chameleon llm
v1.0
Código para o artigo "Chameleon: raciocínio composicional plug-and-play com grandes modelos de idiomas".
? Se você tiver alguma dúvida ou sugestão, não hesite em nos informar. Você pode enviar um email diretamente a Pan Lu usando o endereço de email [email protected], comentar no Twitter ou postar um problema neste repositório.
[Página do projeto] [Paper] [Twitter] [LinkedIn] [YouTube] [slides]
Logotipo tentativo para Chameleon .
O Chameleon é uma estrutura de raciocínio de composição plug-and-play que aumenta o LLMS com vários tipos de ferramentas. O Chameleon sintetiza programas para compor várias ferramentas, incluindo modelos LLM, modelos de visão pronta para uso, mecanismos de pesquisa da web, funções Python e módulos baseados em regras adaptados aos interesses do usuário. Construído em cima de um LLM como planejador de linguagem natural, o Chameleon infere a sequência apropriada de ferramentas para compor e executar para gerar uma resposta final.
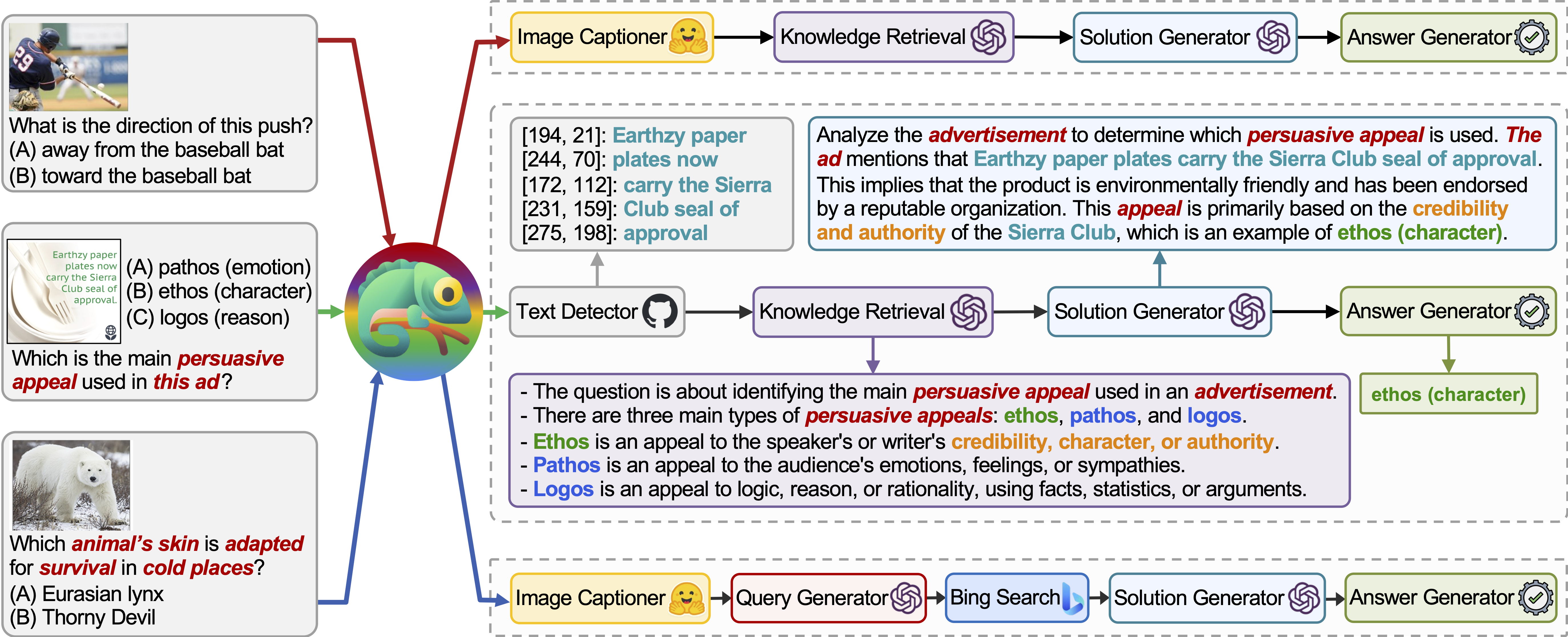
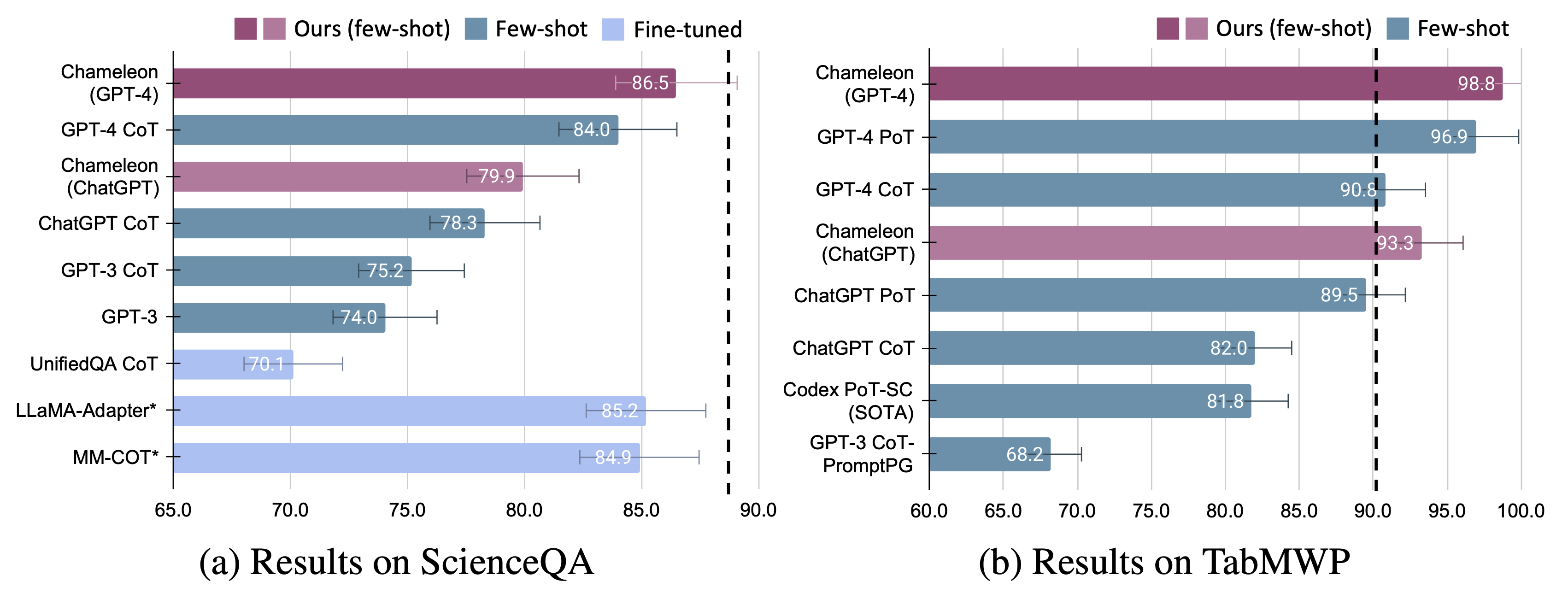
Mostramos a adaptabilidade e a eficácia do Chameleon em duas tarefas: ScienceQa e Tabmwp. Notavelmente, o Chameleon com GPT-4 atinge uma precisão de 86,54% no ScienceQA, melhorando significativamente o melhor modelo publicado de poucos publicados em 11,37%; Usando o GPT-4 como LLM subjacente, o Chameleon alcança um aumento de 17,0% em