face.evoLVe
1.0.0
| 작가 | 지안 자오 |
|---|---|
| 홈페이지 | https://zhaoj9014.github.io |
Code of Face.evolve는 MIT 라이센스에 따라 릴리스됩니다.
✅ CLOSED 02 September 2021 : Baidu Paddlepaddle은 공식적으로 Face를 합병했습니다. 얼굴 관련 분석에 대한 연구 및 응용 프로그램을 촉진하기 위해 노력했습니다 (공식 발표).
CLOSED 03 July 2021 . PaddlePaddle 프레임 워크에 대한 교육 코드를 제공합니다.
✅ CLOSED 04 July 2019 : 우리는 관련 연구 및 분석을 용이하게하기 위해 Face Anti-Spoofing/Livenity Detection에서 공개적으로 이용 가능한 몇 가지 데이터 세트를 공유 할 것입니다.
✅ CLOSED 07 June 2019 : 우리는 MS-CELEB-1M_ALIGN_112X112에서 더 나은 성능 IR-152 모델을 교육하고 있으며 곧 모델을 출시 할 예정입니다.
✅ CLOSED 23 May 2019 : 우리는 이종 얼굴 인식 및 분석에 대한 연구를 용이하게하기 위해 공개적으로 이용 가능한 세 가지 데이터 세트를 공유합니다. SEC를 참조하십시오. 자세한 내용은 데이터 동물원입니다.
✅ CLOSED 23 Jan 2019 : 우리는 연구자/엔지니어가 자신의 개인 데이터 세트와 공개 데이터 세트 사이의 겹치는 부분을 빠르게 제거 할 수 있도록 널리 사용되는 몇 가지 얼굴 인식 데이터 세트의 이름 목록과 쌍별 중첩 목록을 공유합니다. SEC를 참조하십시오. 자세한 내용은 데이터 동물원입니다.
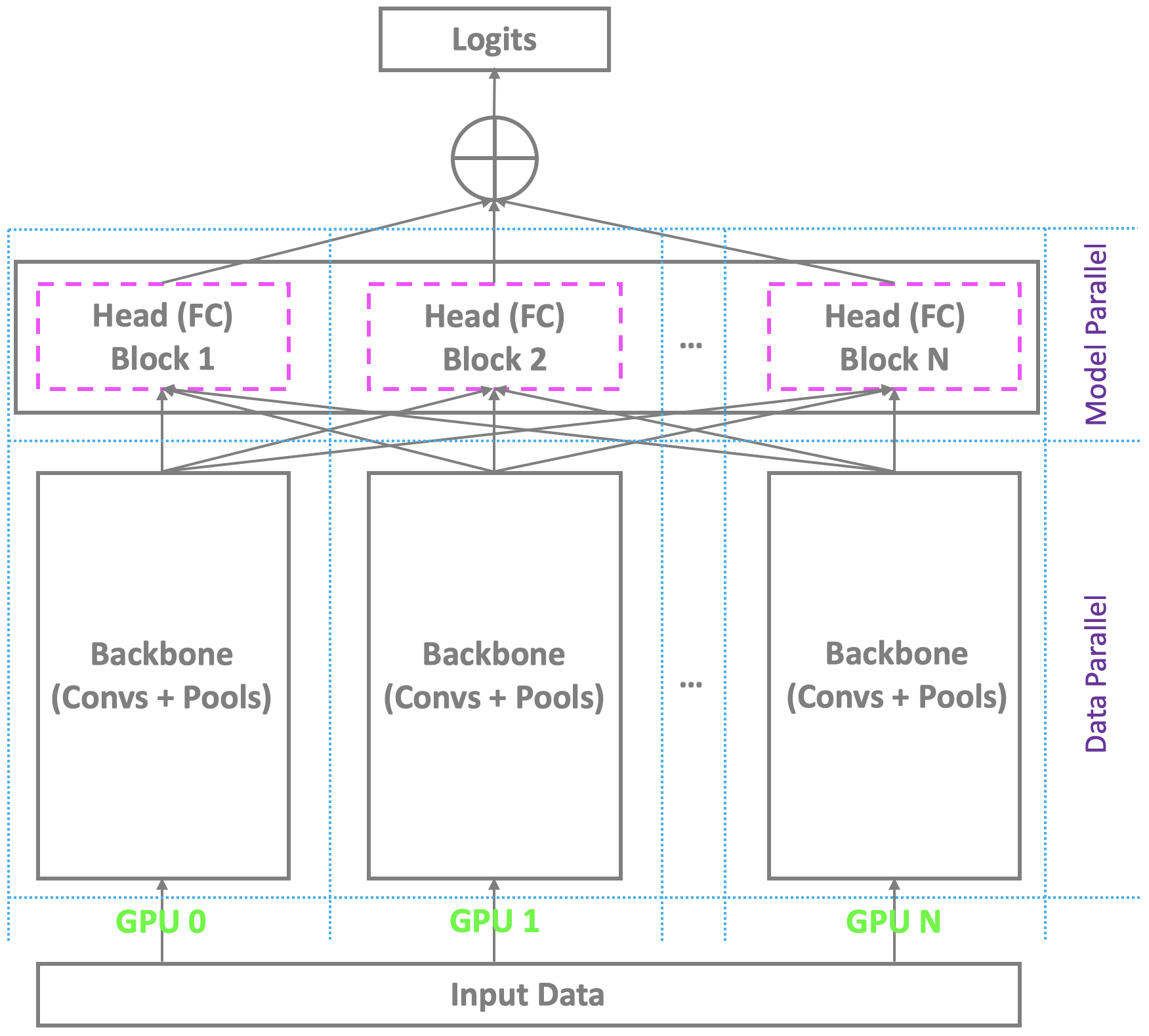
✅ CLOSED 23 Jan 2019 : Pytorch 및 기타 주류 플랫폼 하에서 멀티 Gpus를 갖춘 현재 분산 교육 스키마는 단일 마스터를 사용하는 동시에 백본과 유사하며 최종 병목 현상 (완전 연결/SoftMax) 레이어를 계산합니다. 이것은 적당한 수의 정체성을 가진 기존의 얼굴 인식에 문제가되지 않습니다. 그러나 그것은 대규모 얼굴 인식으로 어려움을 겪고 있으며, 이는 실제 세계에서 수백만의 정체성을 인정해야합니다. 마스터는 대형 최종 계층을 거의 보유 할 수는 없지만 노예는 여전히 중복 계산 자원을 가지고있어 소규모 배치 훈련 또는 훈련에 실패했습니다. 이 문제를 해결하기 위해, 우리는 Pytorch 하의 멀티 Gpus를 사용하여 우수하고 효과적이고 효율적인 분산 교육 스키마를 개발하여 백본뿐만 아니라 완전히 연결된 (SoftMax) 층이있는 헤드를 지원하여 고성능 대규모 대규모 얼굴 인식을 용이하게합니다. 우리는이 지원을 저장소에 추가 할 것입니다.
