face.evoLVe
1.0.0
| Autor | Jian Zhao |
|---|---|
| Página inicial | https://zhaoj9014.github.io |
O código de face.evolve é liberado sob a licença do MIT.
✅ CLOSED 02 September 2021 : O Baidu Paddlepaddle se fundiu oficialmente. Evoluir para facilitar pesquisas e aplicações em análises relacionadas a rosto (anúncio oficial).
✅ CLOSED 03 July 2021 : Fornece código de treinamento para a estrutura Paddlepddle.
✅ CLOSED 04 July 2019 : Compartilharemos vários conjuntos de dados disponíveis ao público na detecção de anti-spoofing/lutividade de face para facilitar pesquisas e análises relacionadas.
✅ CLOSED 07 June 2019 : Estamos treinando um modelo IR-152 com melhor desempenho no MS-CELEB-1M_ALIGN_112X112 e lançará o modelo em breve.
✅ CLOSED 23 May 2019 : Compartilhamos três conjuntos de dados disponíveis ao público para facilitar a pesquisa sobre reconhecimento e análise heterogêneos de rosto. Por favor, consulte a Sec. Data Zoo para obter detalhes.
✅ CLOSED 23 Jan 2019 : Compartilhamos as listas de nomes e listas sobrepostas em pares de vários conjuntos de dados de reconhecimento de rosto amplamente utilizados para ajudar pesquisadores/engenheiros a remover rapidamente as peças sobrepostas entre seus próprios conjuntos de dados privados e os conjuntos de dados públicos. Por favor, consulte a Sec. Data Zoo para obter detalhes.
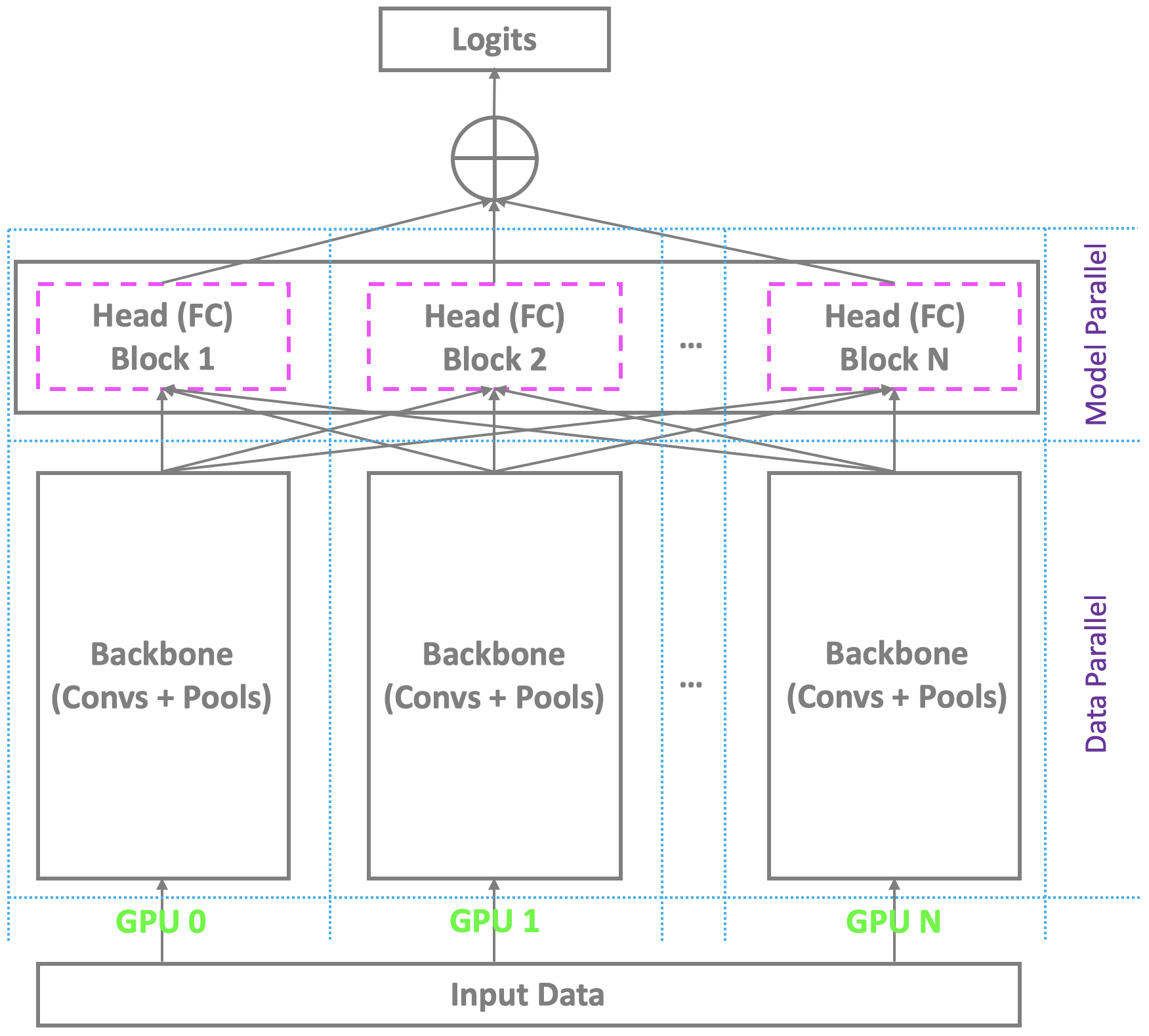
✅ CLOSED 23 Jan 2019 : O atual esquema de treinamento distribuído com Multi-GPUs sob Pytorch e outras plataformas convencionais é paralelo à espinha dorsal entre as Multi-GPUs, enquanto se baseia em um único mestre para calcular a camada final de gargalo (totalmente conectada/softmax). Este não é um problema para o reconhecimento de rosto convencional com número moderado de identidades. No entanto, luta com o reconhecimento de rosto em larga escala, o que exige reconhecer milhões de identidades no mundo real. O mestre dificilmente pode manter a camada final de grandes dimensões, enquanto os escravos ainda têm recursos de computação redundantes, levando a treinamento em pequenos lotes ou até mesmo treinamento com falha. Para resolver esse problema, estamos desenvolvendo um esquema de treinamento distribuído altamente elegante, eficaz e eficiente com multi-GPUs sob Pytorch, apoiando não apenas a espinha dorsal, mas também a cabeça com a camada totalmente conectada (softmax), para facilitar o reconhecimento de face de grande escala de alta desempenho. Adicionaremos esse suporte ao nosso repositório.
