chameleon llm
v1.0
Code für das Papier "Chameleon: Plug-and-Play-Kompositionelle Argumentation mit großen Sprachmodellen".
? Wenn Sie Fragen oder Vorschläge haben, zögern Sie bitte nicht, uns zu informieren. Sie können Pan Lu direkt per E -Mail -Adresse [email protected] per E -Mail senden, einen Kommentar zum Twitter oder ein Problem in diesem Repository veröffentlichen.
[Projektseite] [Papier] [Twitter] [LinkedIn] [YouTube] [Folien]
Vorläufiges Logo für Chamäleon .
Chamäleon ist ein Plug-and-Play-Kompositions-Argumentations-Framework, das LLMs mit verschiedenen Arten von Werkzeugen verstärkt. Chameleon synthetisiert Programme, um verschiedene Tools zu komponieren, darunter LLM-Modelle, Off-the-Shelf-Visionsmodelle, Web-Suchmaschinen, Python-Funktionen und regelbasierte Module, die auf Benutzerinteressen zugeschnitten sind. Chamäleon ist als natürlicher Sprachplaner auf einem LLM aufgebaut und färbt die geeignete Folge von Tools zum Komponieren und Ausführen, um eine endgültige Antwort zu erzeugen.
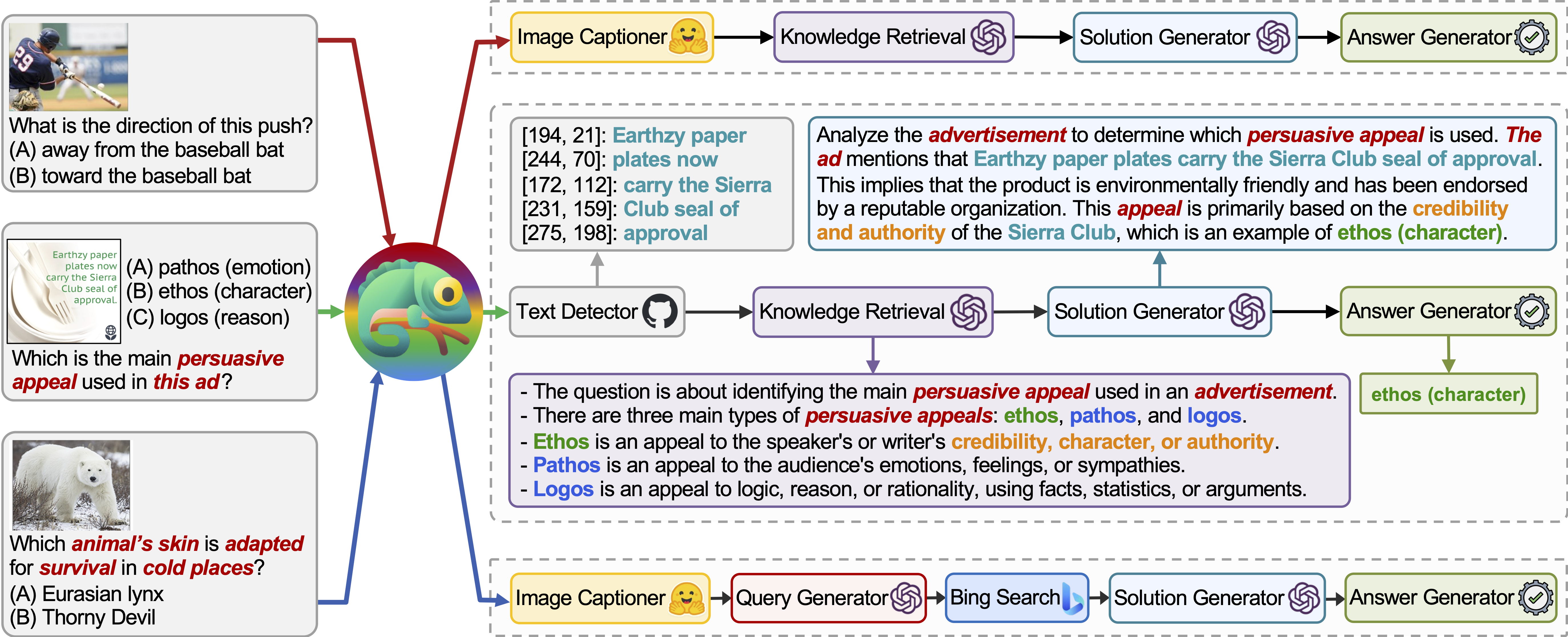
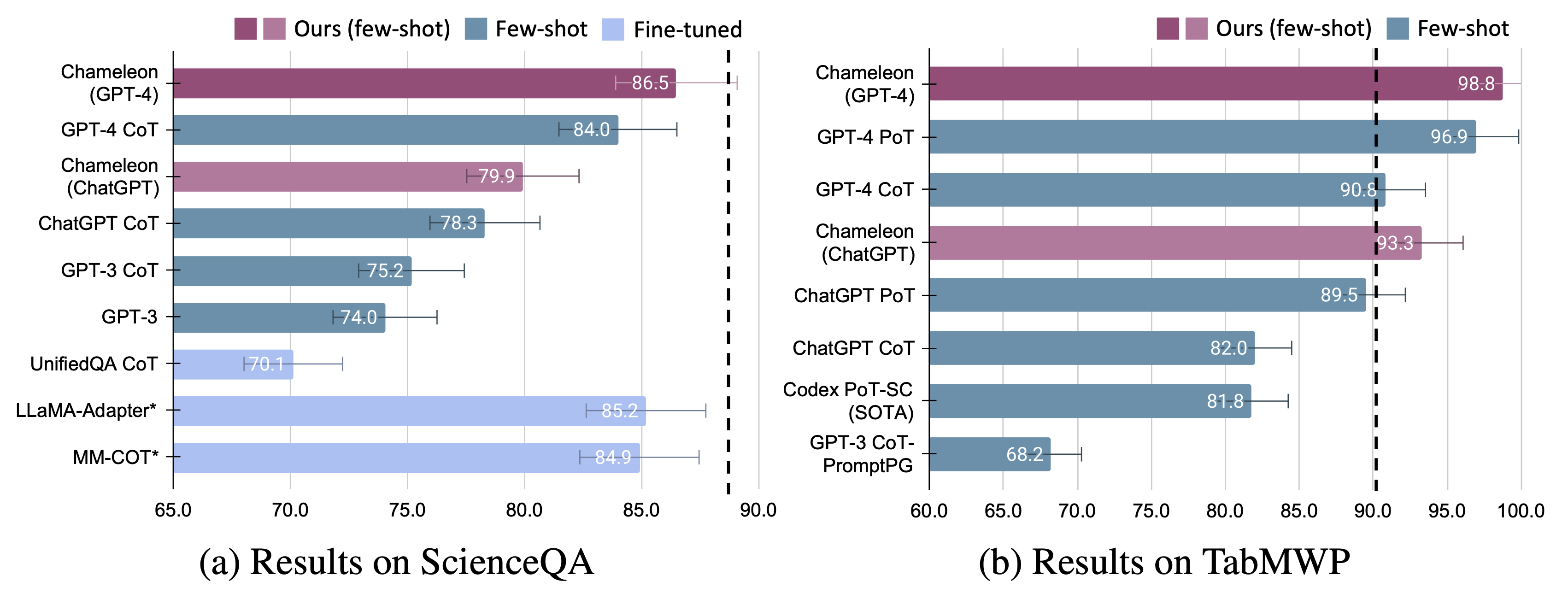
Wir präsentieren die Anpassungsfähigkeit und Wirksamkeit von Chamäleon bei zwei Aufgaben: Scienceqa und Tabmwp. Bemerkenswerterweise erreicht Chamäleon mit GPT-4 eine Genauigkeit von 86,54% auf ScienceQA und verbessert sich signifikant um das am besten veröffentlichte wenige Schussmodell um 11,37%. Mit GPT-4 als zugrunde liegender LLM