✅ CLOSED 22 Jan 2019 : Pytorch 빌드 인 기능 및 OpenCV와 함께 각각 구현 된 미리 훈련 된 모델에서 기능을 추출하기위한 두 가지 기능 추출 API를 출시했습니다. ./util/extract_feature_v1.py 및 ./util/extract_feature_v2.py 를 확인하십시오.
✅ CLOSED 22 Jan 2019 : 우리는 프라이빗 아시아 얼굴 데이터에 대해 출시 된 IR-50 모델을 미세 조정하고 있으며, 이는 고성능 아시아 얼굴 인식을 촉진하기 위해 곧 출시 될 예정입니다.
✅ CLOSED 21 Jan 2019 : 우리는 MS-Celeb-1M_ALIGN_112X112에서 더 나은 성능 IR-50 모델을 훈련시키고 있으며 곧 현재 모델을 대체 할 것입니다.
?

?
pip install torch torchvision 설치)pip install mxnet-cu90 )pip install tensorflow-gpu )pip install tensorboardX )pip install opencv-python )pip install bcolz )필수는 아니지만 최적의 성능을 위해 CUDA 활성화 GPU를 사용하여 코드를 실행하는 것이 좋습니다 . 우리는 4-8 NVIDIA TESLA P40을 병렬로 사용했습니다.
?
git clone https://github.com/ZhaoJ9014/face.evoLVe.PyTorch.git .mkdir data checkpoint log . ./data/db_name/
-> id1/
-> 1.jpg
-> ...
-> id2/
-> 1.jpg
-> ...
-> ...
-> ...
-> ...
?


./align from PIL import Image
from detector import detect_faces
from visualization_utils import show_results
img = Image . open ( 'some_img.jpg' ) # modify the image path to yours
bounding_boxes , landmarks = detect_faces ( img ) # detect bboxes and landmarks for all faces in the image
show_results ( img , bounding_boxes , landmarks ) # visualize the resultssource_root 에서 얼굴 감지, 획기적인 현지화 및 Affine 변환과의 정렬을 수행하고 정렬 된 결과를 동일한 디렉토리 구조를 가진 새 폴더 dest_root 에 저장하십시오. python face_align.py -source_root [source_root] -dest_root [dest_root] -crop_size [crop_size]
# python face_align.py -source_root './data/test' -dest_root './data/test_Aligned' -crop_size 112
*.DS_Store 파일에 대해 걱정할 필요가 없습니다.source_root , dest_root 및 crop_size 의 인수를 face_align.py 실행할 때 자신의 값으로 지정합니다. 2) 사용자 정의 된 min_face_size , thresholds 및 nms_thresholds 값을 detect_faces 의 기능으로 전달하여 실제 요구 사항 detector.py 맞게 전달하십시오. 3) Face API를 사용하여 속도가 약간 느리면 Face API를 호출하기 전에 Face API를 호출하여 먼저 작은 크기가 임계 값보다 큰 이미지를 조정하여 ( source_root , dest_root 및 min_side 의 인수를 자신의 값으로 지정) : Face API를 호출 할 수 있습니다. python face_resize.py
./balanceroot 에서 min_num 샘플이 적은 로우 샷 클래스를 제거하십시오) : python remove_lowshot.py -root [root] -min_num [min_num]
# python remove_lowshot.py -root './data/train' -min_num 10
remove_lowshot.py 실행할 때 root 및 min_num 의 인수를 자신의 값에 지정하십시오.☕
폴더 : ./
구성 API (교육 및 유효성 검사를위한 전체 설정 구성) config.py :
import torch
configurations = {
1 : dict (
SEED = 1337 , # random seed for reproduce results
DATA_ROOT = '/media/pc/6T/jasonjzhao/data/faces_emore' , # the parent root where your train/val/test data are stored
MODEL_ROOT = '/media/pc/6T/jasonjzhao/buffer/model' , # the root to buffer your checkpoints
LOG_ROOT = '/media/pc/6T/jasonjzhao/buffer/log' , # the root to log your train/val status
BACKBONE_RESUME_ROOT = './' , # the root to resume training from a saved checkpoint
HEAD_RESUME_ROOT = './' , # the root to resume training from a saved checkpoint
BACKBONE_NAME = 'IR_SE_50' , # support: ['ResNet_50', 'ResNet_101', 'ResNet_152', 'IR_50', 'IR_101', 'IR_152', 'IR_SE_50', 'IR_SE_101', 'IR_SE_152']
HEAD_NAME = 'ArcFace' , # support: ['Softmax', 'ArcFace', 'CosFace', 'SphereFace', 'Am_softmax']
LOSS_NAME = 'Focal' , # support: ['Focal', 'Softmax']
INPUT_SIZE = [ 112 , 112 ], # support: [112, 112] and [224, 224]
RGB_MEAN = [ 0.5 , 0.5 , 0.5 ], # for normalize inputs to [-1, 1]
RGB_STD = [ 0.5 , 0.5 , 0.5 ],
EMBEDDING_SIZE = 512 , # feature dimension
BATCH_SIZE = 512 ,
DROP_LAST = True , # whether drop the last batch to ensure consistent batch_norm statistics
LR = 0.1 , # initial LR
NUM_EPOCH = 125 , # total epoch number (use the firt 1/25 epochs to warm up)
WEIGHT_DECAY = 5e-4 , # do not apply to batch_norm parameters
MOMENTUM = 0.9 ,
STAGES = [ 35 , 65 , 95 ], # epoch stages to decay learning rate
DEVICE = torch . device ( "cuda:0" if torch . cuda . is_available () else "cpu" ),
MULTI_GPU = True , # flag to use multiple GPUs; if you choose to train with single GPU, you should first run "export CUDA_VISILE_DEVICES=device_id" to specify the GPU card you want to use
GPU_ID = [ 0 , 1 , 2 , 3 ], # specify your GPU ids
PIN_MEMORY = True ,
NUM_WORKERS = 0 ,
),
} Train & Validation API (교육 및 검증, 즉 수입 패키지, 하이퍼 파라미터 및 데이터 로더, 모델 및 손실 및 최적화기, Train & Validation & Save Checkpoint) train.py 에 관한 모든 사람들. MS-CELEB-1M은 얼굴 인식 제출에서 이미지 인 역할을하기 때문에 Face를 사전 훈련시킵니다. MS-Celeb-1M에서 모델을 evolven 고 LFW, CFP_FF, CFP_FP, AGEDB, CALFW, CPLFW 및 VGGFACE2_FP에서 검증을 수행합니다. 세부 사항을 함께 단계별로 다이빙합시다.