✅ CLOSED 22 Jan 2019 : Lançamos duas APIs de extração de recursos para extrair recursos de modelos pré-treinados, implementados com funções de construção do Pytorch e OpenCV, respectivamente. Verifique ./util/extract_feature_v1.py e ./util/extract_feature_v2.py .
✅ CLOSED 22 Jan 2019 : Estamos ajustando o modelo IR-50 lançado em nossos dados privados da Ásia, que serão lançados em breve para facilitar o reconhecimento da ASIA de alto desempenho.
✅ CLOSED 21 Jan 2019 : Estamos treinando um modelo IR-50 com melhor desempenho no MS-CELEB-1M_ALIGN_112X112 e substituiremos o modelo atual em breve.
?

?
pip install torch torchvision )pip install mxnet-cu90 )pip install tensorflow-gpu )pip install tensorboardX )pip install opencv-python )pip install bcolz )Embora não seja necessário, para o desempenho ideal, é altamente recomendável executar o código usando uma GPU habilitada para CUDA. Utilizamos 4-8 Nvidia Tesla P40 em paralelo.
?
git clone https://github.com/ZhaoJ9014/face.evoLVe.PyTorch.git .mkdir data checkpoint log no diretório apropriado para armazenar seus dados de trem/val/teste, pontos de verificação e registros de treinamento. ./data/db_name/
-> id1/
-> 1.jpg
-> ...
-> id2/
-> 1.jpg
-> ...
-> ...
-> ...
-> ...
?


./align from PIL import Image
from detector import detect_faces
from visualization_utils import show_results
img = Image . open ( 'some_img.jpg' ) # modify the image path to yours
bounding_boxes , landmarks = detect_faces ( img ) # detect bboxes and landmarks for all faces in the image
show_results ( img , bounding_boxes , landmarks ) # visualize the resultssource_root com a estrutura do diretório, como demonstrado na seção de uso e armazenar os resultados alinhados em uma nova pasta dest_root com a mesma estrutura de diretório): python face_align.py -source_root [source_root] -dest_root [dest_root] -crop_size [crop_size]
# python face_align.py -source_root './data/test' -dest_root './data/test_Aligned' -crop_size 112
*.DS_Store que podem arruinar seus dados, pois eles serão removidos automaticamente quando você executar os scripts.source_root , dest_root e crop_size aos seus próprios valores quando você executar face_align.py ; 2) Passe seus valores de min_face_size , thresholds e nms_thresholds para a função detect_faces do detector.py para atender aos seus requisitos práticos; 3) Se você encontrar a velocidade usando a API de alinhamento de face é um pouco lenta, poderá chamar a API de redimensionamento FACE para redimensionar primeiro a imagem cujo tamanho menor é maior que um limiar (especifique os argumentos da source_root , dest_root e min_side para seus próprios valores) antes de chamar o alinhamento da face API: python face_resize.py
./balancemin_num no conjunto de treinamento root com a estrutura do diretório, conforme demonstrado na seção python remove_lowshot.py -root [root] -min_num [min_num]
# python remove_lowshot.py -root './data/train' -min_num 10
root e min_num aos seus próprios valores quando você executar remove_lowshot.py .☕
Pasta: ./
API de configuração (configure suas configurações gerais para treinamento e validação) config.py :
import torch
configurations = {
1 : dict (
SEED = 1337 , # random seed for reproduce results
DATA_ROOT = '/media/pc/6T/jasonjzhao/data/faces_emore' , # the parent root where your train/val/test data are stored
MODEL_ROOT = '/media/pc/6T/jasonjzhao/buffer/model' , # the root to buffer your checkpoints
LOG_ROOT = '/media/pc/6T/jasonjzhao/buffer/log' , # the root to log your train/val status
BACKBONE_RESUME_ROOT = './' , # the root to resume training from a saved checkpoint
HEAD_RESUME_ROOT = './' , # the root to resume training from a saved checkpoint
BACKBONE_NAME = 'IR_SE_50' , # support: ['ResNet_50', 'ResNet_101', 'ResNet_152', 'IR_50', 'IR_101', 'IR_152', 'IR_SE_50', 'IR_SE_101', 'IR_SE_152']
HEAD_NAME = 'ArcFace' , # support: ['Softmax', 'ArcFace', 'CosFace', 'SphereFace', 'Am_softmax']
LOSS_NAME = 'Focal' , # support: ['Focal', 'Softmax']
INPUT_SIZE = [ 112 , 112 ], # support: [112, 112] and [224, 224]
RGB_MEAN = [ 0.5 , 0.5 , 0.5 ], # for normalize inputs to [-1, 1]
RGB_STD = [ 0.5 , 0.5 , 0.5 ],
EMBEDDING_SIZE = 512 , # feature dimension
BATCH_SIZE = 512 ,
DROP_LAST = True , # whether drop the last batch to ensure consistent batch_norm statistics
LR = 0.1 , # initial LR
NUM_EPOCH = 125 , # total epoch number (use the firt 1/25 epochs to warm up)
WEIGHT_DECAY = 5e-4 , # do not apply to batch_norm parameters
MOMENTUM = 0.9 ,
STAGES = [ 35 , 65 , 95 ], # epoch stages to decay learning rate
DEVICE = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" ),
MULTI_GPU = True , # flag to use multiple GPUs; if you choose to train with single GPU, you should first run "export CUDA_VISILE_DEVICES=device_id" to specify the GPU card you want to use
GPU_ID = [ 0 , 1 , 2 , 3 ], # specify your GPU ids
PIN_MEMORY = True ,
NUM_WORKERS = 0 ,
),
} API de trem e validação (todas as pessoas sobre treinamento e validação, ou seja , pacote de importação, hiperparameters e carregadores de dados, modelo e perda e otimizador, trem e validação e salvar ponto de verificação) train.py . Como o MS-CELEB-1M serve como um ImageNet no registro de reconhecimento de rosto, pré-trainamos os modelos FACE.Evolve no MS-CELEB-1M e realizamos validação em LFW, CFP_FF, CFP_FP, AGEDB, CLFW, CPLFW e VGGFFFFFPE2_FP. Vamos mergulhar em detalhes juntos passo a passo.
