chameleon llm
v1.0
Code du papier "Chameleon: Raisonnement de composition plug-and-play avec des modèles de gros langues".
? Si vous avez des questions ou des suggestions, n'hésitez pas à nous le faire savoir. Vous pouvez directement envoyer un e-mail à PAN LU à l'aide de l'adresse e-mail [email protected], commenter le Twitter ou publier un problème sur ce référentiel.
[Page du projet] [Paper] [Twitter] [LinkedIn] [YouTube] [diapositives]
Logo provisoire pour Chameleon .
Chameleon est un cadre de raisonnement de composition plug-and-play qui augmente les LLM avec différents types d'outils. Chameleon synthétise des programmes pour composer divers outils, notamment des modèles LLM, des modèles de vision standard, des moteurs de recherche Web, des fonctions Python et des modules basés sur des règles adaptés aux intérêts des utilisateurs. Construit au-dessus d'un LLM en tant que planificateur de langage naturel, le caméléon déduit la séquence appropriée d'outils pour composer et exécuter afin de générer une réponse finale.
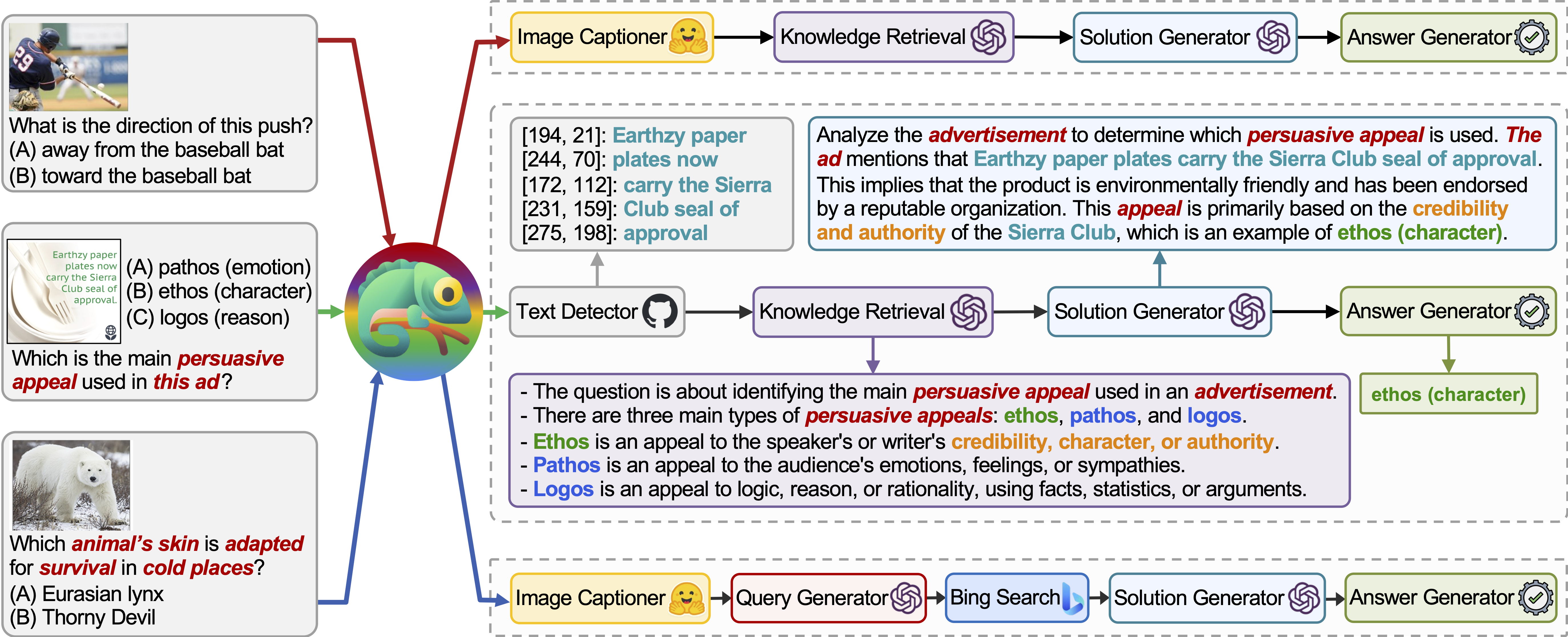
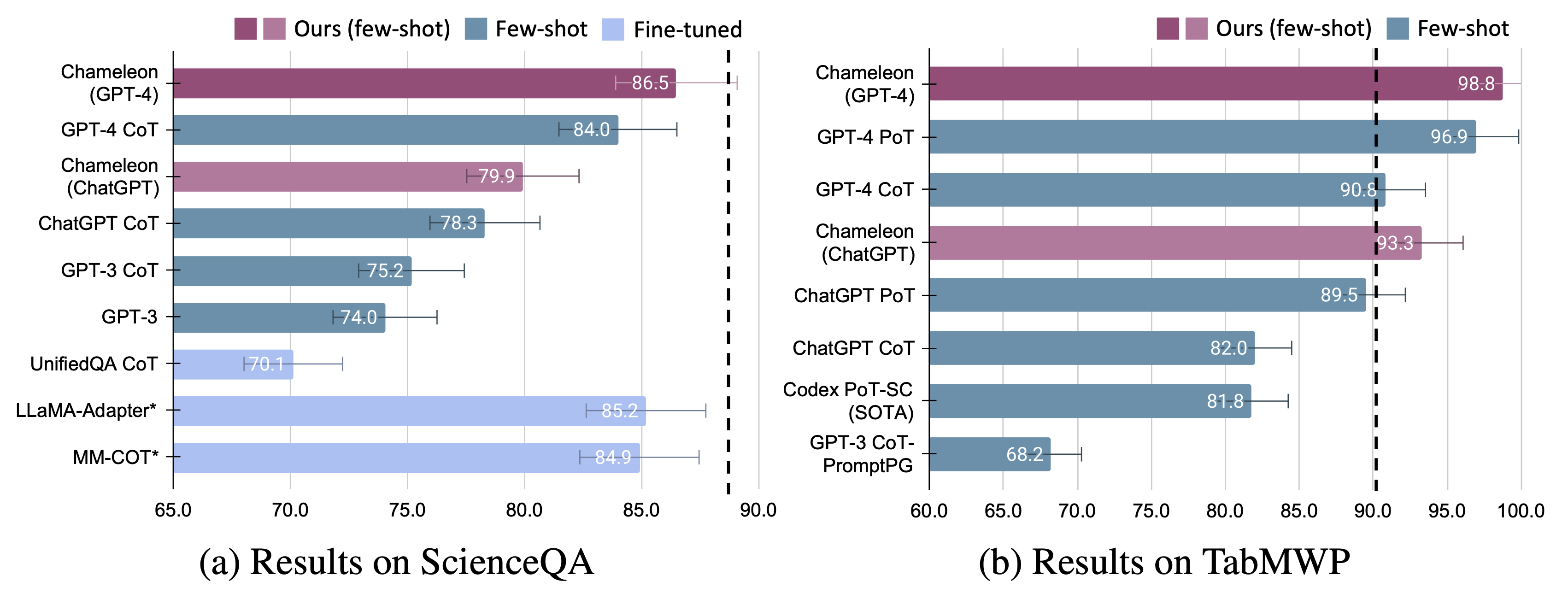
Nous présentons l'adaptabilité et l'efficacité du caméléon sur deux tâches: ScienceQA et TabMWP. Notamment, Chameleon avec GPT-4 atteint une précision de 86,54% sur ScienceQA, améliorant considérablement le modèle à quelques tirs le mieux publié de 11,37%; En utilisant GPT-4 comme LLM sous-jacent, Chameleon atteint une augmentation de 17,0% par rapport au modèle de