import torch
import torch . nn as nn
import torch . optim as optim
import torchvision . transforms as transforms
import torchvision . datasets as datasets
from config import configurations
from backbone . model_resnet import ResNet_50 , ResNet_101 , ResNet_152
from backbone . model_irse import IR_50 , IR_101 , IR_152 , IR_SE_50 , IR_SE_101 , IR_SE_152
from head . metrics import ArcFace , CosFace , SphereFace , Am_softmax
from loss . focal import FocalLoss
from util . utils import make_weights_for_balanced_classes , get_val_data , separate_irse_bn_paras , separate_resnet_bn_paras , warm_up_lr , schedule_lr , perform_val , get_time , buffer_val , AverageMeter , accuracy
from tensorboardX import SummaryWriter
from tqdm import tqdm
import os cfg = configurations [ 1 ]
SEED = cfg [ 'SEED' ] # random seed for reproduce results
torch . manual_seed ( SEED )
DATA_ROOT = cfg [ 'DATA_ROOT' ] # the parent root where your train/val/test data are stored
MODEL_ROOT = cfg [ 'MODEL_ROOT' ] # the root to buffer your checkpoints
LOG_ROOT = cfg [ 'LOG_ROOT' ] # the root to log your train/val status
BACKBONE_RESUME_ROOT = cfg [ 'BACKBONE_RESUME_ROOT' ] # the root to resume training from a saved checkpoint
HEAD_RESUME_ROOT = cfg [ 'HEAD_RESUME_ROOT' ] # the root to resume training from a saved checkpoint
BACKBONE_NAME = cfg [ 'BACKBONE_NAME' ] # support: ['ResNet_50', 'ResNet_101', 'ResNet_152', 'IR_50', 'IR_101', 'IR_152', 'IR_SE_50', 'IR_SE_101', 'IR_SE_152']
HEAD_NAME = cfg [ 'HEAD_NAME' ] # support: ['Softmax', 'ArcFace', 'CosFace', 'SphereFace', 'Am_softmax']
LOSS_NAME = cfg [ 'LOSS_NAME' ] # support: ['Focal', 'Softmax']
INPUT_SIZE = cfg [ 'INPUT_SIZE' ]
RGB_MEAN = cfg [ 'RGB_MEAN' ] # for normalize inputs
RGB_STD = cfg [ 'RGB_STD' ]
EMBEDDING_SIZE = cfg [ 'EMBEDDING_SIZE' ] # feature dimension
BATCH_SIZE = cfg [ 'BATCH_SIZE' ]
DROP_LAST = cfg [ 'DROP_LAST' ] # whether drop the last batch to ensure consistent batch_norm statistics
LR = cfg [ 'LR' ] # initial LR
NUM_EPOCH = cfg [ 'NUM_EPOCH' ]
WEIGHT_DECAY = cfg [ 'WEIGHT_DECAY' ]
MOMENTUM = cfg [ 'MOMENTUM' ]
STAGES = cfg [ 'STAGES' ] # epoch stages to decay learning rate
DEVICE = cfg [ 'DEVICE' ]
MULTI_GPU = cfg [ 'MULTI_GPU' ] # flag to use multiple GPUs
GPU_ID = cfg [ 'GPU_ID' ] # specify your GPU ids
PIN_MEMORY = cfg [ 'PIN_MEMORY' ]
NUM_WORKERS = cfg [ 'NUM_WORKERS' ]
print ( "=" * 60 )
print ( "Overall Configurations:" )
print ( cfg )
print ( "=" * 60 )
writer = SummaryWriter ( LOG_ROOT ) # writer for buffering intermedium results train_transform = transforms . Compose ([ # refer to https://pytorch.org/docs/stable/torchvision/transforms.html for more build-in online data augmentation
transforms . Resize ([ int ( 128 * INPUT_SIZE [ 0 ] / 112 ), int ( 128 * INPUT_SIZE [ 0 ] / 112 )]), # smaller side resized
transforms . RandomCrop ([ INPUT_SIZE [ 0 ], INPUT_SIZE [ 1 ]]),
transforms . RandomHorizontalFlip (),
transforms . ToTensor (),
transforms . Normalize ( mean = RGB_MEAN ,
std = RGB_STD ),
])
dataset_train = datasets . ImageFolder ( os . path . join ( DATA_ROOT , 'imgs' ), train_transform )
# create a weighted random sampler to process imbalanced data
weights = make_weights_for_balanced_classes ( dataset_train . imgs , len ( dataset_train . classes ))
weights = torch . DoubleTensor ( weights )
sampler = torch . utils . data . sampler . WeightedRandomSampler ( weights , len ( weights ))
train_loader = torch . utils . data . DataLoader (
dataset_train , batch_size = BATCH_SIZE , sampler = sampler , pin_memory = PIN_MEMORY ,
num_workers = NUM_WORKERS , drop_last = DROP_LAST
)
NUM_CLASS = len ( train_loader . dataset . classes )
print ( "Number of Training Classes: {}" . format ( NUM_CLASS ))
lfw , cfp_ff , cfp_fp , agedb , calfw , cplfw , vgg2_fp , lfw_issame , cfp_ff_issame , cfp_fp_issame , agedb_issame , calfw_issame , cplfw_issame , vgg2_fp_issame = get_val_data ( DATA_ROOT ) BACKBONE_DICT = { 'ResNet_50' : ResNet_50 ( INPUT_SIZE ),
