chameleon llm
v1.0
Kode untuk kertas "Chameleon: Plug-and-Play Komposisi Penalaran dengan model bahasa besar".
? Jika Anda memiliki pertanyaan atau saran, jangan ragu untuk memberi tahu kami. Anda dapat langsung mengirim email kepada Pan Lu menggunakan alamat email [email protected], mengomentari Twitter, atau memposting masalah di repositori ini.
[Halaman Proyek] [kertas] [Twitter] [LinkedIn] [YouTube] [Slide]
Logo sementara untuk bunglon .
Chameleon adalah kerangka penalaran komposisi plug-and-play yang menambah LLM dengan berbagai jenis alat. Chameleon mensintesis program untuk menyusun berbagai alat, termasuk model LLM, model visi di luar rak, mesin pencari web, fungsi python, dan modul berbasis aturan yang disesuaikan dengan minat pengguna. Dibangun di atas LLM sebagai perencana bahasa alami, Chameleon menyimpulkan urutan alat yang tepat untuk menyusun dan mengeksekusi untuk menghasilkan respons akhir.
Kami memamerkan kemampuan beradaptasi dan efektivitas bunglon pada dua tugas: scienceqa dan tabmwp. Khususnya, bunglon dengan GPT-4 mencapai akurasi 86,54% di scienceQA, secara signifikan membaik pada model beberapa shot terbaik yang diterbitkan sebesar 11,37%; Menggunakan GPT-4 sebagai LLM yang mendasarinya, Chameleon mencapai peningkatan 17,0% dari model canggih, yang mengarah ke akurasi keseluruhan 98,78% pada TABMWP. Studi lebih lanjut menunjukkan bahwa menggunakan GPT-4 sebagai perencana menunjukkan pemilihan alat yang lebih konsisten dan rasional dan mampu menyimpulkan kendala potensial mengingat instruksi, dibandingkan dengan LLM lain seperti ChatGPT.
Untuk detail lebih lanjut, Anda dapat menemukan halaman proyek kami di sini dan makalah kami di sini.
Kami ingin mengucapkan terima kasih besar kepada Worldofai untuk menampilkan dan memperkenalkan karya kami di YouTube!
Instal semua dependensi Python yang diperlukan (dihasilkan oleh pipreqs ):
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
Instal semua dependensi Python yang diperlukan (Anda dapat melewatkan langkah ini jika Anda telah mengatur dependensi sebelumnya dan versi tidak sepenuhnya diperlukan):
pip install -r requirements.txt
Dapatkan Kunci API OpenAI Anda dari: https://platform.openai.com/account/api-keys.
Untuk menggunakan tombol API OpenAI untuk Chameleon , Anda harus mengatur tagihan (alias akun berbayar).
Anda dapat mengatur akun berbayar di https://platform.openai.com/account/billing/overview.
Dapatkan kunci API pencarian Bing Anda dari: https://www.microsoft.com/en-us/bing/apis/bing-web-search-api.
Kunci API pencarian Bing adalah opsional . Kegagalan untuk mengatur kunci ini akan menyebabkan sedikit penurunan kinerja pada tugas ScienceQA.
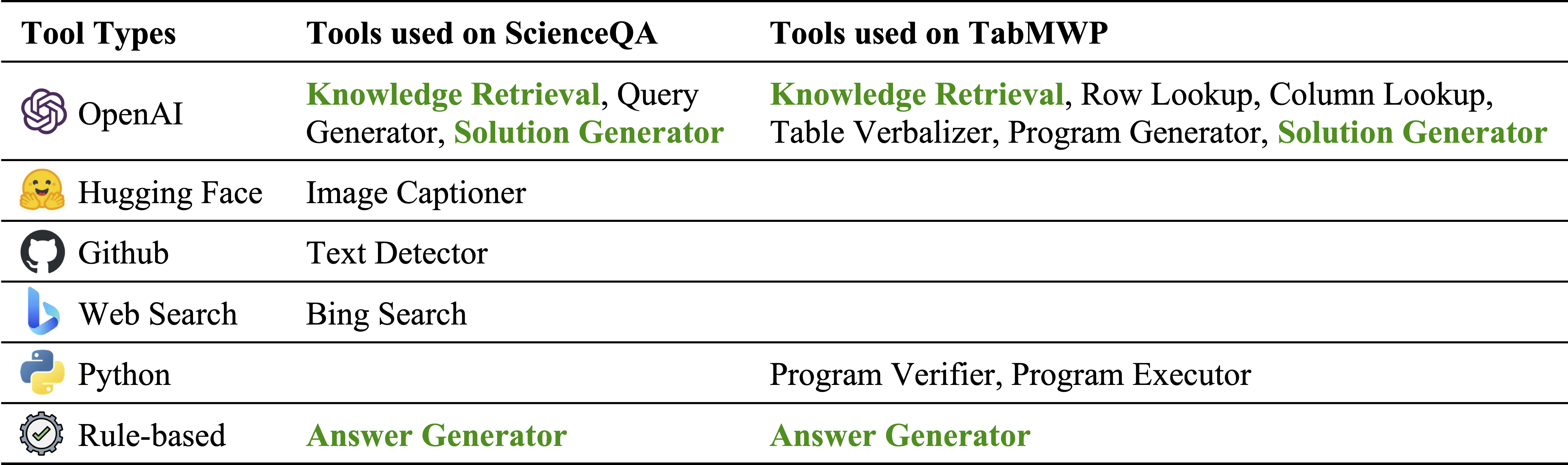
Berbagai jenis alat dalam inventaris modul kami:

Alat yang digunakan masing -masing pada ScienceQA dan TABMWP. Alat yang dapat digunakan kembali dalam dua tugas disorot dengan warna hijau:
Penjawab pertanyaan sains (ScienceQA) adalah tolok ukur jawaban multi-modal yang mencakup berbagai topik ilmiah di atas konteks yang beragam. Dataset ScienceQA disediakan dalam data/scienceqa . Untuk detail lebih lanjut, Anda dapat menjelajahi dataset dan memeriksa halaman Explore dan visualisasikan.