pointe, conduisant à une précision globale de 98,78% sur TABMWP. D'autres études suggèrent que l'utilisation de GPT-4 comme planificateur présente une sélection d'outils plus cohérente et rationnelle et est capable de déduire des contraintes potentielles compte tenu des instructions, par rapport à d'autres LLM comme Chatgpt.
Pour plus de détails, vous pouvez trouver notre page de projet ici et notre article ici.
Nous aimerions exprimer notre immense gratitude à WorldOfai pour avoir présenté et présenter notre travail sur YouTube!
Installez toutes les dépendances Python requises (générées par pipreqs ):
python==3.8.10
huggingface-hub
numpy==1.23.2
openai==0.23.0
pandas==1.4.3
transformers==4.21.1
requests==2.28.1
Installez toutes les dépendances Python requises (vous pouvez ignorer cette étape si vous avez déjà configuré les dépendances et que les versions ne sont pas strictement requises):
pip install -r requirements.txt
Obtenez votre clé API OpenAI à partir de: https://platform.openai.com/account/api-Keys.
Pour utiliser la clé API Openai pour Chameleon , vous devez faire configurer la facturation (compte payant).
Vous pouvez configurer un compte payant sur https://platform.openai.com/account/billing/overview.
Obtenez votre clé API de recherche Bing de: https://www.microsoft.com/en-us/bing/apis/bing-web-search-api.
La touche API de recherche Bing est facultative . Le fait de ne pas configurer cette clé entraînera une légère baisse des performances sur la tâche ScienceQA.
