chad
v7.0
Pesquise o Google Dorks como o Chad. Baseado em Ivan-Sincek/Nagooglesearch.
Testado no Kali Linux V2024.2 (64 bits).
Feito para fins educacionais. Espero que ajude!
Planos futuros:
linkedin-user . pip3 install --upgrade playwright
playwright install chromiumCertifique-se de que sempre que atualize sua dependência do dramaturgo para reinstalar o cromo; Caso contrário, você poderá receber um erro usando o navegador sem cabeça no extrator Chad.
pip3 install --upgrade google-chadgit clone https://github.com/ivan-sincek/chad && cd chad
python3 -m pip install --upgrade build
python3 -m build
python3 -m pip install dist/google_chad-7.0-py3-none-any.whlchad -q ' intitle:"index of /" intext:"parent directory" ' Você disse metagoofil?!
mkdir downloads
chad -q " ext:pdf OR ext:docx OR ext:xlsx OR ext:pptx " -s * .example.com -tr 200 -dir downloadsO recurso de download de arquivos do Chad é baseado na dependência do Python solicitações.
O Chad Extractor é uma ferramenta poderosa baseada no rastreador da Web do Scrapy e no navegador Chromium sem cabeça do dramaturgo, projetado para raspar com eficiência o conteúdo da Web; Ao contrário do Python, solicita a dependência, que não pode renderizar o HTML codificado por JavaScript e é facilmente bloqueado por soluções anti-BOT.
Principalmente, o extrator do Chad foi projetado para extrair e validar dados dos arquivos de resultados do CHAD. No entanto, ele também pode ser usado para extrair e validar dados dos arquivos de texto simples usando a opção -pt .
Se a opção -pt for usada, os arquivos de texto simples serão tratados como respostas do servidor e a lógica de extração será aplicada, seguida pela validação. Isso também é útil se você deseja testar novamente os relatórios do Chad Extractor anterior, por exemplo, usando -res report.json -pt -o retest.json .
Prepare o Google Dorks como Social_Media_Dorks.txt Arquivo:
intext:"t.me/"
intext:"discord.com/invite/" OR intext:"discord.gg/invite/"
intext:"youtube.com/c/" OR intext:"youtube.com/channel/"
intext:"twitter.com/" OR intext:"x.com/"
intext:"facebook.com/"
intext:"instagram.com/"
intext:"tiktok.com/"
intext:"linkedin.com/in/" OR intext:"linkedin.com/company/"
Prepare o modelo como social_media_template.json arquivo:
{
"telegram" :{
"extract" : " t \ .me \ /(?:(?!(?:share)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https:// " ,
"validate" : " <meta property= " og:title " content= " Telegram: Contact .+? " > "
},
"discord" :{
"extract" : " discord \ .(?:com|gg) \ /invite \ /[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https:// " ,
"validate" : " Invite Invalid " ,
"validate_browser" : true ,
"validate_browser_wait" : 6
},
"youtube" :{
"extract" : " youtube \ .com \ /(?:c|channel) \ /[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " <iframe.+?src= "\ /error \ ?src=404.+? " > " ,
"validate_cookies" :{
"SOCS" : " CAESEwgDEgk2OTk3ODk2MzcaAmVuIAEaBgiAn5S6Bg "
}
},
"twitter" :{
"extract" : " (?<=(?<!pic \ .)twitter|(?<!pic \ .)x) \ .com \ /(?:(?!(?:[ \ w]{2} \ /)*(?:explore|hashtag|home|i|intent|library|media|personalization|privacy|search|share|tos|widgets \ .js)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://x " ,
"validate" : " This account doesn.?t exist " ,
"validate_browser" : true ,
"validate_cookies" :{
"night_mode" : " 2 "
}
},
"facebook" :{
"extract" : " facebook \ .com \ /(?:(?!(?:about|dialog|gaming|groups|public|sharer|share \ .php|terms \ .php)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " This (?:content|page) isn't available " ,
"validate_browser" : true
},
"instagram" :{
"extract" : " instagram \ .com \ /(?:(?!(?:about|accounts|ar|explore|p)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"extract_append" : " / " ,
"validate" : " Sorry, this page isn't available \ . " ,
"validate_browser" : true
},
"tiktok" :{
"extract" : " (?<!vt \ .)tiktok \ .com \ / \ @[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " Couldn't find this account "
},
"linkedin-company" :{
"extract" : " linkedin \ .com \ /company \ /[ \ w \ d \ . \ _ \ - \ + \ @ \ &]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " Page not found " ,
"validate_cookies" :{
"bcookie" : " v=2 " ,
"lang" : " v=2&lang=en-us "
}
},
"linkedin-user" :{
"extract" : " linkedin \ .com \ /in \ /[ \ w \ d \ . \ _ \ - \ + \ @ \ &]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " An exact match for .+ could not be found \ . "
}
} Certifique -se de que suas expressões regulares retornem apenas um grupo de captura, por exemplo, [1, 2, 3, 4] ; e não um topo, por exemplo, [(1, 2), (3, 4)] .
