chameleon llm
v1.0
Код для бумаги «Хамелеон: композиционные рассуждения с подключаемой и игрой с большими языковыми моделями».
? Если у вас есть какие -либо вопросы или предложения, не стесняйтесь сообщить нам об этом. Вы можете напрямую по электронной почте Pan Lu, используя адрес электронной почты [email protected], прокомментировать Twitter или опубликовать вопрос об этом хранилище.
[Страница проекта] [Paper] [Twitter] [LinkedIn] [YouTube] [слайды]
Предварительный логотип для Хамелеона .
Chameleon -это структура композиционных рассуждений, которая дополняет LLMS с различными типами инструментов. Chameleon синтезирует программы по составлению различных инструментов, включая модели LLM, готовые модели зрения, веб-поисковые системы, функции Python и модули, основанные на правилах, адаптированные к интересам пользователей. Построенный на вершине LLM в качестве планировщика естественного языка, Хамелеон делает соответствующую последовательность инструментов для сочинения и выполнения, чтобы генерировать окончательный отклик.
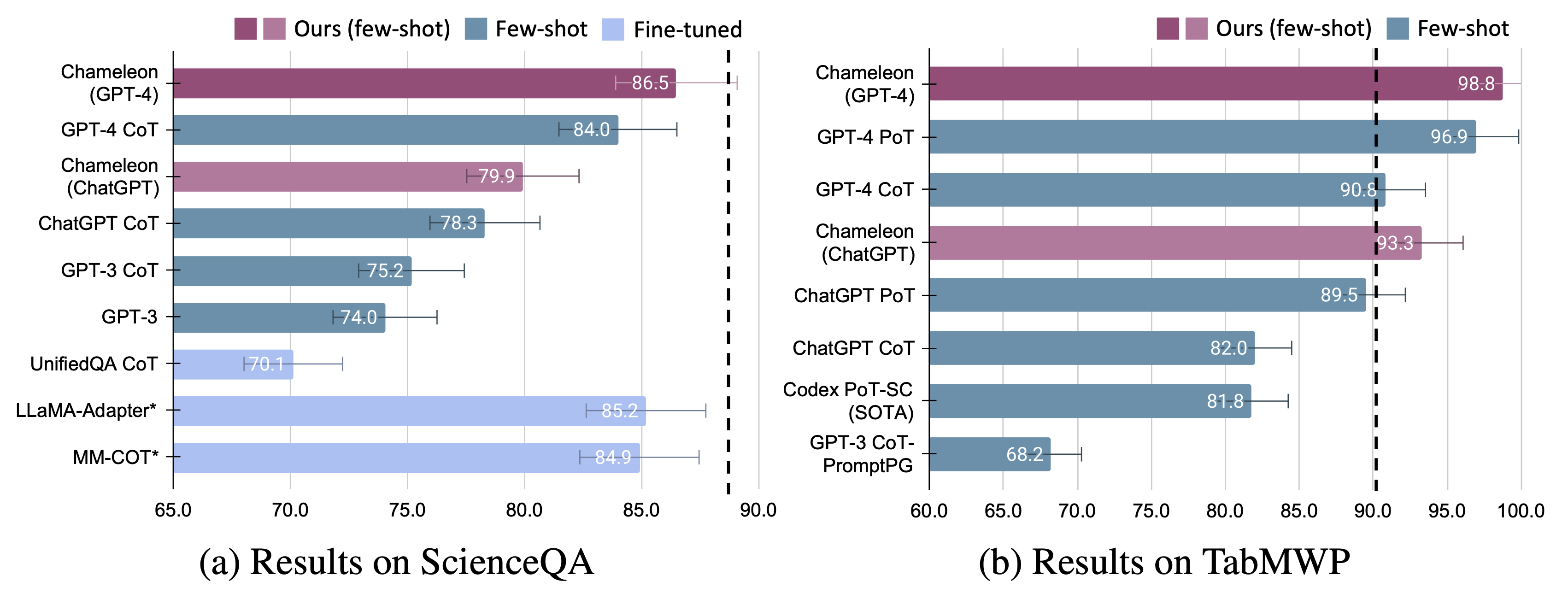
Мы демонстрируем адаптивность и эффективность хамелеона по двум задачам: ScienceQA и TabMWP. Примечательно, что Хамелеон с GPT-4 достигает точность 86,54% в ScienceQA, значительно улучшив лучшую опубликованную модель с несколькими выстрелами на 11,37%; Используя GPT-4 в качестве основного LLM, Хамелеон достигает на 17,0% больше, чем современная модель, что приводит к общей точности на 98,78% на TABMWP. Дальнейшие исследования показывают, что использование GPT-4 в качестве планировщика демонстрирует более последовательный и рациональный выбор инструментов и способен вывести потенциальные ограничения, учитывая инструкции по сравнению с другими LLM, такими как CHATGPT.