erzielt Chameleon eine Erhöhung des hochmodernen Modells um 17,0%, was zu einer Gesamtgenauigkeit von 98,78% auf TABMWP führt. Weitere Studien legen nahe, dass die Verwendung von GPT-4 als Planer eine konsistentere und rationale Werkzeugauswahl aufweist und angesichts der Anweisungen im Vergleich zu anderen LLMs wie ChatGPT potenzielle Einschränkungen schließen kann.
Weitere Informationen finden Sie hier und finden Sie hier unsere Projektseite und unser Papier hier.
Wir möchten Worldofai unseren immensen Dank dafür ausdrücken, dass wir unsere Arbeit auf YouTube vorgestellt und eingeführt haben!
Installieren Sie alle erforderlichen Python -Abhängigkeiten (von pipreqs generiert):
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
Installieren Sie alle erforderlichen Python -Abhängigkeiten (Sie können diesen Schritt überspringen, wenn Sie die Abhängigkeiten zuvor eingerichtet haben und die Versionen nicht ausschließlich erforderlich sind):
pip install -r requirements.txt
Holen Sie sich Ihre OpenAI-API-Schlüssel aus: https://platform.openai.com/account/api-keys.
Um den OpenAI -API -Schlüssel für Chameleon zu verwenden, müssen Sie eine Abrechnungsanlage einrichten (auch bekannt als bezahltes Konto).
Sie können ein kostenpflichtiges Konto unter https://platform.openai.com/account/billing/overview einrichten.
Holen Sie sich Ihre Bing-Search-API-Taste von: https://www.microsoft.com/en-us/bing/apis/bing-web-search-api.
