Switchable Normalization
1.0.0
Normalisasi yang dapat dialihkan adalah teknik normalisasi yang mampu mempelajari operasi normalisasi yang berbeda untuk lapisan normalisasi yang berbeda dalam jaringan saraf yang dalam dengan cara ujung ke ujung.
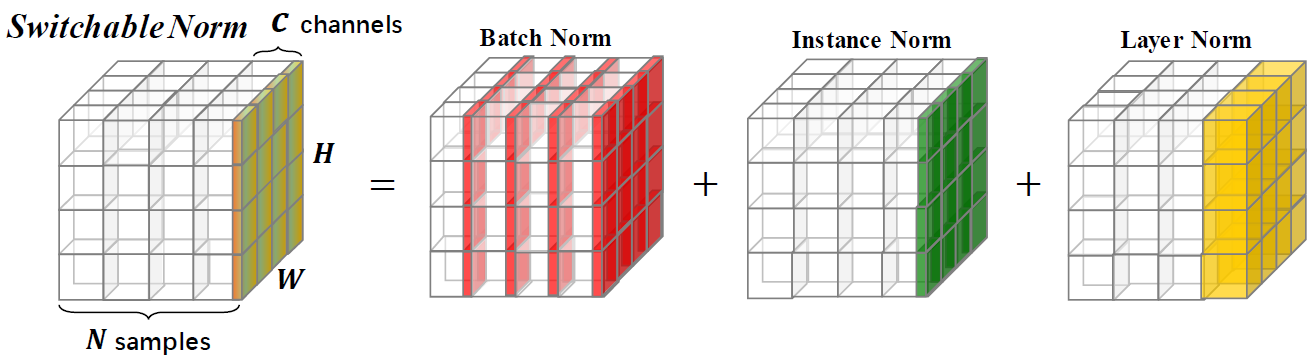
Repositori ini memberikan hasil klasifikasi ImagEnet dan model yang dilatih dengan normalisasi yang dapat dialihkan. Anda didorong untuk mengutip makalah berikut jika Anda menggunakan SN dalam penelitian.
@article{SwitchableNorm,
title={Differentiable Learning-to-Normalize via Switchable Normalization},
author={Ping Luo and Jiamin Ren and Zhanglin Peng and Ruimao Zhang and Jingyu Li},
journal={International Conference on Learning Representation (ICLR)},
year={2019}
}
Perbandingan akurasi Top-1 pada set validasi Imagenet, dengan menggunakan ResNet50 yang dilatih dengan SN, BN, dan GN dalam pengaturan ukuran batch yang berbeda. Braket (·, ·) menunjukkan (#GPU,#sampel per GPU). Di bagian bawah, "GN-BN" menunjukkan perbedaan antara akurasi GN dan BN. "-" dalam (8, 1) dari Bn menunjukkan tidak bertemu.
| (8,32) | (8,16) | (8,8) | (8,4) | (8,2) | (1,16) | (1,32) | (8,1) | (1,8) | |
| Bn | 76.4 | 76.3 | 75.2 | 72.7 | 65.3 | 76.2 | 76.5 | - - | 75.4 |
| Gn | 75.9 | 75.8 | 76.0 | 75.8 | 75.9 | 75.9 | 75.8 | 75.5 | 75.5 |
| Sn | 76.9 | 76.7 | 76.7 | 75.9 | 75.6 | 76.3 | 76.6 | 75.0 * | 75.9 |
| Gn - bn | -0.5 | -0.5 | 0.8 | 3.1 | 10.6 | -0.3 | -0.7 | - - | 0.1 |
| Sn - bn | 0,5 | 0.4 | 1.5 | 3.2 | 10.3 | 0.1 | 0.1 | - - | 0,5 |
| Sn - gn | 1.0 | 0.9 | 0.7 | 0.1 | -0.3 | 0.4 | 0.8 | -0.5 | 0.4 |
Kami memberikan model pretrained dengan SN di ImageNet, dan dibandingkan dengan yang diprasahkan dengan BN sebagai referensi. Jika Anda menggunakan model ini dalam penelitian, silakan kutip kertas SN. Konfigurasi SN dilambangkan sebagai (#gpus, #images per GPU).
| Model | Top-1 * | Top-5 * | Zaman | Penjadwal LR | Kerusakan berat badan | Unduh |
|---|---|---|---|---|---|---|
| Resnet101v2+sn (8,32) | 78,81% | 94,16% | 120 | Pemanasan + Cosine LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet101v1+sn (8,32) | 78,54% | 94,10% | 120 | Pemanasan + Cosine LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v2+sn (8,32) | 77,57% | 93,65% | 120 | Pemanasan + Cosine LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,32) | 77,49% | 93,32% | 120 | Pemanasan + Cosine LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,32) | 76,92% | 93,26% | 100 | LR awal = 0,1 peluruhan = 0,1 langkah [30,60,90,10] | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,4) | 75,85% | 92,7% | 100 | LR awal = 0,0125 peluruhan = 0,1 langkah [30,60,90,10] | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,1) † | 75,94% | 92,7% | 100 | LR awal = 0,003125 peluruhan = 0,1 langkah [30,60,90,10] | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+bn | 75,20% | 92,20% | - | pembusukan bertahap | - | [Model TensorFlow] |
| Resnet50v1+bn | 76,00% | 92,98% | - | pembusukan bertahap | - | [Visi Pytorch] |
| Resnet50v1+bn | 75,30% | 92,20% | - | pembusukan bertahap | - | [MSRA] |
| Resnet50v1+bn | 75,99% | 92,98% | - | pembusukan bertahap | - | [FB Torch] |
*Akurasi validasi single-crop di ImageNet (tanaman tengah 224x224 dari gambar yang diubah ukuran dengan sisi yang lebih pendek = 256)
† Untuk (8,1), SN berisi dalam dan LN tanpa BN, karena BN sama seperti dalam pelatihan. Saat menggunakan model ini, Anda harus menambahkan using_bn : False dalam file yaml.
Semua bahan dalam repositori ini dirilis di bawah lisensi CC-by-NC 4.0.