Для получения более подробной информации вы можете найти нашу страницу проекта здесь и нашу статью здесь.
Мы хотели бы выразить нашу огромную благодарность WorldOfai за то, что он показал и представил нашу работу на YouTube!
Установите все необходимые зависимости от Python (генерируемые pipreqs ):
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
Установите все необходимые зависимости от Python (вы можете пропустить этот шаг, если вы настраиваете зависимости ранее, и версии не требуются строго):
pip install -r requirements.txt
Получите свой ключ API OpenAI от: https://platform.openai.com/account/api-keys.
Чтобы использовать ключ API OpenAI для Хамелеона , вам необходимо настроить счет счетов (он же оплачиваемая учетная запись).
Вы можете настроить платную учетную запись по адресу https://platform.openai.com/account/billing/overview.
Получите свой ключ API поиска Bing от: https://www.microsoft.com/en-us/bing/apis/bing-web-search-api.
Ключ API поиска Bing не является обязательным . Неспособность настроить этот ключ приведет к небольшому снижению производительности на задаче ScienceQA.
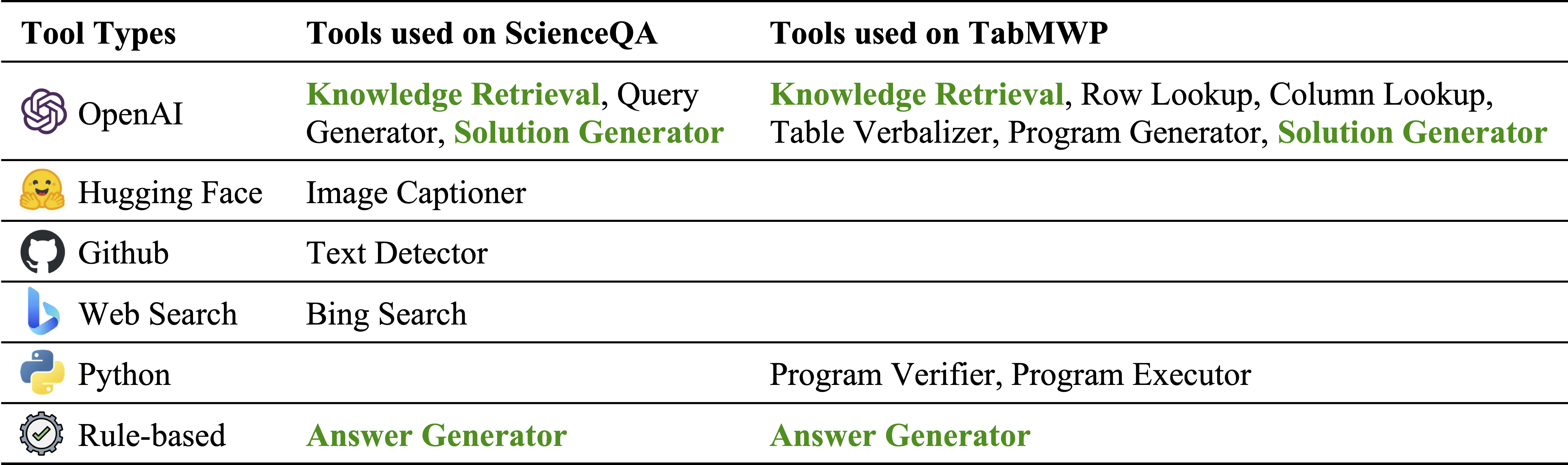
Различные типы инструментов в инвентаре нашего модуля:

Инструменты, используемые на ScienceQA и TABMWP, соответственно. Повторные инструменты в двух задачах выделены зеленым:
Ответ (ScienceQA)-это многомодальный контрольный эталон, охватывающий широкий спектр научных тем по разнообразным контекстам. Набор данных ScienceQA представлен в data/scienceqa . Для получения более подробной информации вы можете изучить набор данных и проверить страницу Explore и визуализировать страницу.
Для текущей версии результаты для Image Captioner и Text Detector являются готовыми и хранятся в data/scienceqa/captions.json и data/scienceqa/ocrs.json , соответственно. Живые призывы этих двух модулей скоро появятся!
