chameleon llm
v1.0
論文のコード「カメレオン:大規模な言語モデルを使用したプラグアンドプレイ構成の推論」。
?ご質問や提案がある場合は、お気軽にお知らせください。電子メールアドレス[email protected]を使用してPan Luを直接メールで送信したり、Twitterにコメントしたり、このリポジトリに問題を投稿したりできます。
[プロジェクトページ] [紙] [Twitter] [LinkedIn] [YouTube] [スライド]
カメレオンの暫定ロゴ。
Chameleonは、さまざまなタイプのツールでLLMを強化するプラグアンドプレイの構成推論フレームワークです。 Chameleonは、LLMモデル、既製のビジョンモデル、Web検索エンジン、Python関数、ユーザーの関心に合わせたルールベースのモジュールなど、さまざまなツールを作成するプログラムを統合します。自然言語プランナーとしてLLMの上に構築されたChameleonは、最終的な応答を生成するために構成および実行するための適切な一連のツールを推進します。
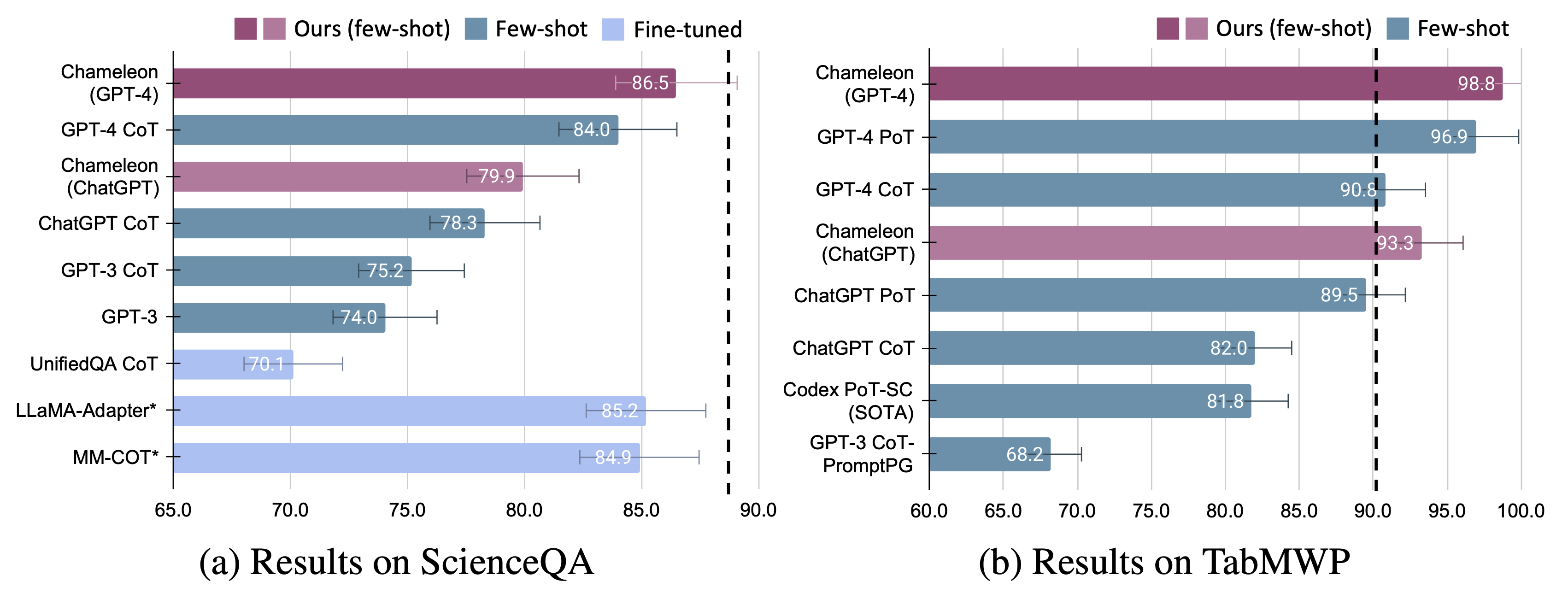
ScienceQAとTABMWPの2つのタスクでカメレオンの適応性と有効性を紹介します。特に、GPT-4のカメレオンは、ScienceQAで86.54%の精度を達成し、最高の公開された少数のショットモデルを11.37%大幅に改善します。 GPT-4を基礎となるLLMとして使用すると、 Chameleonは最先端のモデルで17.0%増加し、TABMWPで98.78%の全体的な精度をもたらしました。さらなる研究は、GPT-4をプランナーとして使用することで、より一貫した合理的なツール選択を示すことが示唆されており、CHATGPTのような他のLLMと比較して、指示を考慮して潜在的な制約を推測できることが示唆されています。
詳細については、プロジェクトページをご覧ください。
YouTubeで作品を紹介し、紹介してくれたWorldofaiに非常に感謝しています。
必要なすべてのPython依存関係( pipreqsによって生成)をインストールします。
