chameleon llm
v1.0
논문 코드 "카멜레온 : 큰 언어 모델을 사용한 플러그 앤 플레이 구성 추론".
? 질문이나 제안이 있으시면 주저하지 말고 알려주십시오. 이메일 주소 [email protected]을 사용하여 Pan Lu에게 직접 이메일을 보내거나 트위터에 댓글을 달거나이 저장소에 문제를 게시 할 수 있습니다.
[프로젝트 페이지] [논문] [트위터] [LinkedIn] [YouTube] [슬라이드]
카멜레온을 위한 잠정적 로고.
카멜레온 은 다양한 유형의 도구로 LLM을 증강시키는 플러그 앤 플레이 구성 추론 프레임 워크입니다. 카멜레온은 LLM 모델, 상용 비전 모델, 웹 검색 엔진, 파이썬 기능 및 사용자 관심사에 맞게 조정 된 규칙 기반 모듈을 포함한 다양한 도구를 작성하는 프로그램을 종합합니다. 자연 언어 플래너로서 LLM 위에 구축 된 Chameleon은 최종 응답을 생성하기 위해 작성하고 실행할 수있는 적절한 일련의 도구를 유추합니다.
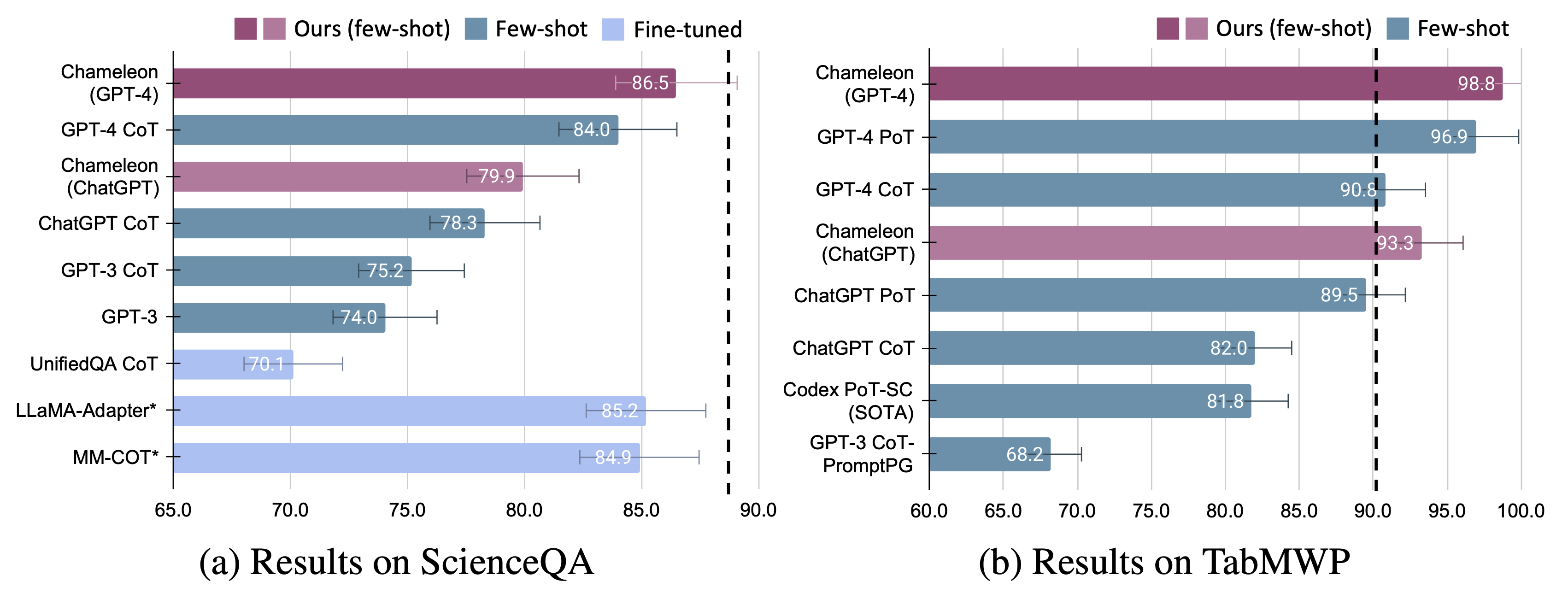
우리는 ScienceQA와 Tabmwp의 두 가지 작업에 대해 카멜레온 의 적응성과 효과를 보여줍니다. 특히, GPT-4를 가진 카멜레온은 ScienceQA에서 86.54% 정확도를 달성하여 가장 출판 된 소수의 소수 모델을 11.37%로 크게 향상시켰다. Chameleon은 기본 LLM으로 GPT-4를 사용하여 최첨단 모델에 비해 17.0% 증가하여 TABMWP의 전반적인 정확도를 98.78% 증가시킵니다. 추가 연구에 따르면 GPT-4를 플래너로 사용하는 것은보다 일관되고 합리적인 도구 선택을 보여 주며 Chatgpt와 같은 다른 LLM에 비해 지침을 고려할 때 잠재적 인 제약을 유추 할 수 있다고합니다.