Запустить хамелеон (GPT-4):
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 Он будет генерировать прогнозы и сохранить результаты в results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl и results/scienceqa/chameleon_gpt4_test_cache.json .
Мы можем получить показатели точности в среднем и по разным классам вопросов, работая:
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlЗапустить хамелеон (Chatgpt):
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 Наш хамелеон является обобщенной формой метода Cot (цепочка мыслей), где генерируемая программа представляет собой последовательность Solution Generator и Answer Generator . Проходя --model в виде cot , modules устанавливаются как ["solution_generator", "answer_generator"] .
Запустить кроватку (цепочка мыслей) GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1Запустить кроватку (цепочка мыслей) Chatgpt:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 Набор данных TABMWP содержит 38,431 табличного математического слова. Каждый вопрос в TabMWP выровнен с табличным контекстом, который представлен как изображение, полуструктурированный текст и структурированная таблица. Набор данных TABMWP представлен в data/tabmwp . Для получения более подробной информации вы можете изучить DataTSet и проверить страницу Explore и страницу Visualize.
Запустить хамелеон (GPT-4):
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 Он будет генерировать прогнозы и сохранить результаты в results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl и results/tabmwp/chameleon_gpt4_test_cache.json .
Мы можем получить показатели точности в среднем и по разным классам вопросов, работая:
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlЗапустить хамелеон (Chatgpt):
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18Запустить кроватку (цепочка мыслей) GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1Запустить кроватку (цепочка мыслей) Chatgpt:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 Наш хамелеон является обобщенной формой метода POT (программа мыслей), где сгенерированная программа представляет собой последовательность Program Generator , Program Executor и Answer Generator . Проходя --model как pot , modules устанавливаются как ["program_generator", "program_executor", "answer_generator"] .
Запустить горшок (программа мыслей, предложенная) GPT-4:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1Запустить горшок (программа мыслей, представленная) Chatgpt:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1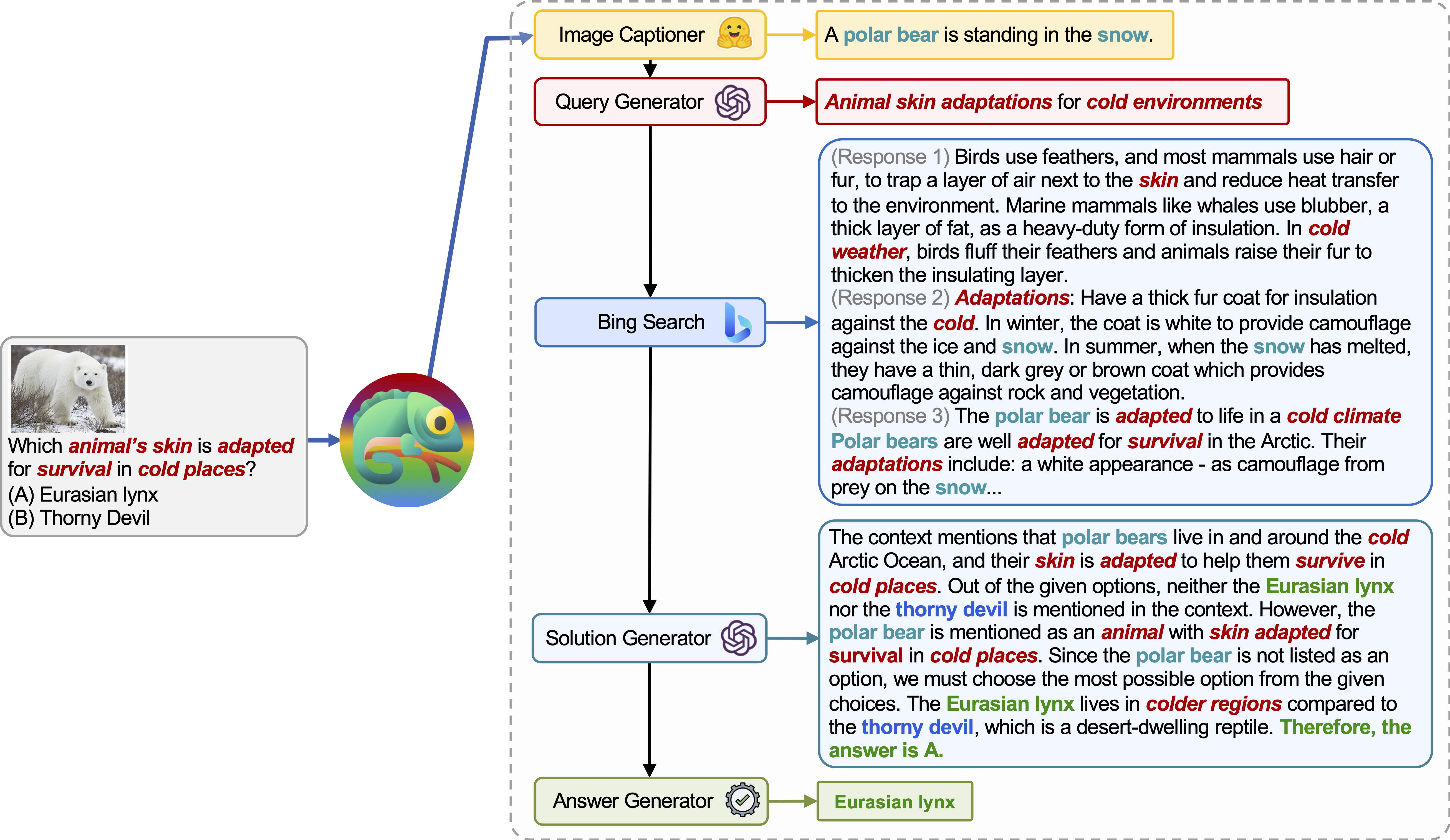
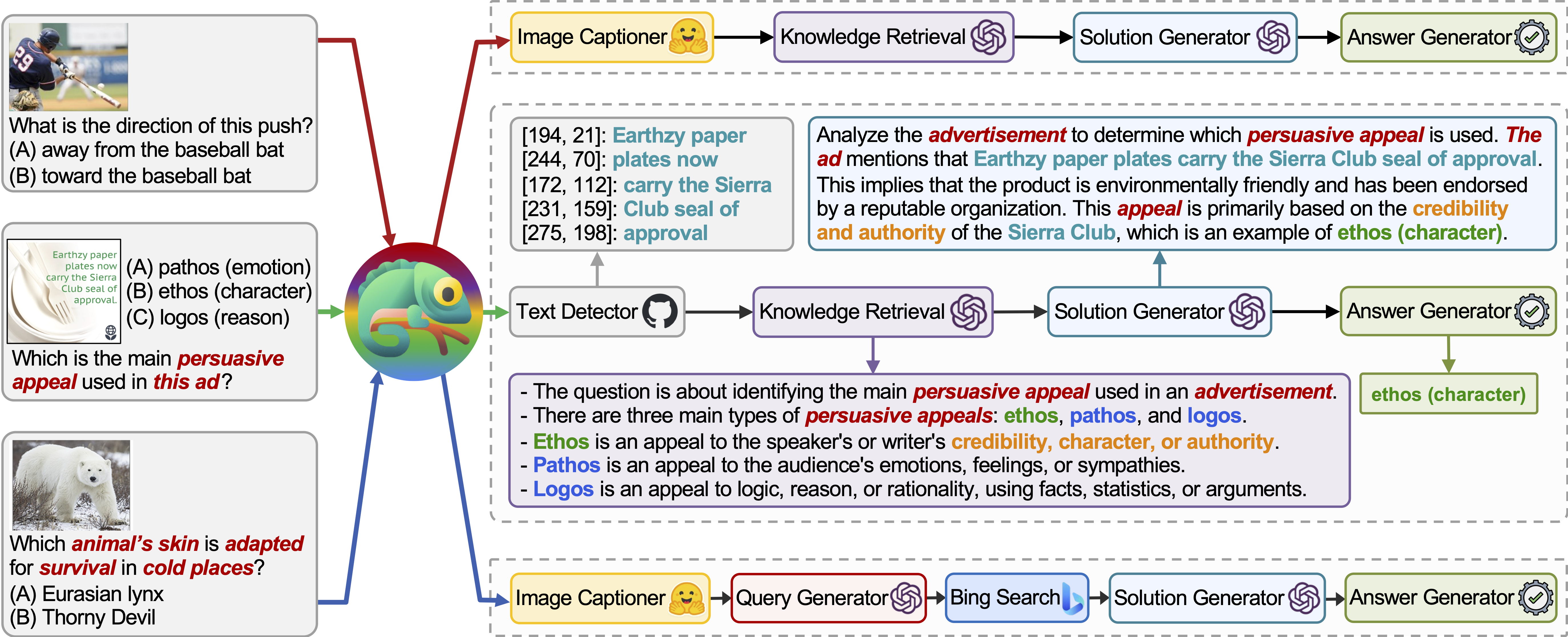
Chameleon (GPT-4) способен адаптироваться к различным входным запросам, генерируя программы, которые составляют различные инструменты и выполняя их последовательно для получения правильных ответов.