import torch
import torch . nn as nn
import torch . optim as optim
import torchvision . transforms as transforms
import torchvision . datasets as datasets
from config import configurations
from backbone . model_resnet import ResNet_50 , ResNet_101 , ResNet_152
from backbone . model_irse import IR_50 , IR_101 , IR_152 , IR_SE_50 , IR_SE_101 , IR_SE_152
from head . metrics import ArcFace , CosFace , SphereFace , Am_softmax
from loss . focal import FocalLoss
from util . utils import make_weights_for_balanced_classes , get_val_data , separate_irse_bn_paras , separate_resnet_bn_paras , warm_up_lr , schedule_lr , perform_val , get_time , buffer_val , AverageMeter , accuracy
from tensorboardX import SummaryWriter
from tqdm import tqdm
import os cfg = configurations [ 1 ]
SEED = cfg [ 'SEED' ] # random seed for reproduce results
torch . manual_seed ( SEED )
DATA_ROOT = cfg [ 'DATA_ROOT' ] # the parent root where your train/val/test data are stored
MODEL_ROOT = cfg [ 'MODEL_ROOT' ] # the root to buffer your checkpoints
LOG_ROOT = cfg [ 'LOG_ROOT' ] # the root to log your train/val status
BACKBONE_RESUME_ROOT = cfg [ 'BACKBONE_RESUME_ROOT' ] # the root to resume training from a saved checkpoint
HEAD_RESUME_ROOT = cfg [ 'HEAD_RESUME_ROOT' ] # the root to resume training from a saved checkpoint
BACKBONE_NAME = cfg [ 'BACKBONE_NAME' ] # support: ['ResNet_50', 'ResNet_101', 'ResNet_152', 'IR_50', 'IR_101', 'IR_152', 'IR_SE_50', 'IR_SE_101', 'IR_SE_152']
HEAD_NAME = cfg [ 'HEAD_NAME' ] # support: ['Softmax', 'ArcFace', 'CosFace', 'SphereFace', 'Am_softmax']
LOSS_NAME = cfg [ 'LOSS_NAME' ] # support: ['Focal', 'Softmax']
INPUT_SIZE = cfg [ 'INPUT_SIZE' ]
RGB_MEAN = cfg [ 'RGB_MEAN' ] # for normalize inputs
RGB_STD = cfg [ 'RGB_STD' ]
EMBEDDING_SIZE = cfg [ 'EMBEDDING_SIZE' ] # feature dimension
BATCH_SIZE = cfg [ 'BATCH_SIZE' ]
DROP_LAST = cfg [ 'DROP_LAST' ] # whether drop the last batch to ensure consistent batch_norm statistics
LR = cfg [ 'LR' ] # initial LR
NUM_EPOCH = cfg [ 'NUM_EPOCH' ]
WEIGHT_DECAY = cfg [ 'WEIGHT_DECAY' ]
MOMENTUM = cfg [ 'MOMENTUM' ]
STAGES = cfg [ 'STAGES' ] # epoch stages to decay learning rate
DEVICE = cfg [ 'DEVICE' ]
MULTI_GPU = cfg [ 'MULTI_GPU' ] # flag to use multiple GPUs
GPU_ID = cfg [ 'GPU_ID' ] # specify your GPU ids
PIN_MEMORY = cfg [ 'PIN_MEMORY' ]
NUM_WORKERS = cfg [ 'NUM_WORKERS' ]
print ( "=" * 60 )
print ( "Overall Configurations:" )
print ( cfg )
print ( "=" * 60 )
writer = SummaryWriter ( LOG_ROOT ) # writer for buffering intermedium results train_transform = transforms . Compose ([ # refer to https://pytorch.org/docs/stable/torchvision/transforms.html for more build-in online data augmentation
transforms . Resize ([ int ( 128 * INPUT_SIZE [ 0 ] / 112 ), int ( 128 * INPUT_SIZE [ 0 ] / 112 )]), # smaller side resized
transforms . RandomCrop ([ INPUT_SIZE [ 0 ], INPUT_SIZE [ 1 ]]),
transforms . RandomHorizontalFlip (),
transforms . ToTensor (),
transforms . Normalize ( mean = RGB_MEAN ,
std = RGB_STD ),
])
dataset_train = datasets . ImageFolder ( os . path . join ( DATA_ROOT , 'imgs' ), train_transform )
# create a weighted random sampler to process imbalanced data
weights = make_weights_for_balanced_classes ( dataset_train . imgs , len ( dataset_train . classes ))
weights = torch . DoubleTensor ( weights )
sampler = torch . utils . data . sampler . WeightedRandomSampler ( weights , len ( weights ))
train_loader = torch . utils . data . DataLoader (
dataset_train , batch_size = BATCH_SIZE , sampler = sampler , pin_memory = PIN_MEMORY ,
num_workers = NUM_WORKERS , drop_last = DROP_LAST
)
NUM_CLASS = len ( train_loader . dataset . classes )
print ( "Number of Training Classes: {}" . format ( NUM_CLASS ))
lfw , cfp_ff , cfp_fp , agedb , calfw , cplfw , vgg2_fp , lfw_issame , cfp_ff_issame , cfp_fp_issame , agedb_issame , calfw_issame , cplfw_issame , vgg2_fp_issame = get_val_data ( DATA_ROOT ) BACKBONE_DICT = { 'ResNet_50' : ResNet_50 ( INPUT_SIZE ),
'ResNet_101' : ResNet_101 ( INPUT_SIZE ),
'ResNet_152' : ResNet_152 ( INPUT_SIZE ),
'IR_50' : IR_50 ( INPUT_SIZE ),