Certifique -se de escapar adequadamente de símbolos específicos da expressão regular em seu arquivo de modelo, por exemplo, escape do DOT . como \. , e para a frente Slash / como \/ , etc.
Todas as pesquisas regulares de expressão são insensíveis a minúsculas.
O conteúdo da Web buscado nos URLs nos arquivos de resultados do CHAD será correspondido com todas as expressões regulares (definidas pelos atributos extract ) no arquivo de modelo para encontrar o máximo de dados relevantes possível.
Para extrair dados sem validação, basta omitir os atributos validate do arquivo de modelo, conforme necessário.
| Escopo | Nome | Tipo | Obrigatório | Descrição |
|---|---|---|---|---|
| extração | extrair | str | sim | Consulta de expressão regular. |
| extração | Extract_prepend | str | não | String para prender todos os dados extraídos. |
| extração | Extract_append | str | não | String para anexar a dados extraídos. |
| validação | validar | str | não | Consulta de expressão regular. |
| validação | validate_browser | bool | não | Se deve usar o navegador sem cabeça ou não. |
| validação | validate_browser_wait | flutuador | não | Tempo de espera em segundos antes de buscar o conteúdo na página do navegador sem cabeça. |
| validação | validate_headers | dict [str, str] | não | Cabeçalhos de solicitação HTTP em formato de valor-chave. O cabeçalho Cookie é ignorado. |
| validação | validate_cookies | dict [str, str] | não | Cookies de solicitação de http em formato de valor-chave. |
Tabela 1 - Atributos de modelo
chad -q social_media_dorks.txt -s * .example.com -tr 200 -pr 100 -o results.json
chad-extractor -t social_media_template.json -res results.json -o report.json Prepare os domínios / subdomínios como sites.txt Arquivo, da mesma maneira que os usaria com o site: Opção no Google:
*.example.com
*.example.com -www
Correr:
mkdir chad_results
IFS= $' n ' ; count=0 ; for site in $( cat sites.txt ) ; do count= $(( count + 1 )) ; echo " # ${count} | ${site} " ; chad -q social_media_dorks.txt -s " ${site} " -tr 200 -pr 100 -o " chad_results/results_ ${count} .json " ; done
chad-extractor -t social_media_template.json -res chad_results -o report.json -v Verifique manualmente se os URLs de mídia social quebrados nos results[summary][validated] são vulneráveis à aquisição:
{
"started_at" : " 2023-12-23 03:30:10 " ,
"ended_at" : " 2023-12-23 04:20:00 " ,
"summary" :{
"validated" :[
" https://t.me/does_not_exist " // might be vulnerable to takeover
],
"extracted" :[
" https://discord.com/invite/exists " ,
" https://t.me/does_not_exist " ,
" https://t.me/exists "
]
},
"failed" :{
"validation" :[],
"extraction" :[]
},
"full" :[
{
"url" : " https://example.com/about " ,
"results" :{
"telegram" :[
" https://t.me/does_not_exist " ,
" https://t.me/exists "
],
"discord" :[
" https://discord.com/invite/exists "
]
}
}
]
}O período de reflexão do Google pode variar de algumas horas a um dia inteiro.