'ResNet_101' : ResNet_101 ( INPUT_SIZE ),
'ResNet_152' : ResNet_152 ( INPUT_SIZE ),
'IR_50' : IR_50 ( INPUT_SIZE ),
'IR_101' : IR_101 ( INPUT_SIZE ),
'IR_152' : IR_152 ( INPUT_SIZE ),
'IR_SE_50' : IR_SE_50 ( INPUT_SIZE ),
'IR_SE_101' : IR_SE_101 ( INPUT_SIZE ),
'IR_SE_152' : IR_SE_152 ( INPUT_SIZE )}
BACKBONE = BACKBONE_DICT [ BACKBONE_NAME ]
print ( "=" * 60 )
print ( BACKBONE )
print ( "{} Backbone Generated" . format ( BACKBONE_NAME ))
print ( "=" * 60 )
HEAD_DICT = { 'ArcFace' : ArcFace ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID ),
'CosFace' : CosFace ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID ),
'SphereFace' : SphereFace ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID ),
'Am_softmax' : Am_softmax ( in_features = EMBEDDING_SIZE , out_features = NUM_CLASS , device_id = GPU_ID )}
HEAD = HEAD_DICT [ HEAD_NAME ]
print ( "=" * 60 )
print ( HEAD )
print ( "{} Head Generated" . format ( HEAD_NAME ))
print ( "=" * 60 ) LOSS_DICT = { 'Focal' : FocalLoss (),
'Softmax' : nn . CrossEntropyLoss ()}
LOSS = LOSS_DICT [ LOSS_NAME ]
print ( "=" * 60 )
print ( LOSS )
print ( "{} Loss Generated" . format ( LOSS_NAME ))
print ( "=" * 60 ) if BACKBONE_NAME . find ( "IR" ) >= 0 :
backbone_paras_only_bn , backbone_paras_wo_bn = separate_irse_bn_paras ( BACKBONE ) # separate batch_norm parameters from others; do not do weight decay for batch_norm parameters to improve the generalizability
_ , head_paras_wo_bn = separate_irse_bn_paras ( HEAD )
else :
backbone_paras_only_bn , backbone_paras_wo_bn = separate_resnet_bn_paras ( BACKBONE ) # separate batch_norm parameters from others; do not do weight decay for batch_norm parameters to improve the generalizability
_ , head_paras_wo_bn = separate_resnet_bn_paras ( HEAD )
OPTIMIZER = optim . SGD ([{ 'params' : backbone_paras_wo_bn + head_paras_wo_bn , 'weight_decay' : WEIGHT_DECAY }, { 'params' : backbone_paras_only_bn }], lr = LR , momentum = MOMENTUM )
print ( "=" * 60 )
print ( OPTIMIZER )
print ( "Optimizer Generated" )
print ( "=" * 60 ) if BACKBONE_RESUME_ROOT and HEAD_RESUME_ROOT :
print ( "=" * 60 )
if os . path . isfile ( BACKBONE_RESUME_ROOT ) and os . path . isfile ( HEAD_RESUME_ROOT ):
print ( "Loading Backbone Checkpoint '{}'" . format ( BACKBONE_RESUME_ROOT ))
BACKBONE . load_state_dict ( torch . load ( BACKBONE_RESUME_ROOT ))
print ( "Loading Head Checkpoint '{}'" . format ( HEAD_RESUME_ROOT ))
HEAD . load_state_dict ( torch . load ( HEAD_RESUME_ROOT ))
else :
print ( "No Checkpoint Found at '{}' and '{}'. Please Have a Check or Continue to Train from Scratch" . format ( BACKBONE_RESUME_ROOT , HEAD_RESUME_ROOT ))
print ( "=" * 60 ) if MULTI_GPU :
# multi-GPU setting
BACKBONE = nn . DataParallel ( BACKBONE , device_ids = GPU_ID )
BACKBONE = BACKBONE . to ( DEVICE )
else :
# single-GPU setting
BACKBONE = BACKBONE . to ( DEVICE ) DISP_FREQ = len ( train_loader ) // 100 # frequency to display training loss & acc
NUM_EPOCH_WARM_UP = NUM_EPOCH // 25 # use the first 1/25 epochs to warm up
NUM_BATCH_WARM_UP = len ( train_loader ) * NUM_EPOCH_WARM_UP # use the first 1/25 epochs to warm up
batch = 0 # batch index for epoch in range ( NUM_EPOCH ): # start training process
if epoch == STAGES [ 0 ]: # adjust LR for each training stage after warm up, you can also choose to adjust LR manually (with slight modification) once plaueau observed
schedule_lr ( OPTIMIZER )
if epoch == STAGES [ 1 ]:
schedule_lr ( OPTIMIZER )
if epoch == STAGES [ 2 ]:
schedule_lr ( OPTIMIZER )
BACKBONE . train () # set to training mode
HEAD . train ()
losses = AverageMeter ()
top1 = AverageMeter ()
top5 = AverageMeter ()
for inputs , labels in tqdm ( iter ( train_loader )):
if ( epoch + 1 <= NUM_EPOCH_WARM_UP ) and ( batch + 1 <= NUM_BATCH_WARM_UP ): # adjust LR for each training batch during warm up