'IR_101' : IR_101 ( INPUT_SIZE ),
'IR_152' : IR_152 ( INPUT_SIZE ),
'IR_SE_50' : IR_SE_50 ( INPUT_SIZE ),
'IR_SE_101' : IR_SE_101 ( INPUT_SIZE ),
'IR_SE_152' : IR_SE_152 ( INPUT_SIZE )}
BACKBONE = BACKBONE_DICT [ BACKBONE_NAME ]
print ( "=" * 60 )
print ( BACKBONE )
print ( "{} Backbone Generated" . format ( BACKBONE_NAME ))
print ( "=" * 60 )
HEAD_DICT = { 'ArcFace' : ArcFace ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID ),
'CosFace' : CosFace ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID ),
'SphereFace' : SphereFace ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID ),
'Am_softmax' : Am_softmax ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID )}
HEAD = HEAD_DICT [ HEAD_NAME ]
print ( "=" * 60 )
print ( HEAD )
print ( "{} Head Generated" . format ( HEAD_NAME ))
print ( "=" * 60 ) LOSS_DICT = { 'Focal' : FocalLoss (),
'Softmax' : nn . CrossEntropyLoss ()}
LOSS = LOSS_DICT [ LOSS_NAME ]
print ( "=" * 60 )
print ( LOSS )
print ( "{} Loss Generated" . format ( LOSS_NAME ))
print ( "=" * 60 ) if BACKBONE_NAME . find ( "IR" ) >= 0 :
backbone_paras_only_bn , backbone_paras_wo_bn = separate_irse_bn_paras ( BACKBONE ) # separate batch_norm parameters from others; do not do weight decay for batch_norm parameters to improve the generalizability
_ , head_paras_wo_bn = separate_irse_bn_paras ( HEAD )
else :
backbone_paras_only_bn , backbone_paras_wo_bn = separate_resnet_bn_paras ( BACKBONE ) # separate batch_norm parameters from others; do not do weight decay for batch_norm parameters to improve the generalizability
_ , head_paras_wo_bn = separate_resnet_bn_paras ( HEAD )
OPTIMIZER = optim . SGD ([{ 'params' : backbone_paras_wo_bn + head_paras_wo_bn , 'weight_decay' : WEIGHT_DECAY }, { 'params' : backbone_paras_only_bn }], lr = LR , momentum = MOMENTUM )
print ( "=" * 60 )
print ( OPTIMIZER )
print ( "Optimizer Generated" )
print ( "=" * 60 ) if BACKBONE_RESUME_ROOT and HEAD_RESUME_ROOT :
print ( "=" * 60 )
if os . path . isfile ( BACKBONE_RESUME_ROOT ) and os . path . isfile ( HEAD_RESUME_ROOT ):
print ( "Loading Backbone Checkpoint '{}'" . format ( BACKBONE_RESUME_ROOT ))
BACKBONE . load_state_dict ( torch . load ( BACKBONE_RESUME_ROOT ))
print ( "Loading Head Checkpoint '{}'" . format ( HEAD_RESUME_ROOT ))
HEAD . load_state_dict ( torch . load ( HEAD_RESUME_ROOT ))
else :
print ( "No Checkpoint Found at '{}' and '{}'. Please Have a Check or Continue to Train from Scratch" . format ( BACKBONE_RESUME_ROOT , HEAD_RESUME_ROOT ))
print ( "=" * 60 ) if MULTI_GPU :
# multi-GPU setting
BACKBONE = nn . DataParallel ( BACKBONE , device_ids = GPU_ID )
BACKBONE = BACKBONE . to ( DEVICE )
else :
# single-GPU setting
BACKBONE = BACKBONE . to ( DEVICE ) DISP_FREQ = len ( train_loader ) // 100 # frequency to display training loss & acc
NUM_EPOCH_WARM_UP = NUM_EPOCH // 25 # use the first 1/25 epochs to warm up
NUM_BATCH_WARM_UP = len ( train_loader ) * NUM_EPOCH_WARM_UP # use the first 1/25 epochs to warm up
batch = 0 # batch index for epoch in range ( NUM_EPOCH ): # start training process
if epoch == STAGES [ 0 ]: # adjust LR for each training stage after warm up, you can also choose to adjust LR manually (with slight modification) once plaueau observed
schedule_lr ( OPTIMIZER )
if epoch == STAGES [ 1 ]:
schedule_lr ( OPTIMIZER )
if epoch == STAGES [ 2 ]:
schedule_lr ( OPTIMIZER )
BACKBONE . train () # set to training mode
HEAD . train ()
losses = AverageMeter ()
top1 = AverageMeter ()
top5 = AverageMeter ()
for inputs , labels in tqdm ( iter ( train_loader )):
if ( epoch + 1 <= NUM_EPOCH_WARM_UP ) and ( batch + 1 <= NUM_BATCH_WARM_UP ): # adjust LR for each training batch during warm up
warm_up_lr ( batch + 1 , NUM_BATCH_WARM_UP , LR , OPTIMIZER )
# compute output
inputs = inputs . to ( DEVICE )
labels = labels . to ( DEVICE ). long ()
features = BACKBONE ( inputs )
outputs = HEAD ( features , labels )
loss = LOSS ( outputs , labels )
# measure accuracy and record loss
prec1 , prec5 = accuracy ( outputs . data , labels , topk = ( 1 , 5 ))
losses . update ( loss . data . item (), inputs . size ( 0 ))