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
必要なすべてのPython依存関係をインストールします(以前に依存関係を設定したことがあり、バージョンが厳密に必要ではない場合は、この手順をスキップできます):
pip install -r requirements.txt
https://platform.openai.com/account/api-keysからOpenai APIキーを入手してください。
ChameleonにOpenai APIキーを使用するには、請求をセットアップする必要があります(別名有料アカウント)。
https://platform.openai.com/account/billing/overviewで有料アカウントを設定できます。
https://www.microsoft.com/en-us/apis/bing-web-search-apiからBing Search APIキーを取得します。
Bing Search APIキーはオプションです。このキーを設定できないと、ScienceQAタスクがわずかなパフォーマンスが低下します。
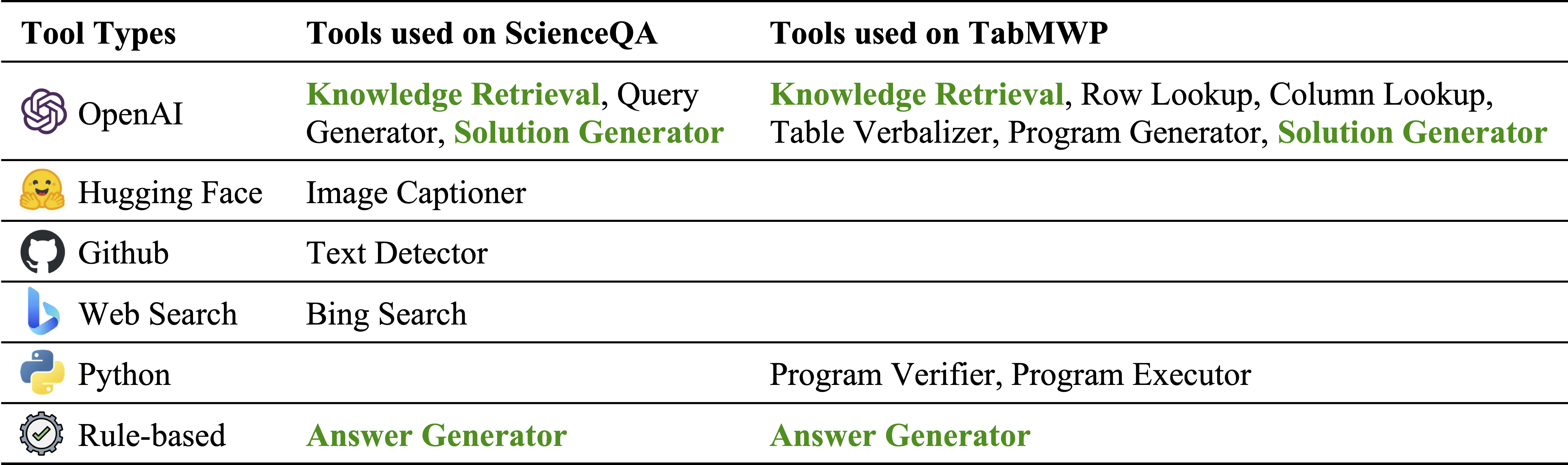
モジュールインベントリ内のさまざまなタイプのツール:

それぞれScienceQAとTABMWPで使用されるツール。 2つのタスクの再利用可能なツールは、緑色で強調表示されます。
Science質問応答(ScienceQA)は、多様なコンテキストをめぐる幅広い科学的トピックをカバーするマルチモーダルの質問アンウェーのベンチマークです。 ScienceQAデータセットはdata/scienceqaで提供されています。詳細については、データセットを探索して、Exploreページをチェックしてページを視覚化できます。
現在のバージョンの場合、 Image CaptionerとText Detectorの結果は既製であり、 data/scienceqa/captions.jsonとdata/scienceqa/ocrs.jsonにそれぞれ保存されています。これらの2つのモジュールを呼び出すライブはまもなく登場します!