Der Bing -Such -API -Schlüssel ist optional . Wenn Sie diesen Schlüssel nicht eingerichtet haben, wird die ScienceQA -Aufgabe zu einem leichten Leistungsrückfall führen.
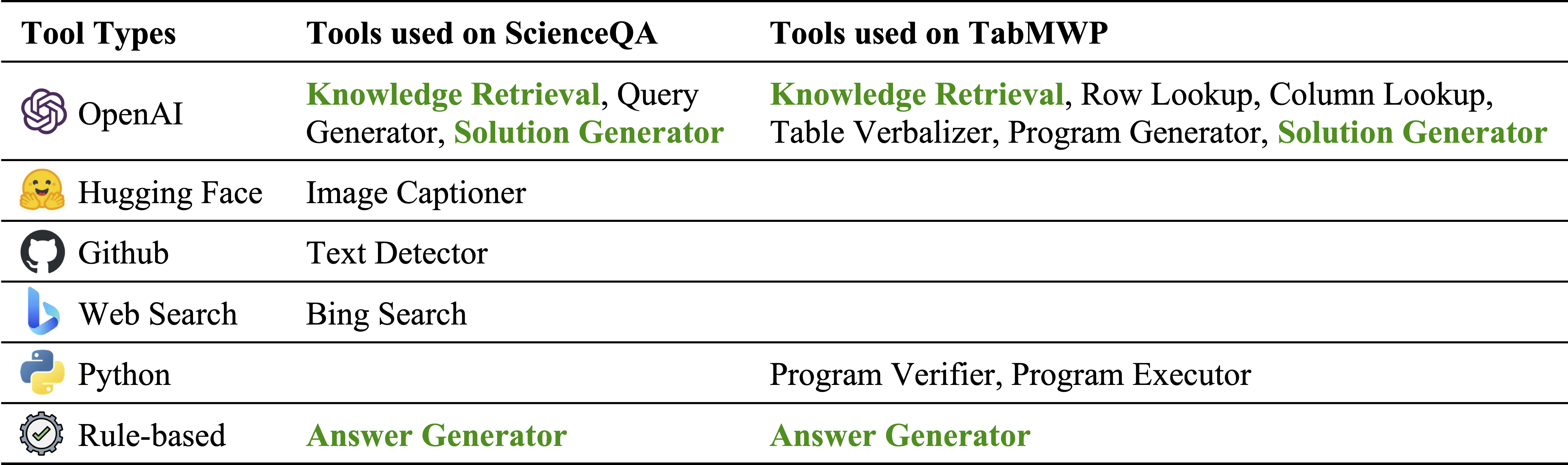
Verschiedene Arten von Werkzeugen in unserem Modulinventar:

Tools, die auf ScienceQA bzw. tabmwp verwendet werden. Die wiederverwendbaren Werkzeuge in zwei Aufgaben sind grün hervorgehoben:
Science Frage Antwort (ScienceQA) ist ein multimodaler Fragen-Answer-Benchmark, der über eine Vielzahl wissenschaftlicher Themen über verschiedene Kontexte abdeckt. Der ScienceQA -Datensatz ist in data/scienceqa bereitgestellt. Weitere Informationen finden Sie im Datensatz und finden Sie die Seite "Explore" und "Visualisieren".
Für die aktuelle Version sind die Ergebnisse für den Image Captioner und Text Detector außerhalb des Shelfs und in data/scienceqa/captions.json und data/scienceqa/ocrs.json gespeichert. Die lebenden Live -Rufe diese beiden Module kommen bald!
Chamäleon (GPT-4) laufen:
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 Es generiert die Vorhersagen und speichert die Ergebnisse bei results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl und results/scienceqa/chameleon_gpt4_test_cache.json .
Wir können die Genauigkeitsmetriken im Durchschnitt und über verschiedene Fragenklassen hinweg erhalten, indem wir Laufen:
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlChamäleon (CHATGPT) ausführen:
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 Unser Chamäleon ist eine verallgemeinerte Form der COT-Methode (Kette der Gedanken), wobei das generierte Programm eine Folge von Solution Generator und Answer Generator ist. Durch das Bestehen --model als cot wird modules als ["solution_generator", "answer_generator"] festgelegt.
Zum Laufen von COT (Kette des Gedanke) GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1Chatgpt: COT (Kette des Gedanke) ausführen:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 Der TABMWP -Datensatz enthält 38.431 tabellarische mathematische Wortprobleme. Jede Frage in TABMWP ist mit einem tabellarischen Kontext ausgerichtet, der als Bild, halbstrukturierter Text und eine strukturierte Tabelle dargestellt wird. Der TABMWP -Datensatz ist in data/tabmwp bereitgestellt. Weitere Informationen finden Sie im DataTSet und finden Sie die Seite "Explore" und "Visualisieren".