top1 . update ( prec1 . data . item (), inputs . size ( 0 ))
top5 . update ( prec5 . data . item (), inputs . size ( 0 ))
# compute gradient and do SGD step
OPTIMIZER . zero_grad ()
loss . backward ()
OPTIMIZER . step ()
# dispaly training loss & acc every DISP_FREQ
if (( batch + 1 ) % DISP_FREQ == 0 ) and batch != 0 :
print ( "=" * 60 )
print ( 'Epoch {}/{} Batch {}/{} t '
'Training Loss {loss.val:.4f} ({loss.avg:.4f}) t '
'Training Prec@1 {top1.val:.3f} ({top1.avg:.3f}) t '
'Training Prec@5 {top5.val:.3f} ({top5.avg:.3f})' . format (
epoch + 1 , NUM_EPOCH , batch + 1 , len ( train_loader ) * NUM_EPOCH , loss = losses , top1 = top1 , top5 = top5 ))
print ( "=" * 60 )
batch += 1 # batch index
# training statistics per epoch (buffer for visualization)
epoch_loss = losses . avg
epoch_acc = top1 . avg
writer . add_scalar ( "Training_Loss" , epoch_loss , epoch + 1 )
writer . add_scalar ( "Training_Accuracy" , epoch_acc , epoch + 1 )
print ( "=" * 60 )
print ( 'Epoch: {}/{} t '
'Training Loss {loss.val:.4f} ({loss.avg:.4f}) t '
'Training Prec@1 {top1.val:.3f} ({top1.avg:.3f}) t '
'Training Prec@5 {top5.val:.3f} ({top5.avg:.3f})' . format (
epoch + 1 , NUM_EPOCH , loss = losses , top1 = top1 , top5 = top5 ))
print ( "=" * 60 )
# perform validation & save checkpoints per epoch
# validation statistics per epoch (buffer for visualization)
print ( "=" * 60 )
print ( "Perform Evaluation on LFW, CFP_FF, CFP_FP, AgeDB, CALFW, CPLFW and VGG2_FP, and Save Checkpoints..." )
accuracy_lfw , best_threshold_lfw , roc_curve_lfw = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , lfw , lfw_issame )
buffer_val ( writer , "LFW" , accuracy_lfw , best_threshold_lfw , roc_curve_lfw , epoch + 1 )
accuracy_cfp_ff , best_threshold_cfp_ff , roc_curve_cfp_ff = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , cfp_ff , cfp_ff_issame )
buffer_val ( writer , "CFP_FF" , accuracy_cfp_ff , best_threshold_cfp_ff , roc_curve_cfp_ff , epoch + 1 )
accuracy_cfp_fp , best_threshold_cfp_fp , roc_curve_cfp_fp = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , cfp_fp , cfp_fp_issame )
buffer_val ( writer , "CFP_FP" , accuracy_cfp_fp , best_threshold_cfp_fp , roc_curve_cfp_fp , epoch + 1 )
accuracy_agedb , best_threshold_agedb , roc_curve_agedb = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , agedb , agedb_issame )
buffer_val ( writer , "AgeDB" , accuracy_agedb , best_threshold_agedb , roc_curve_agedb , epoch + 1 )
accuracy_calfw , best_threshold_calfw , roc_curve_calfw = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , calfw , calfw_issame )
buffer_val ( writer , "CALFW" , accuracy_calfw , best_threshold_calfw , roc_curve_calfw , epoch + 1 )
accuracy_cplfw , best_threshold_cplfw , roc_curve_cplfw = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , cplfw , cplfw_issame )
buffer_val ( writer , "CPLFW" , accuracy_cplfw , best_threshold_cplfw , roc_curve_cplfw , epoch + 1 )
accuracy_vgg2_fp , best_threshold_vgg2_fp , roc_curve_vgg2_fp = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , vgg2_fp , vgg2_fp_issame )
buffer_val ( writer , "VGGFace2_FP" , accuracy_vgg2_fp , best_threshold_vgg2_fp , roc_curve_vgg2_fp , epoch + 1 )
print ( "Epoch {}/{}, Evaluation: LFW Acc: {}, CFP_FF Acc: {}, CFP_FP Acc: {}, AgeDB Acc: {}, CALFW Acc: {}, CPLFW Acc: {}, VGG2_FP Acc: {}" . format ( epoch + 1 , NUM_EPOCH , accuracy_lfw , accuracy_cfp_ff , accuracy_cfp_fp , accuracy_agedb , accuracy_calfw , accuracy_cplfw , accuracy_vgg2_fp ))
print ( "=" * 60 )
# save checkpoints per epoch
if MULTI_GPU :
torch . save ( BACKBONE . module . state_dict (), os . path . join ( MODEL_ROOT , "Backbone_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( BACKBONE_NAME , epoch + 1 , batch , get_time ())))
torch . save ( HEAD . state_dict (), os . path . join ( MODEL_ROOT , "Head_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( HEAD_NAME , epoch + 1 , batch , get_time ())))
else :
torch . save ( BACKBONE . state_dict (), os . path . join ( MODEL_ROOT , "Backbone_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( BACKBONE_NAME , epoch + 1 , batch , get_time ())))
