Switchable Normalization
1.0.0
La normalisation commutable est une technique de normalisation qui est capable d'apprendre différentes opérations de normalisation pour différentes couches de normalisation dans un réseau neuronal profond de bout en bout.
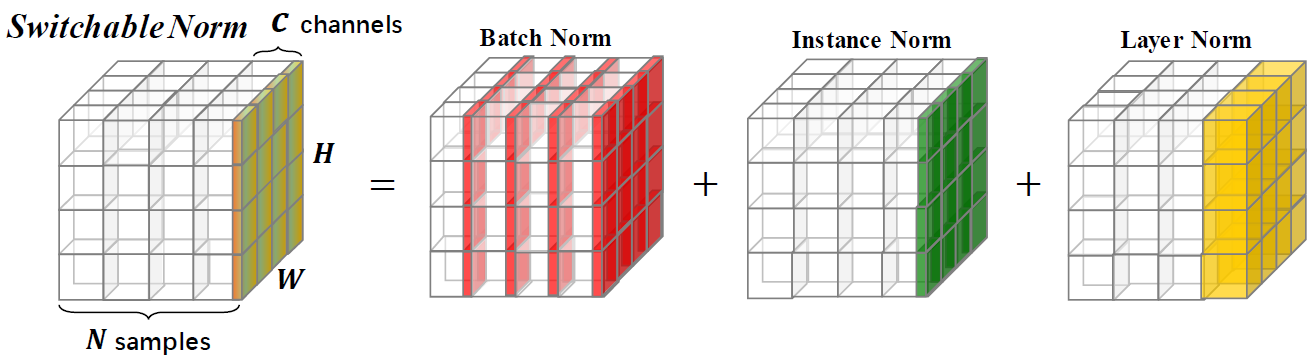
Ce référentiel fournit des résultats de classification ImageNet et des modèles formés avec une normalisation commutable. Vous êtes encouragé à citer l'article suivant si vous utilisez SN dans la recherche.
@article{SwitchableNorm,
title={Differentiable Learning-to-Normalize via Switchable Normalization},
author={Ping Luo and Jiamin Ren and Zhanglin Peng and Ruimao Zhang and Jingyu Li},
journal={International Conference on Learning Representation (ICLR)},
year={2019}
}
Comparaisons des précisions top-1 sur l'ensemble de validation d'imageNet, en utilisant Resnet50 formé avec SN, BN et GN dans différents paramètres de taille par lots. Le support (·, ·) désigne (# gpus, # échantillons par GPU). Dans la partie inférieure, «GN-BN» indique la différence entre les précisions de GN et BN. Le «-» dans (8, 1) de BN indique qu'il ne converge pas.
| (8,32) | (8,16) | (8,8) | (8,4) | (8,2) | (1,16) | (1,32) | (8,1) | (1,8) | |
| BN | 76.4 | 76.3 | 75.2 | 72.7 | 65.3 | 76.2 | 76.5 | - | 75.4 |
| Gn | 75.9 | 75.8 | 76.0 | 75.8 | 75.9 | 75.9 | 75.8 | 75.5 | 75.5 |
| Sn | 76.9 | 76.7 | 76.7 | 75.9 | 75.6 | 76.3 | 76.6 | 75.0 * | 75.9 |
| GN - BN | -0,5 | -0,5 | 0.8 | 3.1 | 10.6 | -0,3 | -0,7 | - | 0.1 |
| Sn - bn | 0,5 | 0.4 | 1.5 | 3.2 | 10.3 | 0.1 | 0.1 | - | 0,5 |
| Sn - gn | 1.0 | 0.9 | 0.7 | 0.1 | -0,3 | 0.4 | 0.8 | -0,5 | 0.4 |
Nous fournissons des modèles pré-entraînés avec SN sur ImageNet et nous comparons à ceux pré-entraînés avec BN comme référence. Si vous utilisez ces modèles dans la recherche, veuillez citer le papier SN. La configuration de SN est désignée (#GPUS, #Images par GPU).
| Modèle | Top-1 * | Top-5 * | Époques | Planificateur LR | Décomposition du poids | Télécharger |
|---|---|---|---|---|---|---|
| Resnet101v2 + sn (8,32) | 78,81% | 94,16% | 120 | Échauffement + cosinus LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet101v1 + sn (8,32) | 78,54% | 94,10% | 120 | Échauffement + cosinus LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v2 + sn (8,32) | 77,57% | 93,65% | 120 | Échauffement + cosinus LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1 + sn (8,32) | 77,49% | 93,32% | 120 | Échauffement + cosinus LR | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1 + sn (8,32) | 76,92% | 93,26% | 100 | LR initial = 0,1 désintégration = 0,1 étapes [30,60,90,10] | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1 + sn (8,4) | 75,85% | 92,7% | 100 | LR initial = 0,0125 DÉCHETURE = 0,1 étapes [30,60,90,10] | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1 + sn (8,1) † | 75,94% | 92,7% | 100 | LR initial = 0,003125 DÉCHETURE = 0,1 étapes [30,60,90,10] | 1E-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1 + bn | 75,20% | 92,20% | - | décroissance pas à pas | - | [Modèles TensorFlow] |
| Resnet50v1 + bn | 76,00% | 92,98% | - | décroissance pas à pas | - | [Vision Pytorch] |
| Resnet50v1 + bn | 75,30% | 92,20% | - | décroissance pas à pas | - | [MSRA] |
| Resnet50v1 + bn | 75,99% | 92,98% | - | décroissance pas à pas | - | [Torche FB] |
* Précision de validation à une seule culture sur ImageNet (une culture centrale 224x224 de l'image redimensionnée avec un côté plus court = 256)
† Pour (8,1), SN contient dans et LN sans BN, comme BN est le même que dans la formation. Lorsque vous utilisez ce modèle, vous devez ajouter using_bn : False dans le fichier yaml.
Tous les documents de ce référentiel sont publiés sous la licence CC-BY-NC 4.0.


