Switchable Normalization
1.0.0
Schaltbare Normalisierung ist eine Normalisierungstechnik, mit der unterschiedliche Normalisierungsvorgänge für unterschiedliche Normalisierungsschichten in einem tiefen neuronalen Netzwerk auf Ende zu Ende gelernt werden können.
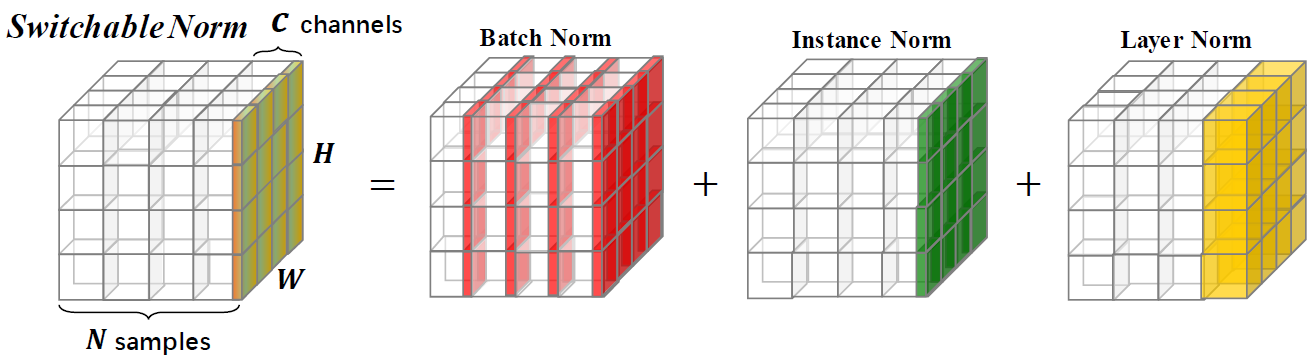
Dieses Repository bietet ImageNet -Klassifizierungsergebnisse und Modelle, die mit einer schaltbaren Normalisierung geschult sind. Sie werden aufgefordert, das folgende Papier zu zitieren, wenn Sie SN in der Forschung verwenden.
@article{SwitchableNorm,
title={Differentiable Learning-to-Normalize via Switchable Normalization},
author={Ping Luo and Jiamin Ren and Zhanglin Peng and Ruimao Zhang and Jingyu Li},
journal={International Conference on Learning Representation (ICLR)},
year={2019}
}
Vergleiche der Top-1-Genauigkeiten auf dem Validierungssatz von ImagEnet unter Verwendung von ResNet50 mit SN, BN und GN in verschiedenen Chargengrößeneinstellungen. Die Klammer (·, ·) bezeichnet (#gpus,#Proben pro GPU). Im unteren Teil zeigt „GN-BN“ den Unterschied zwischen den Genauigkeiten von GN und Bn an. Das "-" in (8, 1) von BN zeigt an, dass es nicht konvergiert.
| (8,32) | (8,16) | (8,8) | (8,4) | (8,2) | (1,16) | (1,32) | (8,1) | (1,8) | |
| Bn | 76,4 | 76,3 | 75,2 | 72.7 | 65.3 | 76,2 | 76,5 | - - | 75,4 |
| Gn | 75,9 | 75,8 | 76.0 | 75,8 | 75,9 | 75,9 | 75,8 | 75,5 | 75,5 |
| Sn | 76,9 | 76,7 | 76,7 | 75,9 | 75,6 | 76,3 | 76,6 | 75,0 * | 75,9 |
| GN - Bn | -0.5 | -0.5 | 0,8 | 3.1 | 10.6 | -0.3 | -0.7 | - - | 0,1 |
| Sn - bn | 0,5 | 0,4 | 1.5 | 3.2 | 10.3 | 0,1 | 0,1 | - - | 0,5 |
| Sn - gn | 1.0 | 0,9 | 0,7 | 0,1 | -0.3 | 0,4 | 0,8 | -0.5 | 0,4 |
Wir stellen Modelle zur Verfügung, die mit SN auf ImageNet vorbereitet sind, und vergleichen mit denjenigen, die mit BN als Referenz vorbereitet sind. Wenn Sie diese Modelle in der Forschung verwenden, zitieren Sie bitte das SN -Papier. Die Konfiguration von SN wird als (#GPUS, #images pro GPU) bezeichnet.
| Modell | Top-1 * | Top-5 * | Epochen | LR Scheduler | Gewichtsverfall | Herunterladen |
|---|---|---|---|---|---|---|
| Resnet101v2+sn (8,32) | 78,81% | 94,16% | 120 | Aufwärmen + Cosinus LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet101v1+sn (8,32) | 78,54% | 94,10% | 120 | Aufwärmen + Cosinus LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v2+sn (8,32) | 77,57% | 93,65% | 120 | Aufwärmen + Cosinus LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,32) | 77,49% | 93,32% | 120 | Aufwärmen + Cosinus LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,32) | 76,92% | 93,26% | 100 | Erstes LR = 0,1 Zerfall = 0,1 Schritte [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,4) | 75,85% | 92,7% | 100 | Erstes LR = 0,0125 Zerfall = 0,1 Schritte [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,1) † | 75,94% | 92,7% | 100 | Erstes LR = 0,003125 Zerfall = 0,1 Schritte [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+bn | 75,20% | 92,20% | - | schrittweisen Verfall | - | [Tensorflow -Modelle] |
| Resnet50v1+bn | 76,00% | 92,98% | - | schrittweisen Verfall | - | [Pytorch Vision] |
| Resnet50v1+bn | 75,30% | 92,20% | - | schrittweisen Verfall | - | [MSRA] |
| Resnet50v1+bn | 75,99% | 92,98% | - | schrittweisen Verfall | - | [FB -Fackel] |
*Ein-Ernte-Validierungsgenauigkeit auf ImageNet (eine 224x224-Mittellage aus der Größe der Größe mit kürzerer Seite = 256)
† Für (8,1) enthält SN in und LN ohne BN, da BN dieselbe wie im Training ist. Wenn Sie dieses Modell verwenden, sollten Sie in der YAML -Datei using_bn : False hinzufügen.
Alle Materialien in diesem Repository werden unter der CC-by-NC 4.0-Lizenz veröffentlicht.