torch . save ( HEAD . state_dict (), os . path . join ( MODEL_ROOT , "Head_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( HEAD_NAME , epoch + 1 , batch , get_time ()))) Agora, você pode começar a brincar com o rosto. Evoluir e correr train.py . Informações amigáveis de uso serão exibidas no seu terminal:
Sobre a configuração geral:

Sobre o número de aulas de treinamento:

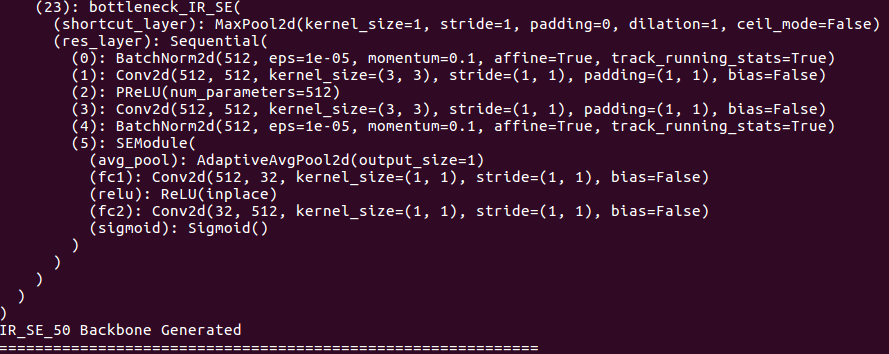
Sobre detalhes da espinha dorsal:
Sobre detalhes da cabeça:

Sobre detalhes de perda:

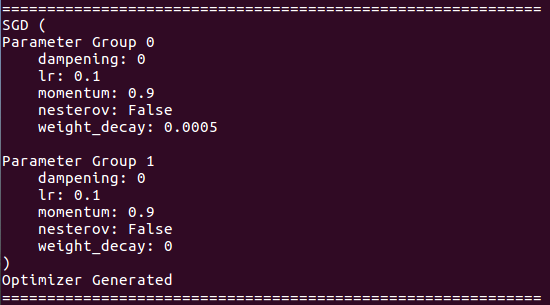
Sobre detalhes do otimizador:
Sobre o treinamento de currículo:

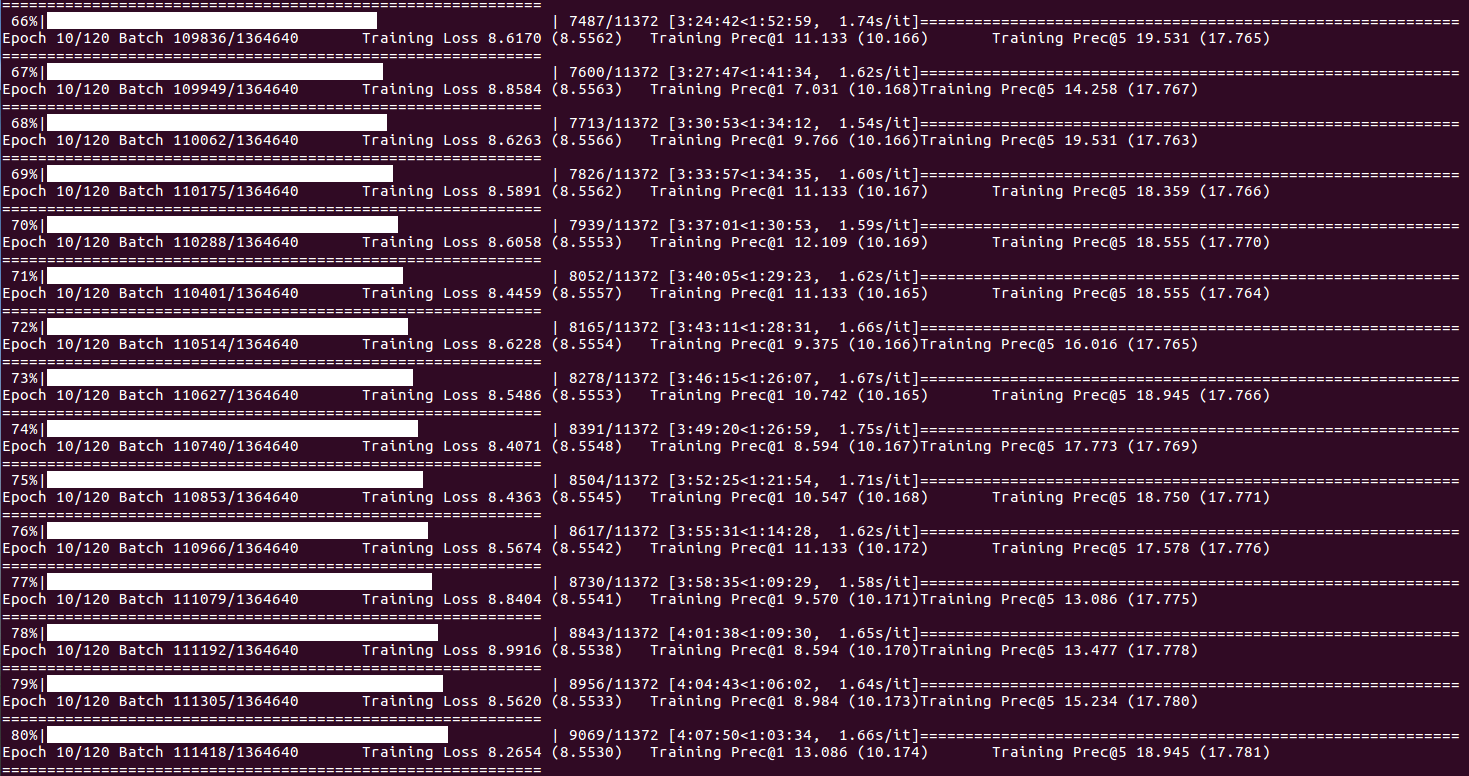
Sobre o status e estatísticas do treinamento (quando o índice de lote atinge DISP_FREQ ou no final de cada época):
Sobre estatísticas de validação e salvar pontos de verificação (no final de cada época):

Monitore a ocupação de GPU on-the-fly com watch -d -n 0.01 nvidia-smi .
Por favor, consulte a Sec. Modelo Zoológico para pesos do modelo específico e desempenho correspondente.
API de extração de recursos (Extrair recursos de modelos pré-treinados) ./util/extract_feature_v1.py (implementado com funções pytorch Build-in) e ./util/extract_feature_v2.py (implementado com OpenCV).
Visualize estatísticas de treinamento e validação com o TensorboardX (consulte o Model Zoo):
tensorboard --logdir /media/pc/6T/jasonjzhao/buffer/log
?
| Banco de dados | Versão | #Identidade | #Imagem | #Quadro | #Vídeo | Baixar link |
|---|---|---|---|---|---|---|
| LFW | Cru | 5.749 | 13.233 | - | - | Google Drive, Baidu Drive |
| LFW | Align_250x250 | 5.749 | 13.233 | - | - | Google Drive, Baidu Drive |
| LFW | Align_112x112 | 5.749 | 13.233 | - | - | Google Drive, Baidu Drive |
| Calfw | Cru | 4.025 | 12.174 | - | - | Google Drive, Baidu Drive |
| Calfw | Align_112x112 | 4.025 | 12.174 | - | - | Google Drive, Baidu Drive |
| CPLFW | Cru | 3.884 | 11.652 | - | - | Google Drive, Baidu Drive |
| CPLFW | Align_112x112 | 3.884 | 11.652 | - | - | Google Drive, Baidu Drive |
| Casia-Webface | RAW_V1 | 10.575 | 494.414 | - | - | Baidu Drive |
| Casia-Webface | RAW_V2 | 10.575 | 494.414 | - | - | Google Drive, Baidu Drive |
| Casia-Webface | Limpar | 10.575 | 455.594 | - | - | Google Drive, Baidu Drive |
| MS-CELEB-1M | Limpar | 100.000 | 5.084.127 | - | - | Google Drive |
| MS-CELEB-1M | Align_112x112 | 85.742 | 5.822.653 | - | - | Google Drive |
| Vggface2 | Limpar | 8.631 | 3.086.894 | - | - | Google Drive |
| Vggface2_fp | Align_112x112 | - | - | - | - | Google Drive, Baidu Drive |
| AGEDB | Cru | 570 | 16.488 | - | - | Google Drive, Baidu Drive |
| AGEDB | Align_112x112 | 570 | 16.488 | - | - | Google Drive, Baidu Drive |
| IJB-A | Limpar | 500 | 5.396 | 20.369 | 2.085 | Google Drive, Baidu Drive |
| IJB-B | Cru | 1.845 | 21.798 | 55.026 | 7.011 | Google Drive |
| CFP | Cru | 500 | 7.000 | - | - | Google Drive, Baidu Drive |
| CFP | Align_112x112 | 500 | 7.000 | - | - | Google Drive, Baidu Drive |
| UMDFaces | Align_112x112 | 8.277 | 367.888 | - | - | Google Drive, Baidu Drive |
| Celeba | Cru | 10.177 | 202.599 | - | - | Google Drive, Baidu Drive |
| CACD-VS | Cru | 2.000 | 163.446 | - | - | Google Drive, Baidu Drive |
| Ytf | Align_344x344 | 1.595 | - | 3.425 | 621.127 | Google Drive, Baidu Drive |
| Deepglint | Align_112x112 | 180.855 | 6.753.545 | - | - | Google Drive |
| Utkface | Align_200x200 | - | 23.708 | - | - | Google Drive, Baidu Drive |
| Buaa-visnir | Align_287x287 | 150 | 5.952 | - | - | Baidu Drive, PW: XMBC |
| Casia nir-vis 2.0 | Align_128x128 | 725 | 17.580 | - | - | Baidu Drive, PW: 883b |
| Oulu-Casia | Cru | 80 | 65.000 | - | - | Baidu Drive, PW: XXP5 |
| Nuaa-impotesterdb | Cru | 15 | 12.614 | - | - | Baidu Drive, PW: IF3N |
| Casia-surf | Cru | 1.000 | - | - | 21.000 | Baidu Drive, PW: IZB3 |
| Casia-Fasd | Cru | 50 | - | - | 600 | Baidu Drive, PW: H5un |
| Casia-Mfsd | Cru | 50 | - | - | 600 | |
| Replay-Ataque | Cru | 50 | - | - | 1.200 | |
| Webface260m | Cru | 24m | 2m | - | https://www.face-benchmark.org/ |