warm_up_lr ( batch + 1 , NUM_BATCH_WARM_UP , LR , OPTIMIZER )
# compute output
inputs = inputs . to ( DEVICE )
labels = labels . to ( DEVICE ). long ()
features = BACKBONE ( inputs )
outputs = HEAD ( features , labels )
loss = LOSS ( outputs , labels )
# measure accuracy and record loss
prec1 , prec5 = accuracy ( outputs . data , labels , topk = ( 1 , 5 ))
losses . update ( loss . data . item (), inputs . size ( 0 ))
top1 . update ( prec1 . data . item (), inputs . size ( 0 ))
top5 . update ( prec5 . data . item (), inputs . size ( 0 ))
# compute gradient and do SGD step
OPTIMIZER . zero_grad ()
loss . backward ()
OPTIMIZER . step ()
# dispaly training loss & acc every DISP_FREQ
if (( batch + 1 ) % DISP_FREQ == 0 ) and batch != 0 :
print ( "=" * 60 )
print ( 'Epoch {}/{} Batch {}/{} t '
'Training Loss {loss.val:.4f} ({loss.avg:.4f}) t '
'Training Prec@1 {top1.val:.3f} ({top1.avg:.3f}) t '
'Training Prec@5 {top5.val:.3f} ({top5.avg:.3f})' . format (
epoch + 1 , NUM_EPOCH , batch + 1 , len ( train_loader ) * NUM_EPOCH , loss = losses , top1 = top1 , top5 = top5 ))
print ( "=" * 60 )
batch += 1 # batch index
# training statistics per epoch (buffer for visualization)
epoch_loss = losses . avg
epoch_acc = top1 . avg
writer . add_scalar ( "Training_Loss" , epoch_loss , epoch + 1 )
writer . add_scalar ( "Training_Accuracy" , epoch_acc , epoch + 1 )
print ( "=" * 60 )
print ( 'Epoch: {}/{} t '
'Training Loss {loss.val:.4f} ({loss.avg:.4f}) t '
'Training Prec@1 {top1.val:.3f} ({top1.avg:.3f}) t '
'Training Prec@5 {top5.val:.3f} ({top5.avg:.3f})' . format (
epoch + 1 , NUM_EPOCH , loss = losses , top1 = top1 , top5 = top5 ))
print ( "=" * 60 )
# perform validation & save checkpoints per epoch
# validation statistics per epoch (buffer for visualization)
print ( "=" * 60 )
print ( "Perform Evaluation on LFW, CFP_FF, CFP_FP, AgeDB, CALFW, CPLFW and VGG2_FP, and Save Checkpoints..." )
accuracy_lfw , best_threshold_lfw , roc_curve_lfw = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , lfw , lfw_issame )
buffer_val ( writer , "LFW" , accuracy_lfw , best_threshold_lfw , roc_curve_lfw , epoch + 1 )
accuracy_cfp_ff , best_threshold_cfp_ff , roc_curve_cfp_ff = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , cfp_ff , cfp_ff_issame )
buffer_val ( writer , "CFP_FF" , accuracy_cfp_ff , best_threshold_cfp_ff , roc_curve_cfp_ff , epoch + 1 )
accuracy_cfp_fp , best_threshold_cfp_fp , roc_curve_cfp_fp = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , cfp_fp , cfp_fp_issame )
buffer_val ( writer , "CFP_FP" , accuracy_cfp_fp , best_threshold_cfp_fp , roc_curve_cfp_fp , epoch + 1 )
accuracy_agedb , best_threshold_agedb , roc_curve_agedb = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , agedb , agedb_issame )
buffer_val ( writer , "AgeDB" , accuracy_agedb , best_threshold_agedb , roc_curve_agedb , epoch + 1 )
accuracy_calfw , best_threshold_calfw , roc_curve_calfw = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , calfw , calfw_issame )
buffer_val ( writer , "CALFW" , accuracy_calfw , best_threshold_calfw , roc_curve_calfw , epoch + 1 )
accuracy_cplfw , best_threshold_cplfw , roc_curve_cplfw = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , cplfw , cplfw_issame )
buffer_val ( writer , "CPLFW" , accuracy_cplfw , best_threshold_cplfw , roc_curve_cplfw , epoch + 1 )
accuracy_vgg2_fp , best_threshold_vgg2_fp , roc_curve_vgg2_fp = perform_val ( MULTI_GPU , DEVICE , EMBEDDING_SIZE , BATCH_SIZE , BACKBONE , vgg2_fp , vgg2_fp_issame )
buffer_val ( writer , "VGGFace2_FP" , accuracy_vgg2_fp , best_threshold_vgg2_fp , roc_curve_vgg2_fp , epoch + 1 )
print ( "Epoch {}/{}, Evaluation: LFW Acc: {}, CFP_FF Acc: {}, CFP_FP Acc: {}, AgeDB Acc: {}, CALFW Acc: {}, CPLFW Acc: {}, VGG2_FP Acc: {}" . format ( epoch + 1 , NUM_EPOCH , accuracy_lfw , accuracy_cfp_ff , accuracy_cfp_fp , accuracy_agedb , accuracy_calfw , accuracy_cplfw , accuracy_vgg2_fp ))