Например, приведенный выше вопрос спрашивает: «Кожа того животного адаптирована для выживания в холодных местах?», Что включает в себя научную терминологию, связанную с выживанием животных. Следовательно, планировщик решает полагаться на поисковую систему Bing для знаний, специфичных для домена, извлекая выгоду из многочисленных доступных онлайн-ресурсов.
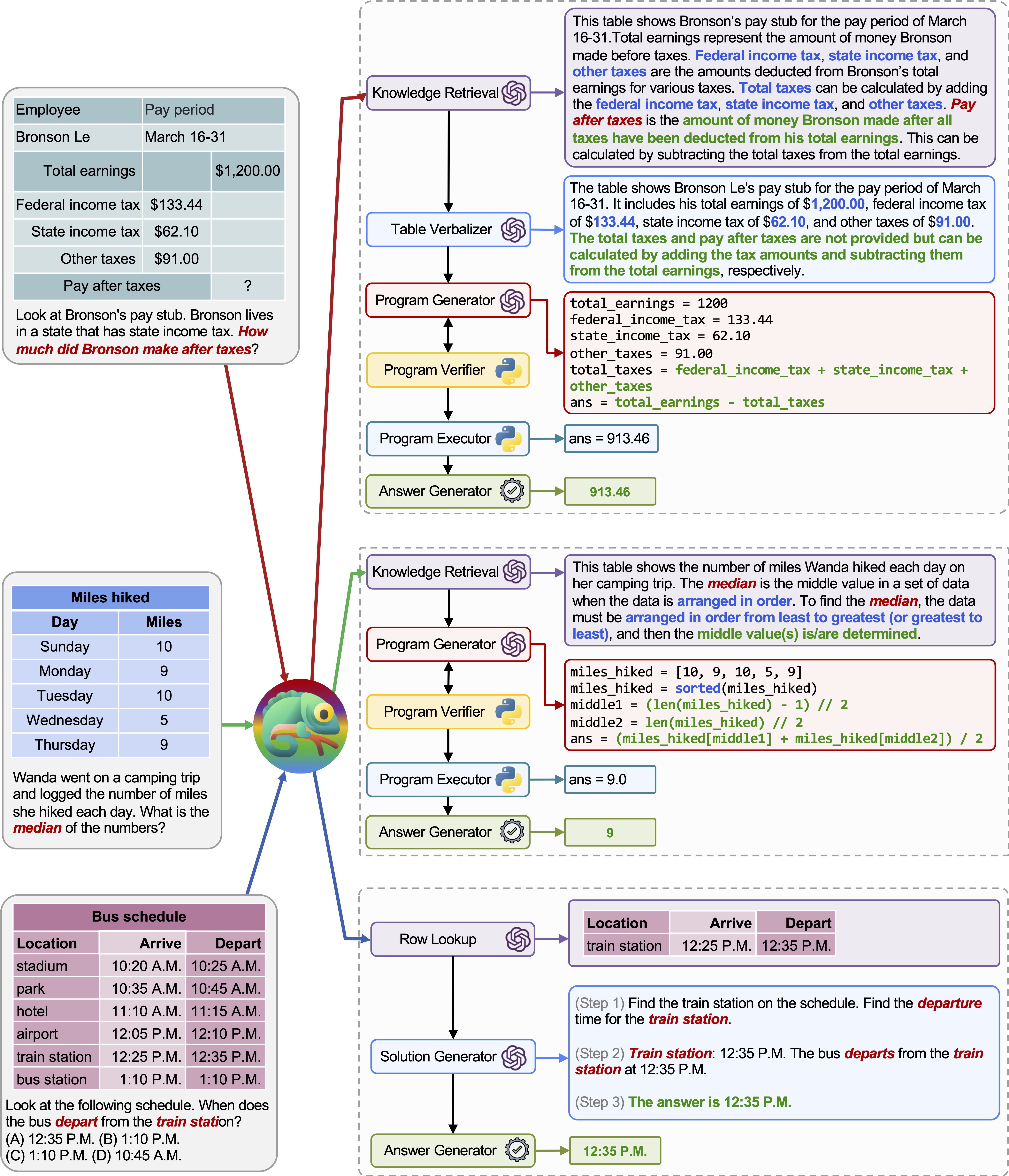
Адаптивность и универсальность нашего хамелеона для различных запросов также наблюдаются на TABMWP, как показано на примерах на рисунке выше.
