Switchable Normalization
1.0.0
La normalización conmutable es una técnica de normalización que puede aprender diferentes operaciones de normalización para diferentes capas de normalización en una red neuronal profunda de una manera de extremo a extremo.
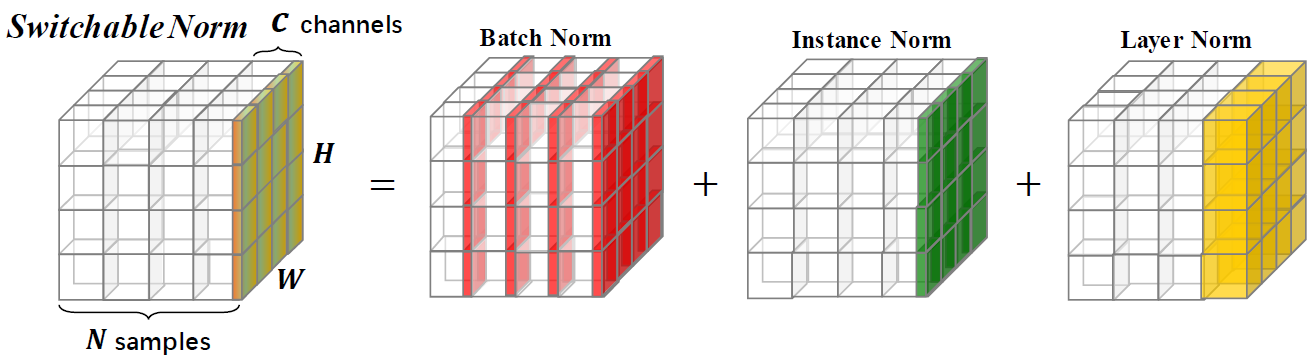
Este repositorio proporciona resultados de clasificación de ImageNet y modelos entrenados con normalización conmutable. Se le recomienda que cite el siguiente documento si usa SN en investigación.
@article{SwitchableNorm,
title={Differentiable Learning-to-Normalize via Switchable Normalization},
author={Ping Luo and Jiamin Ren and Zhanglin Peng and Ruimao Zhang and Jingyu Li},
journal={International Conference on Learning Representation (ICLR)},
year={2019}
}
Comparaciones de las precisiones de Top-1 en el conjunto de validación de Imagenet, utilizando resnet50 entrenado con SN, BN y GN en diferentes configuraciones de tamaño por lotes. El soporte (·, ·) denota (#GPU,#muestras por GPU). En la parte inferior, "Gn-Bn" indica la diferencia entre las precisiones de GN y BN. El "-" en (8, 1) de BN indica que no converge.
| (8,32) | (8,16) | (8,8) | (8,4) | (8,2) | (1,16) | (1.32) | (8,1) | (1,8) | |
| Bn | 76.4 | 76.3 | 75.2 | 72.7 | 65.3 | 76.2 | 76.5 | - | 75.4 |
| Gn | 75.9 | 75.8 | 76.0 | 75.8 | 75.9 | 75.9 | 75.8 | 75.5 | 75.5 |
| Sn | 76.9 | 76.7 | 76.7 | 75.9 | 75.6 | 76.3 | 76.6 | 75.0 * | 75.9 |
| GN - BN | -0.5 | -0.5 | 0.8 | 3.1 | 10.6 | -0.3 | -0.7 | - | 0.1 |
| Sn - bn | 0.5 | 0.4 | 1.5 | 3.2 | 10.3 | 0.1 | 0.1 | - | 0.5 |
| Sn - GN | 1.0 | 0.9 | 0.7 | 0.1 | -0.3 | 0.4 | 0.8 | -0.5 | 0.4 |
Proporcionamos modelos previos a la aparición con SN en Imagenet y comparamos con los que se pretratan con BN como referencia. Si usa estos modelos en la investigación, cite el documento SN. La configuración de SN se denota como (#GPUS, #Images por GPU).
| Modelo | Top-1 * | Top-5 * | Épocas | Planificador LR | Descomposición de peso | Descargar |
|---|---|---|---|---|---|---|
| Resnet101v2+sn (8,32) | 78.81% | 94.16% | 120 | calentamiento + coseno LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet101v1+sn (8,32) | 78.54% | 94.10% | 120 | calentamiento + coseno LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v2+sn (8,32) | 77.57% | 93.65% | 120 | calentamiento + coseno LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,32) | 77.49% | 93.32% | 120 | calentamiento + coseno LR | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,32) | 76.92% | 93.26% | 100 | LR inicial = 0.1 decaimiento = 0.1 pasos [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,4) | 75.85% | 92.7% | 100 | LR inicial = 0.0125 Decadencia = 0.1 pasos [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+sn (8,1) † | 75.94% | 92.7% | 100 | LR inicial = 0.003125 Decadencia = 0.1 pasos [30,60,90,10] | 1e-4 | [Google Drive] [Baidu Pan] |
| Resnet50v1+bn | 75.20% | 92.20% | - | descomposición paso a paso | - | [Modelos TensorFlow] |
| Resnet50v1+bn | 76.00% | 92.98% | - | descomposición paso a paso | - | [Visión de Pytorch] |
| Resnet50v1+bn | 75.30% | 92.20% | - | descomposición paso a paso | - | [MSRA] |
| Resnet50v1+bn | 75.99% | 92.98% | - | descomposición paso a paso | - | [FB Torch] |
*Precisión de validación de un solo cultivo en ImageNet (un cultivo central 224x224 de una imagen redimensionada con el lado más corto = 256)
† Para (8,1), Sn contiene en y ln sin BN, ya que Bn es el mismo que en el entrenamiento. Al usar este modelo, debe agregar using_bn : False en el archivo yaml.
Todos los materiales en este repositorio se lanzan bajo la licencia CC-by-NC 4.0.