Untuk versi saat ini, hasil untuk Image Captioner dan Text Detector adalah di luar rak dan disimpan dalam data/scienceqa/captions.json dan data/scienceqa/ocrs.json , masing-masing. The Live Calling kedua modul ini akan segera hadir!
Untuk menjalankan bunglon (GPT-4):
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 Ini akan menghasilkan prediksi dan menyimpan hasilnya di results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl , dan results/scienceqa/chameleon_gpt4_test_cache.json .
Kita bisa mendapatkan metrik akurasi rata -rata dan di berbagai kelas pertanyaan dengan menjalankan:
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlUntuk menjalankan bunglon (chatgpt):
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 Bunglon kami adalah bentuk umum dari metode COT (rantai-dipikirkan), di mana program yang dihasilkan adalah urutan Solution Generator dan Answer Generator . Dengan melewati --model sebagai cot , modules diatur sebagai ["solution_generator", "answer_generator"] .
Untuk menjalankan cot (rantai-dipikirkan diminta) GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1Untuk menjalankan cot (rantai-dipikirkan diminta) chatgpt:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 Dataset TABMWP berisi 38.431 masalah kata matematika tabular. Setiap pertanyaan di TABMWP disejajarkan dengan konteks tabular, yang disajikan sebagai gambar, teks semi-terstruktur, dan tabel terstruktur. Dataset TABMWP disediakan dalam data/tabmwp . Untuk detail lebih lanjut, Anda dapat menjelajahi DATATSET dan memeriksa halaman Explore dan Visualisasikan.
Untuk menjalankan bunglon (GPT-4):
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 Ini akan menghasilkan prediksi dan menyimpan hasilnya di results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl , dan results/tabmwp/chameleon_gpt4_test_cache.json .
Kita bisa mendapatkan metrik akurasi rata -rata dan di berbagai kelas pertanyaan dengan menjalankan:
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlUntuk menjalankan bunglon (chatgpt):
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18Untuk menjalankan cot (rantai-dipikirkan diminta) GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1Untuk menjalankan cot (rantai-dipikirkan diminta) chatgpt:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 Bunglon kami adalah bentuk umum dari metode pot (program-dipikirkan), di mana program yang dihasilkan adalah urutan Program Generator , Program Executor , dan Answer Generator . Dengan meneruskan --model sebagai pot , modules ditetapkan sebagai ["program_generator", "program_executor", "answer_generator"] .
