chad
v7.0
Suchen Sie Google Dorks wie Chad. Basierend auf Ivan-Sincek/Nagooglesearch.
Getestet an Kali Linux V2024.2 (64-Bit).
Für Bildungszwecke gemacht. Ich hoffe es wird helfen!
Zukünftige Pläne:
linkedin-user . pip3 install --upgrade playwright
playwright install chromiumStellen Sie jedes Mal sicher, dass Sie Ihre Dramatiker-Abhängigkeit upgraden, um das Chrom erneut zu installieren. Andernfalls können Sie einen Fehler mit dem kopflosen Browser im Chad -Extraktor erhalten.
pip3 install --upgrade google-chadgit clone https://github.com/ivan-sincek/chad && cd chad
python3 -m pip install --upgrade build
python3 -m build
python3 -m pip install dist/google_chad-7.0-py3-none-any.whlchad -q ' intitle:"index of /" intext:"parent directory" ' Hast du Metagoofil gesagt?!
mkdir downloads
chad -q " ext:pdf OR ext:docx OR ext:xlsx OR ext:pptx " -s * .example.com -tr 200 -dir downloadsDie Datei -Download -Funktion von Chad basiert auf Python -Anfragen abhängig.
Chad Extractor ist ein leistungsstarkes Tool, das auf Scrapys Web -Crawler und dem Chrom -Browser von Dramiums -Headless basiert, der zum effizienten Kratzen von Webinhalten ausgelegt ist. Im Gegensatz zu Python fordert Python eine Abhängigkeit an, die JavaScript-Codierte HTML nicht rendern und durch Anti-BOT-Lösungen leicht blockiert werden kann.
In erster Linie wurde Chad Extractor so konzipiert, dass sie Daten aus Chad -Ergebnisdateien extrahieren und validieren. Es kann jedoch auch verwendet werden, um Daten aus Klartextdateien mithilfe der Option -pt zu extrahieren und zu validieren.
Wenn die Option -pt verwendet wird, werden Klartextdateien wie Serverantworten behandelt und die Extraktionslogik angewendet, gefolgt von Validierung. Dies ist auch nützlich, wenn Sie frühere Berichte des früheren Chad -Extraktors, z. B. mit -res report.json -pt -o retest.json , erneut testen möchten.
Bereiten Sie die Google Dorks als Social_Media_Dorks.txt -Datei vor:
intext:"t.me/"
intext:"discord.com/invite/" OR intext:"discord.gg/invite/"
intext:"youtube.com/c/" OR intext:"youtube.com/channel/"
intext:"twitter.com/" OR intext:"x.com/"
intext:"facebook.com/"
intext:"instagram.com/"
intext:"tiktok.com/"
intext:"linkedin.com/in/" OR intext:"linkedin.com/company/"
Bereiten Sie die Vorlage als Social_Media_Template.json -Datei vor:
{
"telegram" :{
"extract" : " t \ .me \ /(?:(?!(?:share)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https:// " ,
"validate" : " <meta property= " og:title " content= " Telegram: Contact .+? " > "
},
"discord" :{
"extract" : " discord \ .(?:com|gg) \ /invite \ /[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https:// " ,
"validate" : " Invite Invalid " ,
"validate_browser" : true ,
"validate_browser_wait" : 6
},
"youtube" :{
"extract" : " youtube \ .com \ /(?:c|channel) \ /[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " <iframe.+?src= "\ /error \ ?src=404.+? " > " ,
"validate_cookies" :{
"SOCS" : " CAESEwgDEgk2OTk3ODk2MzcaAmVuIAEaBgiAn5S6Bg "
}
},
"twitter" :{
"extract" : " (?<=(?<!pic \ .)twitter|(?<!pic \ .)x) \ .com \ /(?:(?!(?:[ \ w]{2} \ /)*(?:explore|hashtag|home|i|intent|library|media|personalization|privacy|search|share|tos|widgets \ .js)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://x " ,
"validate" : " This account doesn.?t exist " ,
"validate_browser" : true ,
"validate_cookies" :{
"night_mode" : " 2 "
}
},
"facebook" :{
"extract" : " facebook \ .com \ /(?:(?!(?:about|dialog|gaming|groups|public|sharer|share \ .php|terms \ .php)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " This (?:content|page) isn't available " ,
"validate_browser" : true
},
"instagram" :{
"extract" : " instagram \ .com \ /(?:(?!(?:about|accounts|ar|explore|p)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"extract_append" : " / " ,
"validate" : " Sorry, this page isn't available \ . " ,
"validate_browser" : true
},
"tiktok" :{
"extract" : " (?<!vt \ .)tiktok \ .com \ / \ @[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " Couldn't find this account "
},
"linkedin-company" :{
"extract" : " linkedin \ .com \ /company \ /[ \ w \ d \ . \ _ \ - \ + \ @ \ &]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " Page not found " ,
"validate_cookies" :{
"bcookie" : " v=2 " ,
"lang" : " v=2&lang=en-us "
}
},
"linkedin-user" :{
"extract" : " linkedin \ .com \ /in \ /[ \ w \ d \ . \ _ \ - \ + \ @ \ &]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " An exact match for .+ could not be found \ . "
}
} Stellen Sie sicher, dass Ihre regulären Ausdrücke nur eine Erfassungsgruppe zurückgeben, z. B. [1, 2, 3, 4] ; und kein Touple, z. B. [(1, 2), (3, 4)] .