자세한 내용은 프로젝트 페이지와 여기에서 논문을 찾을 수 있습니다.
우리는 YouTube에 작품을 소개하고 소개 한 Worldofai에 대한 엄청난 감사를 표현하고 싶습니다!
필요한 모든 Python 종속성을 설치합니다 ( pipreqs 에서 생성) :
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
필요한 모든 Python 종속성을 설치하십시오 (이전의 종속성을 설정하고 버전이 엄격하게 필요하지 않은 경우이 단계를 건너 뛸 수 있습니다).
pip install -r requirements.txt
https://platform.openai.com/account/api-keys에서 OpenAI API 키를 얻으십시오.
카멜레온 에 OpenAI API 키를 사용하려면 청구 설정 (일명 유료 계정)이 있어야 합니다 .
https://platform.openai.com/account/billing/overview에서 유료 계정을 설정할 수 있습니다.
https://www.microsoft.com/en-us/bing/apis/bing-web-search-api에서 Bing Search API 키를 얻으십시오.
Bing Search API 키는 선택 사항 입니다. 이 키를 설정하지 않으면 ScienceQA 작업에서 약간의 성능이 떨어집니다.
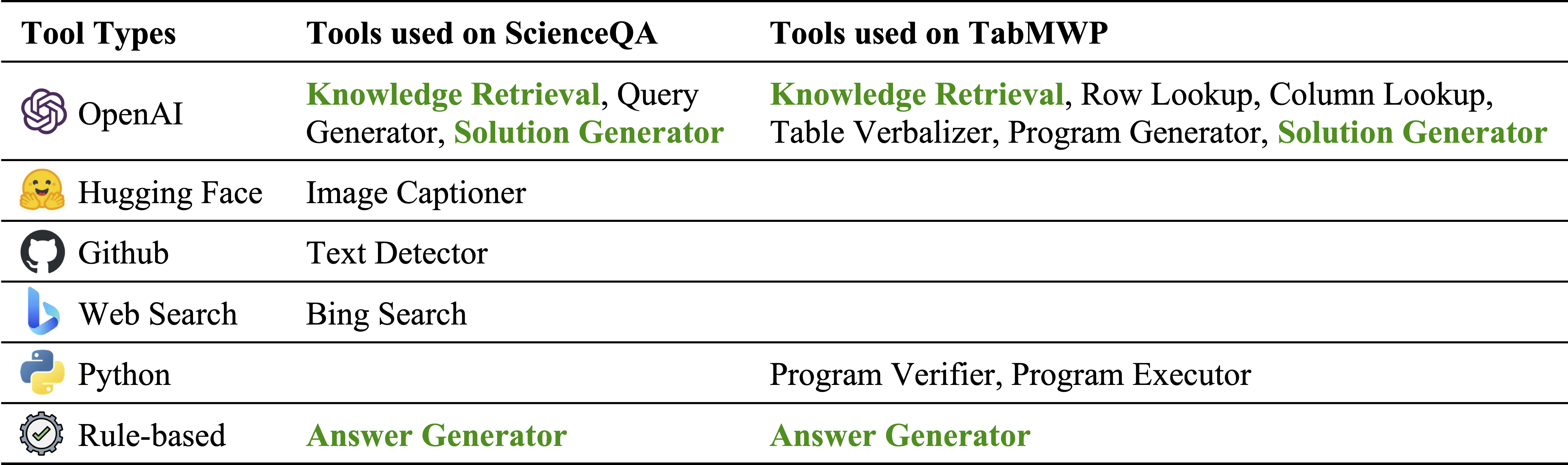
모듈 인벤토리의 다른 유형의 도구 :

ScienceQa 및 Tabmwp에 각각 사용되는 도구. 두 작업의 재사용 가능한 도구는 녹색으로 강조 표시됩니다.
과학 질문 답변 (ScienceQA)은 다양한 상황에 대한 다양한 과학적 주제를 다루는 멀티 모달 질문 응답 벤치 마크입니다. ScienceQA 데이터 세트는 data/scienceqa 에 제공됩니다. 자세한 내용은 데이터 세트를 탐색하고 탐색 페이지를 확인하고 페이지를 시각화 할 수 있습니다.
현재 버전의 경우 Image Captioner 및 Text Detector 의 결과는 상용이없고 data/scienceqa/captions.json 및 data/scienceqa/ocrs.json 에 각각 저장됩니다. 이 두 모듈을 호출하는 라이브는 곧 출시 될 예정입니다!