カメレオンを実行する(GPT-4):
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1予測を生成し、 results/scienceqa/chameleon_gpt4_test.json 、およびresults/scienceqa/chameleon_gpt4_test_cache.jsonで結果results/scienceqa/chameleon_gpt4_test_cache.jsonl保存します。
実行することで、平均して、さまざまな質問クラスで精度メトリックを取得できます。
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlChameleonを実行する(chatgpt):
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1私たちのカメレオンは、COT(チェーンのチェーン)メソッドの一般化された形式であり、生成されたプログラムはSolution GeneratorとAnswer Generatorのシーケンスです。 cotとして--modelを通過することにより、 modules ["solution_generator", "answer_generator"]として設定されます。
コットを実行するには(考えられたチェーンプロンプト)GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1COT(考え方のチェーンプロンプト)を実行するには、ChatGPT:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1TABMWPデータセットには、38,431の表形式の数学ワードの問題が含まれています。 TABMWPの各質問は、画像、半構造化されたテキスト、および構造化されたテーブルとして表示される表形式のコンテキストと整合しています。 TABMWPデータセットは、 data/tabmwpで提供されています。詳細については、Datatatsetを探索して、Exploreページをご覧ください。ページを視覚化できます。
カメレオンを実行する(GPT-4):
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18それは予測を生成し、 results/tabmwp/chameleon_gpt4_test.json 、およびresults/tabmwp/chameleon_gpt4_test_cache.json results/tabmwp/chameleon_gpt4_test_cache.jsonl結果を保存します。
実行することで、平均して、さまざまな質問クラスで精度メトリックを取得できます。