relação ao modelo de ponta, levando a uma precisão geral de 98,78% no TABMWP. Estudos adicionais sugerem que o uso do GPT-4 como planejador exibe seleção de ferramentas mais consistente e racional e é capaz de inferir possíveis restrições, dadas as instruções, em comparação com outros LLMs como o ChatGPT.
Para mais detalhes, você pode encontrar nossa página de projeto aqui e nosso artigo aqui.
Gostaríamos de expressar nossa imensa gratidão ao Worndofai por apresentar e apresentar nosso trabalho no YouTube!
Instale todas as dependências do Python necessárias (geradas pelo pipreqs ):
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
Instale todas as dependências do Python necessárias (você pode pular esta etapa se configurar as dependências antes e as versões não forem estritamente necessárias):
pip install -r requirements.txt
Obtenha sua chave da API do OpenAI em: https://platform.openai.com/account/api-keys.
Para usar a chave da API OpenAI para Chameleon , você precisa configurar o faturamento (também conhecido como conta paga).
Você pode configurar a conta paga em https://platform.openai.com/account/billing/overview.
Obtenha sua tecla API de pesquisa de Bing em: https://www.microsoft.com/en-us/bing/bing/apis/bing-web-search-api.
A chave da API de pesquisa do Bing é opcional . A falha em configurar essa chave levará a uma pequena queda de desempenho na tarefa da ScienceQA.