print ( "=" * 60 )
# save checkpoints per epoch
if MULTI_GPU :
torch . save ( BACKBONE . module . state_dict (), os . path . join ( MODEL_ROOT , "Backbone_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( BACKBONE_NAME , epoch + 1 , batch , get_time ())))
torch . save ( HEAD . state_dict (), os . path . join ( MODEL_ROOT , "Head_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( HEAD_NAME , epoch + 1 , batch , get_time ())))
else :
torch . save ( BACKBONE . state_dict (), os . path . join ( MODEL_ROOT , "Backbone_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( BACKBONE_NAME , epoch + 1 , batch , get_time ())))
torch . save ( HEAD . state_dict (), os . path . join ( MODEL_ROOT , "Head_{}_Epoch_{}_Batch_{}_Time_{}_checkpoint.pth" . format ( HEAD_NAME , epoch + 1 , batch , get_time ()))) 이제 얼굴을 가지고 놀기 시작할 수 있습니다 train.py 사용자 친화적 인 정보는 터미널에서 튀어 나옵니다.
전체 구성 정보 :

교육 수업의 수 :

백본 세부 사항에 대해 :
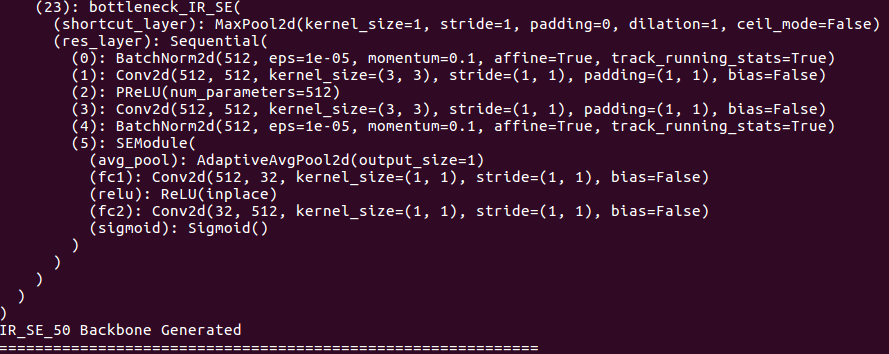
헤드 세부 사항에 대해 :

손실 세부 사항에 대해 :

최적화 세부 사항에 대해 :
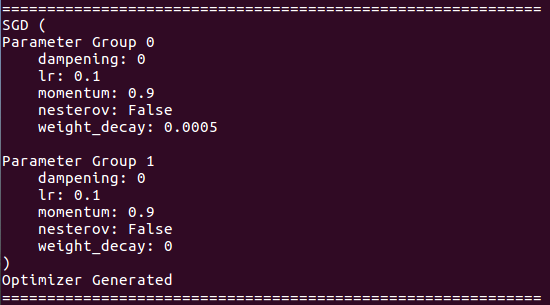
이력서 교육 정보 :

교육 상태 및 통계 정보 (배치 인덱스에 도달 할 때 DISP_FREQ 도달하거나 각 시대의 끝에) :
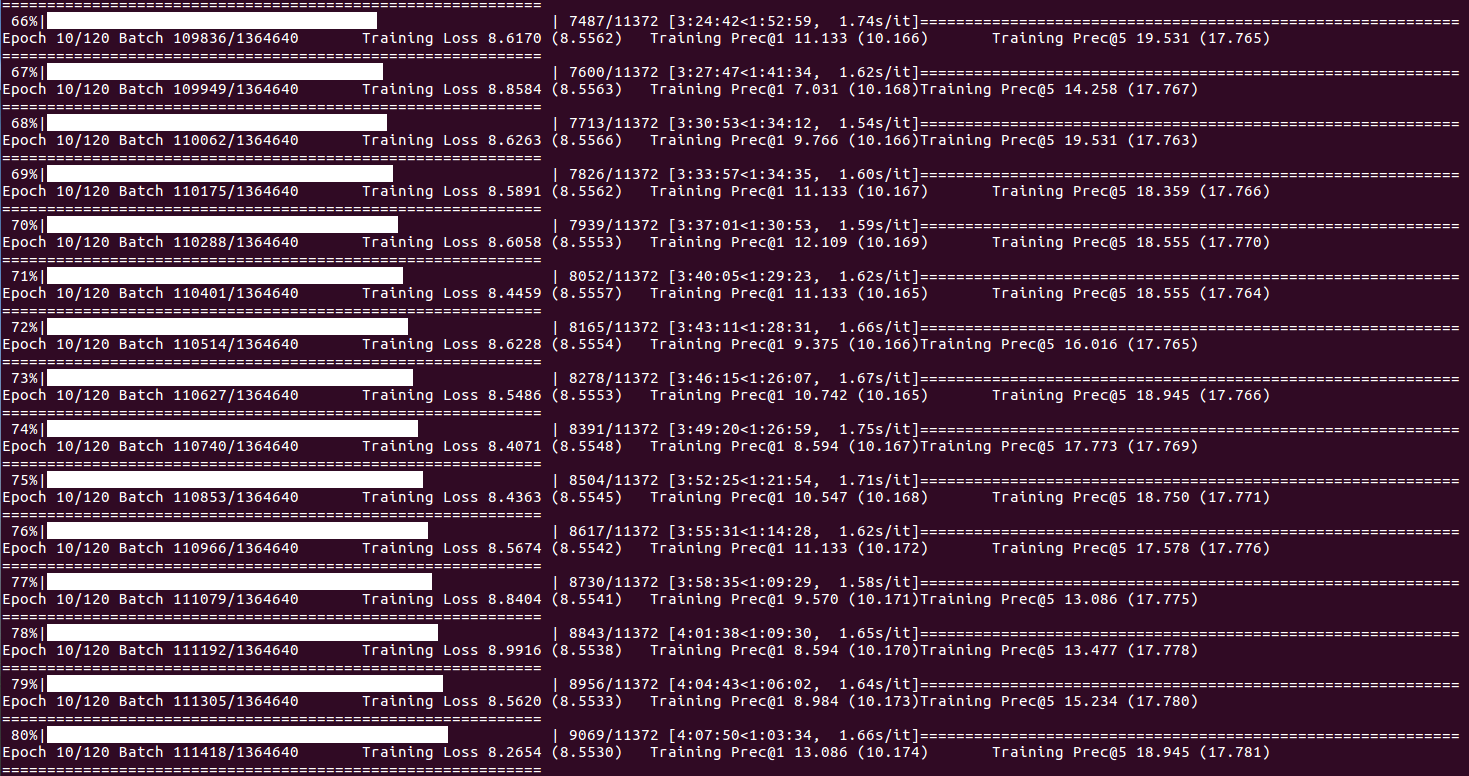
유효성 검사 통계 및 체크 포인트 저장 (각 시대의 끝에서) :

watch -d -n 0.01 nvidia-smi 사용하여 온실 GPU 점유를 모니터링하십시오.
SEC를 참조하십시오. 특정 모델 가중치 및 해당 성능에 대한 모델 동물원.
기능 추출 API (사전 훈련 된 모델에서 추출 기능) ./util/extract_feature_v1.py (Pytorch 빌드 인 함수로 구현 됨) 및 ./util/extract_feature_v2.py (OpenCV와 함께 구현).
Tensorboardx를 사용하여 교육 및 유효성 검사 통계 시각화 (Sec. Model Zoo 참조) :
tensorboard --logdir /media/pc/6T/jasonjzhao/buffer/log
?
| 데이터 베이스 | 버전 | #신원 | #영상 | #액자 | #동영상 | 링크 다운로드 |
|---|---|---|---|---|---|---|
| LFW | 날것의 | 5,749 | 13,233 | - | - | Google Drive, Baidu Drive |
| LFW | align_250x250 | 5,749 | 13,233 | - | - | Google Drive, Baidu Drive |
| LFW | align_112x112 | 5,749 | 13,233 | - | - | Google Drive, Baidu Drive |
| calfw | 날것의 | 4,025 | 12,174 | - | - | Google Drive, Baidu Drive |
| calfw | align_112x112 | 4,025 | 12,174 | - | - | Google Drive, Baidu Drive |
| cplfw | 날것의 | 3,884 | 11,652 | - | - | Google Drive, Baidu Drive |
| cplfw | align_112x112 | 3,884 | 11,652 | - | - | Google Drive, Baidu Drive |
| Casia-Webface | raw_v1 | 10,575 | 494,414 | - | - | 바이두 드라이브 |
| Casia-Webface | raw_v2 | 10,575 | 494,414 | - | - | Google Drive, Baidu Drive |
| Casia-Webface | 깨끗한 | 10,575 | 455,594 | - | - | Google Drive, Baidu Drive |
| MS-CELEB-1M | 깨끗한 | 100,000 | 5,084,127 | - | - | 구글 드라이브 |
| MS-CELEB-1M | align_112x112 | 85,742 | 5,822,653 | - | - | 구글 드라이브 |
| vggface2 | 깨끗한 | 8,631 | 3,086,894 | - | - | 구글 드라이브 |
| vggface2_fp | align_112x112 | - | - | - | - | Google Drive, Baidu Drive |
| agedb | 날것의 | 570 | 16,488 | - | - | Google Drive, Baidu Drive |
| agedb | align_112x112 | 570 | 16,488 | - | - | Google Drive, Baidu Drive |
| IJB-A | 깨끗한 | 500 | 5,396 | 20,369 | 2,085 | Google Drive, Baidu Drive |
| IJB-B | 날것의 | 1,845 | 21,798 | 55,026 | 7,011 | 구글 드라이브 |
| CFP | 날것의 | 500 | 7,000 | - | - | Google Drive, Baidu Drive |
| CFP | align_112x112 | 500 | 7,000 | - | - | Google Drive, Baidu Drive |
| umdfaces | align_112x112 | 8,277 | 367,888 | - | - | Google Drive, Baidu Drive |
| Celeba | 날것의 | 10,177 | 202,599 | - | - | Google Drive, Baidu Drive |
| CACD-VS | 날것의 | 2,000 | 163,446 | - | - | Google Drive, Baidu Drive |
| YTF | align_344x344 | 1,595 | - | 3,425 | 621,127 | Google Drive, Baidu Drive |
| Deepglint | align_112x112 | 180,855 | 6,753,545 | - | - | 구글 드라이브 |
| Utkface | align_200x200 | - | 23,708 | - | - | Google Drive, Baidu Drive |
| Buaa-Visnir | align_287x287 | 150 | 5,952 | - | - | 바이두 드라이브, PW : XMBC |
| CASIA NIR-VIS 2.0 | align_128x128 | 725 | 17,580 | - | - | 바이두 드라이브, PW : 883b |
| Oulu-Casia | 날것의 | 80 | 65,000 | - | - | 바이두 드라이브, PW : XXP5 |
| nuaa-imposterdb | 날것의 | 15 | 12,614 | - | - | 바이두 드라이브, PW : IF3N |
| 카시아-서프 | 날것의 | 1,000 | - | - | 21,000 | 바이두 드라이브, PW : IZB3 |