Chamäleon (GPT-4) laufen:
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 Es generiert die Vorhersagen und speichert die Ergebnisse bei results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl und results/tabmwp/chameleon_gpt4_test_cache.json .
Wir können die Genauigkeitsmetriken im Durchschnitt und über verschiedene Fragenklassen hinweg erhalten, indem wir Laufen:
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlChamäleon (CHATGPT) ausführen:
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18Zum Laufen von COT (Kette des Gedanke) GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1Chatgpt: COT (Kette des Gedanke) ausführen:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 Unser Chamäleon ist eine verallgemeinerte Form der POT-Methode (Programmprogramme), wobei das generierte Programm eine Folge von Program Generator , Program Executor und Answer Generator ist. Durch das Bestehen --model als pot wird modules als ["program_generator", "program_executor", "answer_generator"] festgelegt.
To Pot (Program of Duncing forderted) GPT-4 ausführen:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1Chatgpt: Pot (Program of Duncyed) ausführen:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1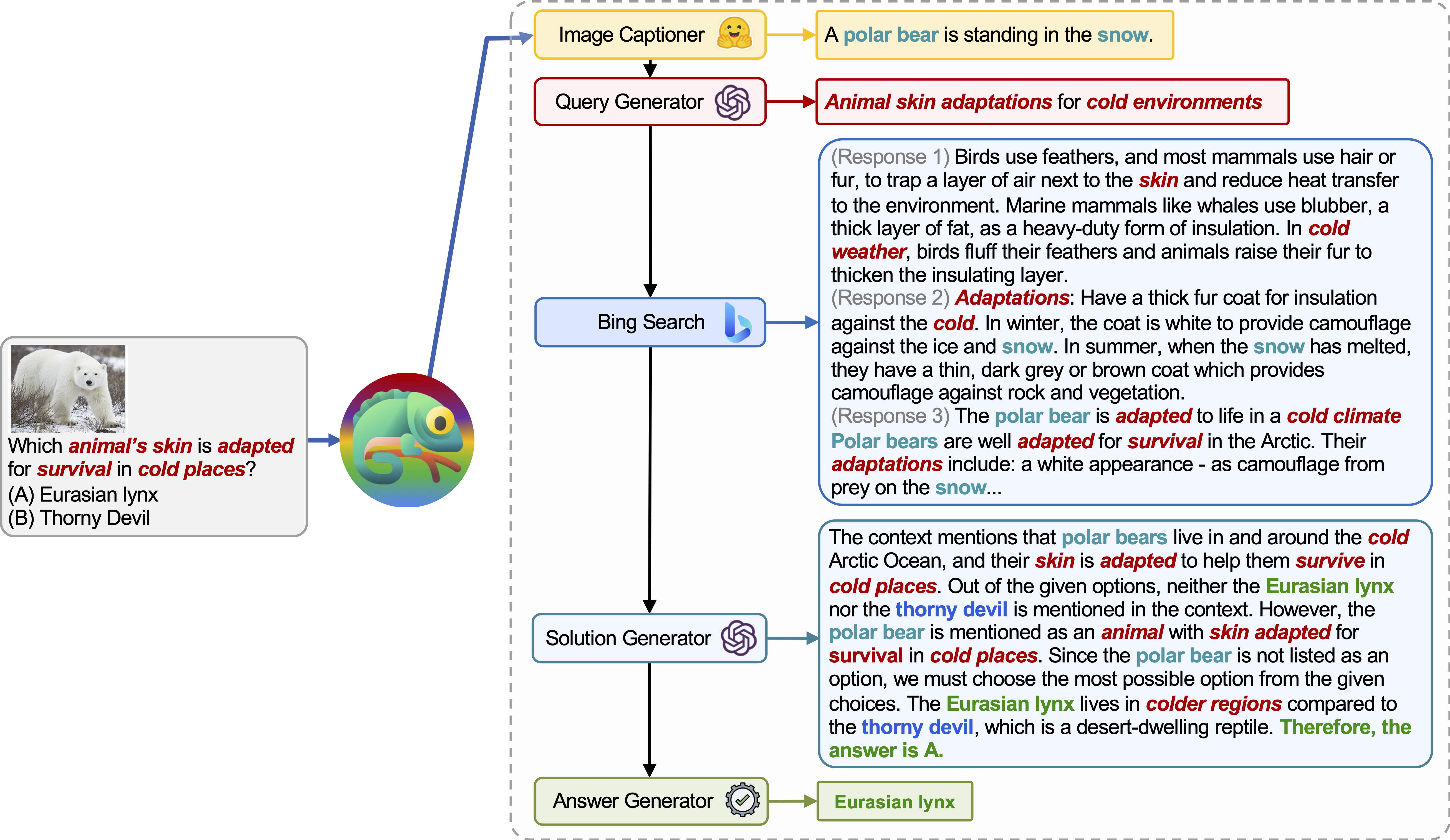
Chamäleon (GPT-4) kann sich an verschiedene Eingabebrüstung anpassen, indem sie Programme generieren, die verschiedene Tools zusammenstellen und nacheinander ausführen, um die richtigen Antworten zu erhalten.
