chameleon llm
v1.0
Código para el documento "Camaleón: razonamiento de composición de plug-and-play con modelos de idiomas grandes".
? Si tiene alguna pregunta o sugerencia, no dude en informarnos. Puede enviar un correo electrónico directamente a Pan Lu usando la dirección de correo electrónico [email protected], comentar en Twitter o publicar un problema en este repositorio.
[Página del proyecto] [Paper] [Twitter] [LinkedIn] [YouTube] [Slides]
Logotipo tentativo para camaleón .
Chameleon es un marco de razonamiento de composición plug-and-play que aumenta los LLM con varios tipos de herramientas. Chameleon sintetiza programas para componer diversas herramientas, incluidos los modelos LLM, los modelos de visión en el estante, los motores de búsqueda web, las funciones de Python y los módulos basados en reglas adaptados a los intereses de los usuarios. Construido sobre un LLM como un planificador de lenguaje natural, Chameleon infiere la secuencia apropiada de herramientas para componer y ejecutar para generar una respuesta final.
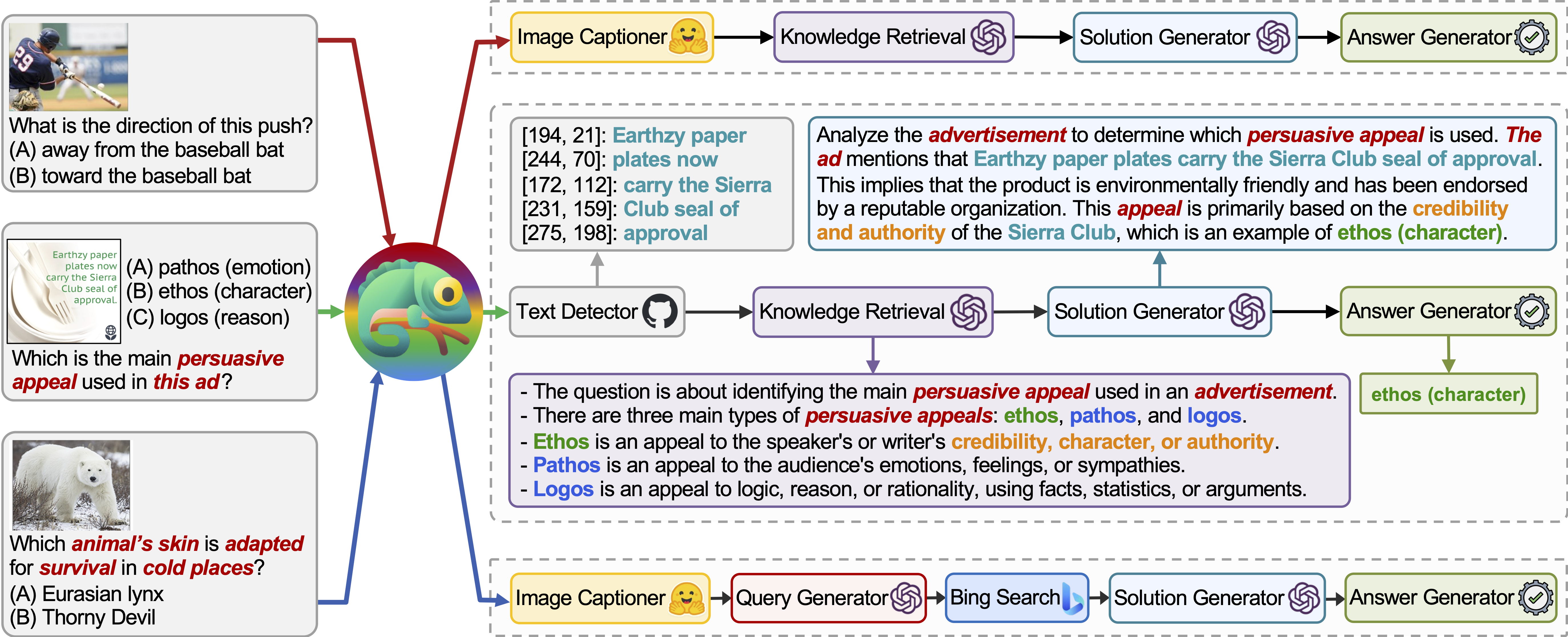
Mostramos la adaptabilidad y efectividad del camaleón en dos tareas: Scienceqa y TabMWP. En particular, el camaleón con GPT-4 logra una precisión del 86.54% en ScienceQA, mejorando significativamente el modelo de pocos disparos mejor publicado en un 11.37%; Usando GPT-4 como LLM subyacente, Chameleon logra un aumento del 17.0% sobre el modelo de última generación, lo que lleva a una precisión general del 98.78% en TABMWP. Otros estudios sugieren que el uso de GPT-4 como planificador exhibe una selección de herramientas más consistente y racional y es capaz de inferir posibles restricciones dadas las instrucciones, en comparación con otros LLM como ChatGPT.