카멜레온 (GPT-4)을 실행하려면 :
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl 및 results/scienceqa/chameleon_gpt4_test_cache.json 에서 예측을 생성하고 결과를 저장합니다.
우리는 평균적으로 정확도 지표를 평균적으로 그리고 다른 질문 클래스에서 실행하여 얻을 수 있습니다.
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonl카멜레온 (Chatgpt)을 실행하려면 :
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 우리의 카멜레온은 생성 된 프로그램이 Solution Generator 및 Answer Generator 의 시퀀스 인 COT (Chain-of-Thought) 방법의 일반화 된 형태입니다. --model cot 로 통과시킴으로써 modules ["solution_generator", "answer_generator"] 로 설정됩니다.
COT를 운영하려면 (체인-생각 프롬프트) GPT-4 :
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1침대를 운영하려면 (체인-생각 프롬프트) chatgpt :
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 TABMWP 데이터 세트에는 38,431 개의 표 수학 단어 문제가 포함되어 있습니다. TABMWP의 각 질문은 이미지, 반 구조화 된 텍스트 및 구조화 된 테이블로 제시되는 표의 컨텍스트와 정렬됩니다. TABMWP 데이터 세트는 data/tabmwp 에 제공됩니다. 자세한 내용은 데이터 세트를 탐색하고 탐색 페이지를 확인하고 페이지를 시각화 할 수 있습니다.
카멜레온 (GPT-4)을 실행하려면 :
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl 및 results/tabmwp/chameleon_gpt4_test_cache.json 에서 예측을 생성하고 결과를 저장합니다.