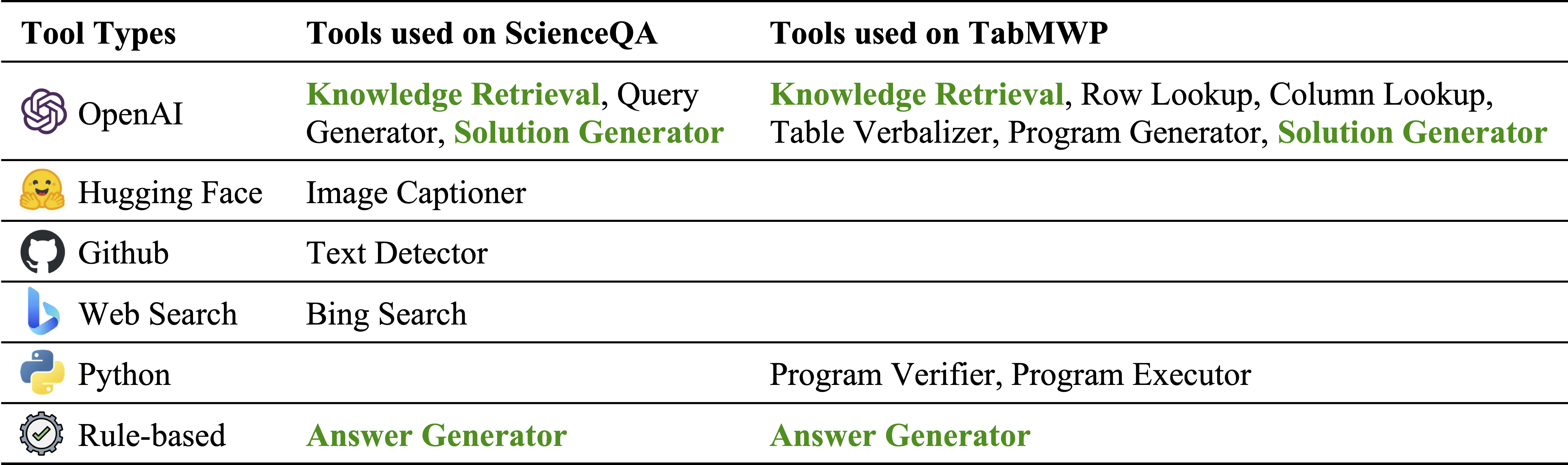
Diferentes tipos de ferramentas em nosso inventário de módulos:

Ferramentas usadas no ScienceQA e Tabmwp, respectivamente. As ferramentas reutilizáveis em duas tarefas são destacadas em verde:
A resposta de perguntas científicas (ScienceQA) é um benchmark multimodal que impede de perguntas, cobrindo uma ampla gama de tópicos científicos em diversos contextos. O conjunto de dados da ScienceQA é fornecido no data/scienceqa . Para mais detalhes, você pode explorar o conjunto de dados e conferir a página Explorar e visualizar a página.
Para a versão atual, os resultados para o Image Captioner e Text Detector são prontos para uso e armazenados em data/scienceqa/captions.json e data/scienceqa/ocrs.json , respectivamente. O LIVE chamando esses dois módulos estão chegando em breve!
Para executar o Chameleon (GPT-4):
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 Ele gerará as previsões e salvará os resultados nos results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl e results/scienceqa/chameleon_gpt4_test_cache.json .
Podemos obter as métricas de precisão em média e em diferentes classes de perguntas, executando:
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlPara executar o Chameleon (chatgpt):
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 Nosso camaleão é uma forma generalizada do método Cot (cadeia de pensamento), onde o programa gerado é uma sequência de Solution Generator e Answer Generator . Ao passar --model como cot , modules são definidos como ["solution_generator", "answer_generator"] .
Para executar o berço (solicitação de cadeia de pensamento) GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1Para executar o BOT (cadeia de pensamento solicitada) ChatGPT:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 O conjunto de dados TABMWP contém 38.431 problemas de palavra matemática tabular. Cada pergunta no TABMWP está alinhada com um contexto tabular, que é apresentado como uma imagem, texto semiestruturado e uma tabela estruturada. O conjunto de dados TABMWP é fornecido no data/tabmwp . Para mais detalhes, você pode explorar o DatatSet e conferir a página Explorar e visualizar a página.
Para executar o Chameleon (GPT-4):
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 Ele gerará as previsões e salvará os resultados nos results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl e results/tabmwp/chameleon_gpt4_test_cache.json .