| CASIA-FASD | 날것의 | 50 | - | - | 600 | 바이두 드라이브, PW : H5UN |
| CASIA-MFSD | 날것의 | 50 | - | - | 600 | |
| 재생 공격 | 날것의 | 50 | - | - | 1,200 | |
| webface260m | 날것의 | 24m | 2m | - | https://www.face-benchmark.org/ |
unzip casia-maxpy-clean.zip
cd casia-maxpy-clean
zip -F CASIA-maxpy-clean.zip --out CASIA-maxpy-clean_fix.zip
unzip CASIA-maxpy-clean_fix.zip
import numpy as np
import bcolz
import os
def get_pair ( root , name ):
carray = bcolz . carray ( rootdir = os . path . join ( root , name ), mode = 'r' )
issame = np . load ( '{}/{}_list.npy' . format ( root , name ))
return carray , issame
def get_data ( data_root ):
agedb_30 , agedb_30_issame = get_pair ( data_root , 'agedb_30' )
cfp_fp , cfp_fp_issame = get_pair ( data_root , 'cfp_fp' )
lfw , lfw_issame = get_pair ( data_root , 'lfw' )
vgg2_fp , vgg2_fp_issame = get_pair ( data_root , 'vgg2_fp' )
return agedb_30 , cfp_fp , lfw , vgg2_fp , agedb_30_issame , cfp_fp_issame , lfw_issame , vgg2_fp_issame
agedb_30 , cfp_fp , lfw , vgg2_fp , agedb_30_issame , cfp_fp_issame , lfw_issame , vgg2_fp_issame = get_data ( DATA_ROOT )MS-Celeb-1M_Top1M_MID2Name.tsv (Google Drive, Baidu Drive), VGGface2_ID2Name.csv (Google Drive, Baidu Drive), VGGface2_FaceScrub_Overlap.txt (Google Drive, Baidu Drive), VGGface2_LFW_Overlap.txt (Google Drive, Baidu Drive)를 공유합니다. CASIA-WebFace_ID2Name.txt (Google Drive, Baidu Drive), CASIA-WebFace_FaceScrub_Overlap.txt (Google Drive, Baidu Drive), CASIA-WebFace_LFW_Overlap.txt (Google Drive, Baidu Drive), FaceScrub_Name.txt (Google Drive, Baidu Drive), LFW_Name.txt , BAIDU DRIVE) LFW_Log.txt (Google Drive, Baidu Drive)는 연구원/엔지니어가 자신의 개인 데이터 세트와 공개 데이터 세트간에 겹치는 부품을 빠르게 제거 할 수 있도록 도와줍니다.?
모델
| 등뼈 | 머리 | 손실 | 교육 데이터 | 링크 다운로드 |
|---|---|---|---|---|
| IR-50 | 아크 페이스 | 초점 | MS-CELEB-1M_ALIGN_112X112 | Google Drive, Baidu Drive |
환경
INPUT_SIZE: [112, 112]; RGB_MEAN: [0.5, 0.5, 0.5]; RGB_STD: [0.5, 0.5, 0.5]; BATCH_SIZE: 512 (drop the last batch to ensure consistent batch_norm statistics); Initial LR: 0.1; NUM_EPOCH: 120; WEIGHT_DECAY: 5e-4 (do not apply to batch_norm parameters); MOMENTUM: 0.9; STAGES: [30, 60, 90]; Augmentation: Random Crop + Horizontal Flip; Imbalanced Data Processing: Weighted Random Sampling; Solver: SGD; GPUs: 4 NVIDIA Tesla P40 in Parallel
교육 및 검증 통계

성능
| LFW | CFP_FF | CFP_FP | agedb | calfw | cplfw | vggface2_fp |
|---|---|---|---|---|---|---|
| 99.78 | 99.69 | 98.14 | 97.53 | 95.87 | 92.45 | 95.22 |
모델
| 등뼈 | 머리 | 손실 | 교육 데이터 | 링크 다운로드 |
|---|---|---|---|---|
| IR-50 | 아크 페이스 | 초점 | 개인 아시아 얼굴 데이터 | Google Drive, Baidu Drive |
환경
INPUT_SIZE: [112, 112]; RGB_MEAN: [0.5, 0.5, 0.5]; RGB_STD: [0.5, 0.5, 0.5]; BATCH_SIZE: 1024 (drop the last batch to ensure consistent batch_norm statistics); Initial LR: 0.01 (initialize weights from the above model pre-trained on MS-Celeb-1M_Align_112x112); NUM_EPOCH: 80; WEIGHT_DECAY: 5e-4 (do not apply to batch_norm parameters); MOMENTUM: 0.9; STAGES: [20, 40, 60]; Augmentation: Random Crop + Horizontal Flip; Imbalanced Data Processing: Weighted Random Sampling; Solver: SGD; GPUs: 8 NVIDIA Tesla P40 in Parallel
성능 (자신의 아시아 얼굴 벤치 마크 데이터 세트에 대한 평가를 수행하십시오)
모델
| 등뼈 | 머리 | 손실 | 교육 데이터 | 링크 다운로드 |
|---|---|---|---|---|
| IR-152 | 아크 페이스 | 초점 | MS-CELEB-1M_ALIGN_112X112 | 바이두 드라이브, PW : B197 |
환경
INPUT_SIZE: [112, 112]; RGB_MEAN: [0.5, 0.5, 0.5]; RGB_STD: [0.5, 0.5, 0.5]; BATCH_SIZE: 256 (drop the last batch to ensure consistent batch_norm statistics); Initial LR: 0.01; NUM_EPOCH: 120; WEIGHT_DECAY: 5e-4 (do not apply to batch_norm parameters); MOMENTUM: 0.9; STAGES: [30, 60, 90]; Augmentation: Random Crop + Horizontal Flip; Imbalanced Data Processing: Weighted Random Sampling; Solver: SGD; GPUs: 4 NVIDIA Geforce RTX 2080 Ti in Parallel
교육 및 검증 통계

성능
| LFW | CFP_FF | CFP_FP | agedb | calfw | cplfw | vggface2_fp |
|---|---|---|---|---|---|---|
| 99.82 | 99.83 | 98.37 | 98.07 | 96.03 | 93.05 | 95.50 |
?