Stellen Sie sicher, dass Sie den regulären Ausdruckspezifischen Symbolen in Ihrer Vorlagendatei ordnungsgemäß entgehen, z. B. entkommen Sie dem Punkt . als \. und vorwärts Schrägstrich / als \/ usw.
Alle regelmäßigen Ausdrucksuche sind unempfindlich.
Webinhalte, die aus den URLs in Chad -Ergebnisdateien abgerufen werden, werden gegen alle regulären Ausdrücke (definiert durch die extract ) in der Vorlagendatei abgestimmt, um so viele relevante Daten wie möglich zu finden.
Um Daten ohne Validierung zu extrahieren, lassen Sie die validate einfach nach Bedarf aus der Vorlagendatei weg.
| Umfang | Name | Typ | Erforderlich | Beschreibung |
|---|---|---|---|---|
| Extraktion | Extrakt | str | Ja | Abfrage des regulären Ausdrucks. |
| Extraktion | extract_prepend | str | NEIN | String, um sich auf alle extrahierten Daten vorzubereiten. |
| Extraktion | extract_append | str | NEIN | String, um an extrahierten Daten hinzugefügt zu werden. |
| Validierung | bestätigen | str | NEIN | Abfrage des regulären Ausdrucks. |
| Validierung | validate_browser | bool | NEIN | Ob Sie den kopflosen Browser verwenden oder nicht. |
| Validierung | validate_browser_wait | schweben | NEIN | Warten Sie die Zeit in Sekunden, bevor Sie den Inhalt von der Seite des kopflosen Browsers abrufen. |
| Validierung | validate_Headers | DICT [STR, STR] | NEIN | HTTP-Header im Schlüsselwertformat. Der Cookie -Header wird ignoriert. |
| Validierung | validate_cookies | DICT [STR, STR] | NEIN | HTTP Fordern Sie Cookies im Schlüsselwertformat an. |
Tabelle 1 - Vorlagenattribute
chad -q social_media_dorks.txt -s * .example.com -tr 200 -pr 100 -o results.json
chad-extractor -t social_media_template.json -res results.json -o report.json Bereiten Sie die Domänen / Subdomains als sites.txt -Datei vor, genauso wie Sie sie mit der site: Option in Google:
*.example.com
*.example.com -www
Laufen:
mkdir chad_results
IFS= $' n ' ; count=0 ; for site in $( cat sites.txt ) ; do count= $(( count + 1 )) ; echo " # ${count} | ${site} " ; chad -q social_media_dorks.txt -s " ${site} " -tr 200 -pr 100 -o " chad_results/results_ ${count} .json " ; done
chad-extractor -t social_media_template.json -res chad_results -o report.json -v Überprüfen Sie manuell, ob die gebrochenen URLs für soziale Medien in results[summary][validated] für die Übernahme anfällig sind:
{
"started_at" : " 2023-12-23 03:30:10 " ,
"ended_at" : " 2023-12-23 04:20:00 " ,
"summary" :{
"validated" :[
" https://t.me/does_not_exist " // might be vulnerable to takeover
],
"extracted" :[
" https://discord.com/invite/exists " ,
" https://t.me/does_not_exist " ,
" https://t.me/exists "
]
},
"failed" :{
"validation" :[],
"extraction" :[]
},
"full" :[
{
"url" : " https://example.com/about " ,
"results" :{
"telegram" :[
" https://t.me/does_not_exist " ,
" https://t.me/exists "
],
"discord" :[
" https://discord.com/invite/exists "
]
}
}
]
}Die Abkühlungszeit von Google kann von wenigen Stunden bis zu einem ganzen Tag reichen.