Podemos obter as métricas de precisão em média e em diferentes classes de perguntas, executando:
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlPara executar o Chameleon (chatgpt):
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18Para executar o berço (solicitação de cadeia de pensamento) GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1Para executar o BOT (cadeia de pensamento solicitada) ChatGPT:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 Nosso Chameleon é uma forma generalizada do método POT (Programa de pensamento), onde o programa gerado é uma sequência de Program Generator , Program Executor e Answer Generator . Ao passar --model como pot , modules são definidos como ["program_generator", "program_executor", "answer_generator"] .
Para executar maconha (providenciado pelo programa de pensamento) GPT-4:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1Para executar o pote (o programa de pensamento solicitado) ChatGPT:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1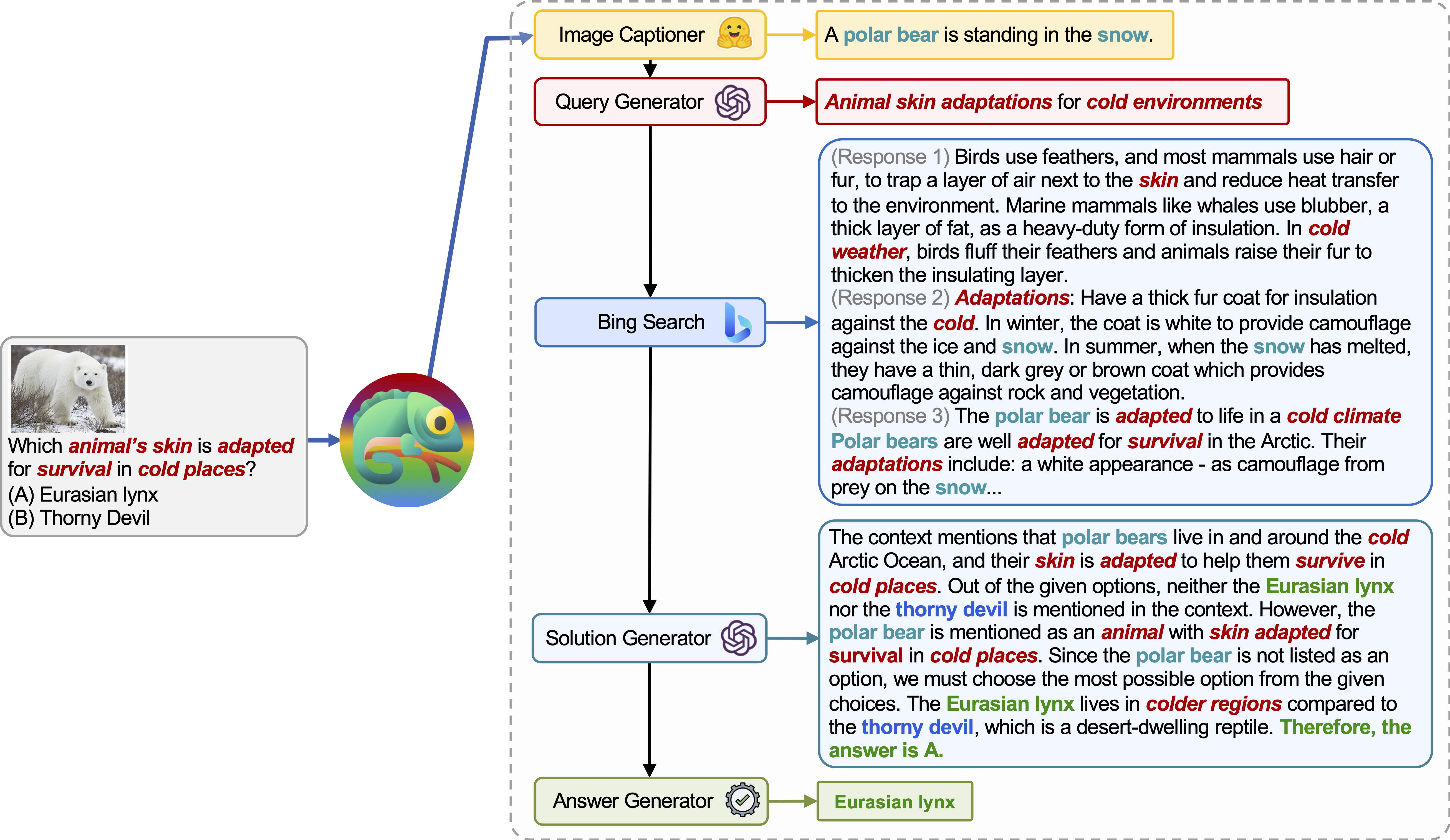
O Chameleon (GPT-4) é capaz de se adaptar a diferentes consultas de entrada, gerando programas que compõem várias ferramentas e executando-as sequencialmente para obter as respostas corretas.