ICCV 2017 MS-CELEB-1M 대규모 얼굴 인식 하드 세트/랜덤 세트/로우 샷 학습 문제에 대한 2017 No.1. WeChat News, NUS ECE News, NUS ECE 포스터, 트랙 -1에 대한 수상 인증서, 트랙 -2의 수상 인증서, 시상식.
NIST (National Institute of Standards and Technology) IARPA JANUS 벤치 마크 A (IJB-A)가 제한되지 않은 얼굴 검증 과제 및 식별 문제의 2017 No.1. Wechat 뉴스.
최첨단 성과
?
?
다음 논문을 인용하고 고려하십시오.
@article{wu20223d,
title={3D-Guided Frontal Face Generation for Pose-Invariant Recognition},
author={Wu, Hao and Gu, Jianyang and Fan, Xiaojin and Li, He and Xie, Lidong and Zhao, Jian},
journal={T-IST},
year={2022}
}
@article{wang2021face,
title={Face.evoLVe: A High-Performance Face Recognition Library},
author={Wang, Qingzhong and Zhang, Pengfei and Xiong, Haoyi and Zhao, Jian},
journal={arXiv preprint arXiv:2107.08621},
year={2021}
}
@article{tu2021joint,
title={Joint Face Image Restoration and Frontalization for Recognition},
author={Tu, Xiaoguang and Zhao, Jian and Liu, Qiankun and Ai, Wenjie and Guo, Guodong and Li, Zhifeng and Liu, Wei and Feng, Jiashi},
journal={T-CSVT},
year={2021}
}
@article{zhao2020towards,
title={Towards age-invariant face recognition},
author={Zhao, Jian and Yan, Shuicheng and Feng, Jiashi},
journal={T-PAMI},
year={2020}
}
@article{zhao2019recognizing,
title={Recognizing Profile Faces by Imagining Frontal View},
author={Zhao, Jian and Xing, Junliang and Xiong, Lin and Yan, Shuicheng and Feng, Jiashi},
journal={IJCV},
pages={1--19},
year={2019}
}
@inproceedings{zhao2019multi,
title={Multi-Prototype Networks for Unconstrained Set-based Face Recognition},
author={Zhao, Jian and Li, Jianshu and Tu, Xiaoguang and Zhao, Fang and Xin, Yuan and Xing, Junliang and Liu, Hengzhu and Yan, Shuicheng and Feng, Jiashi},
booktitle={IJCAI},
year={2019}
}
@inproceedings{zhao2019look,
title={Look Across Elapse: Disentangled Representation Learning and Photorealistic Cross-Age Face Synthesis for Age-Invariant Face Recognition},
author={Zhao, Jian and Cheng, Yu and Cheng, Yi and Yang, Yang and Lan, Haochong and Zhao, Fang and Xiong, Lin and Xu, Yan and Li, Jianshu and Pranata, Sugiri and others},
booktitle={AAAI},
year={2019}
}
@article{zhao20183d,
title={3D-Aided Dual-Agent GANs for Unconstrained Face Recognition},
author={Zhao, Jian and Xiong, Lin and Li, Jianshu and Xing, Junliang and Yan, Shuicheng and Feng, Jiashi},
journal={T-PAMI},
year={2018}
}
@inproceedings{zhao2018towards,
title={Towards Pose Invariant Face Recognition in the Wild},
author={Zhao, Jian and Cheng, Yu and Xu, Yan and Xiong, Lin and Li, Jianshu and Zhao, Fang and Jayashree, Karlekar and Pranata, Sugiri and Shen, Shengmei and Xing, Junliang and others},
booktitle={CVPR},
pages={2207--2216},
year={2018}
}
@inproceedings{zhao3d,
title={3D-Aided Deep Pose-Invariant Face Recognition},
author={Zhao, Jian and Xiong, Lin and Cheng, Yu and Cheng, Yi and Li, Jianshu and Zhou, Li and Xu, Yan and Karlekar, Jayashree and Pranata, Sugiri and Shen, Shengmei and others},
booktitle={IJCAI},
pages={1184--1190},
year={2018}
}
@inproceedings{zhao2018dynamic,
title={Dynamic Conditional Networks for Few-Shot Learning},
author={Zhao, Fang and Zhao, Jian and Yan, Shuicheng and Feng, Jiashi},
booktitle={ECCV},
pages={19--35},
year={2018}
}
@inproceedings{zhao2017dual,
title={Dual-agent gans for photorealistic and identity preserving profile face synthesis},
author={Zhao, Jian and Xiong, Lin and Jayashree, Panasonic Karlekar and Li, Jianshu and Zhao, Fang and Wang, Zhecan and Pranata, Panasonic Sugiri and Shen, Panasonic Shengmei and Yan, Shuicheng and Feng, Jiashi},
booktitle={NeurIPS},
pages={66--76},
year={2017}
}
@inproceedings{zhao122017marginalized,
title={Marginalized cnn: Learning deep invariant representations},
author={Zhao12, Jian and Li, Jianshu and Zhao, Fang and Yan13, Shuicheng and Feng, Jiashi},
booktitle={BMVC},
year={2017}
}
@inproceedings{cheng2017know,
title={Know you at one glance: A compact vector representation for low-shot learning},
author={Cheng, Yu and Zhao, Jian and Wang, Zhecan and Xu, Yan and Jayashree, Karlekar and Shen, Shengmei and Feng, Jiashi},
booktitle={ICCVW},
pages={1924--1932},
year={2017}
}
@inproceedings{wangconditional,
title={Conditional Dual-Agent GANs for Photorealistic and Annotation Preserving Image Synthesis},
author={Wang, Zhecan and Zhao, Jian and Cheng, Yu and Xiao, Shengtao and Li, Jianshu and Zhao, Fang and Feng, Jiashi and Kassim, Ashraf},
booktitle={BMVCW},
}