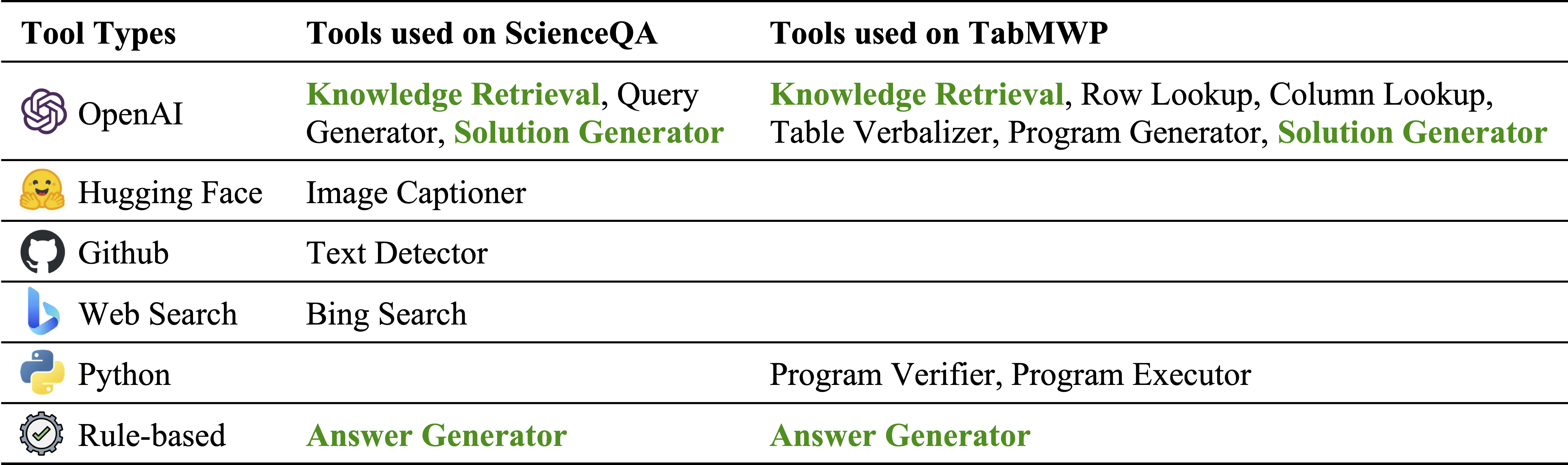
Différents types d'outils dans notre inventaire de module:

Outils utilisés sur ScienceQA et TabMWP, respectivement. Les outils réutilisables dans deux tâches sont mis en évidence en vert:
La réponse à la question de la question scientifique (ScienceQA) est une référence multimodale de questions de questions couvrant un large éventail de sujets scientifiques dans divers contextes. L'ensemble de données ScienceQA est fourni dans data/scienceqa . Pour plus de détails, vous pouvez explorer l'ensemble de données et consulter la page Explorer et visualiser la page.
Pour la version actuelle, les résultats du Image Captioner et Text Detector sont standard et stockés dans data/scienceqa/captions.json et data/scienceqa/ocrs.json , respectivement. Les appels en direct ces deux modules arrivent bientôt!
Pour courir Chameleon (GPT-4):
cd run_scienceqa
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-4
--kr_engine gpt-4
--qg_engine gpt-4
--sg_engine gpt-4
--test_split test
--test_number -1 Il générera les prédictions et sauvera les résultats sur results/scienceqa/chameleon_gpt4_test.json , results/scienceqa/chameleon_gpt4_test_cache.jsonl , et results/scienceqa/chameleon_gpt4_test_cache.json .
Nous pouvons obtenir les mesures de précision en moyenne et sur différentes classes de questions en fonctionnant:
python evaluate.py
--data_file ../data/scienceqa/problems.json
--result_root ../results/scienceqa
--result_files chameleon_chatgpt_test_cache.jsonlPour exécuter Chameleon (Chatgpt):
python run.py
--model chameleon
--label chameleon_gpt4
--policy_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--qg_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--test_split test
--test_number -1 Notre caméléon est une forme généralisée de la méthode COT (chaîne de pensée), où le programme généré est une séquence de Solution Generator et Answer Generator . En passant --model comme cot , modules sont définis comme ["solution_generator", "answer_generator"] .
Pour courir le COT (chaîne de pensée invitée) GPT-4:
python run.py
--model cot
--label cot_gpt4
--sg_engine gpt-4
--test_split test
--test_number -1Pour courir le COT (chaîne de pensée invitée) Chatgpt:
python run.py
--model cot
--label cot_chatgpt
--sg_engine gpt-4
--test_split test
--test_number -1 L'ensemble de données TABMWP contient 38 431 problèmes de mots mathématiques tabulaires. Chaque question dans TABMWP est alignée sur un contexte tabulaire, qui est présenté comme une image, un texte semi-structuré et une table structurée. L'ensemble de données TABMWP est fourni dans data/tabmwp . Pour plus de détails, vous pouvez explorer l'ensemble de données et consulter la page Explorer et visualiser la page.
Pour courir Chameleon (GPT-4):
cd run_tabmwp
python run.py
--model chameleon
--label chameleon_gpt4
--test_split test
--policy_engine gpt-4
--rl_engine gpt-4
--cl_engine gpt-4
--tv_engine gpt-4
--kr_engine gpt-4
--sg_engine gpt-4
--pg_engine gpt-4
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18 Il générera les prédictions et enregistrera les résultats sur results/tabmwp/chameleon_gpt4_test.json , results/tabmwp/chameleon_gpt4_test_cache.jsonl , et results/tabmwp/chameleon_gpt4_test_cache.json .
