rzv_data_engineering_series_s01e01
1.0.0

Aquí hay un episodio abierto del curso de capacitación de RZV Data Engineering Series. ¡Elija qué serie activará esta noche, una que lo distraerá de la vida, o una que le brinde la oportunidad de aprender habilidades y crear!
El curso va en un formato a su propio ritmo, la infraestructura se implementa localmente en contenedores Docker. Espero que busque materiales para responder sus preguntas por su cuenta y discutirlas en el chat general. Se aplica una solución a la tarea en el nivel medio. Las tareas se dividen en diferentes niveles de dificultad. Comience con donde se sienta más cómodo y avance. Cuanto mayor sea la calificación, más abstracta es la declaración del problema, es como en la vida.
Las habilidades que adquiere durante el curso se pueden transferir a la práctica laboral casi sin esfuerzo. Y, a diferencia de la mayoría de los cursos, aquí trabaja con datos "en vivo" que se generan en tiempo real (de manera simplificada). Al final de la primera temporada de la serie, podrá experimentar problemas de ingeniería de datos en la práctica y escribir las soluciones usted mismo.
Cuanto más lejos se adjuntará más módulos después del "Desarrollo de Negocios":
PS Compruebe las versiones traducidas ReadMe.MD en la raíz de los directorios principales: [RU] está disponible.
Este es el primer episodio que cubre las características de la carga incremental a través del flujo de aire Apache. En el proceso de realizar tareas a nivel medio y superior, encontrará muchas dificultades que existen en la práctica de trabajo real. Al mismo tiempo, incluso las tareas junior y pasante le presentarán nuevos conceptos y lo prepararán gradualmente para tareas más complejas.
Te animo a que intentes resolver el problema tú mismo y luego mirar mi versión.
Aprenderás:
Cada nivel tiene su propio directorio. Con cada nivel, reduzco la cantidad de código listo para ejecutar y elevar la complejidad de la tarea. El contenido de los directorios es ligeramente diferente, pero la infraestructura está lista para usar en todas partes. Las tareas detalladas se describen en README.md de cada grado. Elija el suyo y no dude en reducir el nivel si es necesario.
