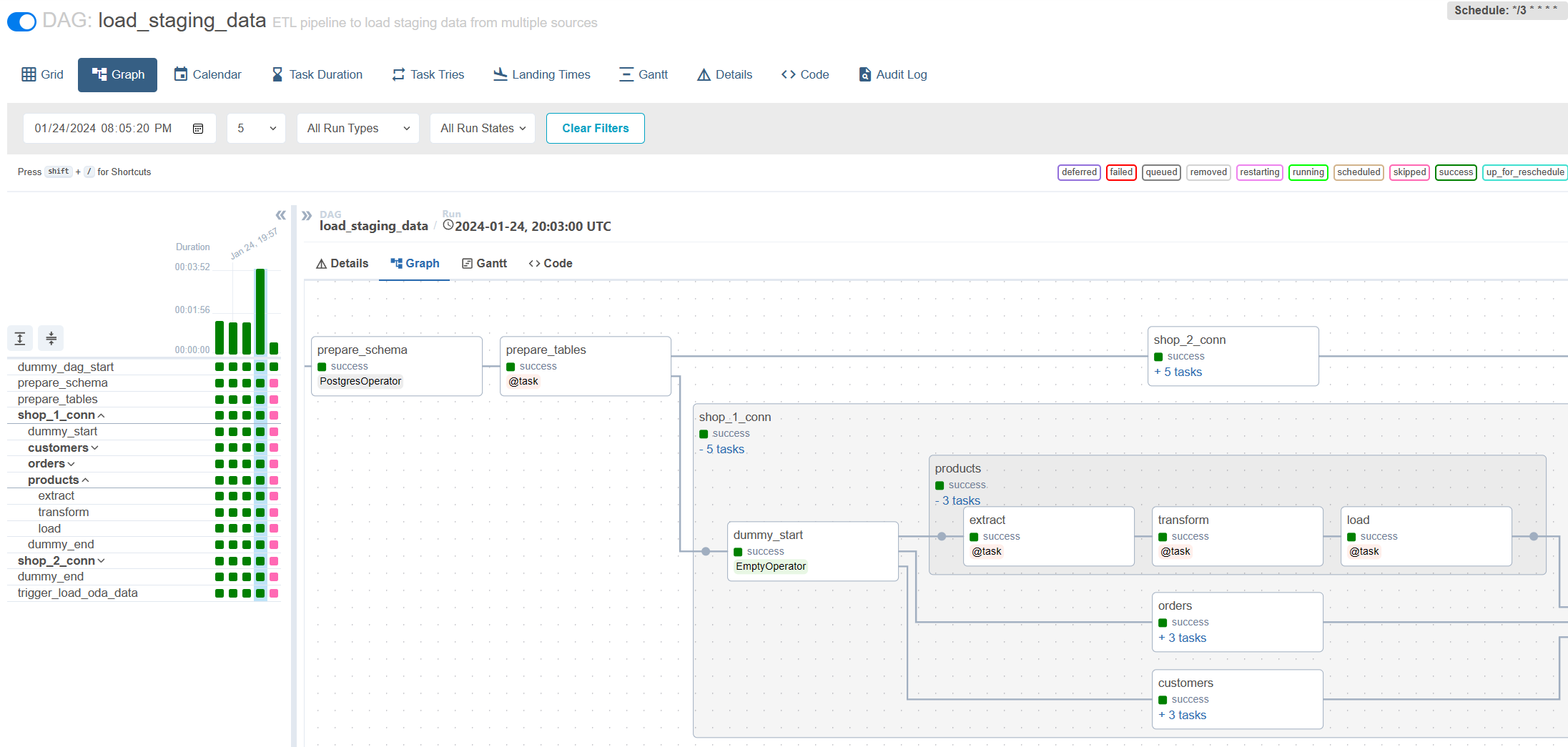
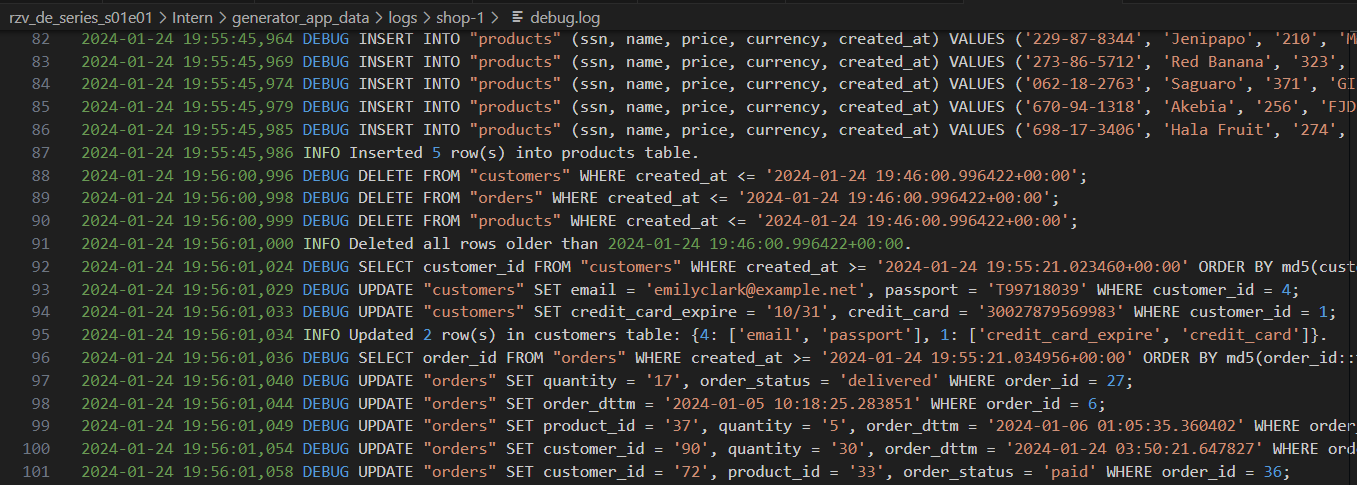
さまざまなレベルの詳細を持つジェネレーターログ: 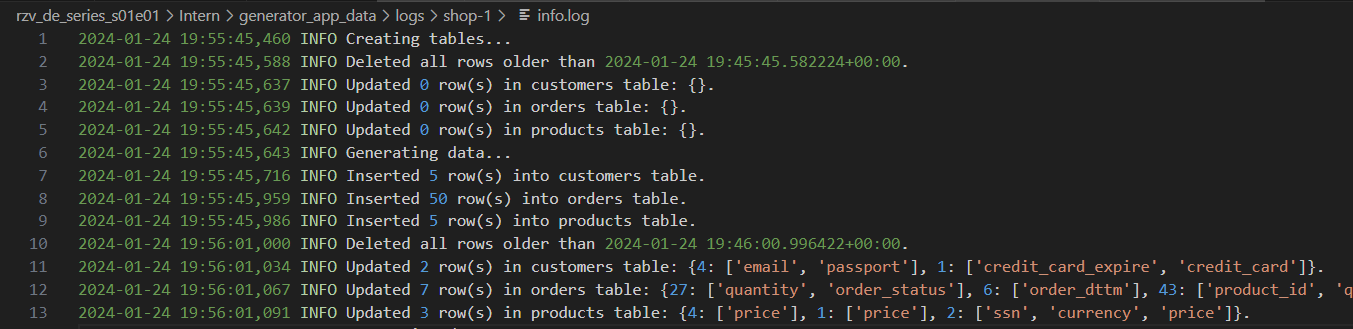
必要なものすべてを備えた完全にローカルインフラストラクチャ: 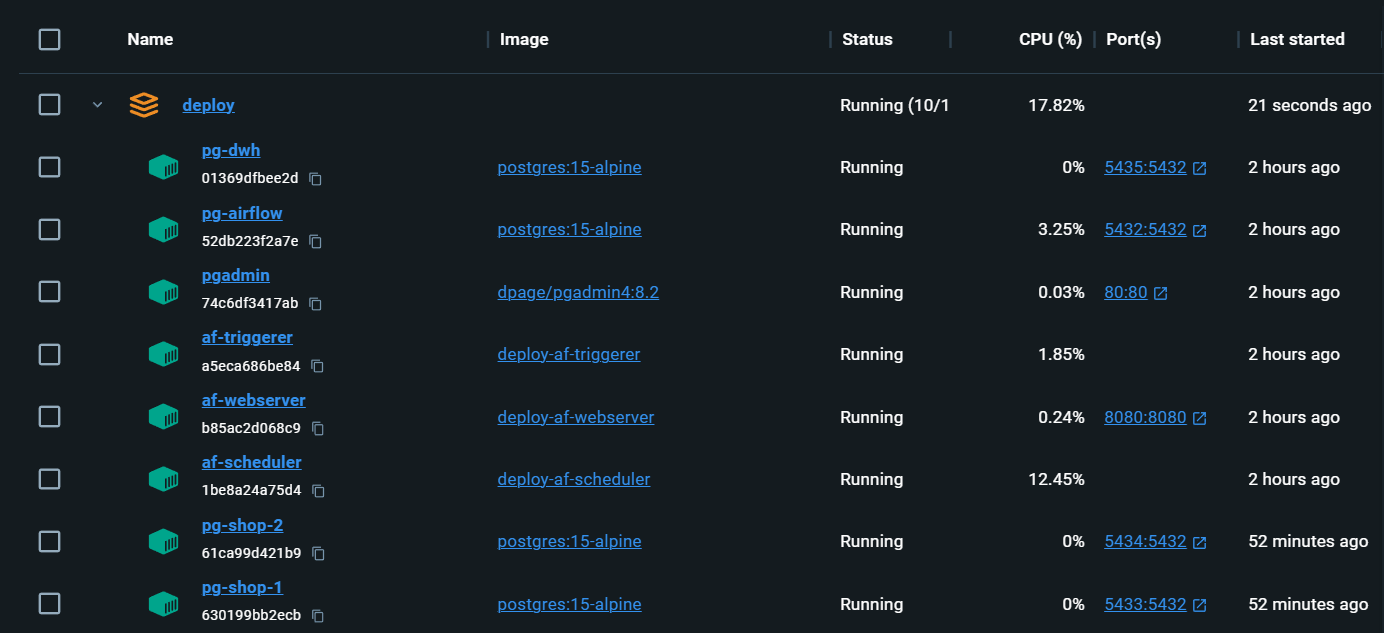
localhost:80/#/adminに移動し、ログインしてから、メインページlocalhost/#/に戻りますdocker compose up後、気流が再現されるたびに再目的化されます。ダグは保存されますが、 ConnectionsとVariables再度入力する必要があります。 Aleksei Razvodov、業界で5年以上の経験を持つデータエンジニア。私は、データエンジニアの仕事についての私の理解を伝え、この道に沿って発展している人々を助けるよう努めています。
このリポジトリがあなたを助け、あなたがそれを気に入ったなら、それを与えて、ソーシャルネットワークを購読してください。