Por exemplo, a consulta acima pergunta: “Qual pele do animal está adaptada para a sobrevivência em lugares frios?”, Que envolve terminologia científica relacionada à sobrevivência animal. Consequentemente, o planejador decide confiar no mecanismo de busca do Bing para obter conhecimentos específicos de domínio, beneficiando-se dos inúmeros recursos on-line disponíveis.
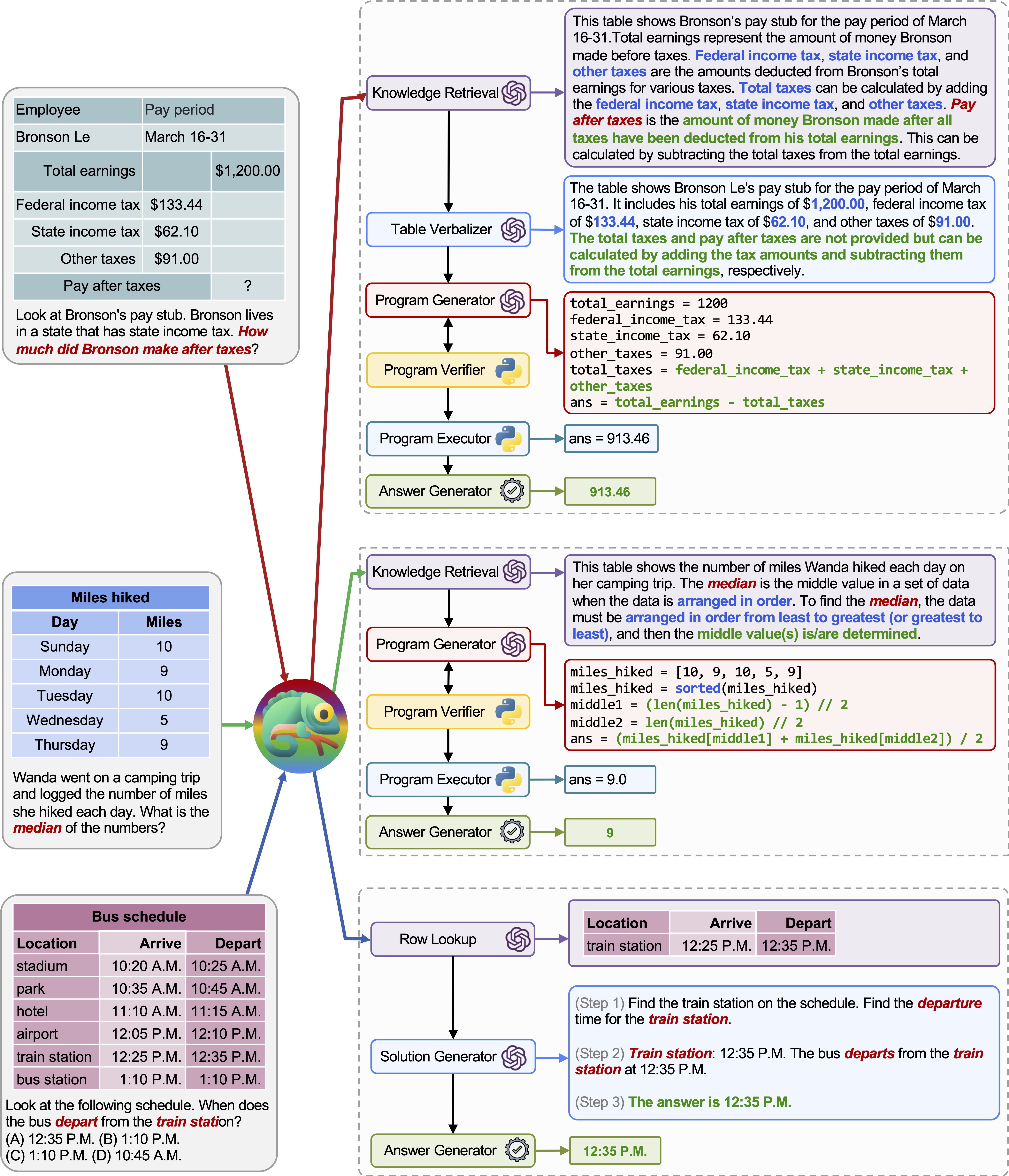
A adaptabilidade e a versatilidade do nosso camaleão para várias consultas também são observadas no TABMWP, conforme ilustrado nos exemplos da figura acima.