Nous pouvons obtenir les mesures de précision en moyenne et sur différentes classes de questions en fonctionnant:
python evaluate.py
--data_file ../data/tabmwp/problems_test.json
--result_root ../results/tabmwp
--result_files chameleon_chatgpt_test_cache.jsonlPour exécuter Chameleon (Chatgpt):
python run.py
--model chameleon
--label chameleon_chatgpt
--test_split test
--policy_engine gpt-3.5-turbo
--rl_engine gpt-3.5-turbo
--cl_engine gpt-3.5-turbo
--tv_engine gpt-3.5-turbo
--kr_engine gpt-3.5-turbo
--sg_engine gpt-3.5-turbo
--pg_engine gpt-3.5-turbo
--test_number -1
--rl_cell_threshold 18
--cl_cell_threshold 18Pour courir le COT (chaîne de pensée invitée) GPT-4:
python run.py
--model cot
--label cot_gpt4
--test_split test
--sg_engine gpt-4
--test_number -1Pour courir le COT (chaîne de pensée invitée) Chatgpt:
python run.py
--model cot
--label cot_chatgpt
--test_split test
--sg_engine gpt-3.5-turbo
--test_number -1 Notre caméléon est une forme généralisée de la méthode Pot (programme de pensée), où le programme généré est une séquence de Program Generator , Program Executor et Answer Generator . En passant --model en pot , modules sont définis comme ["program_generator", "program_executor", "answer_generator"] .
Pour exécuter le pot (programme de pensée invité) GPT-4:
python run.py
--model pot
--label pot_gpt4
--test_split test
--pg_engine gpt-4
--test_number -1Pour exécuter un pot (programme de pensée invité) Chatgpt:
python run.py
--model pot
--label pot_chatgpt
--test_split test
--pg_engine gpt-3.5-turbo
--test_number -1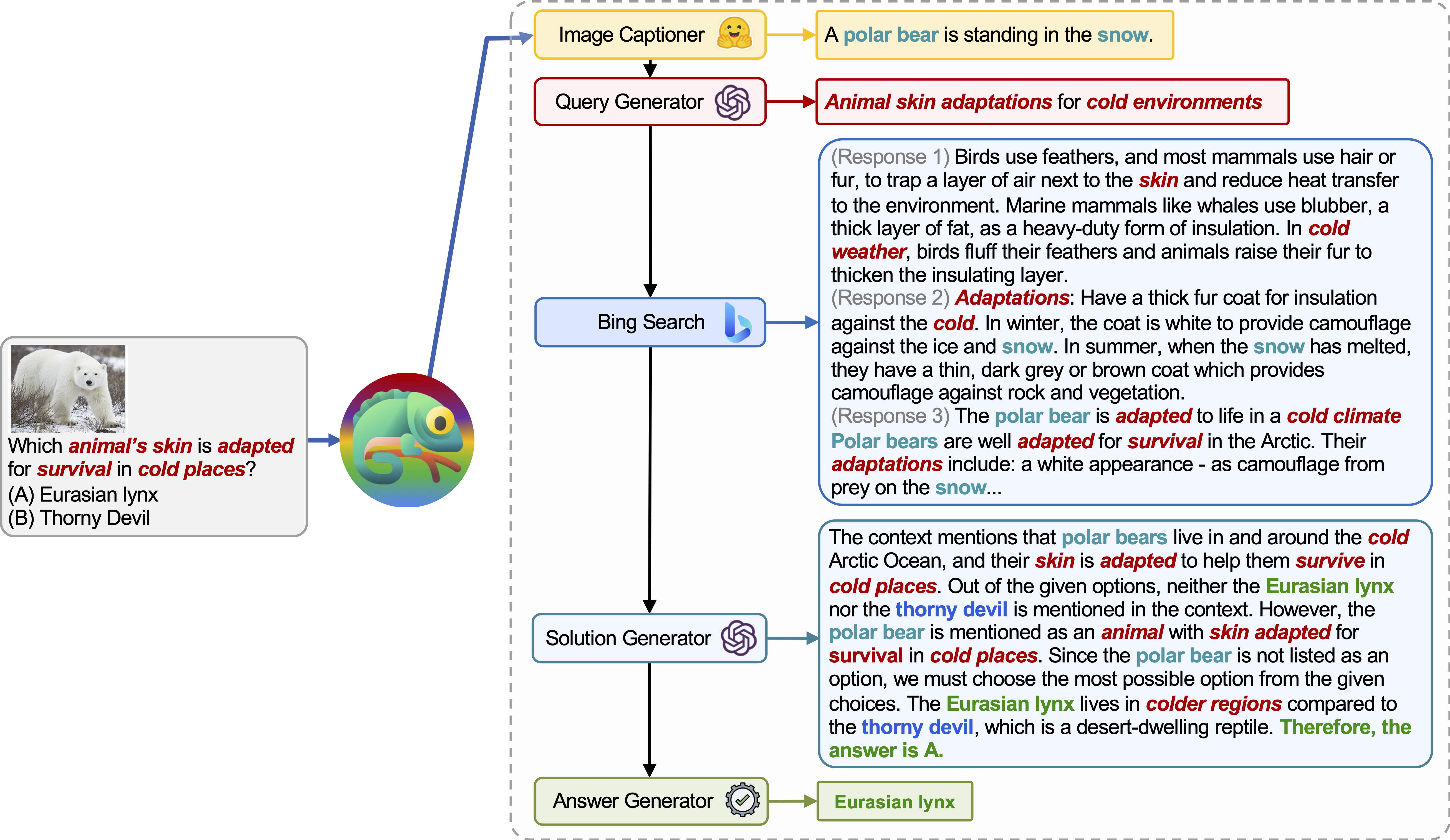
Chameleon (GPT-4) est capable de s'adapter à différentes requêtes d'entrée en générant des programmes qui composent divers outils et les exécuter séquentiellement pour obtenir les bonnes réponses.