unzip casia-maxpy-clean.zip
cd casia-maxpy-clean
zip -F CASIA-maxpy-clean.zip --out CASIA-maxpy-clean_fix.zip
unzip CASIA-maxpy-clean_fix.zip
import numpy as np
import bcolz
import os
def get_pair ( root , name ):
carray = bcolz . carray ( rootdir = os . path . join ( root , name ), mode = 'r' )
issame = np . load ( '{}/{}_list.npy' . format ( root , name ))
return carray , issame
def get_data ( data_root ):
agedb_30 , agedb_30_issame = get_pair ( data_root , 'agedb_30' )
cfp_fp , cfp_fp_issame = get_pair ( data_root , 'cfp_fp' )
lfw , lfw_issame = get_pair ( data_root , 'lfw' )
vgg2_fp , vgg2_fp_issame = get_pair ( data_root , 'vgg2_fp' )
return agedb_30 , cfp_fp , lfw , vgg2_fp , agedb_30_issame , cfp_fp_issame , lfw_issame , vgg2_fp_issame
agedb_30 , cfp_fp , lfw , vgg2_fp , agedb_30_issame , cfp_fp_issame , lfw_issame , vgg2_fp_issame = get_data ( DATA_ROOT )MS-Celeb-1M_Top1M_MID2Name.tsv (Google Drive, Baidu Drive), VGGface2_ID2Name.csv (Google Drive, Baidu Drive), VGGface2_FaceScrub_Overlap.txt (Google Drive, Baidu Drive), VGGface2_LFW_Overlap.txt (Google Drive, Baidu Drive), CASIA-WebFace_ID2Name.txt (Google Drive, Baidu Drive), CASIA-WebFace_FaceScrub_Overlap.txt (Google Drive, Baidu Drive), CASIA-WebFace_LFW_Overlap.txt (Google Drive, Baidu Drive), FaceScrub_Name.txt (Google Drive, Baidu Drive), LFW_Name.txt (Google Drive, Baidu Drive), LFW_Log.txt (Google Drive, Baidu Drive) para ajudar pesquisadores/engenheiros a remover rapidamente as peças sobrepostas entre seus próprios conjuntos de dados privados e os conjuntos de dados públicos.?
Modelo
| Espinha dorsal | Cabeça | Perda | Dados de treinamento | Baixar link |
|---|---|---|---|---|
| IR-50 | Arcface | Focal | MS-CELEB-1M_ALIGN_112X112 | Google Drive, Baidu Drive |
Contexto
INPUT_SIZE: [112, 112]; RGB_MEAN: [0.5, 0.5, 0.5]; RGB_STD: [0.5, 0.5, 0.5]; BATCH_SIZE: 512 (drop the last batch to ensure consistent batch_norm statistics); Initial LR: 0.1; NUM_EPOCH: 120; WEIGHT_DECAY: 5e-4 (do not apply to batch_norm parameters); MOMENTUM: 0.9; STAGES: [30, 60, 90]; Augmentation: Random Crop + Horizontal Flip; Imbalanced Data Processing: Weighted Random Sampling; Solver: SGD; GPUs: 4 NVIDIA Tesla P40 in Parallel
Estatísticas de treinamento e validação

Desempenho
| LFW | Cfp_ff | CFP_FP | AGEDB | Calfw | CPLFW | Vggface2_fp |
|---|---|---|---|---|---|---|
| 99.78 | 99.69 | 98.14 | 97.53 | 95.87 | 92.45 | 95.22 |
Modelo
| Espinha dorsal | Cabeça | Perda | Dados de treinamento | Baixar link |
|---|---|---|---|---|
| IR-50 | Arcface | Focal | Private Asia Face Data | Google Drive, Baidu Drive |
Contexto
INPUT_SIZE: [112, 112]; RGB_MEAN: [0.5, 0.5, 0.5]; RGB_STD: [0.5, 0.5, 0.5]; BATCH_SIZE: 1024 (drop the last batch to ensure consistent batch_norm statistics); Initial LR: 0.01 (initialize weights from the above model pre-trained on MS-Celeb-1M_Align_112x112); NUM_EPOCH: 80; WEIGHT_DECAY: 5e-4 (do not apply to batch_norm parameters); MOMENTUM: 0.9; STAGES: [20, 40, 60]; Augmentation: Random Crop + Horizontal Flip; Imbalanced Data Processing: Weighted Random Sampling; Solver: SGD; GPUs: 8 NVIDIA Tesla P40 in Parallel
Desempenho (faça uma avaliação em seu próprio conjunto de dados de referência de face da Ásia)
Modelo
| Espinha dorsal | Cabeça | Perda | Dados de treinamento | Baixar link |
|---|---|---|---|---|
| IR-152 | Arcface | Focal | MS-CELEB-1M_ALIGN_112X112 | Baidu Drive, PW: B197 |
Contexto
INPUT_SIZE: [112, 112]; RGB_MEAN: [0.5, 0.5, 0.5]; RGB_STD: [0.5, 0.5, 0.5]; BATCH_SIZE: 256 (drop the last batch to ensure consistent batch_norm statistics); Initial LR: 0.01; NUM_EPOCH: 120; WEIGHT_DECAY: 5e-4 (do not apply to batch_norm parameters); MOMENTUM: 0.9; STAGES: [30, 60, 90]; Augmentation: Random Crop + Horizontal Flip; Imbalanced Data Processing: Weighted Random Sampling; Solver: SGD; GPUs: 4 NVIDIA Geforce RTX 2080 Ti in Parallel
Estatísticas de treinamento e validação

Desempenho
| LFW | Cfp_ff | CFP_FP | AGEDB | Calfw | CPLFW | Vggface2_fp |
|---|---|---|---|---|---|---|
| 99.82 | 99.83 | 98.37 | 98.07 | 96.03 | 93.05 | 95.50 |
?