우리는 평균적으로 정확도 지표를 평균적으로 그리고 다른 질문 클래스에서 실행하여 얻을 수 있습니다.
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonl카멜레온 (Chatgpt)을 실행하려면 :
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18COT를 운영하려면 (체인-생각 프롬프트) GPT-4 :
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1침대를 운영하려면 (체인-생각 프롬프트) chatgpt :
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 우리의 카멜레온은 생성 된 프로그램이 일련의 Program Generator , Program Executor 및 Answer Generator 의 시퀀스 인 POT (Thought-Of-Thought) 방법의 일반화 된 형태입니다. --model pot 로 통과시킴으로써 modules ["program_generator", "program_executor", "answer_generator"] 로 설정됩니다.
냄비를 달리려면 (프로그램의 추정 프로그램) GPT-4 :
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1냄비를 달리기 위해 (프로그램의 프로그램 프로그램) chatgpt :
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1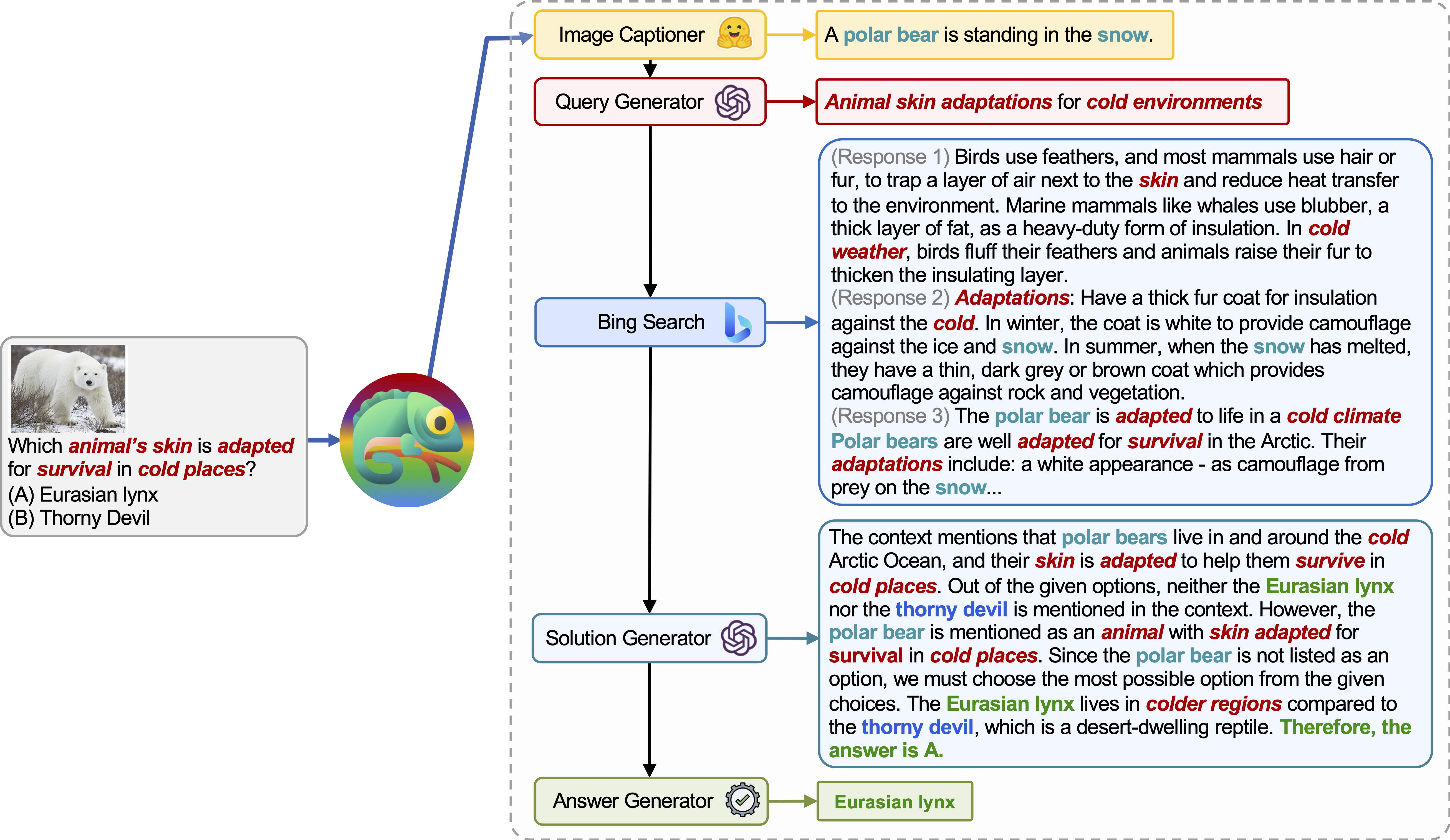
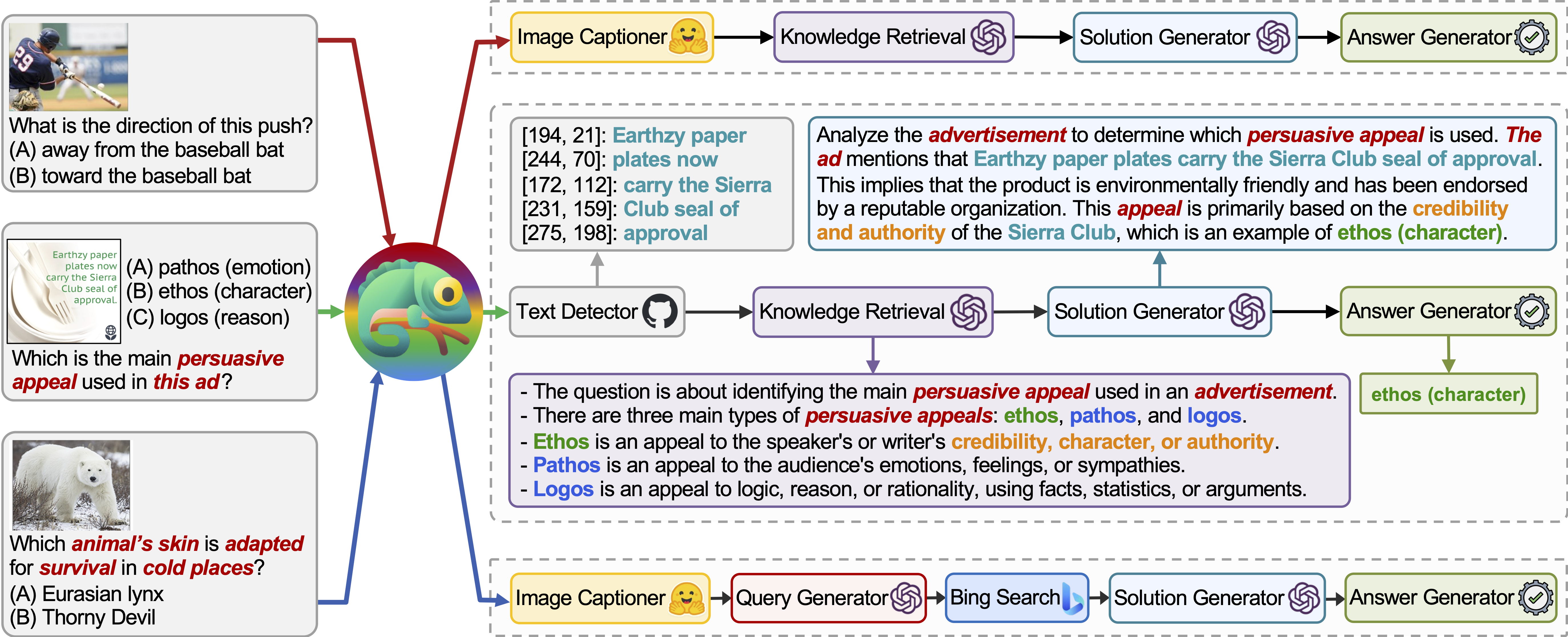
카멜레온 (GPT-4)은 다양한 도구를 작성하고 정답을 순차적으로 실행하는 프로그램을 생성하여 다른 입력 쿼리에 적응할 수 있습니다.