Первый пример включает в себя математические рассуждения на налоговой форме. Хамелеон (1) называет модель поиска знаний, чтобы вспомнить базовые знания, которые помогают понять такие таблицы, специфичные для домена, (2) описывает таблицу в более читаемом формате естественного языка и (3) наконец полагается на программные инструменты для выполнения Точные вычисления.
Во втором примере система генерирует код Python, который тесно связан с фоновыми знаниями, предоставленными моделью поиска знаний.
Третий пример требует, чтобы система обнаружила ячейку в большом табличном контексте, учитывая входной запрос. Chameleon называет модель поиска строк, чтобы помочь точно найти соответствующие строки и генерировать языковое решение через модель LLM, а не полагаться на программные инструменты.
Значительные улучшения наблюдаются для хамелеона по сравнению с тонкими моделями, так и с несколькими выстрелами, вызванными GPT-4/CHATGPT:
Чтобы визуализировать прогнозы, сделанные Chameleon , просто выполните ноутбук Jupyter, соответствующую вашей конкретной задаче: notebooks/results_viewer_[TASK].ipynb . Это обеспечит интерактивный и удобный способ изучения результатов, сгенерированных моделью. В качестве альтернативы, изучите нашу страницу проекта для получения дополнительной информации и опций.
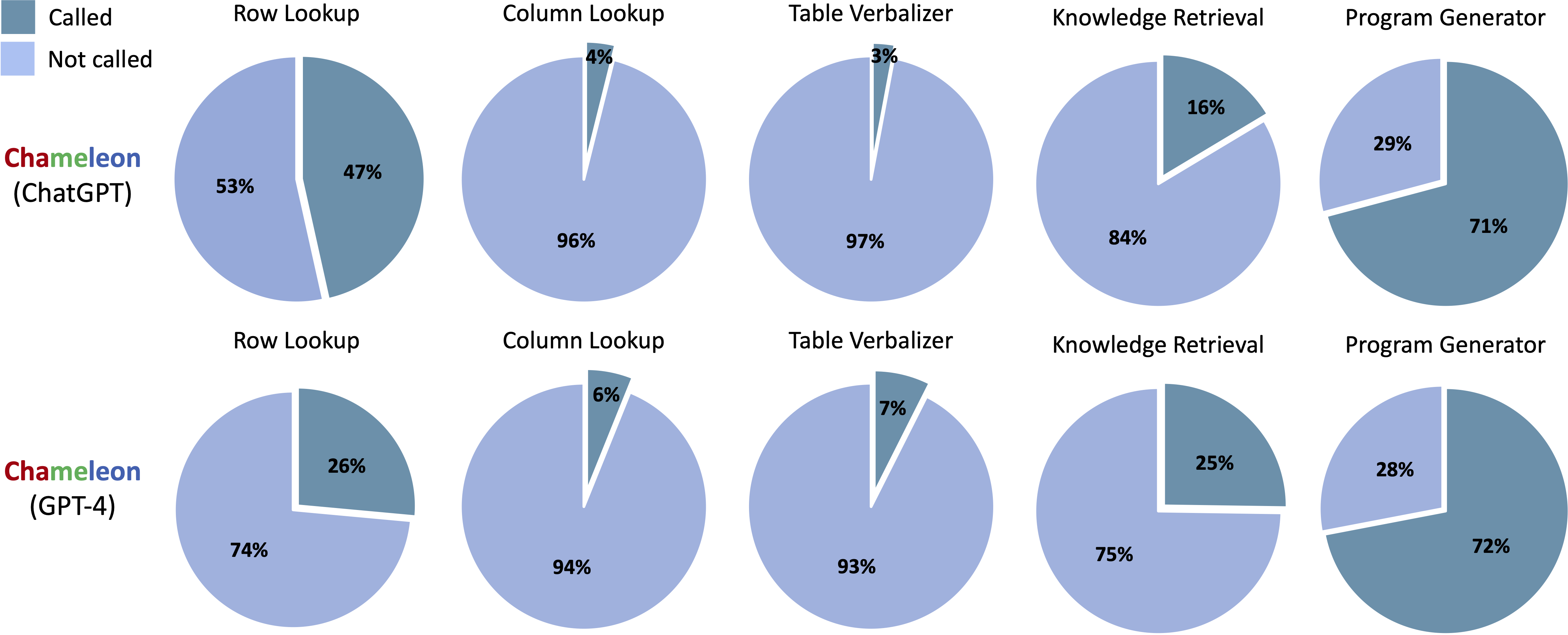
Инструменты, вызванные сгенерированными программами от Chameleon (CHATGPT) и Chameleon (GPT-4) на Scienceqa:

Инструменты, вызванные сгенерированными программами от Chameleon (CHATGPT) и Chameleon (GPT-4) на TABMWP:
Выполнить notebooks/transition_[TASK]_[Model]_Engine.ipynb чтобы визуализировать график перехода модуля для программ, сгенерированных в наборе тестирования.