Um zu vermeiden, dass die Ratengrenzen von Google mit THAD erreicht werden, erhöhen Sie den minimalen und maximalen Schlaf zwischen Google -Abfragen und/oder Seiten. Oder verwenden Sie kostenlose oder kostenpflichtige Stellvertreter. Freie Proxys sind jedoch oft blockiert und instabil.
Um eine Liste mit kostenlosen Proxys herunterzuladen, rennen Sie:
curl -s ' https://proxylist.geonode.com/api/proxy-list?limit=50&page=1&sort_by=lastChecked&sort_type=desc ' -H ' Referer: https://proxylist.geonode.com/ ' | jq -r ' .data[] | "(.protocols[])://(.ip):(.port)" ' > proxies.txtWenn Sie Proxies verwenden, möchten Sie möglicherweise das Anfrage -Zeitüberschreitungszeitlimit erhöhen, da die Antworten längere Zeit benötigen.
Um zu vermeiden, dass die Ratenlimits auf Plattformen wie Instagram bei der Verwendung von Chad -Extraktor nicht erreicht werden, sollten Sie die Anzahl der gleichzeitigen Anforderungen pro Domäne verringern und den Schlaf und die Wartezeiten erhöhen.
Chad v7.0 ( github.com/ivan-sincek/chad )
Usage: chad -q queries [-s site ] [-x proxies ] [-o out ]
Example: chad -q queries.txt [-s *.example.com] [-x proxies.txt] [-o results.json]
DESCRIPTION
Search Google Dorks like Chad
QUERIES
File containing Google Dorks or a single query to use
-q, --queries = queries.txt | intext:password | "ext:tar OR ext:zip" | etc.
SITE
Domain[s] to search
-s, --site = example.com | sub.example.com | *.example.com | "*.example.com -www" | etc.
TIME
Get results not older than the specified time in months
-t, --time = 6 | 12 | 24 | etc.
TOTAL RESULTS
Total number of unique results
Default: 100
-tr, --total-results = 200 | etc.
PAGE RESULTS
Number of results per page - capped at 100 by Google
Default: randint(70, 100)
-pr, --page-results = 50 | etc.
MINIMUM QUERIES
Minimum sleep time in seconds between Google queries
Default: 75
-min-q, --minimum-queries = 120 | etc.
MAXIMUM QUERIES
Maximum sleep time between Google queries
Default: minimum + 50
-max-q, --maximum-queries = 180 | etc.
MINIMUM PAGES
Minimum sleep time between Google pages
Default: 15
-min-p, --minimum-pages = 30 | etc.
MAXIMUM PAGES
Maximum sleep time between Google pages
Default: minimum + 10
-max-p, --maximum-pages = 60 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random(-all) | curl/3.30.1 | etc.
PROXIES
File containing web proxies or a single web proxy to use
-x, --proxies = proxies.txt | http://127.0.0.1:8080 | etc.
DIRECTORY
Downloads directory
All downloaded files will be saved in this directory
-dir, --directory = downloads | etc.
THREADS
Number of files to download in parallel
Default: 5
-th, --threads = 20 | etc.
OUT
Output file
-o, --out = results.json | etc.
NO SLEEP ON START
Disable the safety feature to prevent triggering rate limits by accident
-nsos, --no-sleep-on-start
DEBUG
Enable debug output
-dbg, --debug
Chad Extractor v7.0 ( github.com/ivan-sincek/chad )
Usage: chad-extractor -t template -res results -o out [-s sleep] [-rs random-sleep]
Example: chad-extractor -t template.json -res chad_results -o report.json [-s 1.5 ] [-rs ]
DESCRIPTION
Extract and validate data from Chad results or plaintext files
TEMPLATE
File containing extraction and validation details
-t, --template = template.json | etc.