O primeiro exemplo envolve o raciocínio matemático em um formulário tributário. Chameleon (1) chama o modelo de recuperação de conhecimento para recuperar o conhecimento básico que ajuda a entender essas tabelas específicas de domínio, (2) descreve a tabela em um formato de linguagem natural mais legível e (3) finalmente depende de ferramentas auxiliadas pelo programa para executar cálculos precisos.
No segundo exemplo, o sistema gera código Python que se alinha de perto com o conhecimento de fundo fornecido pelo modelo de recuperação de conhecimento.
O terceiro exemplo exige que o sistema localize a célula em um grande contexto tabular, dada a consulta de entrada. Chameleon chama o modelo de pesquisa de linha para ajudar a localizar com precisão as linhas relevantes e gerar a solução de idiomas por meio de um modelo LLM, em vez de confiar nas ferramentas baseadas em programas.
Melhorias significativas são observadas para o Chameleon em relação aos modelos de ajuste fino e com poucos anos levando GPT-4/ChatGPT:
Para visualizar as previsões feitas pelo Chameleon , basta executar o notebook Jupyter correspondente à sua tarefa específica: notebooks/results_viewer_[TASK].ipynb . Isso fornecerá uma maneira interativa e fácil de usar para explorar os resultados gerados pelo modelo. Como alternativa, explore nossa página do projeto para obter mais informações e opções.
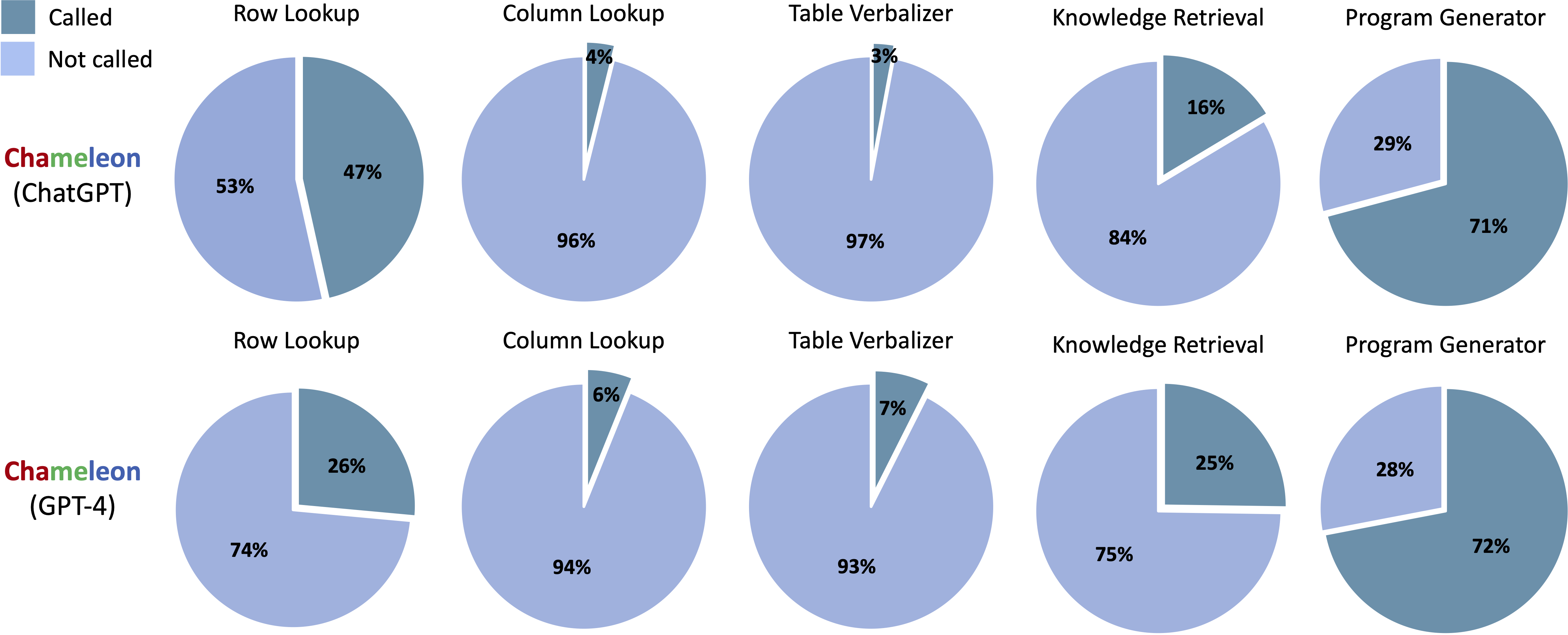
Ferramentas chamadas nos programas gerados de Chameleon (ChatGPT) e Chameleon (GPT-4) em ScienceQa:

Ferramentas chamadas nos programas gerados do Chameleon (ChatGPT) e Chameleon (GPT-4) no TABMWP:
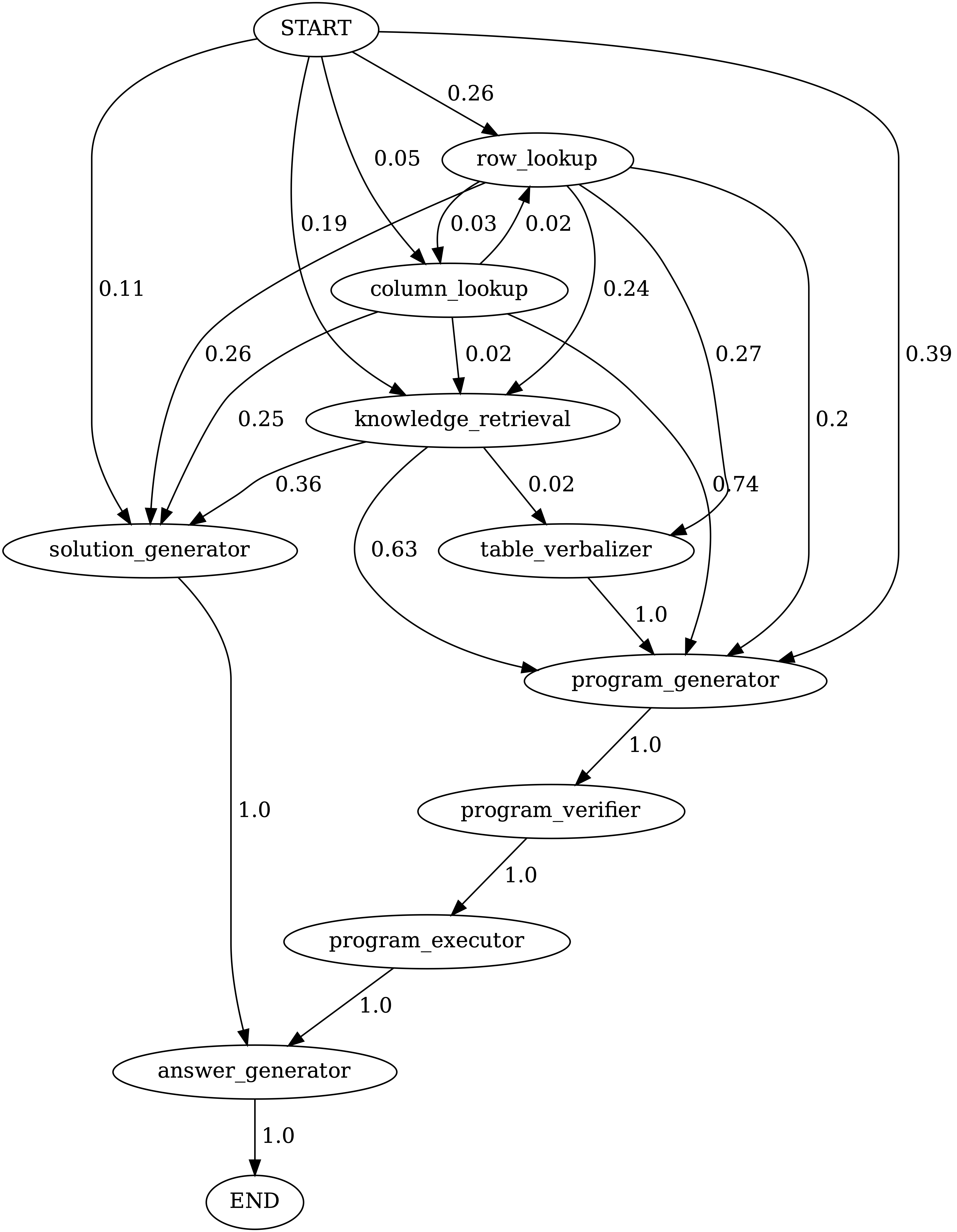
Executar notebooks/transition_[TASK]_[Model]_Engine.ipynb para visualizar o gráfico de transição do módulo para programas gerados no conjunto de testes.
Transições entre módulos em programas gerados pelo Chameleon (GPT-4) em ScienceQa. Start é o símbolo de início, o final é um símbolo terminal e os outros são símbolos não terminais.