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlChameleonを実行する(chatgpt):
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18コットを実行するには(考えられたチェーンプロンプト)GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1COT(考え方のチェーンプロンプト)を実行するには、ChatGPT:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1私たちのカメレオンは、一般化されたフォームのポット(プログラム)メソッドであり、生成されたプログラムは、 Program Generator 、 Program Executor 、およびAnswer Generatorのシーケンスです。 potとして--modelを渡すことにより、 modules ["program_generator", "program_executor", "answer_generator"]として設定されます。
ポットを走らせる(思考プログラムが促された)GPT-4:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1ポット(思考プログラムプロンプト)を実行するには、chatgpt:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1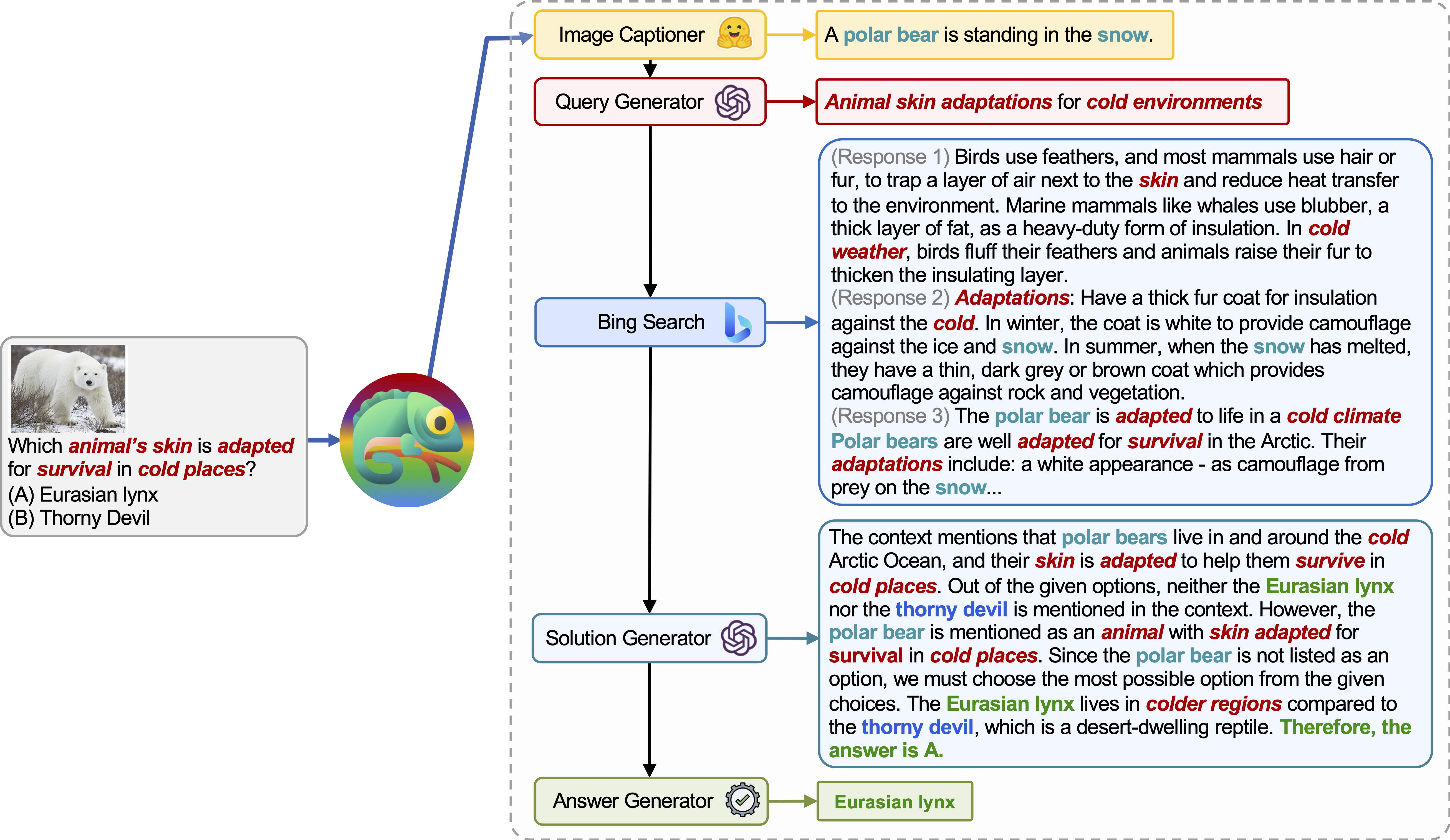
