Switchable Normalization
1.0.0
A normalização comutável é uma técnica de normalização capaz de aprender diferentes operações de normalização para diferentes camadas de normalização em uma rede neural profunda de maneira pontual a ponta.
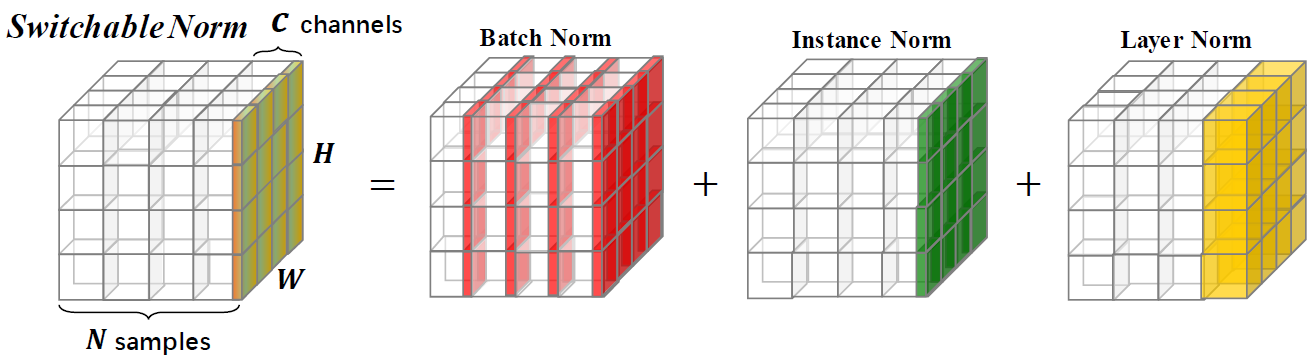
Este repositório fornece resultados de classificação do ImageNet e modelos treinados com normalização comutável. Você é incentivado a citar o artigo a seguir se usar o SN na pesquisa.
@article{SwitchableNorm,
title={Differentiable Learning-to-Normalize via Switchable Normalization},
author={Ping Luo and Jiamin Ren and Zhanglin Peng and Ruimao Zhang and Jingyu Li},
journal={International Conference on Learning Representation (ICLR)},
year={2019}
}
Comparações de precisão Top-1 no conjunto de validação do ImageNet, usando o Resnet50 treinado com SN, BN e GN em diferentes configurações de tamanho em lote. O suporte (·, ·) denota (#gpus,#amostras por GPU). Na parte inferior, "GN-bn" indica a diferença entre as precisão de GN e BN. O "-" em (8, 1) do BN indica que não converge.
| (8,32) | (8,16) | (8,8) | (8,4) | (8,2) | (1,16) | (1,32) | (8,1) | (1,8) | |
| Bn | 76.4 | 76.3 | 75.2 | 72.7 | 65.3 | 76.2 | 76.5 | - | 75.4 |
| Gn | 75.9 | 75.8 | 76.0 | 75.8 | 75.9 | 75.9 | 75.8 | 75.5 | 75.5 |
| Sn | 76.9 | 76.7 | 76.7 | 75.9 | 75.6 | 76.3 | 76.6 | 75.0 * | 75.9 |
| GN - Bn | -0.5 | -0.5 | 0,8 | 3.1 | 10.6 | -0.3 | -0.7 | - | 0.1 |
| Sn - Bn | 0,5 | 0,4 | 1.5 | 3.2 | 10.3 | 0.1 | 0.1 | - | 0,5 |
| Sn - gn | 1.0 | 0,9 | 0,7 | 0.1 | -0.3 | 0,4 | 0,8 | -0.5 | 0,4 |
Fornecemos modelos pré -tenhados com SN no ImageNet e comparamos com aqueles pré -tenhados com o BN como referência. Se você usar esses modelos em pesquisa, cite o papel SN. A configuração do SN é indicada como (#GPUS, #IMAGES por GPU).
| Modelo | Top-1 * | Top-5 * | Épocas | LR Scheduler | Decaimento de peso | Download |
|---|---|---|---|---|---|---|
| Resnet101V2+SN (8,32) | 78,81% | 94,16% | 120 | Warmup + Cosine LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet101V1+SN (8,32) | 78,54% | 94,10% | 120 | Warmup + Cosine LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v2+SN (8,32) | 77,57% | 93,65% | 120 | Warmup + Cosine LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+SN (8,32) | 77,49% | 93,32% | 120 | Warmup + Cosine LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+SN (8,32) | 76,92% | 93,26% | 100 | LR inicial = 0,1 decaimento = 0,1 etapas [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+SN (8,4) | 75,85% | 92,7% | 100 | LR inicial = 0,0125 decaimento = 0,1 etapas [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+SN (8,1) † | 75,94% | 92,7% | 100 | LR inicial = 0,003125 decaimento = 0,1 etapas [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+Bn | 75,20% | 92,20% | - | decaimento passo a passo | - | [Modelos Tensorflow] |
| Resnet50v1+Bn | 76,00% | 92,98% | - | decaimento passo a passo | - | [Visão de Pytorch] |
| Resnet50v1+Bn | 75,30% | 92,20% | - | decaimento passo a passo | - | [MSRA] |
| Resnet50v1+Bn | 75,99% | 92,98% | - | decaimento passo a passo | - | [Tocha do FB] |
*Precisão de validação de cropa única no ImageNet (uma colheita central de 224x224 da imagem redimensionada com lado mais curto = 256)
† Para (8,1), o SN contém e LN sem BN, pois o BN é o mesmo que no treinamento. Ao usar este modelo, você deve adicionar using_bn : False no YAML.
Todos os materiais neste repositório são liberados sob a licença CC-BY-NC 4.0.