Traineo : Todo el código ya se ha implementado para el problema de grado medio. Simplemente lanza y explora. También puede encontrar notas que expliquen por qué he implementado la solución de esta manera.
Pasante : Extienda la configuración existente para que el DAG escrito comience a cargar datos de una nueva fuente y nuevas tablas. Escriba un DAG simple para trabajar con el sistema de archivos para limpiar archivos temporales utilizando Bashoperator.
Junior : Escriba la carga incremental sin tener en cuenta el almacenamiento histórico. Los datos en la fuente no se actualizan.
Medio : Escriba una carga incremental en las tablas SCD2. Tenga en cuenta que los datos pueden actualizarse en la fuente.
Senior : Asignación en cuanto al patrón de publicación de escritura de escritura Middle + Configuración para garantizar la calidad de los datos y realizar pruebas de carga de la solución escrita.
Almacenamiento de datos históricos con SCD2: 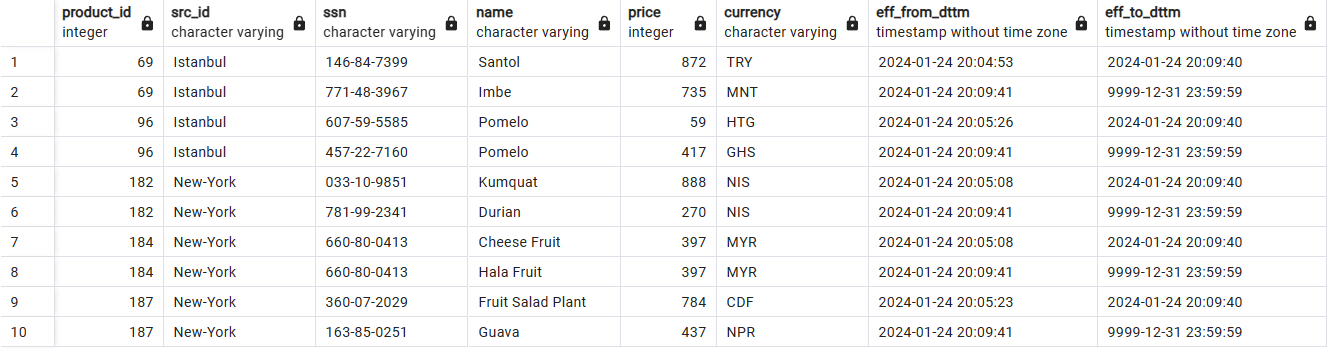
Carga incremental a través del flujo de aire: 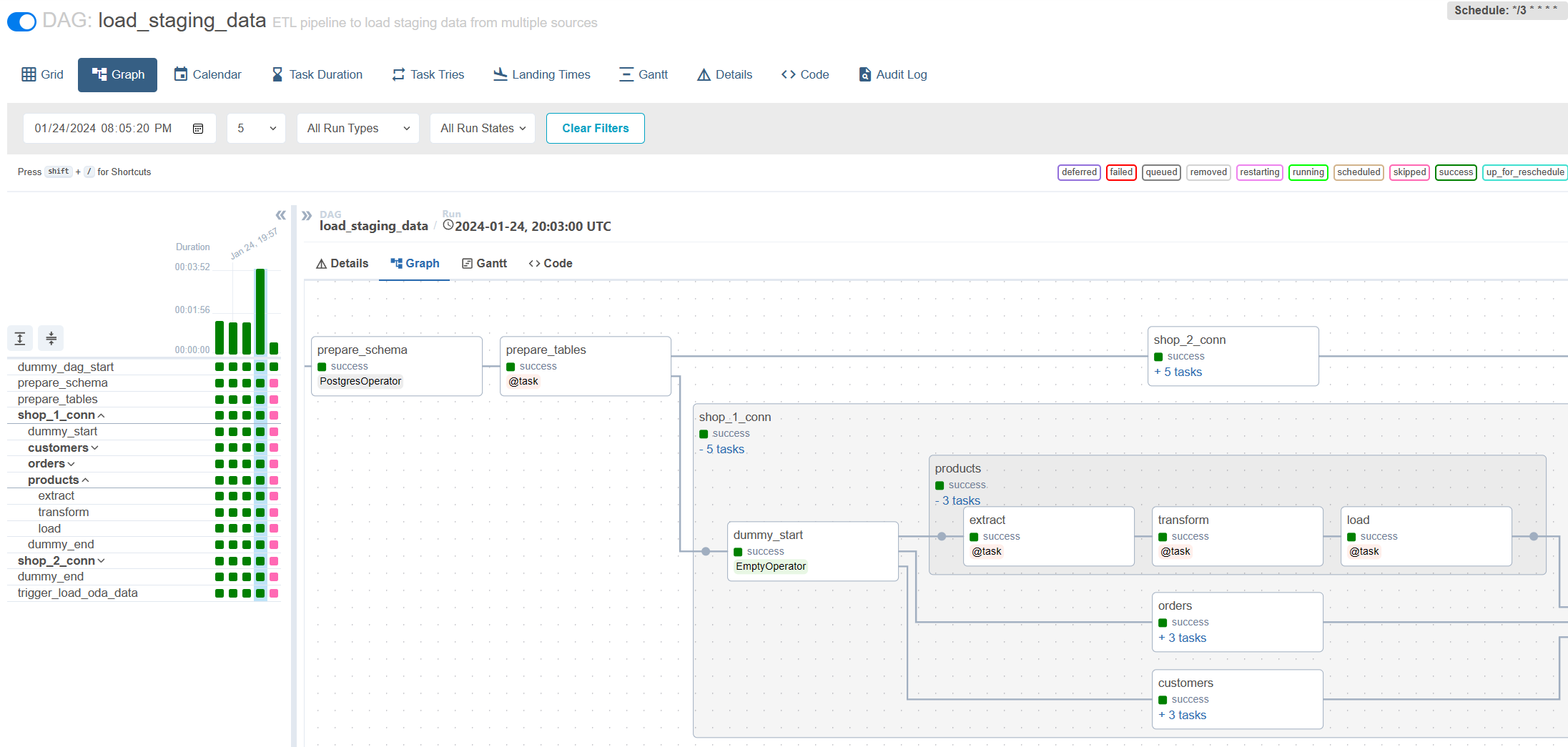
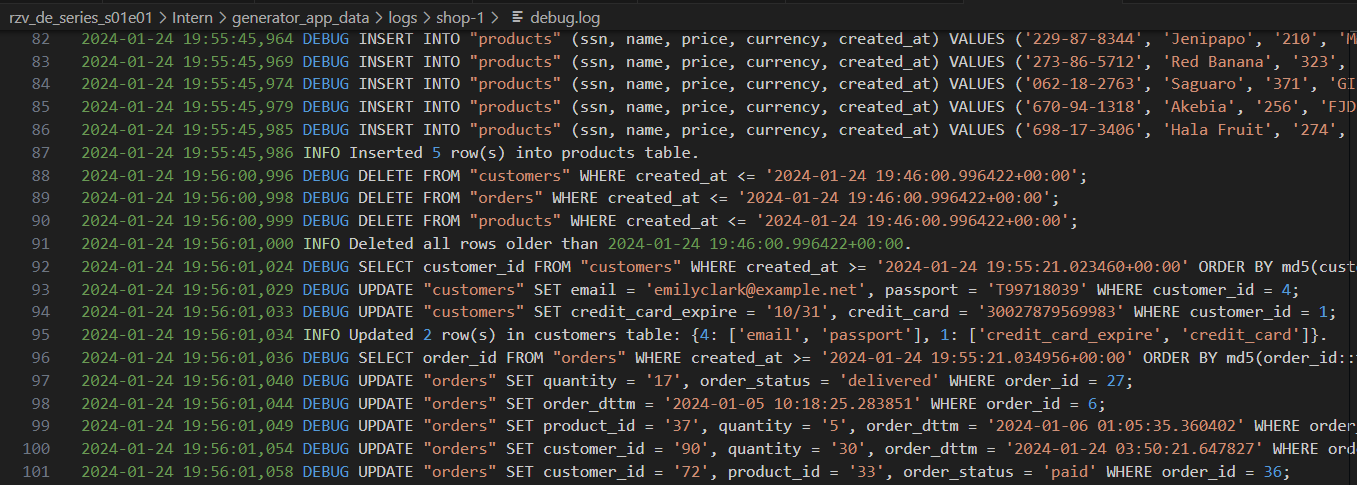
Registros de generador con diferentes niveles de detalle: 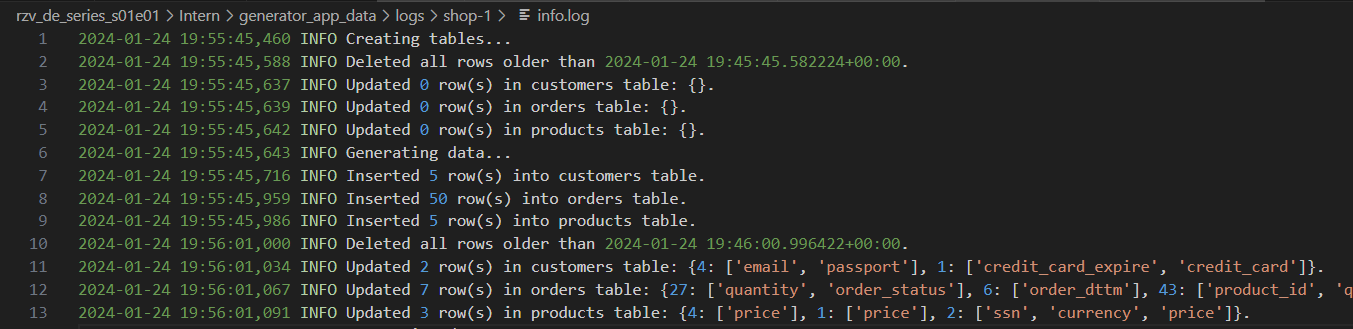
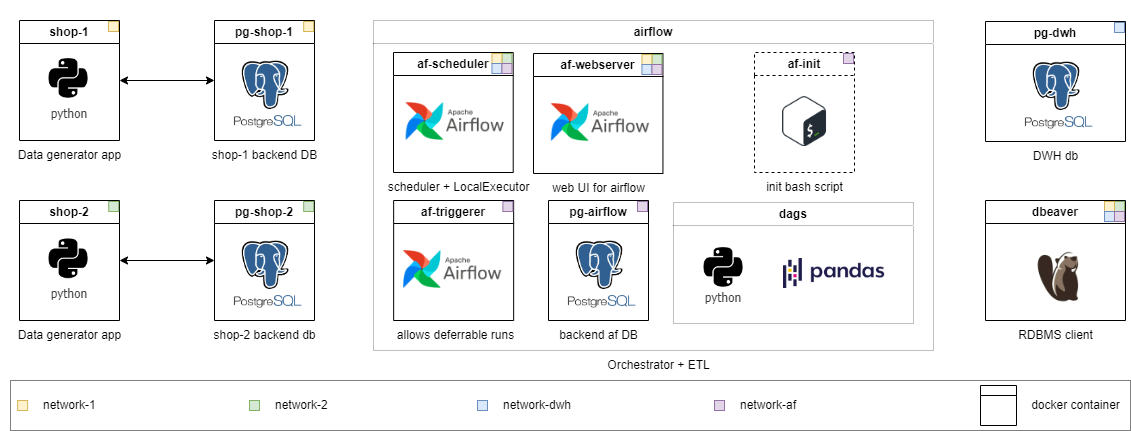
Infraestructura completamente local con todo lo que necesita: 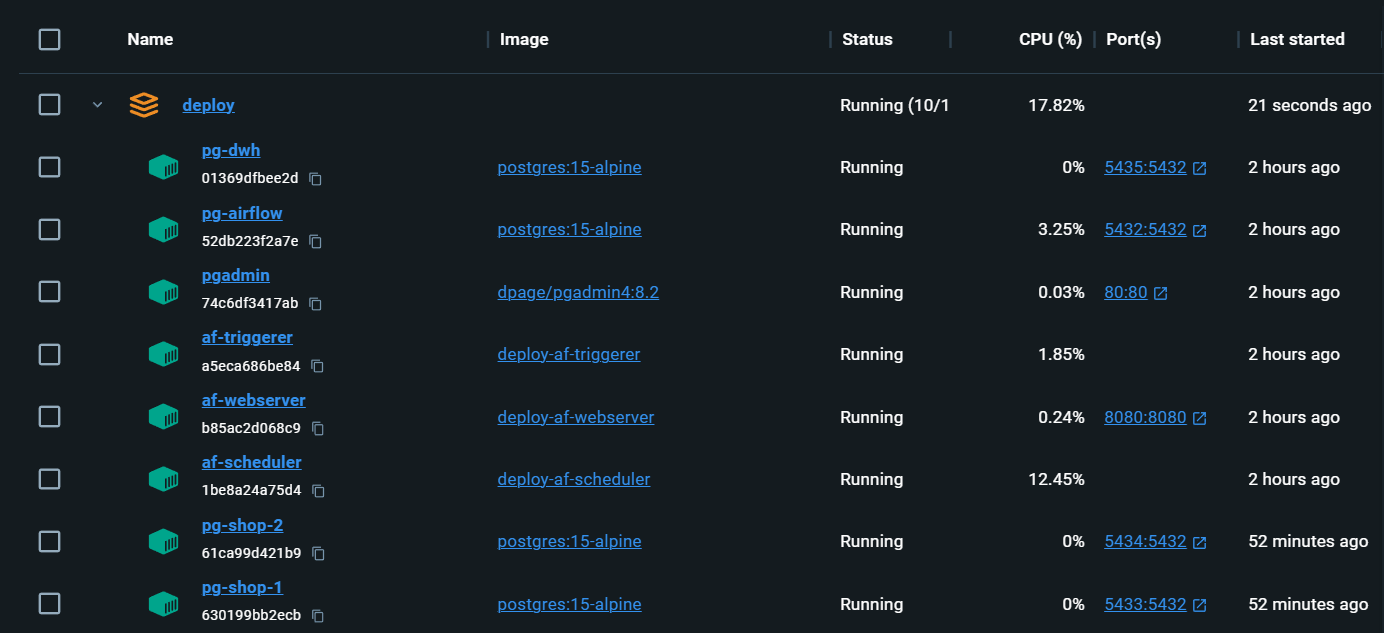
localhost:80/#/admin , inicie sesión, luego regrese a la página principal localhost/#/ docker compose up el flujo de aire se reinicializa. Los DAG se guardan, pero Connections y Variables deben completarse nuevamente. Aleksei Razvodov, ingeniero de datos con más de 5 años de experiencia en la industria. Me esfuerzo por transmitir mi comprensión del trabajo de un ingeniero de datos y ayudar a aquellos que se están desarrollando a lo largo de este camino.
Si este repositorio lo ayudó y le gustó, dale un y suscribir a las redes sociales.