Para obtener más detalles, puede encontrar nuestra página del proyecto aquí y nuestro artículo aquí.
¡Nos gustaría expresar nuestra inmensa gratitud a Wordofai por presentar y presentar nuestro trabajo en YouTube!
Instale todas las dependencias de Python requeridas (generadas por pipreqs ):
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
Instale todas las dependencias de Python requeridas (puede omitir este paso si ha configurado las dependencias antes y las versiones no son estrictamente necesarias):
pip install -r requirements.txt
Obtenga su clave API OpenAI de: https://platform.openai.com/account/api-keys.
Para usar la clave API de OpenAI para Chameleon , debe configurar la facturación (también conocido como cuenta pagada).
Puede configurar una cuenta pagada en https://platform.openai.com/account/billing/overview.
Obtenga su clave de API de búsqueda de Bing de: https://www.microsoft.com/en-us/bing/apis/bing-web-search-api.
La clave de la API de búsqueda de Bing es opcional . No configurar esta clave conducirá a una ligera caída de rendimiento en la tarea ScienceQA.
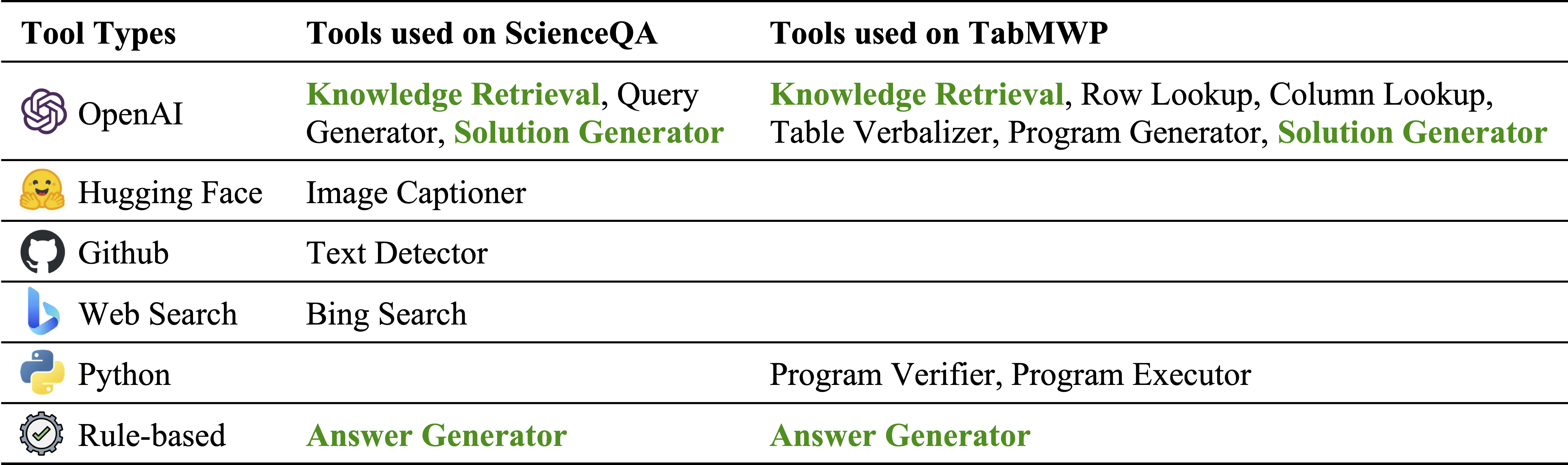
Diferentes tipos de herramientas en nuestro inventario de módulos:

Herramientas utilizadas en ScienceQA y TABMWP, respectivamente. Las herramientas reutilizables en dos tareas se destacan en verde:
La respuesta a las preguntas de la ciencia (Scienceqa) es un punto de referencia de preguntas de pregunta multimodal que cubre una amplia gama de temas científicos sobre diversos contextos. El conjunto de datos ScienceQA se proporciona en data/scienceqa . Para obtener más detalles, puede explorar el conjunto de datos y consultar la página de explorar y visualizar la página.
Para la versión actual, los resultados para el Image Captioner y Text Detector están fuera de lugar y se almacenan en data/scienceqa/captions.json y data/scienceqa/ocrs.json , respectivamente. ¡Los llamados en vivo de estos dos módulos llegarán pronto!