2017 No.1 no ICCV 2017 MS-CELEB-1M Reconhecimento em larga escala Conjunto duro/conjunto aleatório/desafios de aprendizado de baixo tiro. WeChat News, NUS ECE News, NUS ECE Poster, Certificado de Prêmio para Track-1, Certificado de Prêmio para Track-2, Cerimônia de Prêmio.
2017 No.1 no Instituto Nacional de Padrões e Tecnologia (NIST) IARPA Janus Benchmark A (IJB-A) Desafio de verificação de rosto e desafio de identificação sem restrições. WeChat News.
Desempenho de última geração em
?
?
Consulte e considere citar os seguintes artigos:
@article{wu20223d,
title={3D-Guided Frontal Face Generation for Pose-Invariant Recognition},
author={Wu, Hao and Gu, Jianyang and Fan, Xiaojin and Li, He and Xie, Lidong and Zhao, Jian},
journal={T-IST},
year={2022}
}
@article{wang2021face,
title={Face.evoLVe: A High-Performance Face Recognition Library},
author={Wang, Qingzhong and Zhang, Pengfei and Xiong, Haoyi and Zhao, Jian},
journal={arXiv preprint arXiv:2107.08621},
year={2021}
}
@article{tu2021joint,
title={Joint Face Image Restoration and Frontalization for Recognition},
author={Tu, Xiaoguang and Zhao, Jian and Liu, Qiankun and Ai, Wenjie and Guo, Guodong and Li, Zhifeng and Liu, Wei and Feng, Jiashi},
journal={T-CSVT},
year={2021}
}
@article{zhao2020towards,
title={Towards age-invariant face recognition},
author={Zhao, Jian and Yan, Shuicheng and Feng, Jiashi},
journal={T-PAMI},
year={2020}
}
@article{zhao2019recognizing,
title={Recognizing Profile Faces by Imagining Frontal View},
author={Zhao, Jian and Xing, Junliang and Xiong, Lin and Yan, Shuicheng and Feng, Jiashi},
journal={IJCV},
pages={1--19},
year={2019}
}
@inproceedings{zhao2019multi,
title={Multi-Prototype Networks for Unconstrained Set-based Face Recognition},
author={Zhao, Jian and Li, Jianshu and Tu, Xiaoguang and Zhao, Fang and Xin, Yuan and Xing, Junliang and Liu, Hengzhu and Yan, Shuicheng and Feng, Jiashi},
booktitle={IJCAI},
year={2019}
}
@inproceedings{zhao2019look,
title={Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition},
author={Zhao, Jian and Cheng, Yu and Cheng, Yi and Yang, Yang and Lan, Haochong and Zhao, Fang and Xiong, Lin and Xu, Yan and Li, Jianshu and Pranata, Sugiri and others},
booktitle={AAAI},
year={2019}
}
@article{zhao20183d,
title={3D-Aided Dual-Agent GANs for Unconstrained Face Recognition},
author={Zhao, Jian and Xiong, Lin and Li, Jianshu and Xing, Junliang and Yan, Shuicheng and Feng, Jiashi},
journal={T-PAMI},
year={2018}
}
@inproceedings{zhao2018towards,
title={Towards Pose Invariant Face Recognition in the Wild},
author={Zhao, Jian and Cheng, Yu and Xu, Yan and Xiong, Lin and Li, Jianshu and Zhao, Fang and Jayashree, Karlekar and Pranata, Sugiri and Shen, Shengmei and Xing, Junliang and others},
booktitle={CVPR},
pages={2207--2216},
year={2018}
}
@inproceedings{zhao3d,
title={3D-Aided Deep Pose-Invariant Face Recognition},
author={Zhao, Jian and Xiong, Lin and Cheng, Yu and Cheng, Yi and Li, Jianshu and Zhou, Li and Xu, Yan and Karlekar, Jayashree and Pranata, Sugiri and Shen, Shengmei and others},
booktitle={IJCAI},
pages={1184--1190},
year={2018}
}
@inproceedings{zhao2018dynamic,
title={Dynamic Conditional Networks for Few-Shot Learning},
author={Zhao, Fang and Zhao, Jian and Yan, Shuicheng and Feng, Jiashi},
booktitle={ECCV},
pages={19--35},
year={2018}
}
@inproceedings{zhao2017dual,
title={Dual-agent gans for photorealistic and identity preserving profile face synthesis},
author={Zhao, Jian and Xiong, Lin and Jayashree, Panasonic Karlekar and Li, Jianshu and Zhao, Fang and Wang, Zhecan and Pranata, Panasonic Sugiri and Shen, Panasonic Shengmei and Yan, Shuicheng and Feng, Jiashi},
booktitle={NeurIPS},
pages={66--76},
year={2017}
}
@inproceedings{zhao122017marginalized,
title={Marginalized cnn: Learning deep invariant representations},
author={Zhao12, Jian and Li, Jianshu and Zhao, Fang and Yan13, Shuicheng and Feng, Jiashi},
booktitle={BMVC},
year={2017}
}
@inproceedings{cheng2017know,
title={Know you at one glance: A compact vector representation for low-shot learning},
author={Cheng, Yu and Zhao, Jian and Wang, Zhecan and Xu, Yan and Jayashree, Karlekar and Shen, Shengmei and Feng, Jiashi},
booktitle={ICCVW},
pages={1924--1932},
year={2017}
}
@inproceedings{wangconditional,
title={Conditional Dual-Agent GANs for Photorealistic and Annotation Preserving Image Synthesis},
author={Wang, Zhecan and Zhao, Jian and Cheng, Yu and Xiao, Shengtao and Li, Jianshu and Zhao, Fang and Feng, Jiashi and Kassim, Ashraf},
booktitle={BMVCW},
}