Untuk menjalankan pot (program-dipikirkan diminta) GPT-4:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1Untuk menjalankan pot (program-dipikirkan diminta) chatgpt:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1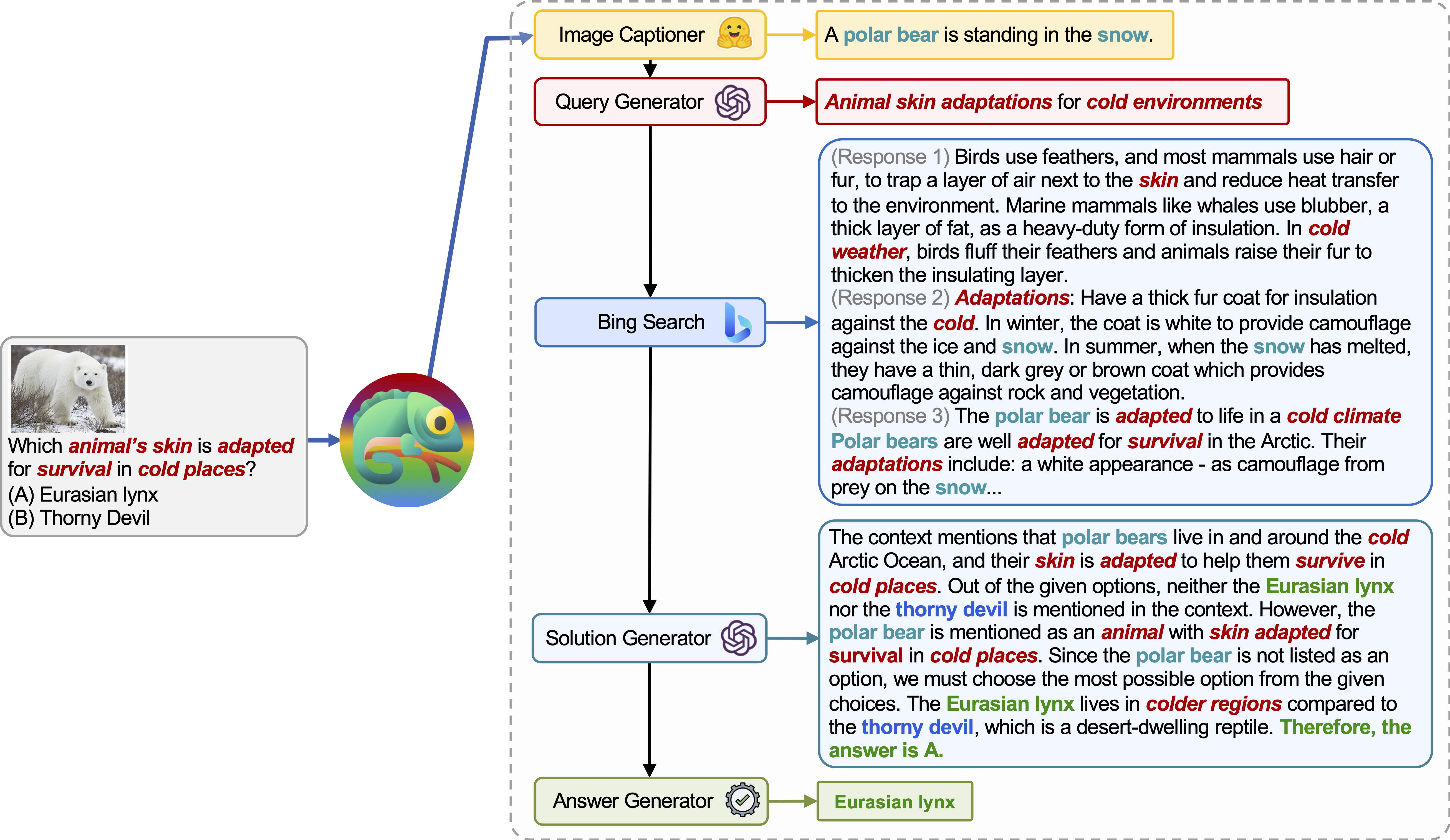
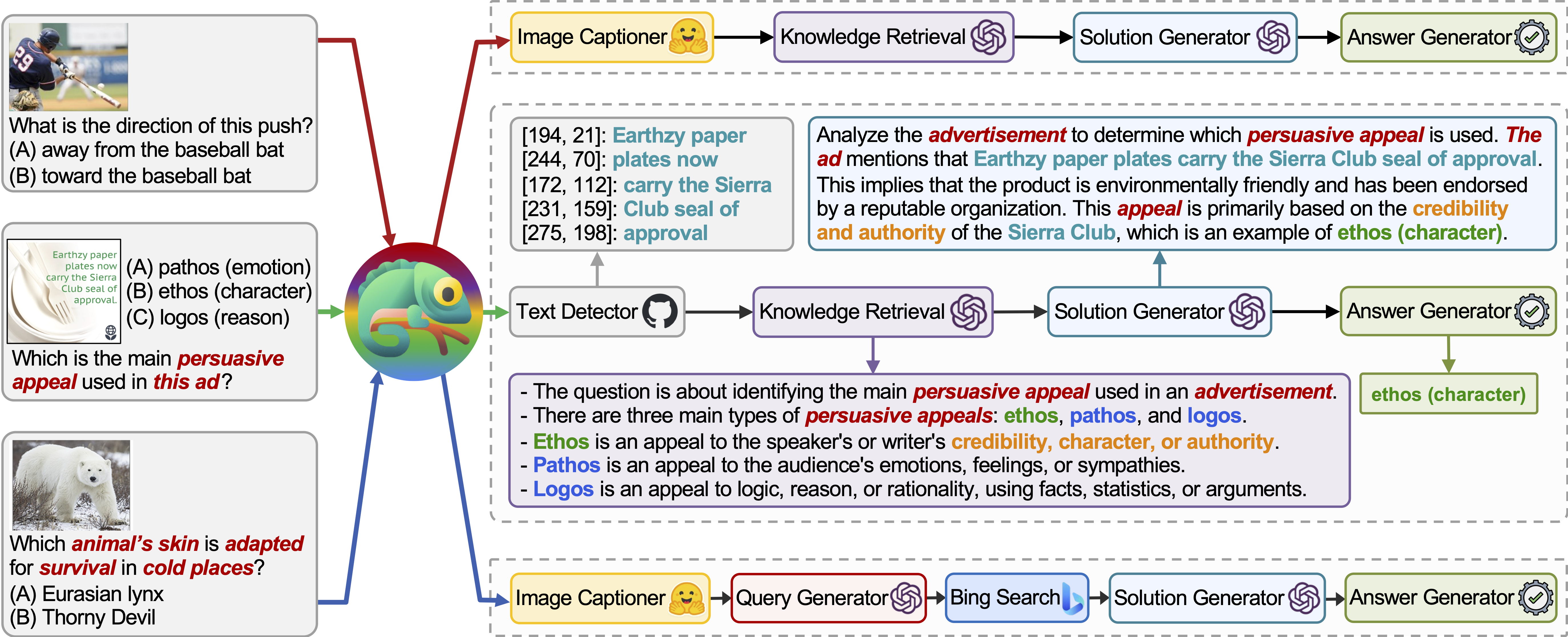
Chameleon (GPT-4) dapat beradaptasi dengan kueri input yang berbeda dengan menghasilkan program yang menyusun berbagai alat dan mengeksekusi mereka secara berurutan untuk mendapatkan jawaban yang benar.
Misalnya, kueri di atas bertanya, "Kulit hewan mana yang diadaptasi untuk bertahan hidup di tempat -tempat dingin?", Yang melibatkan