Zum Beispiel fragt die obige Abfrage: „Welche Haut des Tieres ist für das Überleben an kalten Orten angepasst?“, Was eine wissenschaftliche Terminologie im Zusammenhang mit dem Überleben von Tieren beinhaltet. Infolgedessen beschließt der Planer, sich auf die Bing-Suchmaschine für domänenspezifisches Wissen zu verlassen, was von den zahlreichen verfügbaren Online-Ressourcen profitiert.
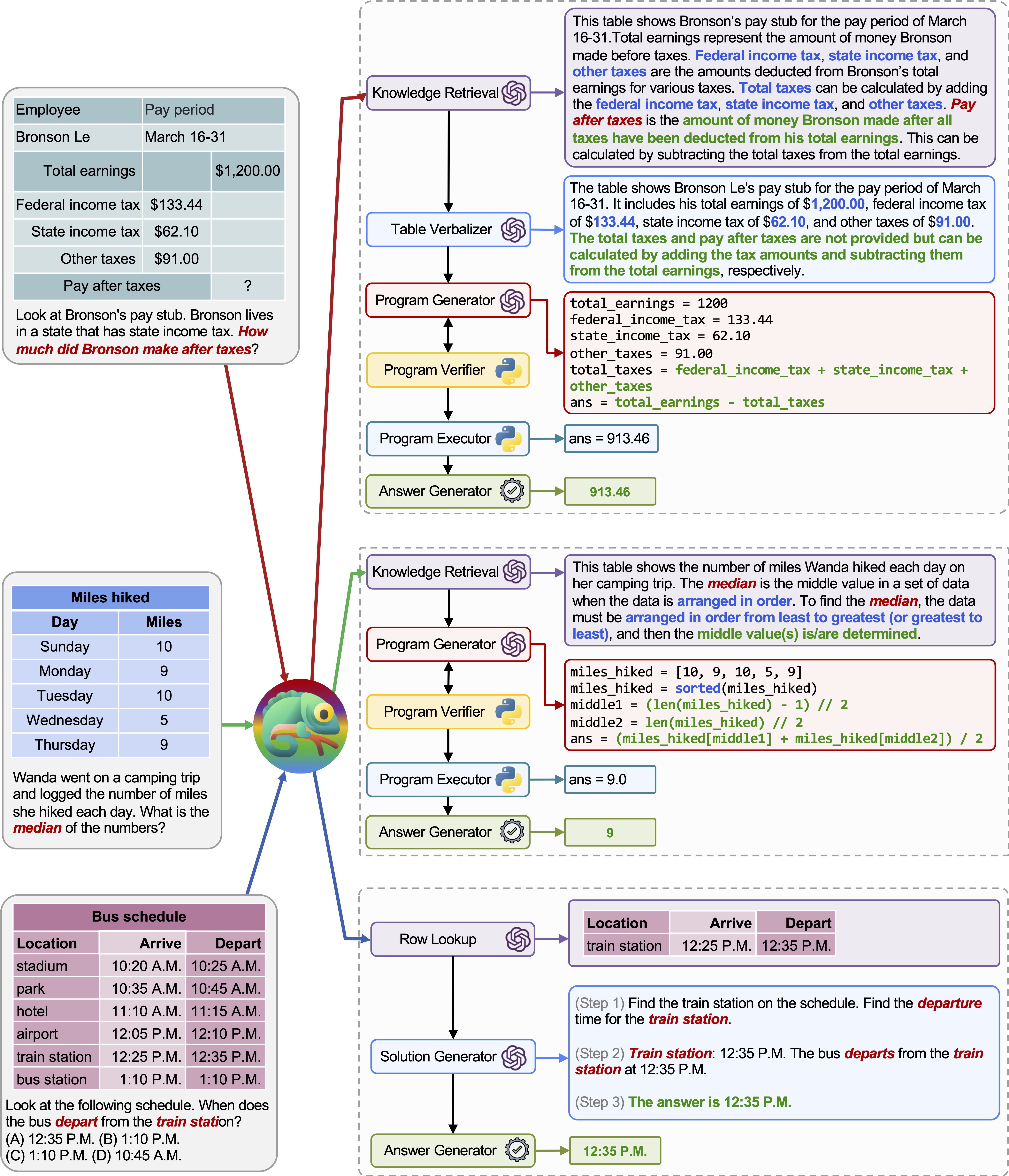
Die Anpassungsfähigkeit und Vielseitigkeit unseres Chamäleon für verschiedene Abfragen werden auch auf TABMWP beobachtet, wie in den Beispielen in der obigen Abbildung dargestellt.