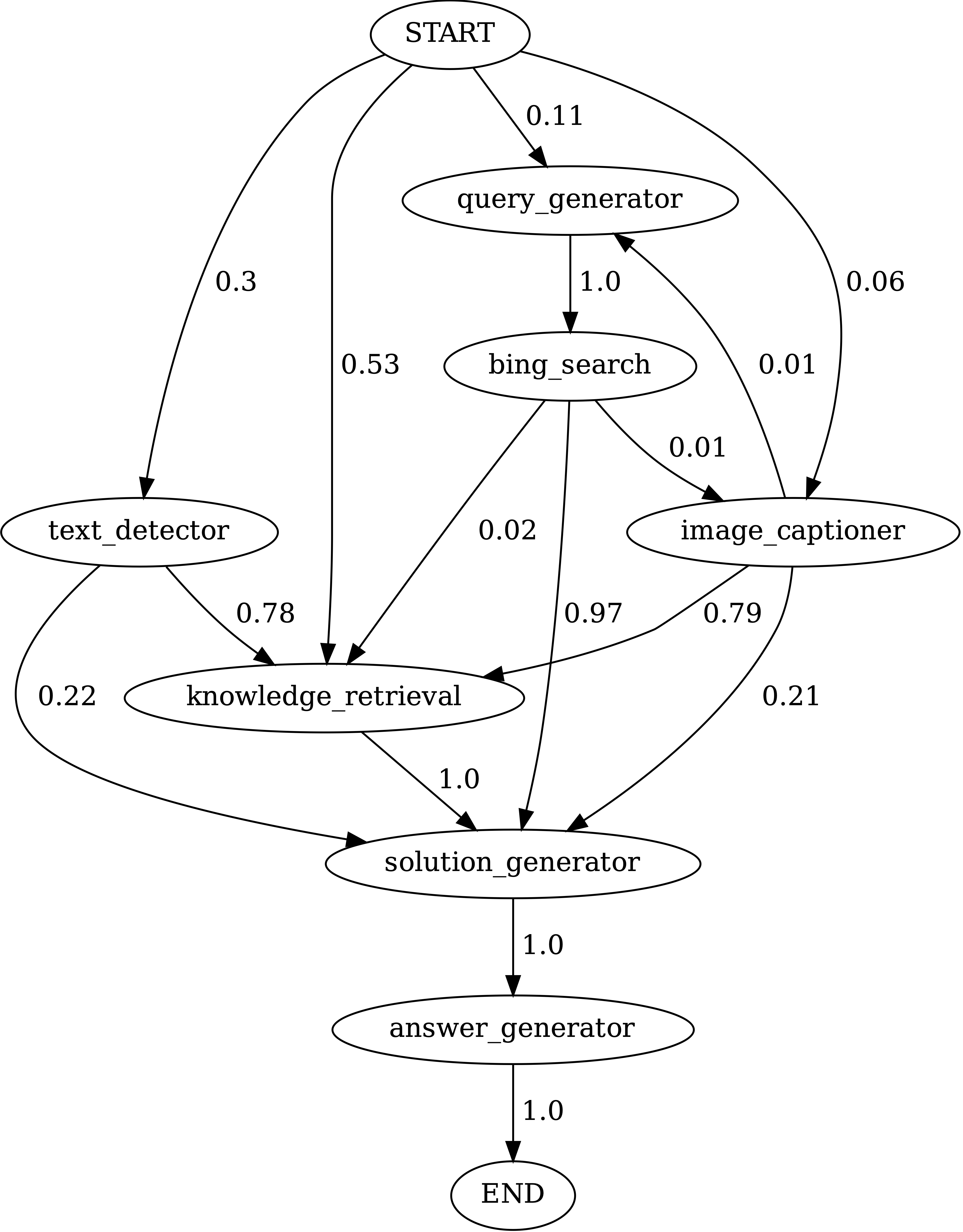
Переходы между модулями в программах, генерируемых Chameleon (GPT-4) на ScienceQA. Начало-это символ начала, End-это символ терминала, а другие-не концевые символы.