Para ejecutar el camaleón (GPT-4):
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 Generará las predicciones y guardará los resultados en results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl , y results/scienceqa/chameleon_gpt4_test_cache.json .
Podemos obtener las métricas de precisión en promedio y en diferentes clases de preguntas ejecutando:
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlPara ejecutar Chameleon (chatgpt):
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 Nuestro camaleón es una forma generalizada del método COT (cadena de pensamiento), donde el programa generado es una secuencia de Solution Generator y Answer Generator . Al pasar --model como cot , modules se establecen como ["solution_generator", "answer_generator"] .
Para ejecutar cot (cadena de pensamiento provocada) GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1Para ejecutar cot (cadena de pensamiento solicitado) chatgpt:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 El conjunto de datos TABMWP contiene 38,431 problemas de palabras matemáticas tabulares. Cada pregunta en TABMWP está alineada con un contexto tabular, que se presenta como una imagen, texto semiestructurado y una tabla estructurada. El conjunto de datos TABMWP se proporciona en data/tabmwp . Para obtener más detalles, puede explorar el conjunto de datos y consultar la página de explorar y visualizar la página.
Para ejecutar el camaleón (GPT-4):
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 Generará las predicciones y guardará los resultados en results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl , y results/tabmwp/chameleon_gpt4_test_cache.json .
Podemos obtener las métricas de precisión en promedio y en diferentes clases de preguntas ejecutando:
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlPara ejecutar Chameleon (chatgpt):
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18Para ejecutar cot (cadena de pensamiento provocada) GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1Para ejecutar cot (cadena de pensamiento solicitado) chatgpt:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 Nuestro