Das erste Beispiel beinhaltet mathematisches Denken in einem Steuerformular. Chamäleon (1) ruft das Wissensabrufmodell auf, um Grundwissen zu erinnern, das beim Verständnis solcher domänenspezifischen Tabellen hilft, (2) die Tabelle in einem lesbaren natürlichen Sprachformat beschreibt, und (3) stützt sich schließlich auf programmgestützte Tools zur Ausführung Präzise Berechnungen.
Im zweiten Beispiel generiert das System einen Python -Code, der genau mit dem Hintergrundkenntnis des Wissensabrufmodells übereinstimmt.
Im dritten Beispiel muss das System die Zelle in einem großen tabellarischen Kontext angesichts der Eingabeabfrage lokalisieren. Chameleon nennt das Zeilen-Lookup-Modell, um die relevanten Zeilen genau zu lokalisieren und die Sprachlösung über ein LLM-Modell zu generieren, anstatt sich auf programmbasierte Tools zu verlassen.
Für Chamäleon werden bei beiden fein abgestimmten Modellen signifikante Verbesserungen beobachtet, und nur wenige Schüsse veranlassten GPT-4/CHATGPT:
Um die Vorhersagen von Chameleon zu visualisieren, führen Sie einfach das Jupyter -Notizbuch aus, das Ihrer spezifischen Aufgabe entspricht: notebooks/results_viewer_[TASK].ipynb . Dies bietet eine interaktive und benutzerfreundliche Möglichkeit, die vom Modell generierten Ergebnisse zu untersuchen. Erkunden Sie alternativ unsere Projektseite für weitere Informationen und Optionen.
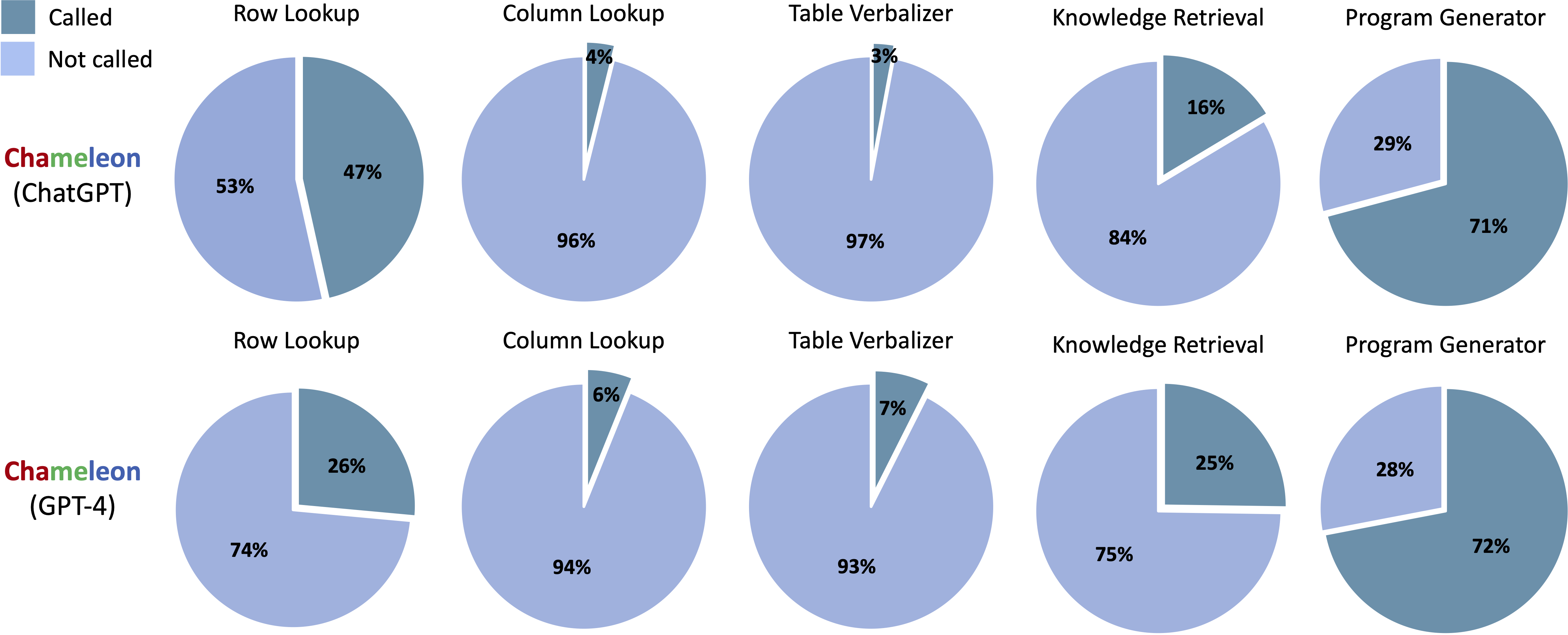
Tools, die in den generierten Programmen von Chameleon (CHATGPT) und Chameleon (GPT-4) auf ScienceQA aufgerufen wurden:

Tools, die in den generierten Programmen von Chameleon (CHATGPT) und Chameleon (GPT-4) auf Tabmwp aufgerufen wurden:
Führen Sie notebooks/transition_[TASK]_[Model]_Engine.ipynb aus, um das Modulübergangsdiagramm für Programme zu visualisieren, die im Testsatz generiert wurden.