terminologi ilmiah yang terkait dengan kelangsungan hidup hewan. Akibatnya, perencana memutuskan untuk mengandalkan mesin pencari Bing untuk pengetahuan khusus domain, mendapat manfaat dari berbagai sumber daring yang tersedia.
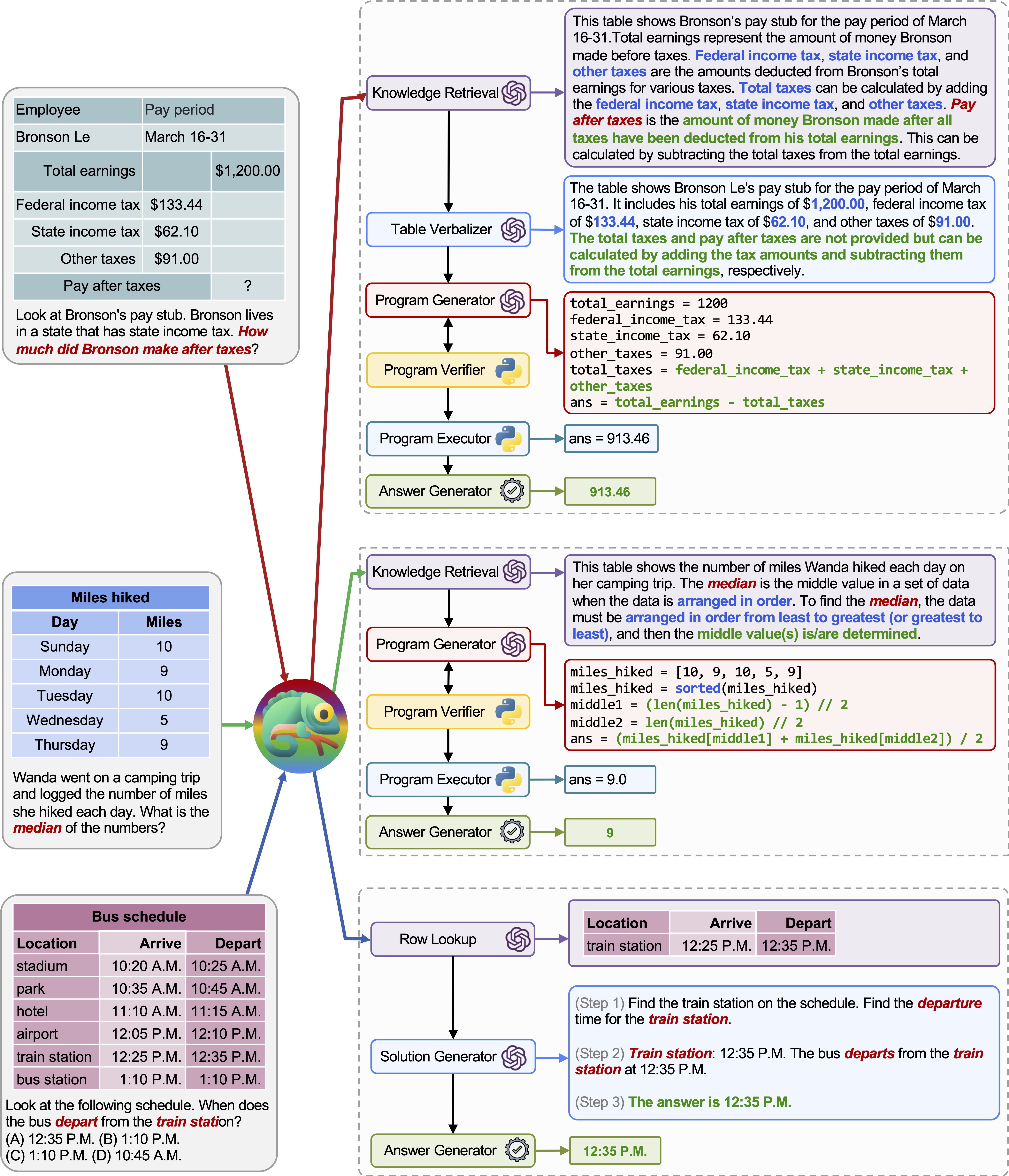
Kemampuan beradaptasi dan keserbagunaan bunglon kami untuk berbagai pertanyaan juga diamati pada tabmwp, seperti yang diilustrasikan dalam contoh pada gambar di atas.
Contoh pertama melibatkan penalaran matematika pada formulir pajak. Chameleon (1) Memanggil model pengambilan pengetahuan untuk mengingat pengetahuan dasar yang membantu dalam memahami tabel khusus