camaleón es una forma generalizada del método POT (Programa de pensamiento), donde el programa generado es una secuencia de Program Generator , Program Executor y Answer Generator . Al pasar --model como pot , modules se establecen como ["program_generator", "program_executor", "answer_generator"] .
Para ejecutar POT (programa de pensamiento solicitado) GPT-4:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1Para ejecutar el Pot (Programa de pensamiento solicitado) CHATGPT:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1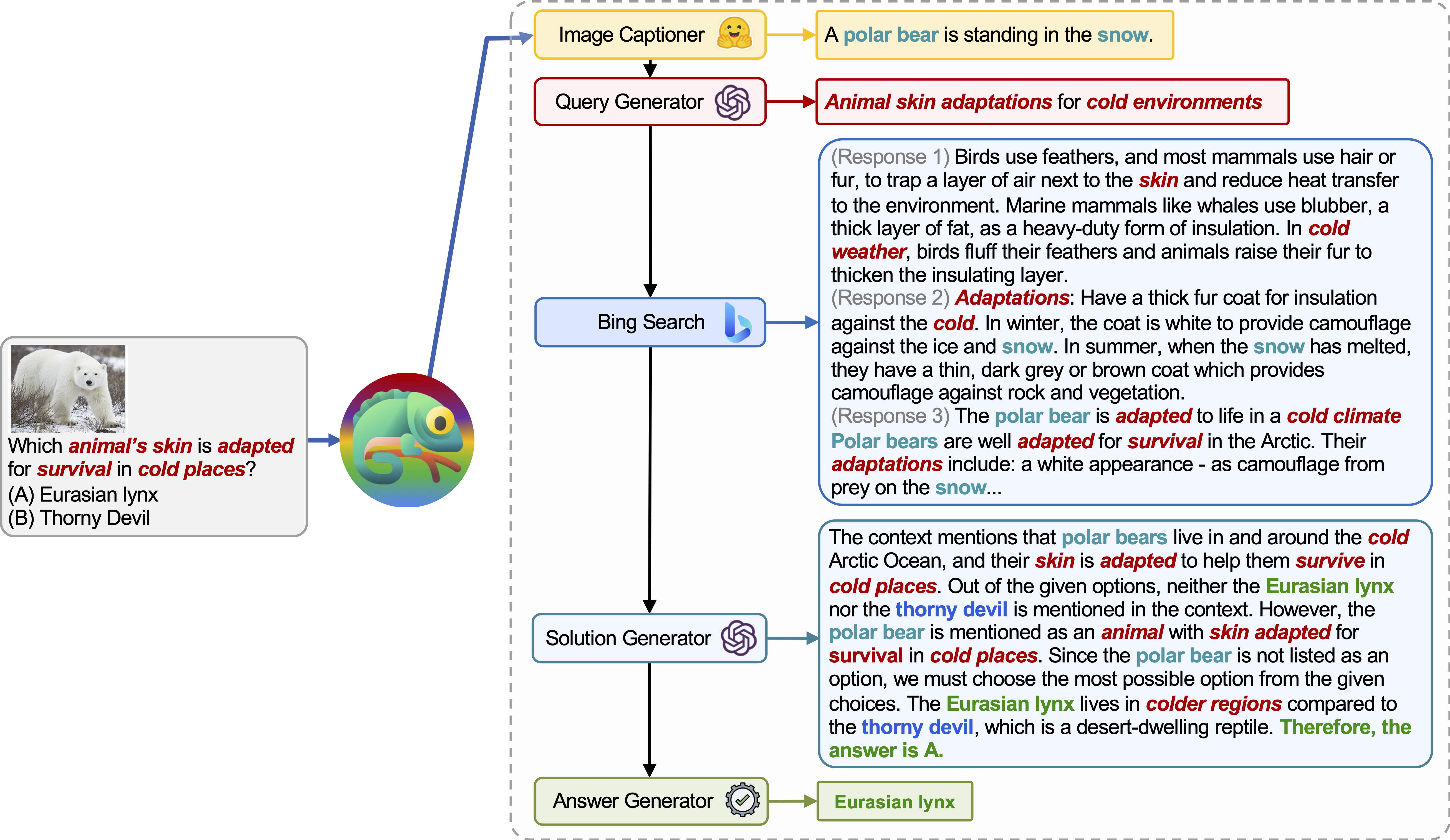
Chameleon (GPT-4) puede adaptarse a diferentes consultas de entrada mediante la generación de programas que componen varias herramientas y ejecutándolas secuencialmente para obtener las respuestas correctas.
Por ejemplo, la consulta anterior pregunta: "¿Qué piel del animal se adapta para la supervivencia en lugares fríos?", Que implica terminología científica relacionada con la supervivencia de los animales. En consecuencia, el planificador decide confiar en el motor de búsqueda de Bing para el conocimiento específico del dominio, beneficiándose de los numerosos recursos en línea disponibles.