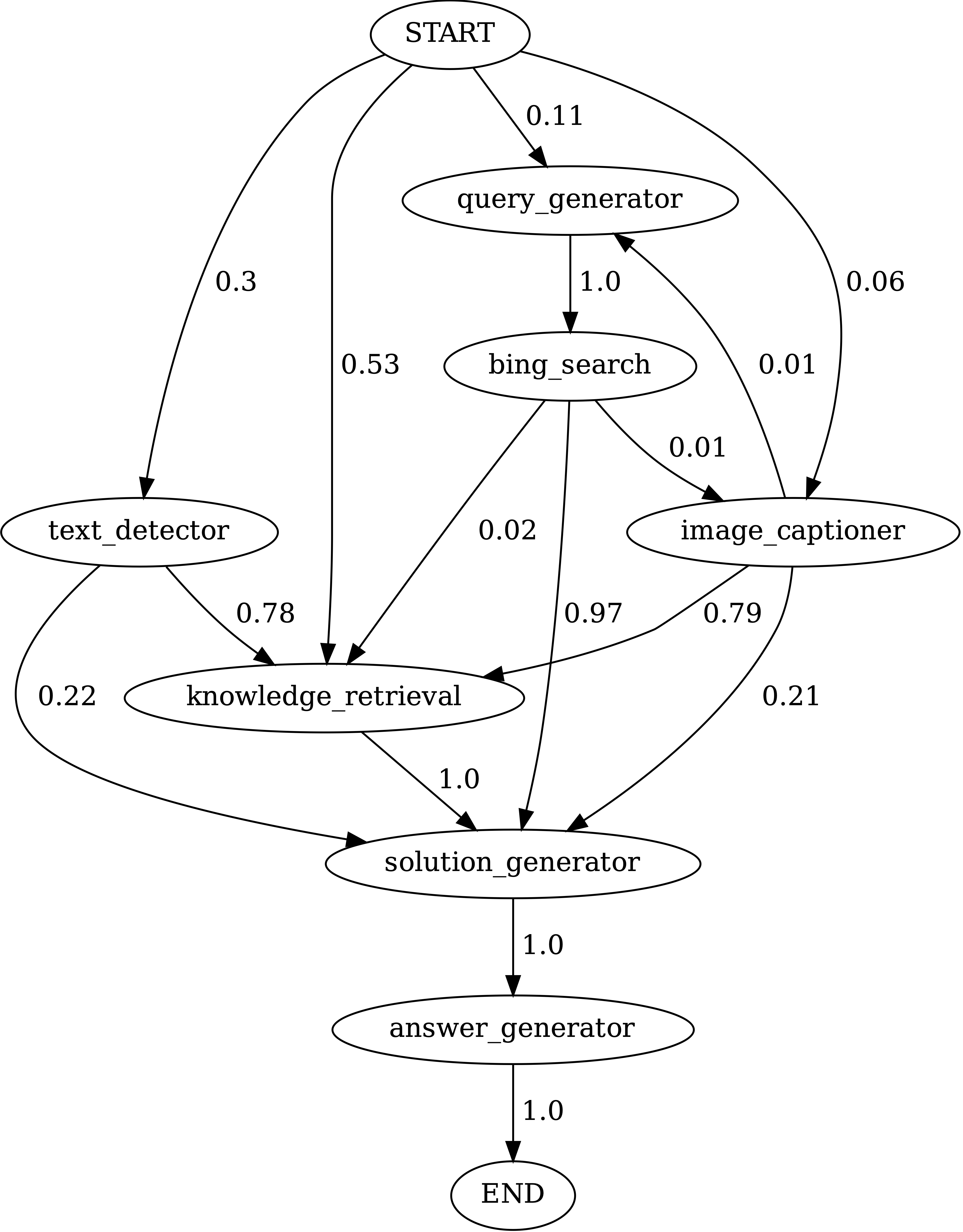
Übergänge zwischen Modulen in Programmen, die von Chameleon (GPT-4) auf ScienceQA erzeugt wurden. Start ist das Startsymbol, Ende ist ein Endsymbol und die anderen sind nicht terminale Symbole.