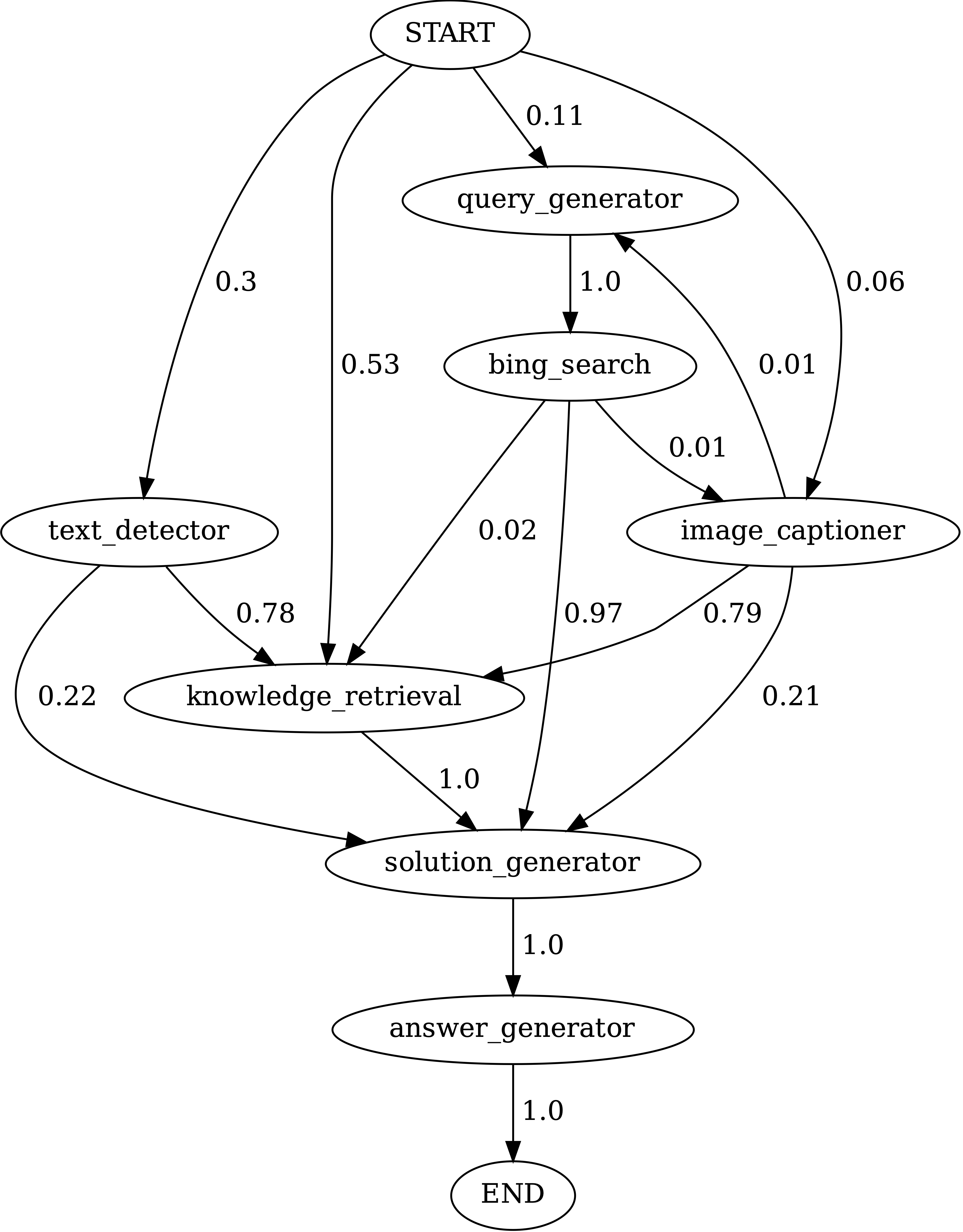
Transições entre módulos em programas gerados pelo Chameleon (GPT-4) no TabMWPQA. Start é o símbolo de início, o final é um símbolo terminal e os outros são símbolos não terminais.
demos . Defina a entrada, a execução e a saída para cada módulo no model.py .model.py . Para modificar o método de avaliação, atualize a seção correspondente em main.pyFantástico! Estou sempre aberto a discussões, colaborações, ou mesmo apenas compartilhar um café virtual. Para entrar em contato, visite a página inicial de Pan Lu para obter informações de contato.
Se você achar o Chameleon útil para sua pesquisa e aplicações, cite gentilmente usando este Bibtex:
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