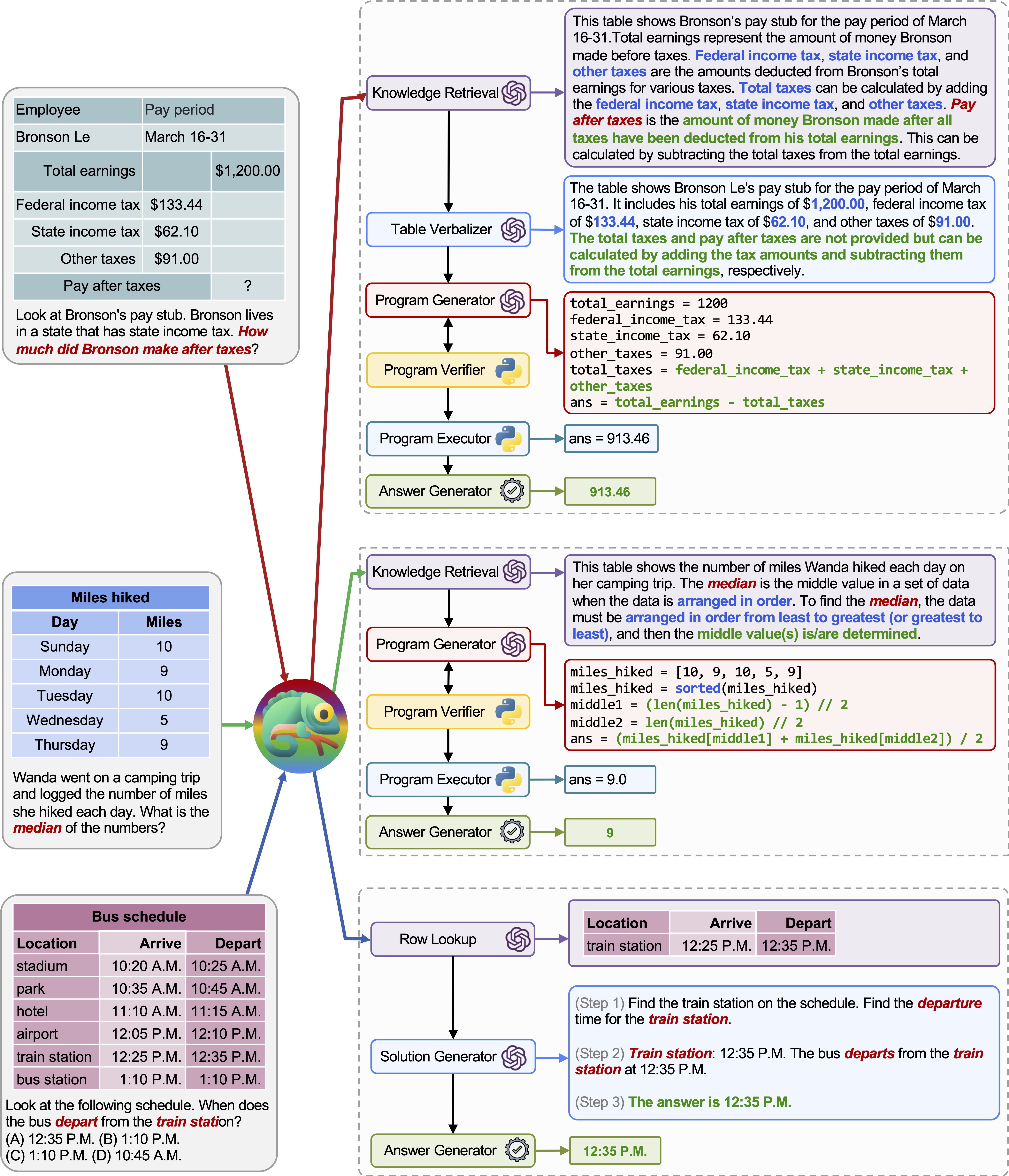
La adaptabilidad y la versatilidad de nuestro camaleón para varias consultas también se observan en TABMWP, como se ilustra en los ejemplos de la figura anterior.
El primer ejemplo implica un razonamiento matemático en un formulario de impuestos. Chameleon (1) llama al modelo de recuperación de conocimiento para recordar el conocimiento básico que ayuda a comprender tales tablas específicas del dominio, (2) describe la tabla en un formato de lenguaje natural más legible y (3) finalmente se basa en herramientas asistidas por programas para realizar cálculos precisos.
En el segundo ejemplo, el sistema genera un código de pitón que se alinea estrechamente con el conocimiento de fondo proporcionado por el modelo de recuperación de conocimiento.
El tercer ejemplo requiere que el sistema localice la celda en un gran contexto tabular dada la consulta de entrada. Chameleon llama al modelo de búsqueda de filas para ayudar a