Para evitar atingir os limites da taxa do Google com o Chade, aumente o sono mínimo e máximo entre as consultas e/ou páginas do Google; ou use proxies gratuitos ou pagos. No entanto, proxies gratuitos são frequentemente bloqueados e instáveis.
Para baixar uma lista de proxies gratuitos, execute:
curl -s ' https://proxylist.geonode.com/api/proxy-list?limit=50&page=1&sort_by=lastChecked&sort_type=desc ' -H ' Referer: https://proxylist.geonode.com/ ' | jq -r ' .data[] | "(.protocols[])://(.ip):(.port)" ' > proxies.txtSe você estiver usando proxies, convém aumentar o tempo limite da solicitação, pois as respostas precisarão de mais tempo para chegar.
Além disso, para evitar atingir limites de taxa em plataformas como o Instagram enquanto usam o extrator do Chad, considere diminuir o número de solicitações simultâneas por domínio e aumentar o sono e o tempo de espera.
Chad v7.0 ( github.com/ivan-sincek/chad )
Usage: chad -q queries [-s site ] [-x proxies ] [-o out ]
Example: chad -q queries.txt [-s *.example.com] [-x proxies.txt] [-o results.json]
DESCRIPTION
Search Google Dorks like Chad
QUERIES
File containing Google Dorks or a single query to use
-q, --queries = queries.txt | intext:password | "ext:tar OR ext:zip" | etc.
SITE
Domain[s] to search
-s, --site = example.com | sub.example.com | *.example.com | "*.example.com -www" | etc.
TIME
Get results not older than the specified time in months
-t, --time = 6 | 12 | 24 | etc.
TOTAL RESULTS
Total number of unique results
Default: 100
-tr, --total-results = 200 | etc.
PAGE RESULTS
Number of results per page - capped at 100 by Google
Default: randint(70, 100)
-pr, --page-results = 50 | etc.
MINIMUM QUERIES
Minimum sleep time in seconds between Google queries
Default: 75
-min-q, --minimum-queries = 120 | etc.
MAXIMUM QUERIES
Maximum sleep time between Google queries
Default: minimum + 50
-max-q, --maximum-queries = 180 | etc.
MINIMUM PAGES
Minimum sleep time between Google pages
Default: 15
-min-p, --minimum-pages = 30 | etc.
MAXIMUM PAGES
Maximum sleep time between Google pages
Default: minimum + 10
-max-p, --maximum-pages = 60 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random(-all) | curl/3.30.1 | etc.
PROXIES
File containing web proxies or a single web proxy to use
-x, --proxies = proxies.txt | http://127.0.0.1:8080 | etc.
DIRECTORY
Downloads directory
All downloaded files will be saved in this directory
-dir, --directory = downloads | etc.
THREADS
Number of files to download in parallel
Default: 5
-th, --threads = 20 | etc.
OUT
Output file
-o, --out = results.json | etc.
NO SLEEP ON START
Disable the safety feature to prevent triggering rate limits by accident
-nsos, --no-sleep-on-start
DEBUG
Enable debug output
-dbg, --debug
Chad Extractor v7.0 ( github.com/ivan-sincek/chad )
Usage: chad-extractor -t template -res results -o out [-s sleep] [-rs random-sleep]
Example: chad-extractor -t template.json -res chad_results -o report.json [-s 1.5 ] [-rs ]
DESCRIPTION
Extract and validate data from Chad results or plaintext files
TEMPLATE
File containing extraction and validation details
-t, --template = template.json | etc.
RESULTS
Directory containing Chad results or plaintext files, or a single file
If a directory is specified, files ending with '.report.json' will be ignored
-res, --results = chad_results | results.json | urls.txt | etc.
PLAINTEXT
Treat all the results as plaintext files / server responses
-pt, --plaintext
EXCLUDES
File containing regular expressions or a single regular expression to exclude content from the page
Applies only for extraction
-e, --excludes = regexes.txt | "<div id="seo">.+?</div>" | etc.
PLAYWRIGHT
Use Playwright's headless browser
Applies only for extraction
-p, --playwright
PLAYWRIGHT WAIT
Wait time in seconds before fetching the page content
Applies only for extraction
-pw, --playwright-wait = 0.5 | 2 | 4 | etc.