Par exemple, la requête ci-dessus demande: «Quelle peau de l'animal est adaptée à la survie dans des endroits froids?», Qui implique une terminologie scientifique liée à la survie animale. Par conséquent, le planificateur décide de s'appuyer sur le moteur de recherche Bing pour les connaissances spécifiques au domaine, bénéficiant des nombreuses ressources en ligne disponibles.
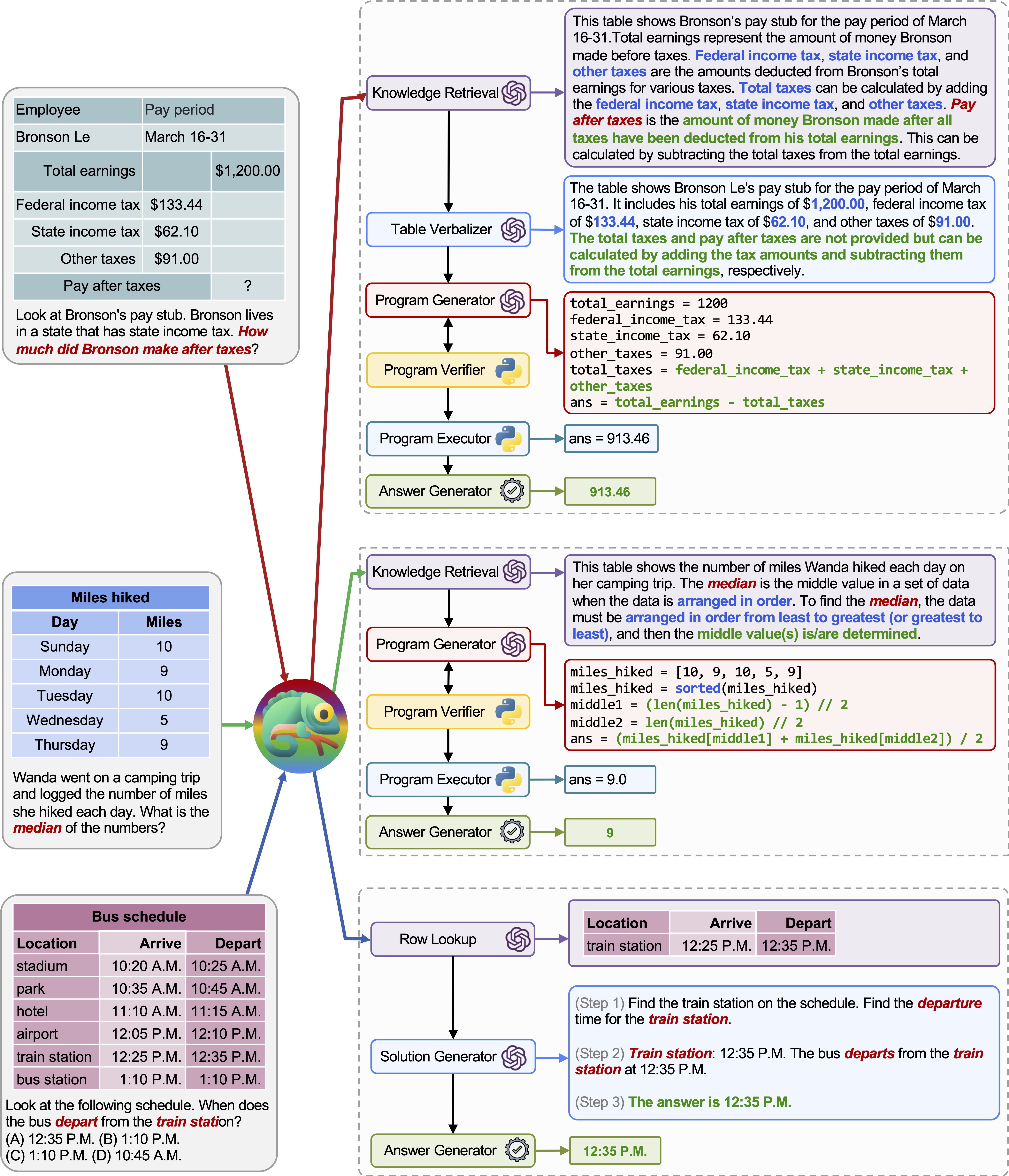
L'adaptabilité et la polyvalence de notre caméléon pour diverses requêtes sont également observées sur TABMWP, comme illustré dans les exemples de la figure ci-dessus.