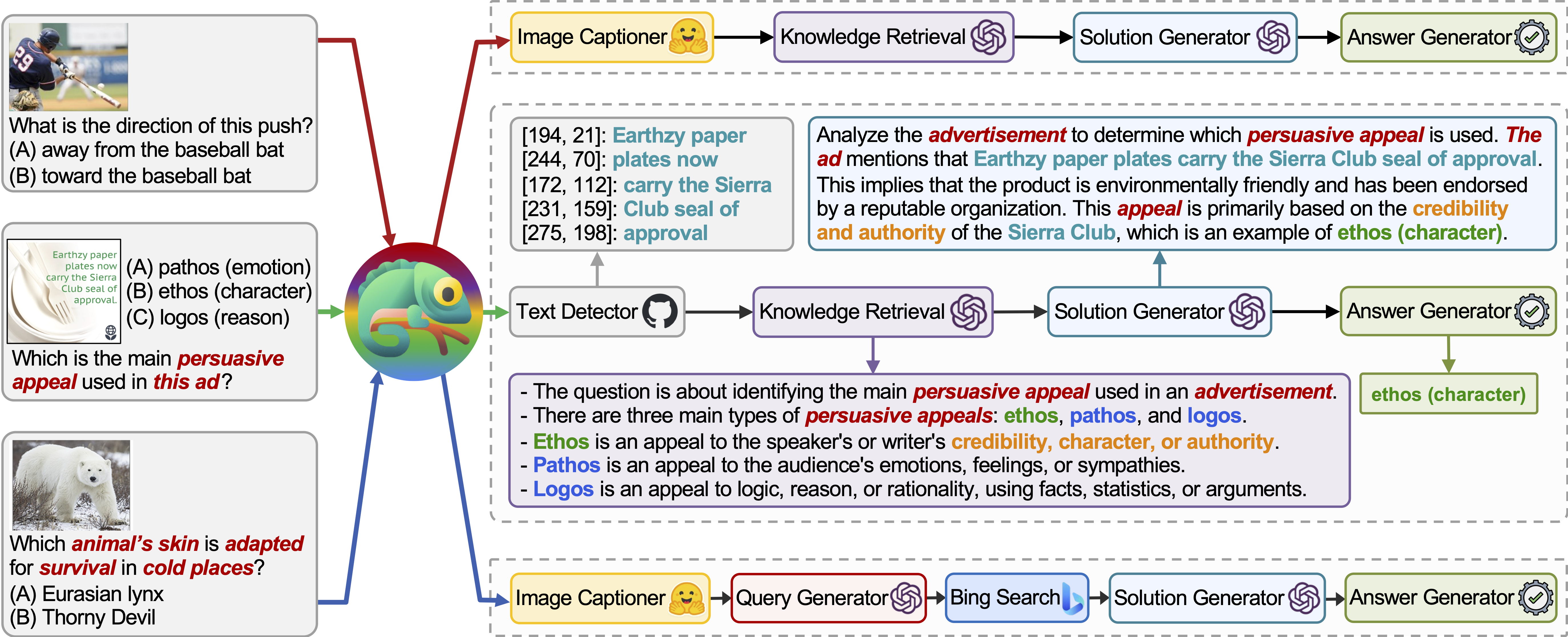
Chameleon (GPT-4)は、さまざまなツールを構成するプログラムを生成し、正解を取得するためにそれらを順番に実行することにより、さまざまな入力クエリに適応することができます。
たとえば、上記のクエリには、「動物の生存が寒い場所で生存するためにどの動物の皮膚が適応されていますか?」と尋ねます。これには、動物の生存に関連する科学用語が含まれます。その結果、プランナーは、ドメイン固有の知識をBing検索エンジンに依存することを決定し、利用可能な多数のオンラインリソースの恩恵を受けます。
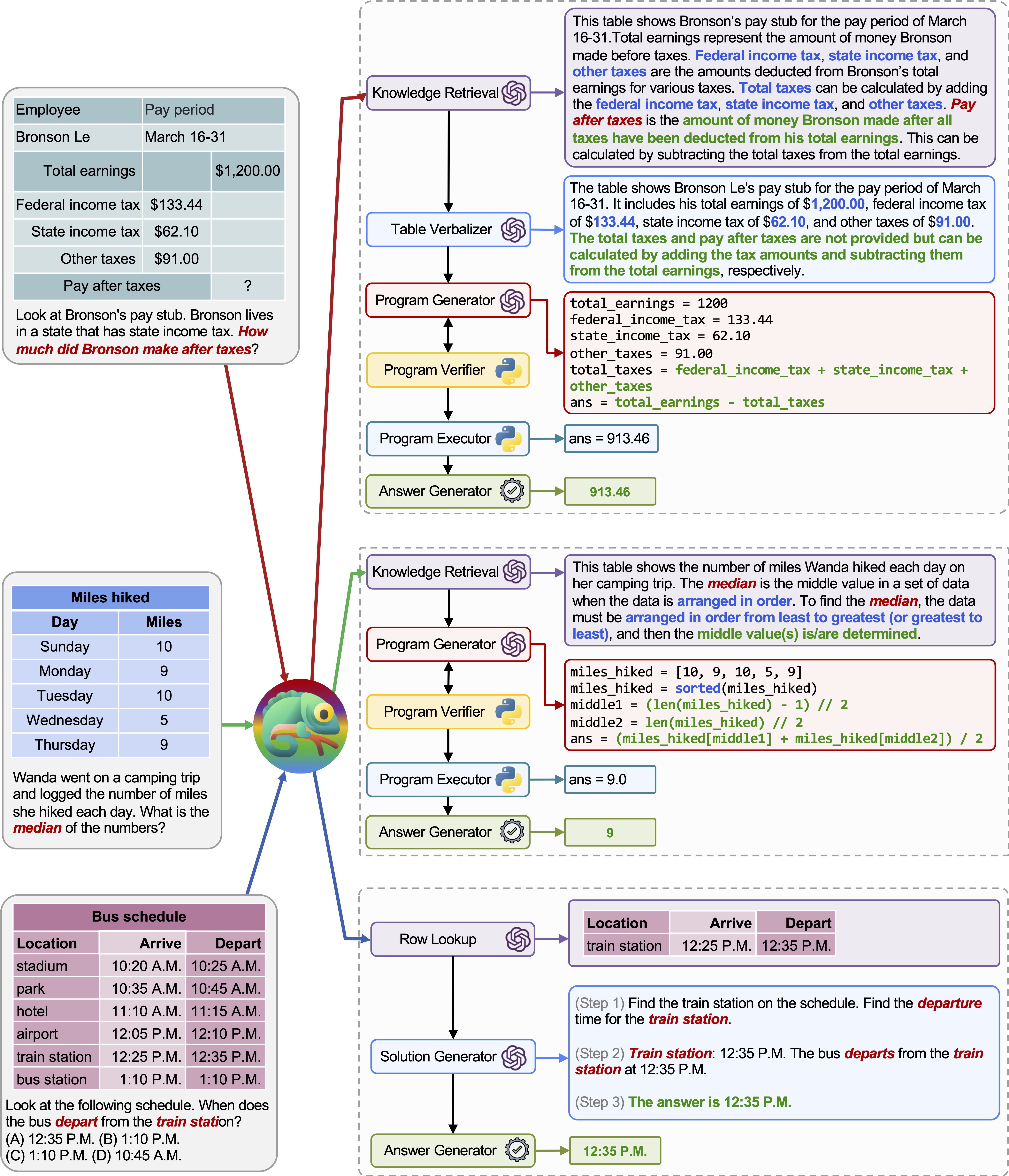
上の図の例に示すように、さまざまなクエリに対するカメレオンの適応性と汎用性もTabmwpで観察されます。
最初の例では、税務フォームの数学的推論が含まれます。 Chameleon (1)は、知識検索モデルを呼び出して、このようなドメイン固有のテーブルを理解するのに役立つ基本的な知識を思い出します。正確な計算。
2番目の例では、システムは、知識検索モデルによって提供される背景知識と密接に整合するPythonコードを生成します。