localizar con precisión las filas relevantes y generar la solución de lenguaje a través de un modelo LLM, en lugar de depender de las herramientas basadas en programas.
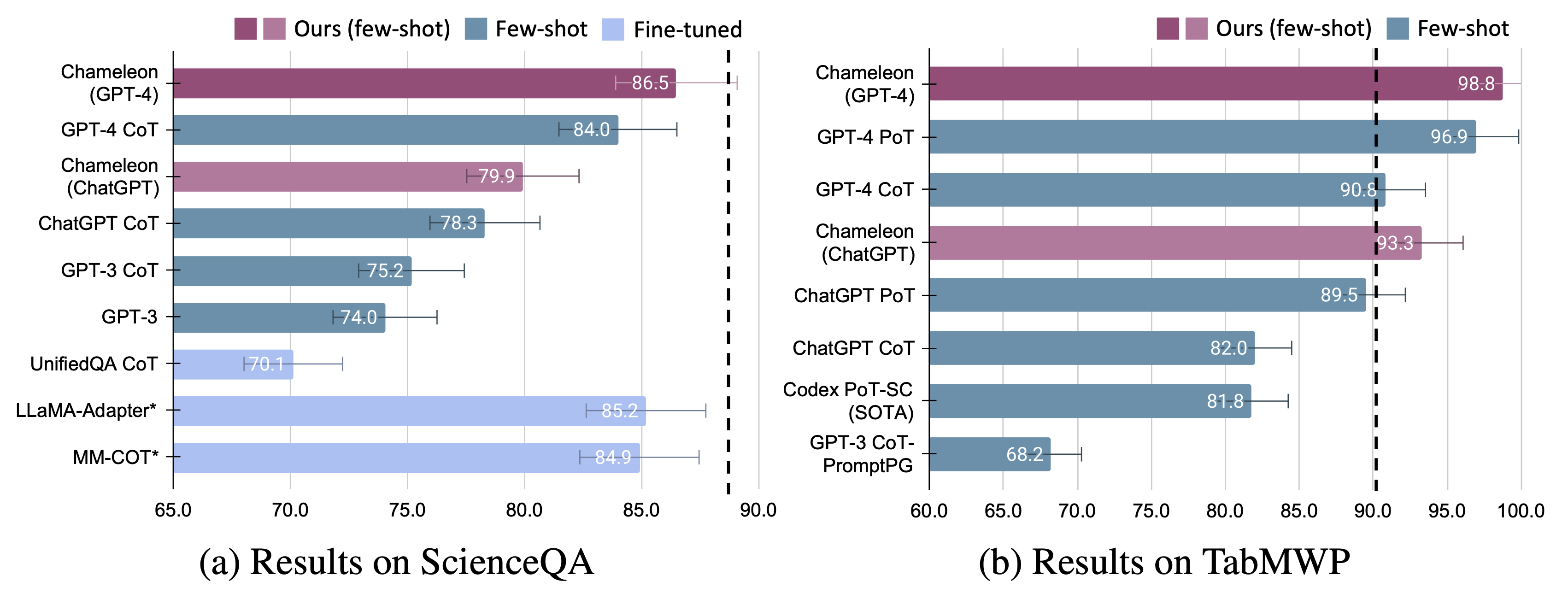
Se observan mejoras significativas para el camaleón sobre los modelos ajustados y los pocos disparos provocaron GPT-4/CHATGPT:
Para visualizar las predicciones hechas por Chameleon , simplemente ejecute el cuaderno Jupyter correspondiente a su tarea específica: notebooks/results_viewer_[TASK].ipynb . Esto proporcionará una forma interactiva y fácil de usar para explorar los resultados generados por el modelo. Alternativamente, explore nuestra página del proyecto para obtener más información y opciones.
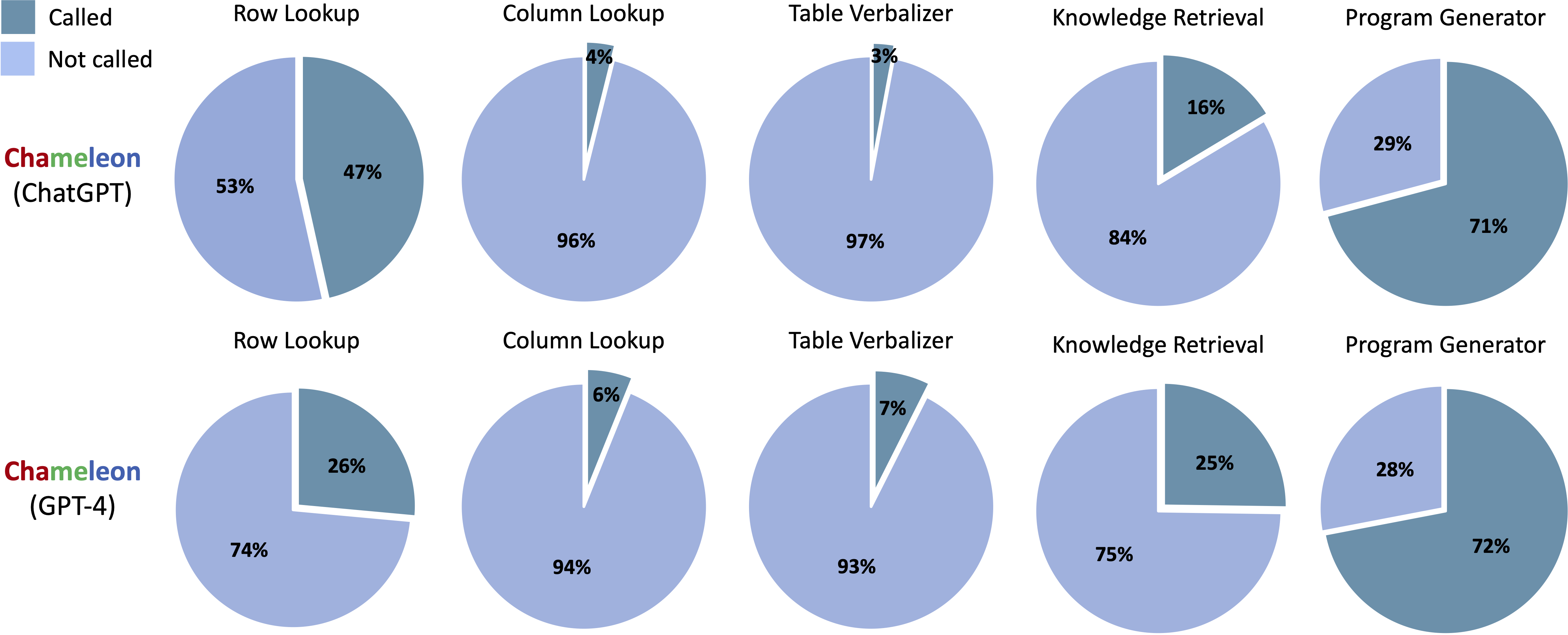
Herramientas llamadas en los programas generados de Chameleon (CHATGPT) y Chameleon (GPT-4) en ScienceQA:

Herramientas llamadas en los programas generados de Chameleon (CHATGPT) y Chameleon (GPT-4) en TABMWP:
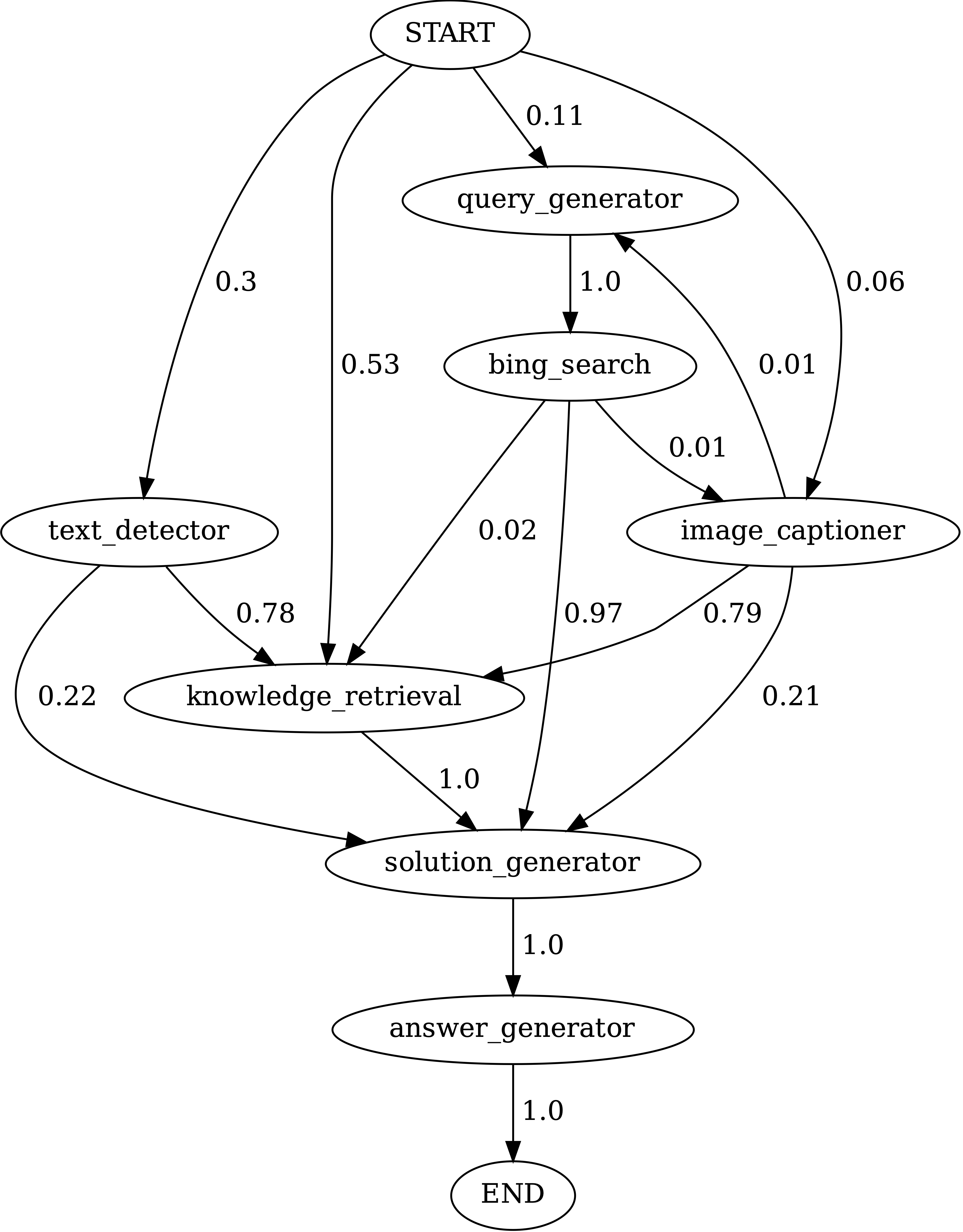
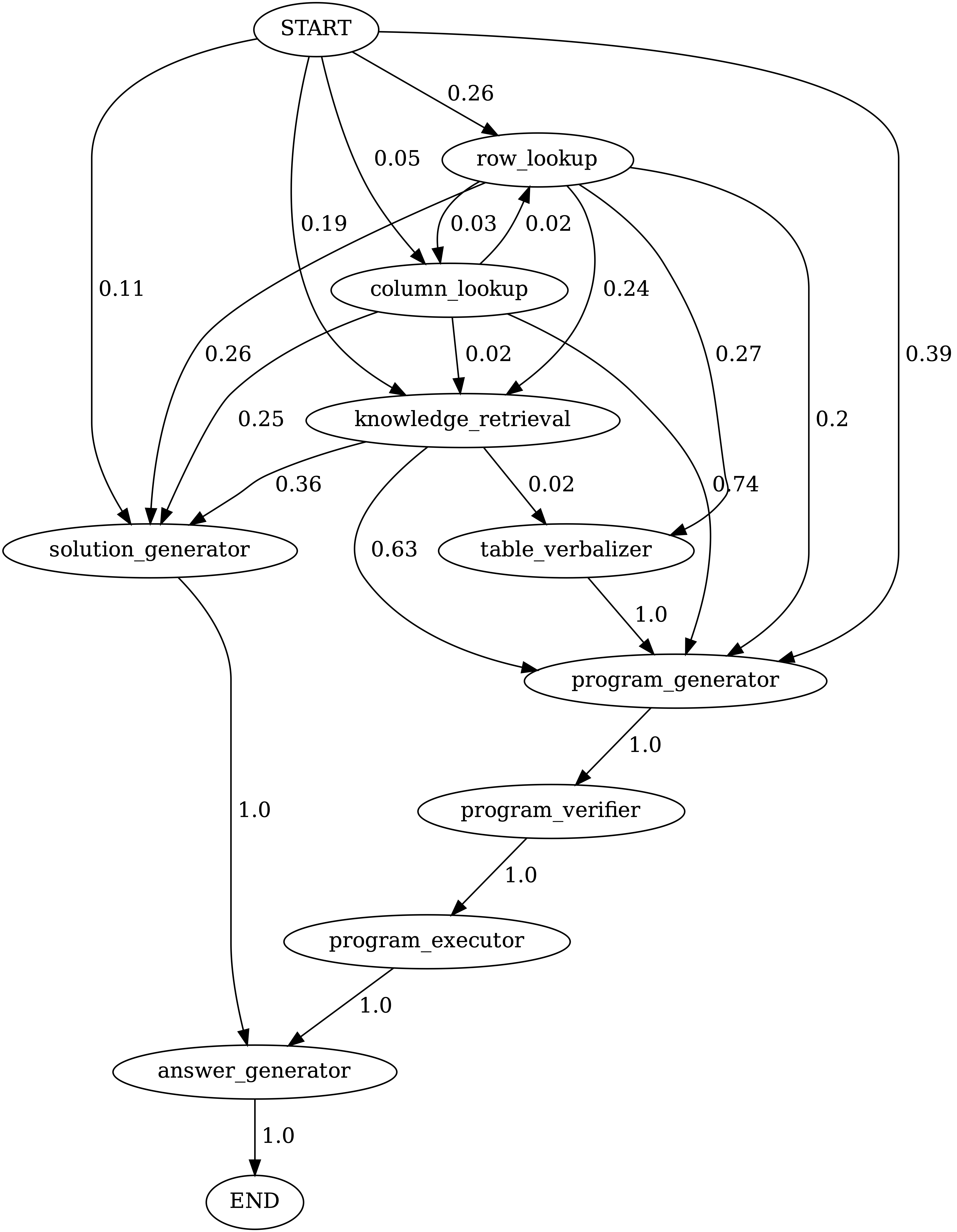
Ejecutar notebooks/transition_[TASK]_[Model]_Engine.ipynb para visualizar el gráfico de transición del módulo para los programas generados en el conjunto de pruebas.
Transiciones entre módulos en programas generados por Chameleon (GPT-4) en ScienceQA. El inicio es el símbolo de inicio, el final es un símbolo terminal y los otros son símbolos no terminales.
Transiciones entre módulos en programas generados por Chameleon (GPT-4) en TABMWPQA. El inicio es el símbolo de inicio, el final es un símbolo terminal y los otros son símbolos no terminales.
demos . Defina la entrada, la ejecución y la salida para cada módulo en model.py .model.py . Para modificar el método de evaluación, actualice la sección correspondiente en main.py¡Fantástico! Siempre estoy abierto a discusiones atractivas, colaboraciones o incluso compartir un café virtual. Para ponerse en contacto, visite la página de inicio de Pan Lu para obtener información de contacto.
Si encuentra útil Chameleon para su investigación y aplicaciones, cita amablemente usando este bibtex:
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