Le premier exemple implique un raisonnement mathématique sur un formulaire fiscal. Chameleon (1) appelle le modèle de récupération des connaissances pour rappeler les connaissances de base qui aident à comprendre ces tables spécifiques au domaine, (2) décrit le tableau dans un format de langage naturel plus lisible, et (3) s'appuie enfin sur des outils assistés par le programme pour effectuer calculs précis.
Dans le deuxième exemple, le système génère du code Python qui s'aligne étroitement sur les connaissances de base fournies par le modèle de récupération des connaissances.
Le troisième exemple nécessite que le système localise la cellule dans un grand contexte tabulaire compte tenu de la requête d'entrée. Chameleon appelle le modèle de recherche de lignes pour aider à localiser avec précision les lignes pertinentes et générer la solution linguistique via un modèle LLM, au lieu de compter sur des outils basés sur le programme.
Des améliorations significatives sont observées pour le caméléon sur les deux modèles affinés et à quelques coups invités GPT-4 / Chatgpt:
Pour visualiser les prédictions faites par Chameleon , exécutez simplement le cahier Jupyter correspondant à votre tâche spécifique: notebooks/results_viewer_[TASK].ipynb . Cela fournira une façon interactive et conviviale d'explorer les résultats générés par le modèle. Alternativement, explorez notre page de projet pour plus d'informations et d'options.
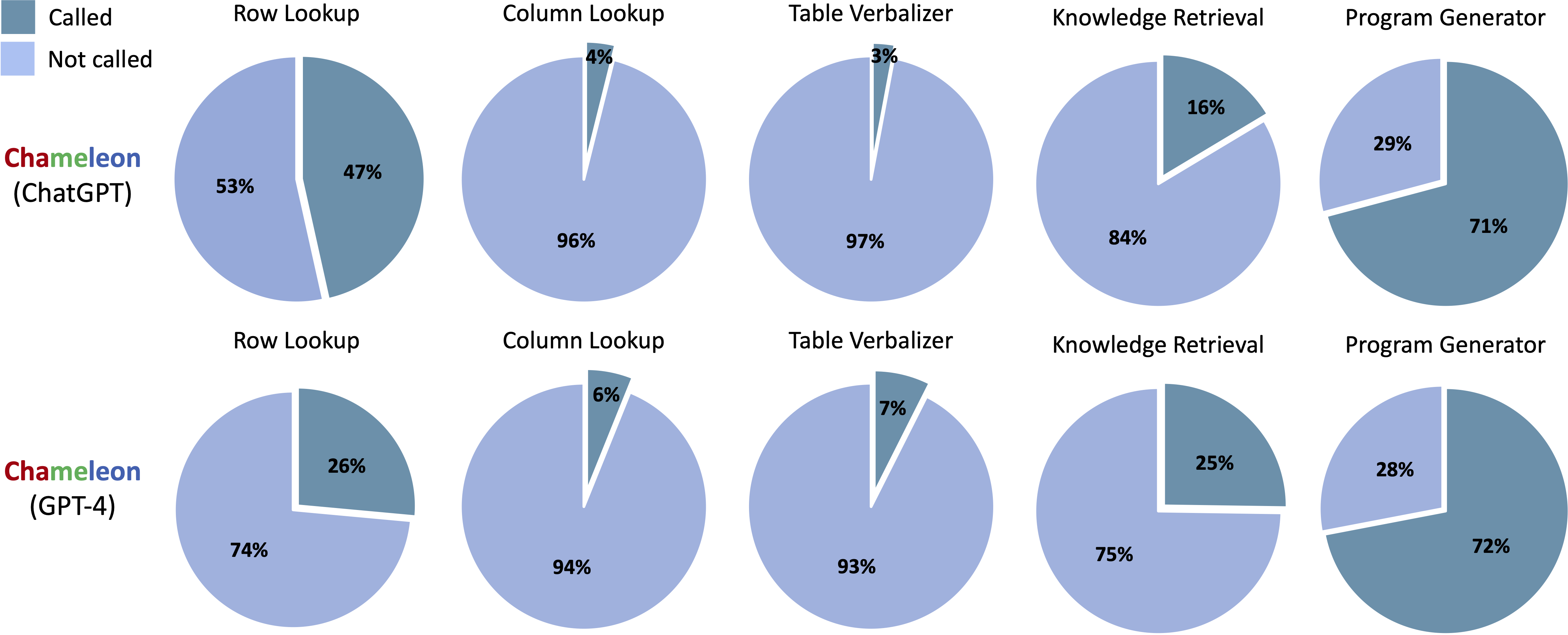
Outils appelés dans les programmes générés de Chameleon (Chatgpt) et Chameleon (GPT-4) sur ScienceQA:

Outils appelés dans les programmes générés de Chameleon (Chatgpt) et Chameleon (GPT-4) sur TABMWP:
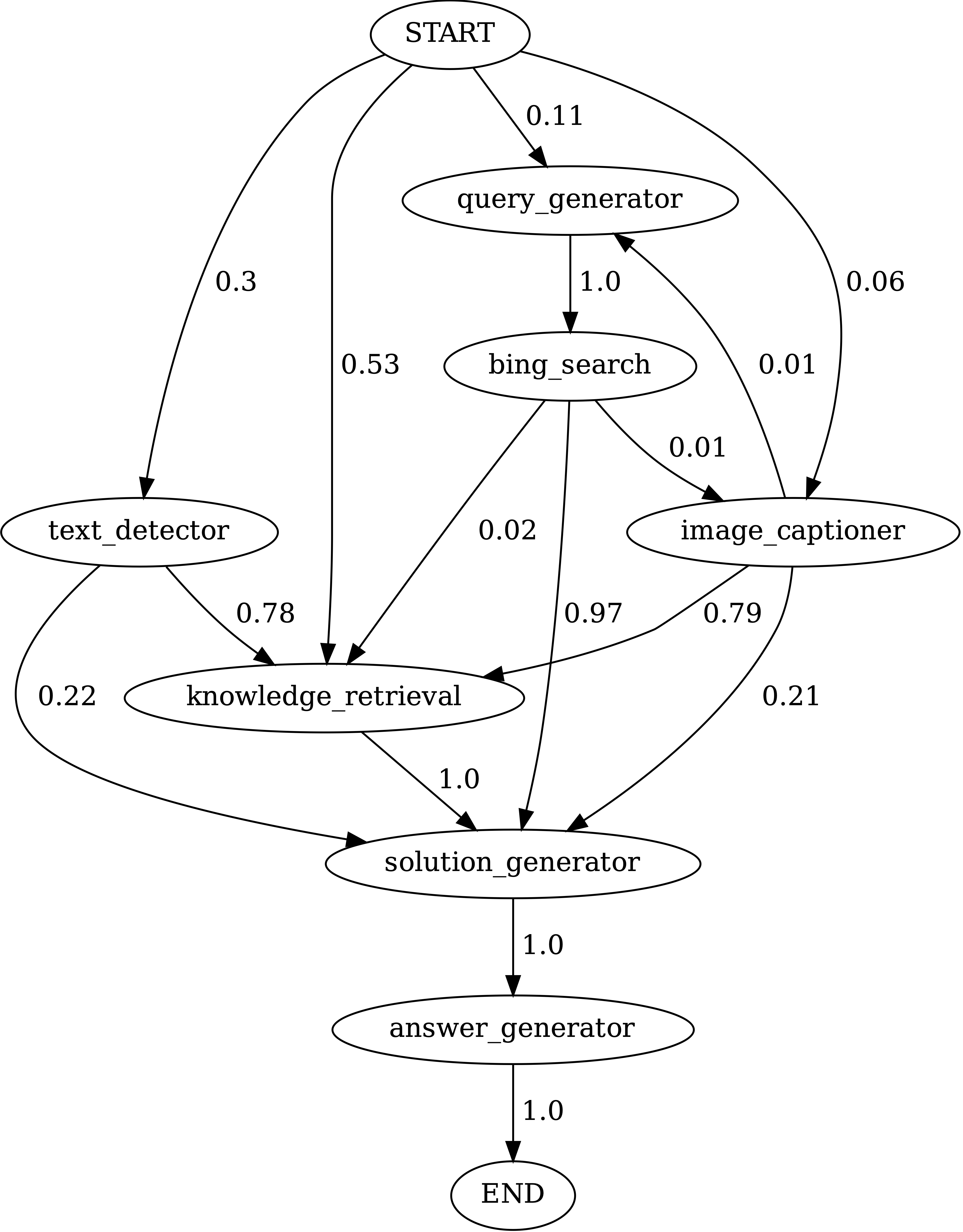
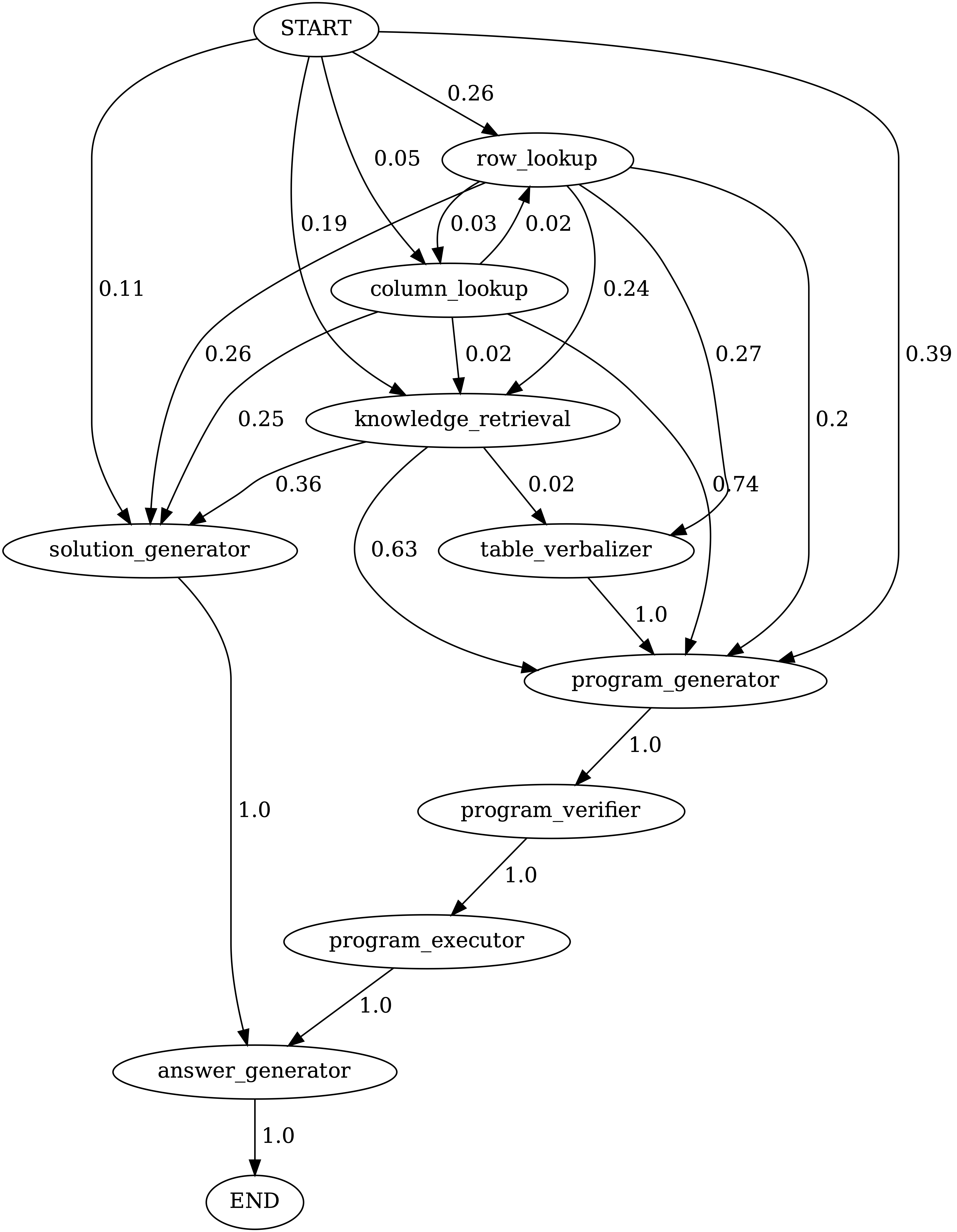
Exécuter notebooks/transition_[TASK]_[Model]_Engine.ipynb pour visualiser le graphique de transition du module pour les programmes générés sur l'ensemble de tests.
Transitions entre les modules dans les programmes générés par Chameleon (GPT-4) sur ScienceQA. Le début est le symbole de début, la fin est un symbole terminal et les autres sont des symboles non terminaux.
Transitions entre les modules dans les programmes générés par Chameleon (GPT-4) sur TABMWPQA. Le début est le symbole de début, la fin est un symbole terminal et les autres sont des symboles non terminaux.
demos . Définissez l'entrée, l'exécution et la sortie pour chaque module dans model.py .model.py . Pour modifier la méthode d'évaluation, mettez à jour la section correspondante dans main.pyFantastique! Je suis toujours ouvert à des discussions engageantes, à des collaborations ou même à partager un café virtuel. Pour nous contacter, visitez la page d'accueil de Pan Lu pour les coordonnées.
Si vous trouvez Chameleon utile pour vos recherches et vos applications, veuillez citer avec cette Bibtex:
@article{lu2023chameleon,
title={Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models},
author={Lu, Pan and Peng, Baolin and Cheng, Hao and Galley, Michel and Chang, Kai-Wei and Wu, Ying Nian and Zhu, Song-Chun and Gao, Jianfeng},
journal={arXiv preprint arXiv:2304.09842},
year={2023}
}