3番目の例では、入力クエリを考慮して、システムが大きな表形式のコンテキストでセルを特定する必要があります。 Chameleonは、プログラムベースのツールに依存するのではなく、関連する行を正確に見つけ、LLMモデルを介して言語ソリューションを生成するために行ルックアップモデルを呼び出します。
微調整されたモデルと少数のショットの両方のGPT-4/ChatGPTの両方でカメレオンの大幅な改善が観察されます。
Chameleonによって行われた予測を視覚化するには、特定のタスクに対応するJupyterノートブックを実行するだけです: notebooks/results_viewer_[TASK].ipynb 。これにより、モデルによって生成された結果を調査するためのインタラクティブでユーザーフレンドリーな方法が提供されます。または、詳細とオプションについては、プロジェクトページをご覧ください。
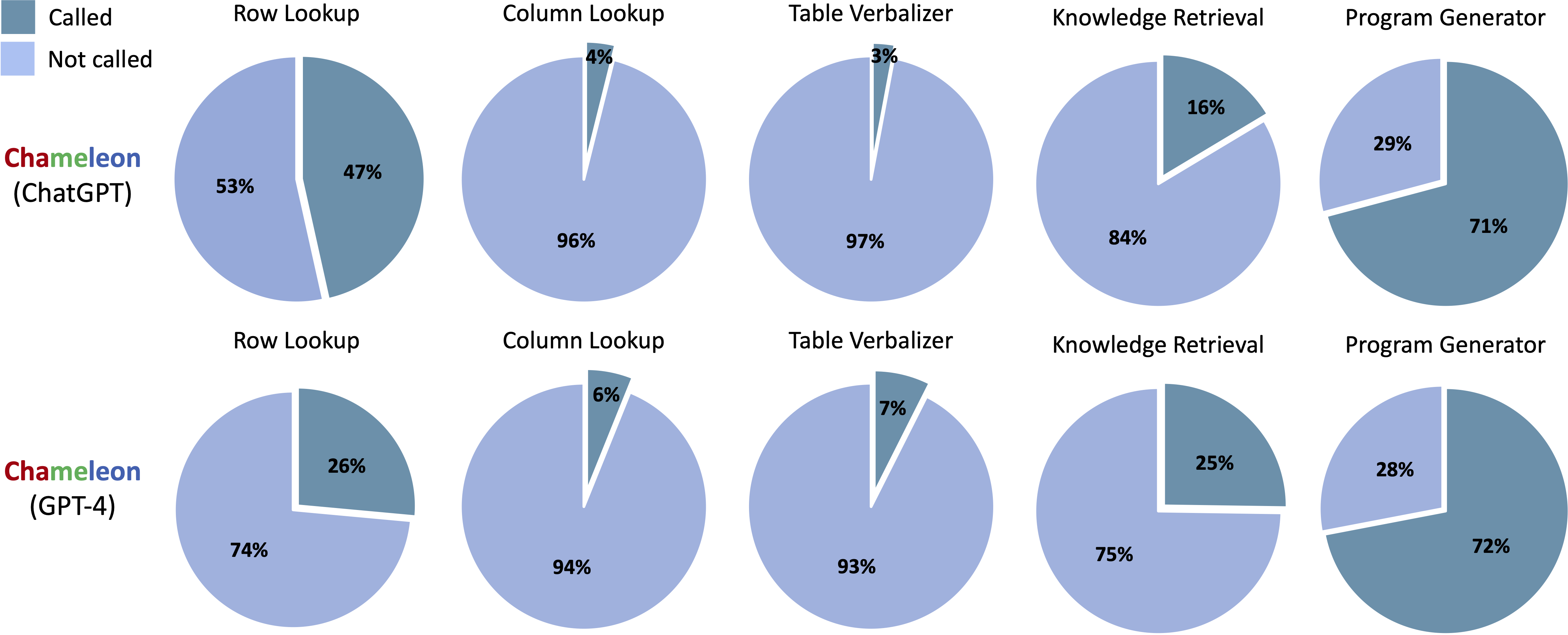
ScienceqaのChameleon (ChatGpt)とChameleon (GPT-4)から生成されたプログラムで呼ばれるツール:

TabmwpのChameleon(ChatGpt)とChameleon(GPT-4)から生成されたプログラムで呼ばれるツール:
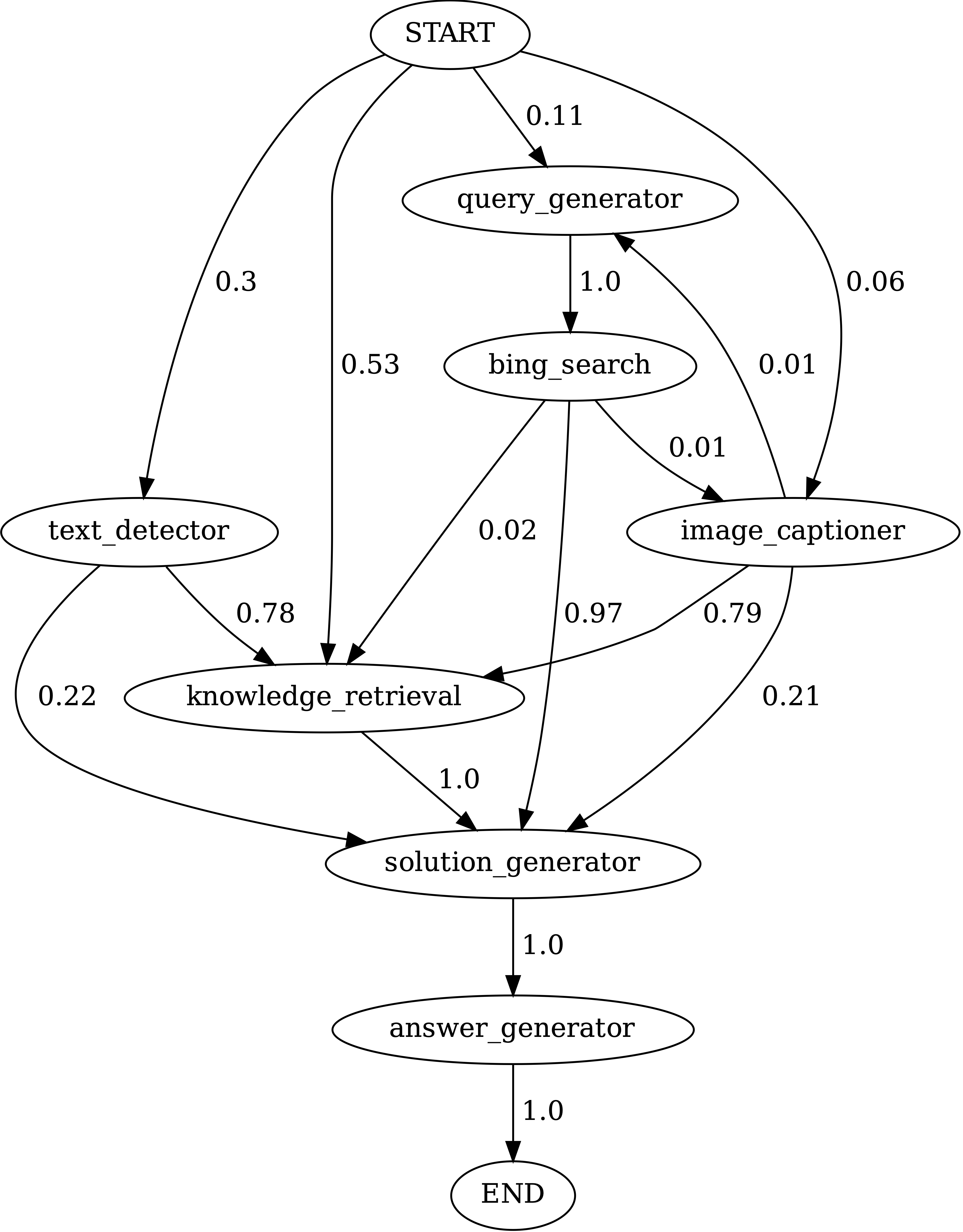
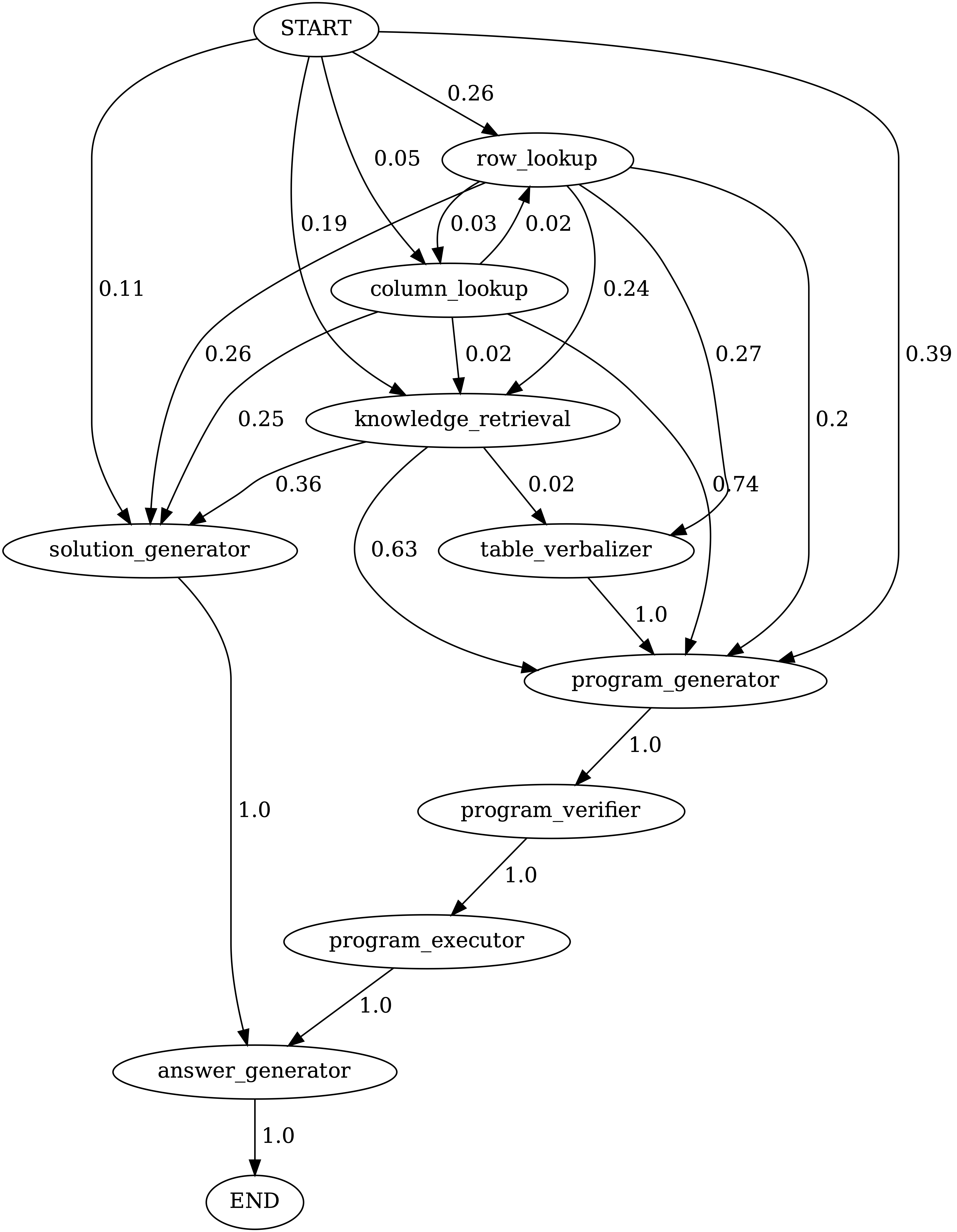
notebooks/transition_[TASK]_[Model]_Engine.ipynbテストセットで生成されたプログラムのモジュールトランジショングラフを視覚化します。
ScienceqaでChameleon (GPT-4)によって生成されたプログラムのモジュール間の遷移。 StartはStart Symbol、Endは末端シンボル、その他は非末端シンボルです。
TabmwpqaでChameleon (GPT-4)によって生成されたプログラムのモジュール間の遷移。 StartはStart Symbol、Endは末端シンボル、その他は非末端シンボルです。
demos内でLLMベースのモデルのプロンプトを作成します。 model.pyの各モジュールの入力、実行、および出力を定義します。model.py内のデータローダーを定義します。評価方法を変更するには、 main.pyの対応するセクションを更新します。素晴らしい!私は常に、議論、コラボレーション、または仮想コーヒーを共有することさえ魅了することにオープンです。連絡するために、連絡先情報についてはPan Luのホームページにアクセスしてください。
Chameleonが研究やアプリケーションに役立つと思われる場合は、このbibtexを使用して親切に引用してください。
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