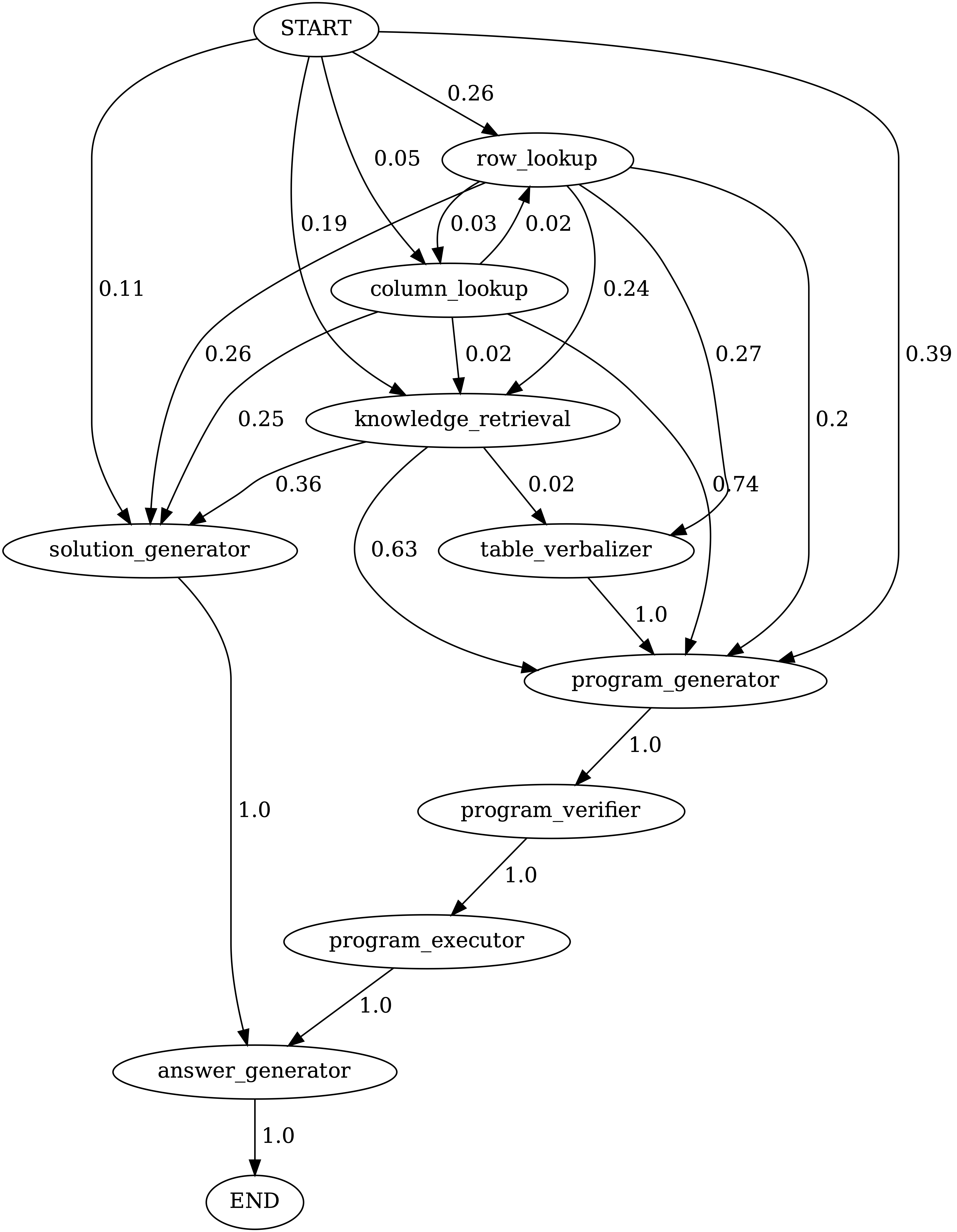
Переходы между модулями в программах, сгенерированных хамелеоном (GPT-4) на TabMWPQA. Начало-это символ начала, End-это символ терминала, а другие-не концевые символы.
demos . Определите вход, выполнение и вывод для каждого модуля в model.py .model.py . Чтобы изменить метод оценки, обновите соответствующий раздел в main.pyФантастика! Я всегда открыт для участия в обсуждениях, сотрудничестве или даже просто делюсь виртуальным кофе. Чтобы связаться, посетите домашнюю страницу Пан Лу для контактной информации.
Если вы найдете Chameleon полезным для ваших исследований и приложений, пожалуйста, цитируйте, используя этот Bibtex:
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