CONCURRENT REQUESTS
Number of concurrent requests
Default: 15
-cr, --concurrent-requests = 30 | 45 | etc.
CONCURRENT REQUESTS PER DOMAIN
Number of concurrent requests per domain
Default: 5
-crd, --concurrent-requests-domain = 10 | 15 | etc.
SLEEP
Sleep time in seconds between two consecutive requests to the same domain
-s, --sleep = 1.5 | 3 | etc.
RANDOM SLEEP
Randomize the sleep time between requests to vary between '0.5 * sleep' and '1.5 * sleep'
-rs, --random-sleep
AUTO THROTTLE
Auto throttle concurrent requests based on the load and latency
Sleep time is still respected
-at, --auto-throttle = 0.5 | 10 | 15 | 45 | etc.
RETRIES
Number of retries per URL
Default: 2
-r, --retries = 0 | 4 | etc.
REQUEST TIMEOUT
Request timeout in seconds
Default: 60
-rt, --request-timeout = 30 | 90 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random(-all) | curl/3.30.1 | etc.
PROXY
Web proxy to use
-x, --proxy = http://127.0.0.1:8080 | etc.
OUT
Output file
-o, --out = report.json | etc.
VERBOSE
Create additional supporting output files that end with '.report.json'
-v, --verbose
DEBUG
Enable debug output
-dbg, --debug
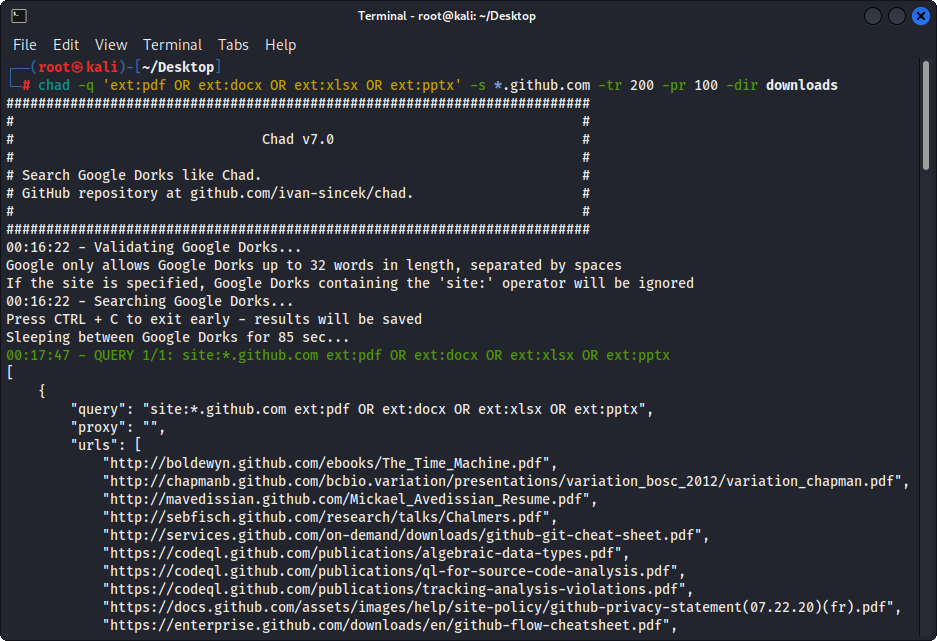
Figura 1 - (Chad) Download de arquivos - Único Google Dork
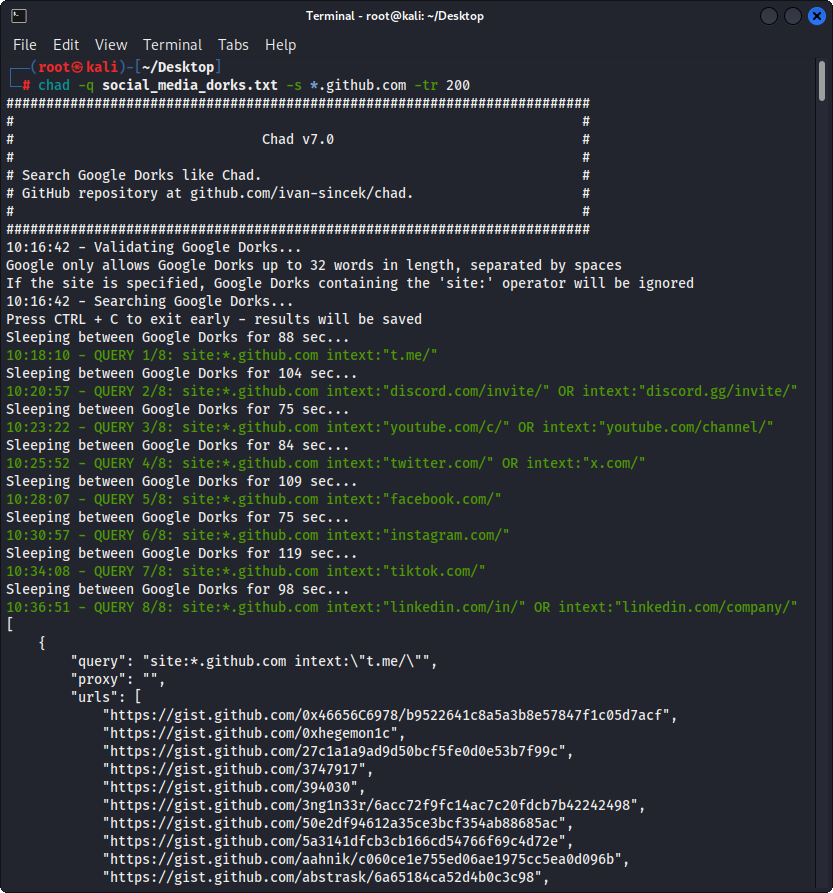
Figura 2 - (Chad) seqüestro de link quebrado - múltiplos Dorks do Google
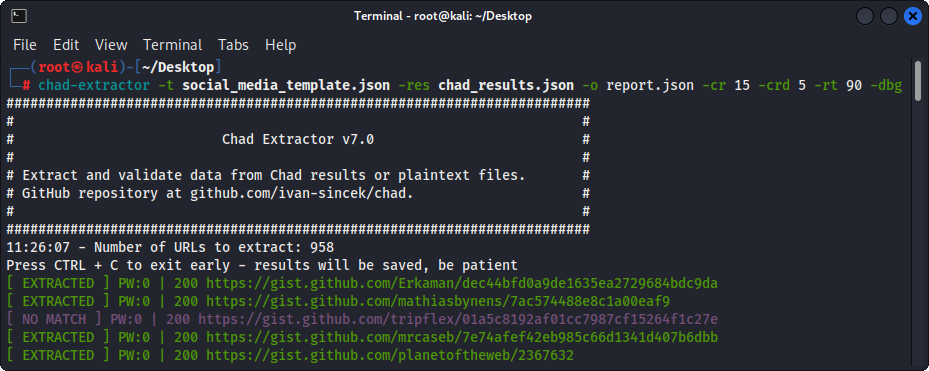
Figura 3 - Extrator (CHAD)
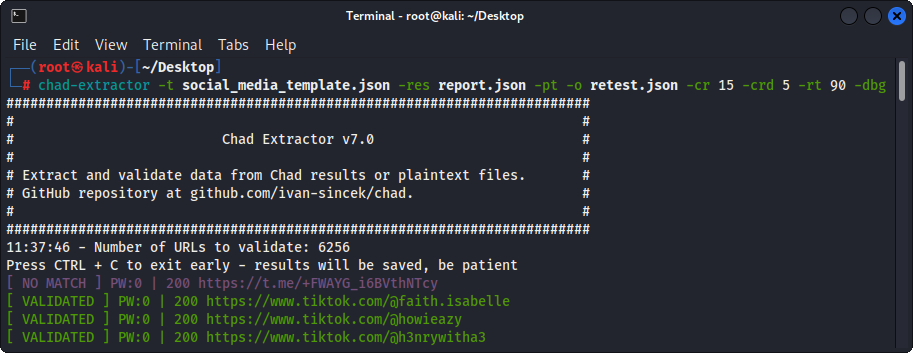
Figura 4 - Validação (extrator de Chade)