domain, (2) menggambarkan tabel dalam format bahasa alami yang lebih mudah dibaca, dan (3) akhirnya bergantung pada alat yang dibantu program untuk melakukan Perhitungan yang tepat.
Dalam contoh kedua, sistem menghasilkan kode Python yang sangat erat dengan pengetahuan latar belakang yang disediakan oleh model pengambilan pengetahuan.
Contoh ketiga membutuhkan sistem untuk menemukan sel dalam konteks tabel besar mengingat kueri input. Chameleon memanggil model pencarian baris untuk membantu secara akurat menemukan baris yang relevan dan menghasilkan solusi bahasa melalui model LLM, alih-alih mengandalkan alat berbasis program.
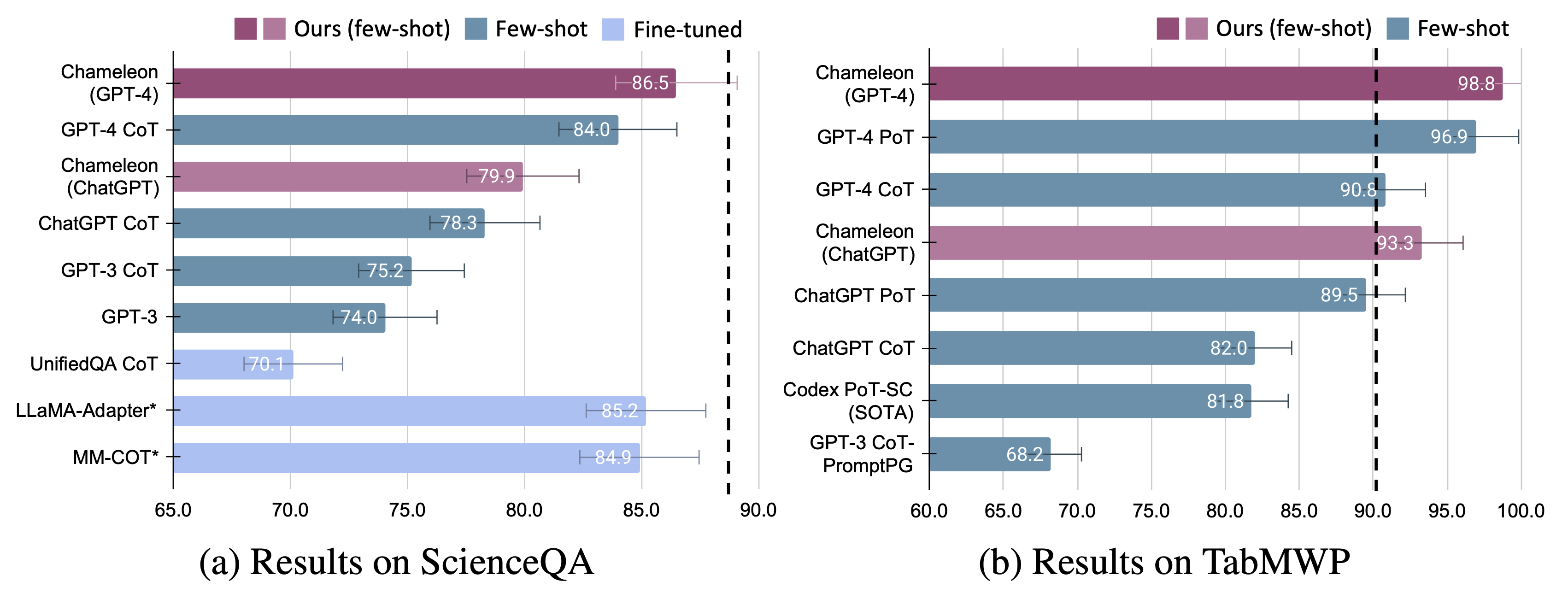
Perbaikan yang signifikan diamati untuk bunglon pada kedua model yang disesuaikan dan beberapa tembakan mendorong GPT-4/chatgpt:
Untuk memvisualisasikan prediksi yang dibuat oleh Chameleon , cukup jalankan buku catatan Jupyter yang sesuai dengan tugas spesifik Anda: notebooks/results_viewer_[TASK].ipynb . Ini akan memberikan cara interaktif dan ramah pengguna untuk mengeksplorasi hasil yang dihasilkan oleh model. Atau, jelajahi halaman proyek kami untuk informasi dan opsi lebih lanjut.
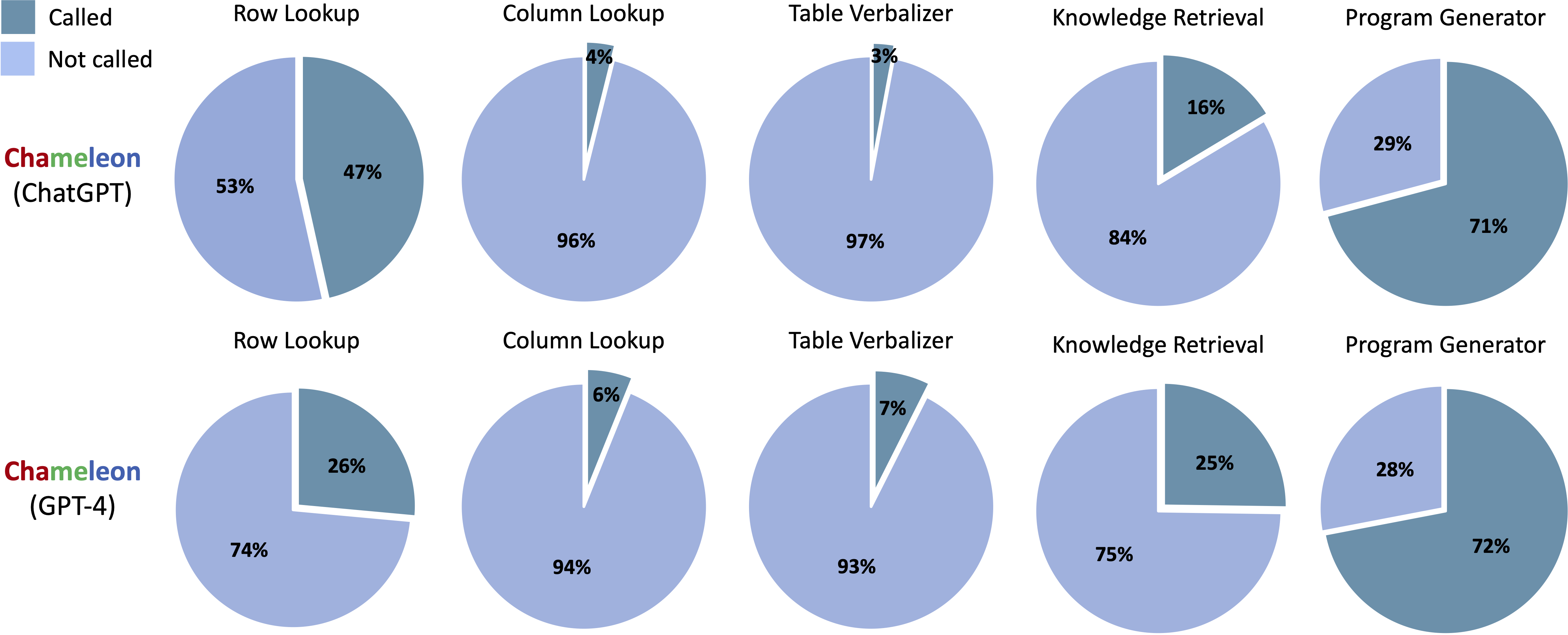
Alat-alat yang dipanggil dalam program yang dihasilkan dari Chameleon (ChatGPT) dan Chameleon (GPT-4) di Scienceqa:

Alat yang dipanggil dalam program yang dihasilkan dari Chameleon (ChatGPT) dan Chameleon (GPT-4) di TABMWP:
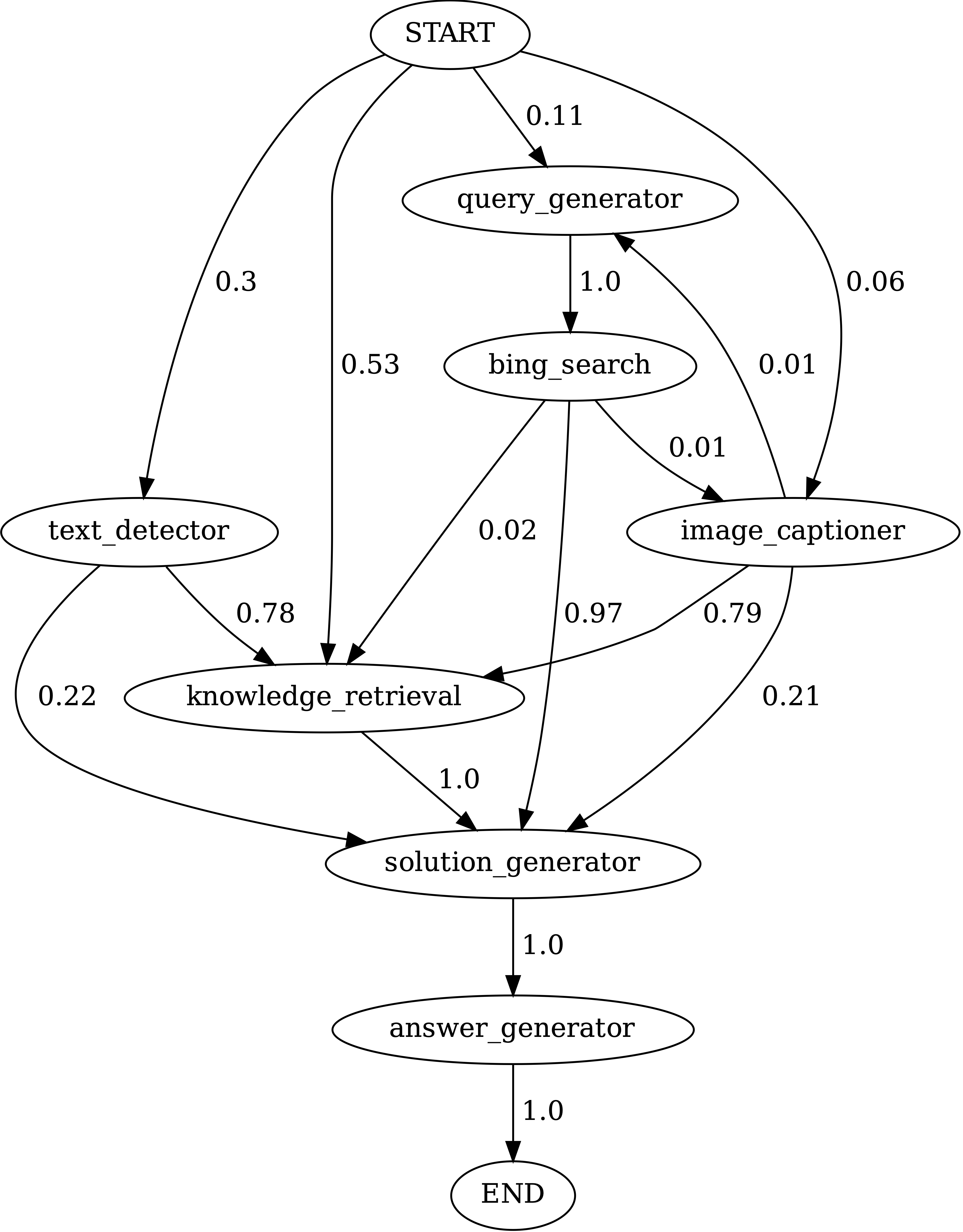
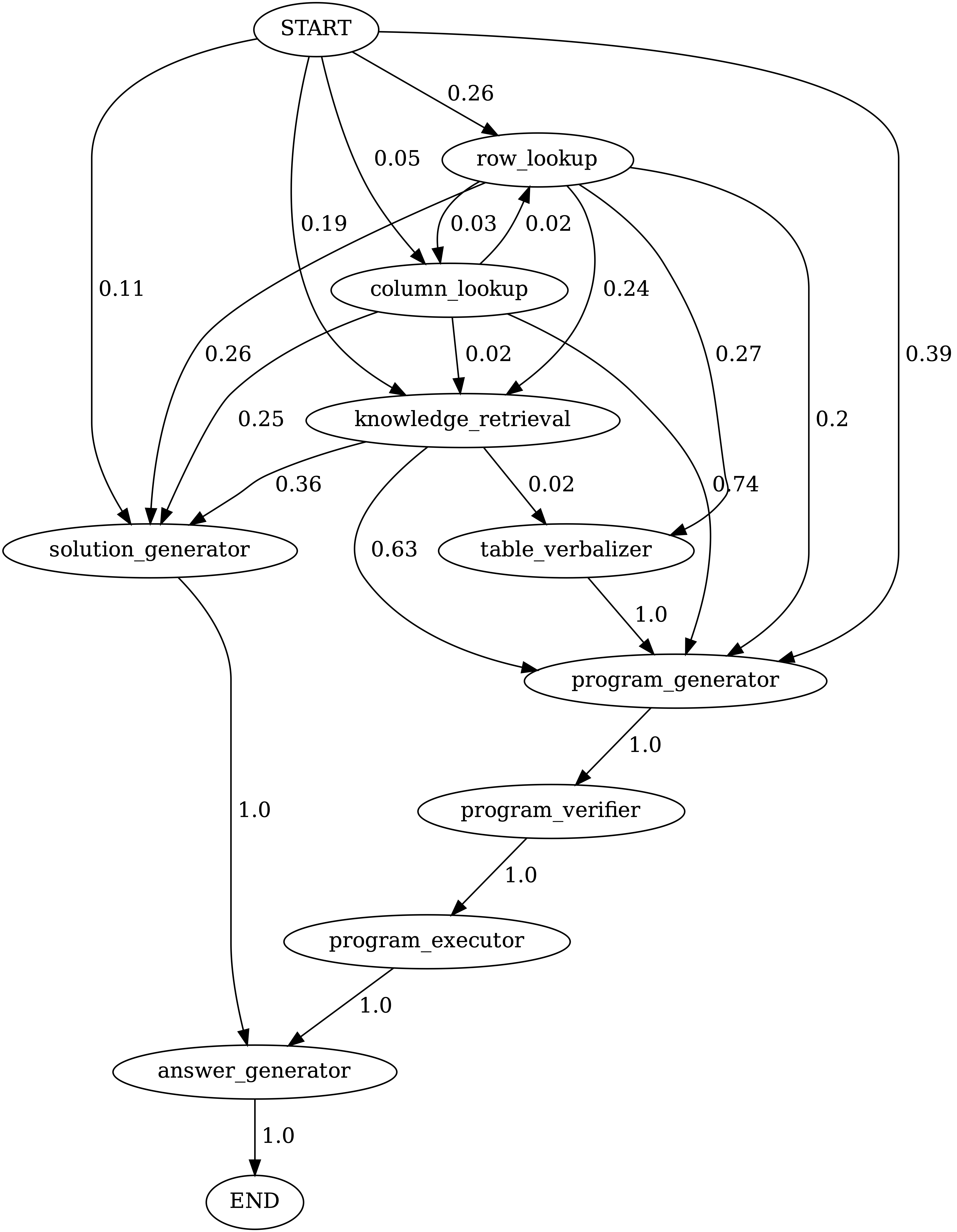
Jalankan notebooks/transition_[TASK]_[Model]_Engine.ipynb untuk memvisualisasikan grafik transisi modul untuk program yang dihasilkan pada set tes.
Transisi antara modul dalam program yang dihasilkan oleh Chameleon (GPT-4) di ScienceQA. Mulai adalah simbol awal, akhir adalah simbol terminal dan yang lainnya adalah simbol non-terminal.
Transisi antara modul dalam program yang dihasilkan oleh Chameleon (GPT-4) di TABMWPQA. Mulai adalah simbol awal, akhir adalah simbol terminal dan yang lainnya adalah simbol non-terminal.
demos . Tentukan input, eksekusi, dan output untuk setiap modul di model.py .model.py . Untuk memodifikasi metode evaluasi, perbarui bagian yang sesuai di main.pyFantastis! Saya selalu terbuka untuk melibatkan diskusi, kolaborasi, atau bahkan hanya berbagi kopi virtual. Untuk menghubungi, kunjungi beranda Pan Lu untuk informasi kontak.
Jika Anda menemukan bunglon berguna untuk penelitian dan aplikasi Anda, silakan mengutip menggunakan Bibtex ini:
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