예를 들어, 위의 쿼리는“차가운 곳에서 생존에 적합한 동물의 피부는?”라고 묻습니다. 여기에는 동물 생존과 관련된 과학적 용어가 포함됩니다. 결과적으로, 플래너는 도메인 별 지식을 위해 Bing Search Engine에 의존하여 이용 가능한 수많은 온라인 리소스의 혜택을 받기로 결정합니다.
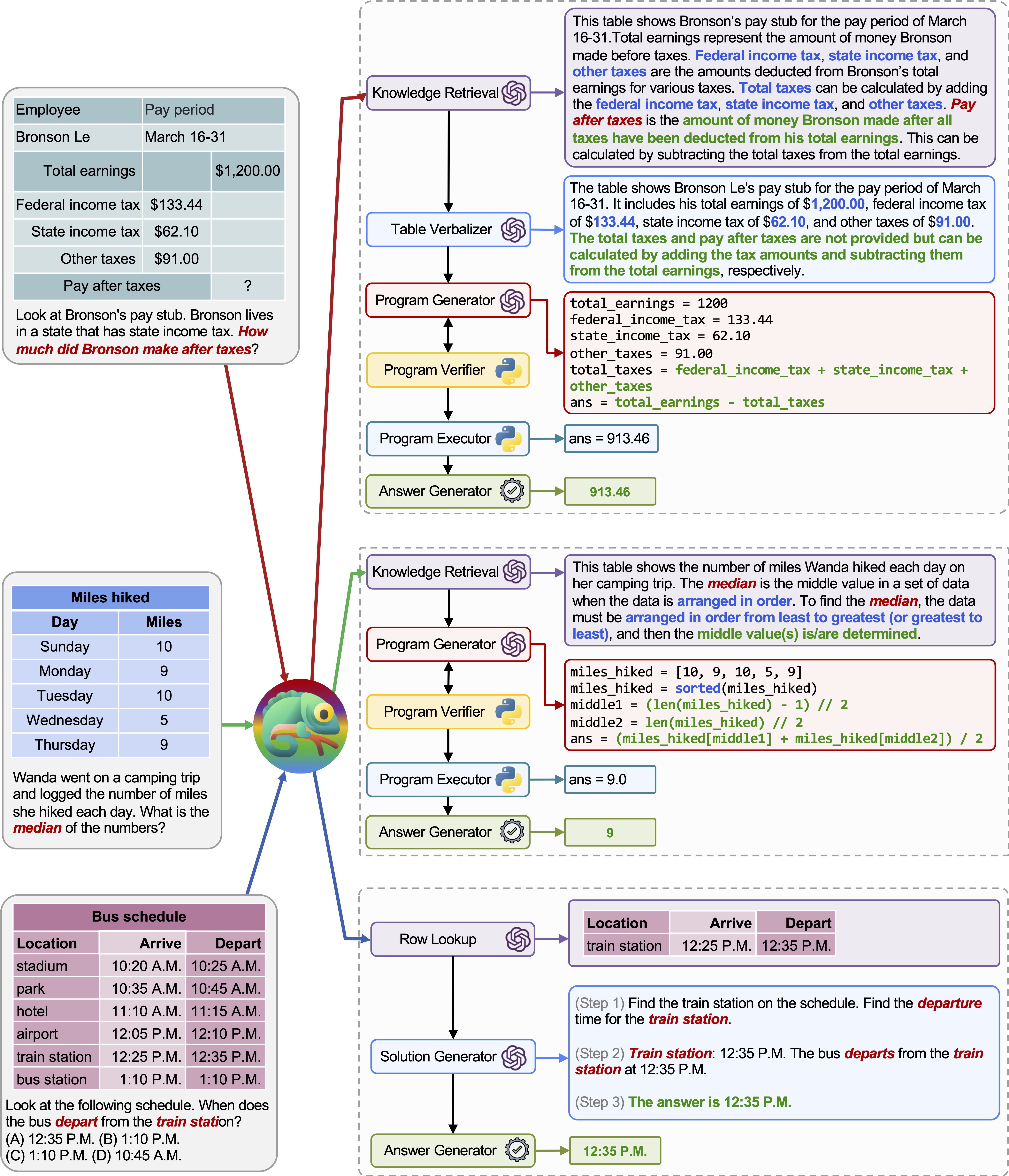
다양한 쿼리에 대한 카멜레온 의 적응성과 다양성은 위 그림의 예에서 볼 수 있듯이 TABMWP에서도 관찰됩니다.