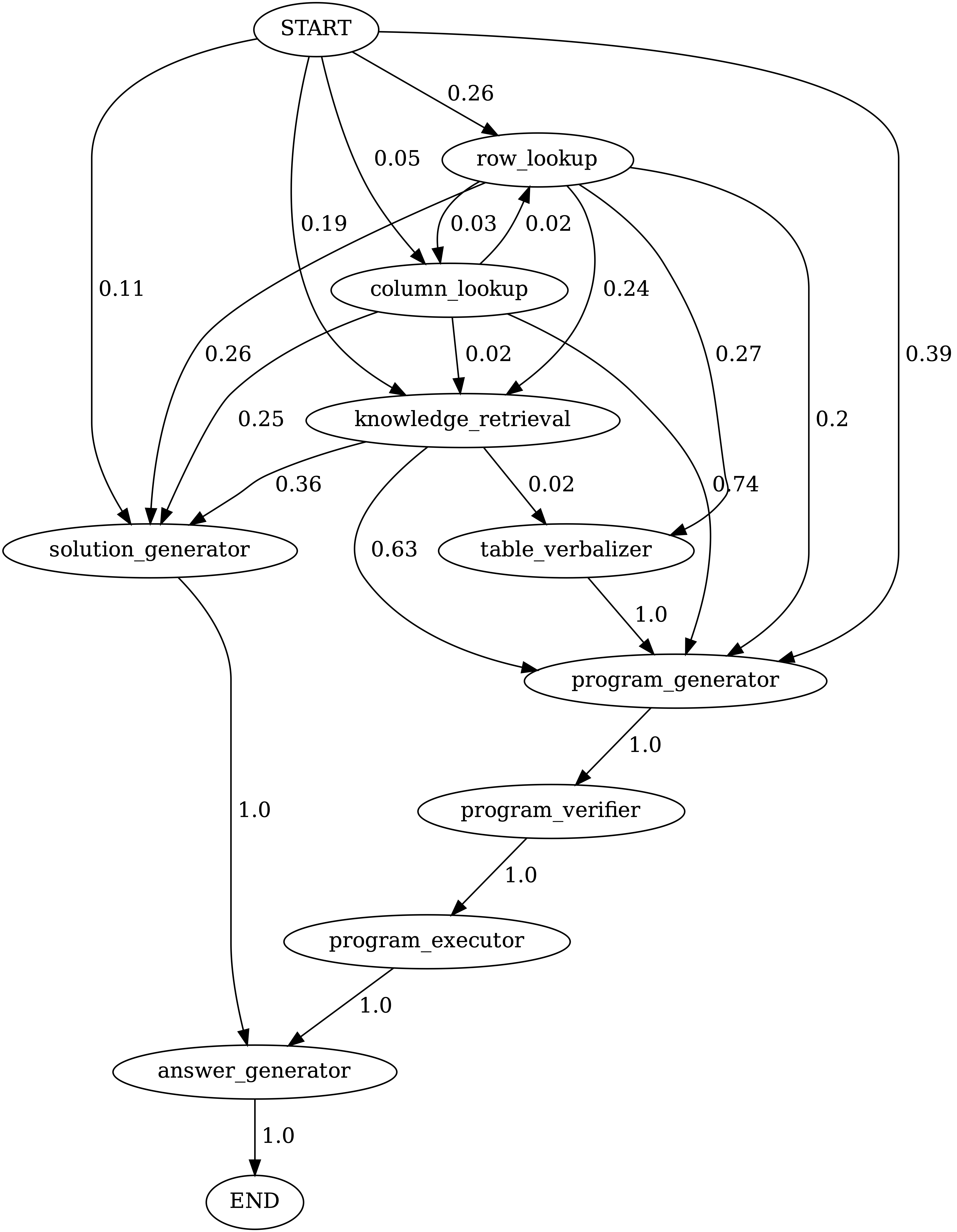
Übergänge zwischen Modulen in Programmen, die von Chameleon (GPT-4) auf tabmwpqa generiert wurden. Start ist das Startsymbol, Ende ist ein Endsymbol und die anderen sind nicht terminale Symbole.
demos Verzeichnis. Definieren Sie die Eingabe, Ausführung und Ausgabe für jedes Modul in model.py .model.py . Um die Bewertungsmethode zu ändern, aktualisieren Sie den entsprechenden Abschnitt in main.pyFantastisch! Ich bin immer offen für ansprechende Diskussionen, Kooperationen oder sogar nur einen virtuellen Kaffee. Um Kontakt aufzunehmen, besuchen Sie die Homepage von Pan Lu für Kontaktinformationen.
Wenn Sie Chamäleon für Ihre Forschung und Anwendungen nützlich finden, zitieren Sie bitte mit diesem Bibtex:
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