첫 번째 예는 세금 양식의 수학적 추론과 관련이 있습니다. 카멜레온 (1) 지식 검색 모델을 호출하여 그러한 영역 별 테이블을 이해하는 데 도움이되는 기본 지식을 기억하고 (2)보다 읽기 쉬운 자연어 형식으로 표를 설명하고 (3) 마지막으로 프로그램 보조 도구에 의존합니다. 정확한 계산.
두 번째 예에서, 시스템은 지식 검색 모델이 제공하는 배경 지식과 밀접하게 일치하는 Python 코드를 생성합니다.
세 번째 예제는 시스템이 입력 쿼리가 주어진 큰 테이블 컨텍스트에서 셀을 찾아야합니다. 카멜레온은 행 조회 모델을 호출하여 프로그램 기반 도구에 의존하는 대신 관련 행을 정확하게 찾아 LLM 모델을 통해 언어 솔루션을 생성하는 데 도움이됩니다.
미세 조정 된 모델과 소수의 소수의 GPT-4/chatgpt에 대해 카멜레온 의 상당한 개선이 관찰됩니다.
카멜레온 의 예측을 시각화하려면 특정 작업에 해당하는 Jupyter 노트북을 실행하십시오. notebooks/results_viewer_[TASK].ipynb . 이는 모델에서 생성 된 결과를 탐색하는 대화식 및 사용자 친화적 인 방법을 제공합니다. 또는 자세한 정보와 옵션은 프로젝트 페이지를 살펴보십시오.
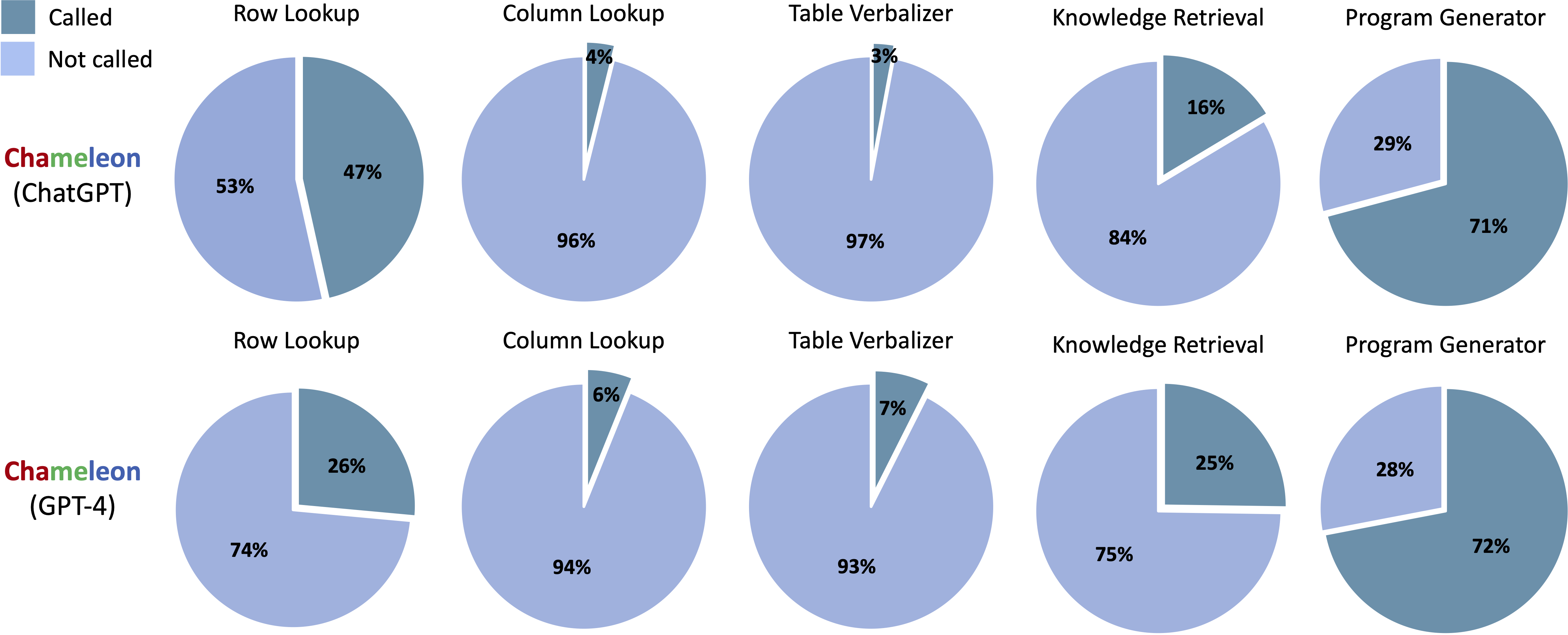
Scienceqa의 Chameleon (Chatgpt) 및 Chameleon (GPT-4)에서 생성 된 프로그램에서 호출되는 도구 :

Tabmwp의 Chameleon (Chatgpt) 및 Chameleon (GPT-4)에서 생성 된 프로그램에서 호출되는 도구 :
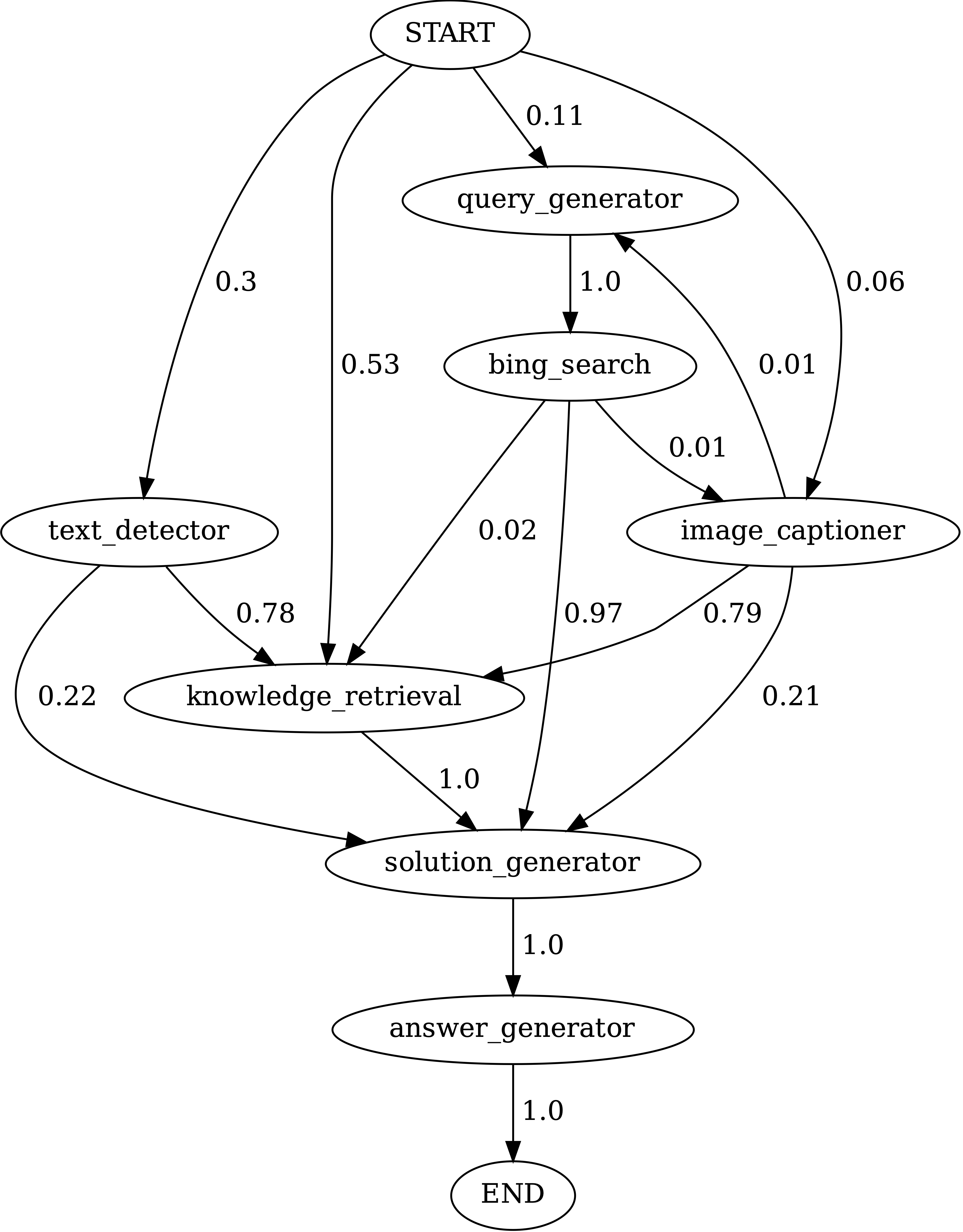
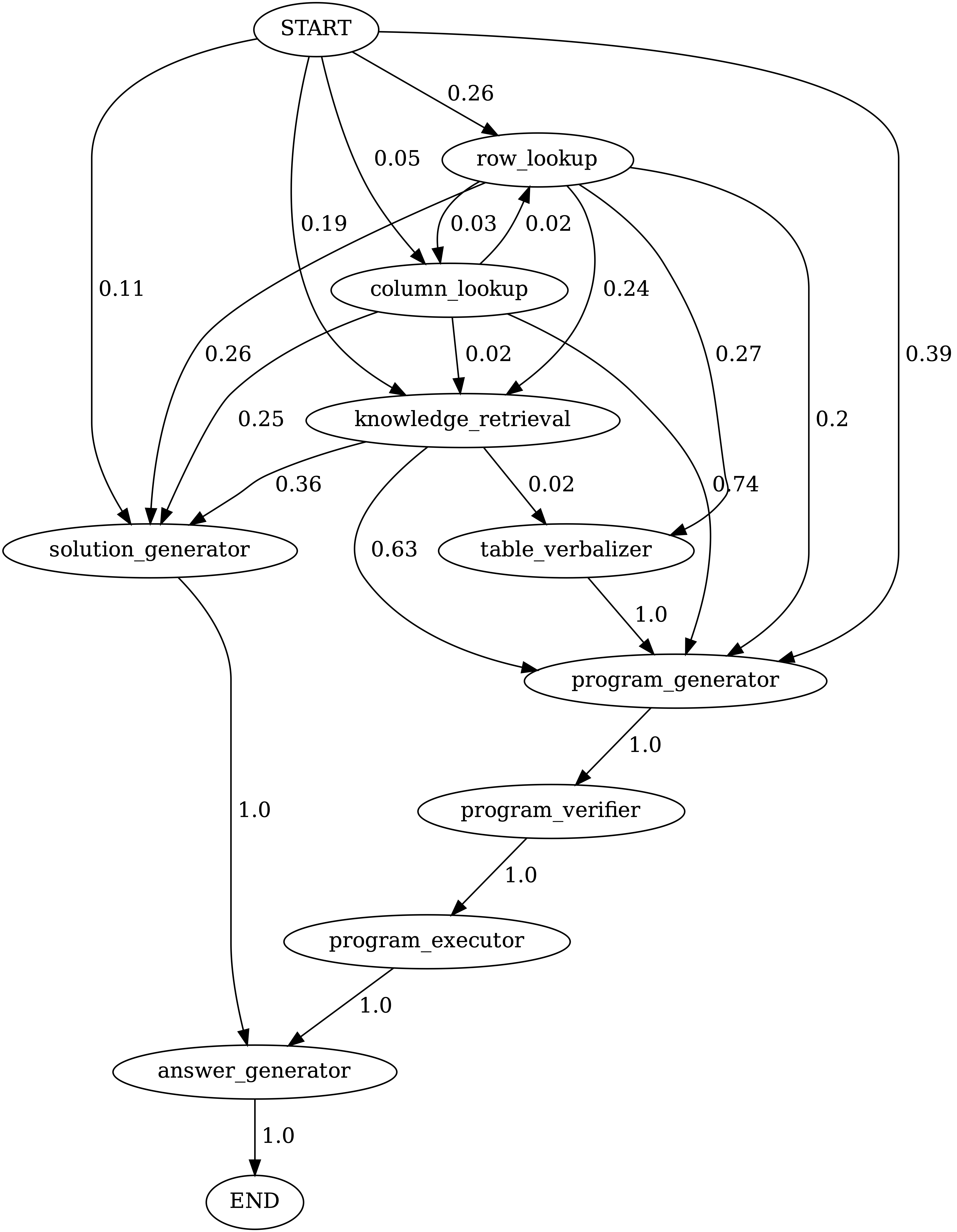
notebooks/transition_[TASK]_[Model]_Engine.ipynb 를 실행하여 테스트 세트에서 생성 된 프로그램의 모듈 전환 그래프를 시각화합니다.
ScienceQA에서 카멜레온 (GPT-4)에 의해 생성 된 프로그램의 모듈 간의 전환. 시작은 시작 기호이고, 끝은 터미널 기호이고 다른 하나는 비 말단 기호입니다.
TabmwPQA에서 카멜레온 (GPT-4)에 의해 생성 된 프로그램의 모듈 사이의 전환. 시작은 시작 기호이고, 끝은 터미널 기호이고 다른 하나는 비 말단 기호입니다.
demos 디렉토리 내에서 LLM 기반 모델에 대한 프롬프트를 만듭니다. model.py 의 각 모듈에 대한 입력, 실행 및 출력을 정의하십시오.model.py 내에서 데이터 로더를 정의하십시오. 평가 방법을 수정하려면 main.py 에서 해당 섹션을 업데이트하십시오.환상적인! 나는 항상 토론, 협업 또는 가상 커피를 공유하는 데 개방적입니다. 연락을 취하려면 연락처 정보를 보려면 Pan Lu의 홈페이지를 방문하십시오.
카멜레온이 연구 및 응용 프로그램에 유용하다고 생각되면이 Bibtex를 사용하여 친절하게 인용하십시오.
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