RESULTS
Directory containing Chad results or plaintext files, or a single file
If a directory is specified, files ending with '.report.json' will be ignored
-res, --results = chad_results | results.json | urls.txt | etc.
PLAINTEXT
Treat all the results as plaintext files / server responses
-pt, --plaintext
EXCLUDES
File containing regular expressions or a single regular expression to exclude content from the page
Applies only for extraction
-e, --excludes = regexes.txt | "<div id="seo">.+?</div>" | etc.
PLAYWRIGHT
Use Playwright's headless browser
Applies only for extraction
-p, --playwright
PLAYWRIGHT WAIT
Wait time in seconds before fetching the page content
Applies only for extraction
-pw, --playwright-wait = 0.5 | 2 | 4 | etc.
CONCURRENT REQUESTS
Number of concurrent requests
Default: 15
-cr, --concurrent-requests = 30 | 45 | etc.
CONCURRENT REQUESTS PER DOMAIN
Number of concurrent requests per domain
Default: 5
-crd, --concurrent-requests-domain = 10 | 15 | etc.
SLEEP
Sleep time in seconds between two consecutive requests to the same domain
-s, --sleep = 1.5 | 3 | etc.
RANDOM SLEEP
Randomize the sleep time between requests to vary between '0.5 * sleep' and '1.5 * sleep'
-rs, --random-sleep
AUTO THROTTLE
Auto throttle concurrent requests based on the load and latency
Sleep time is still respected
-at, --auto-throttle = 0.5 | 10 | 15 | 45 | etc.
RETRIES
Number of retries per URL
Default: 2
-r, --retries = 0 | 4 | etc.
REQUEST TIMEOUT
Request timeout in seconds
Default: 60
-rt, --request-timeout = 30 | 90 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random(-all) | curl/3.30.1 | etc.
PROXY
Web proxy to use
-x, --proxy = http://127.0.0.1:8080 | etc.
OUT
Output file
-o, --out = report.json | etc.
VERBOSE
Create additional supporting output files that end with '.report.json'
-v, --verbose
DEBUG
Enable debug output
-dbg, --debug
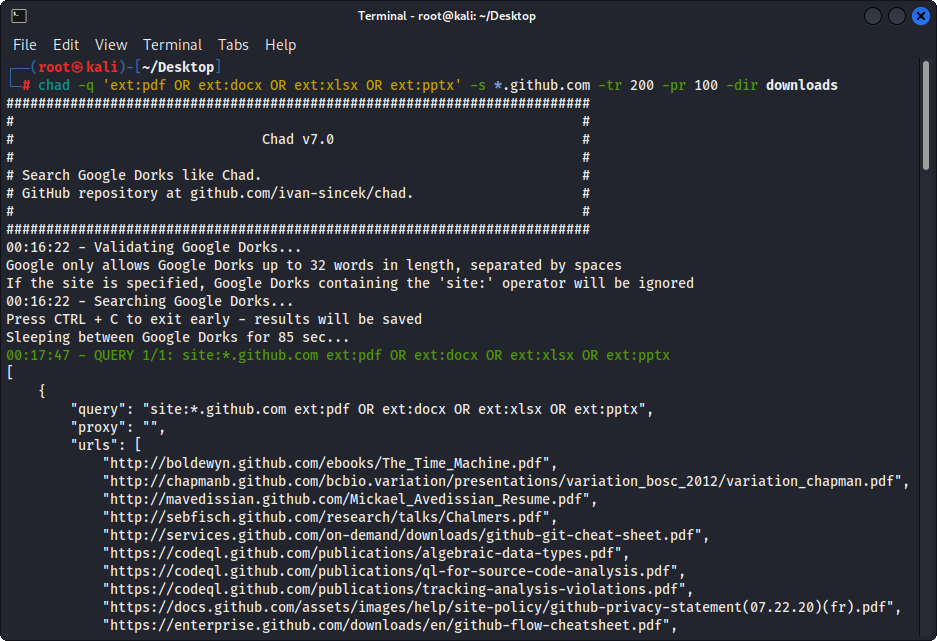
Abbildung 1 - (CHAD) Datei Download - Single Google Dork
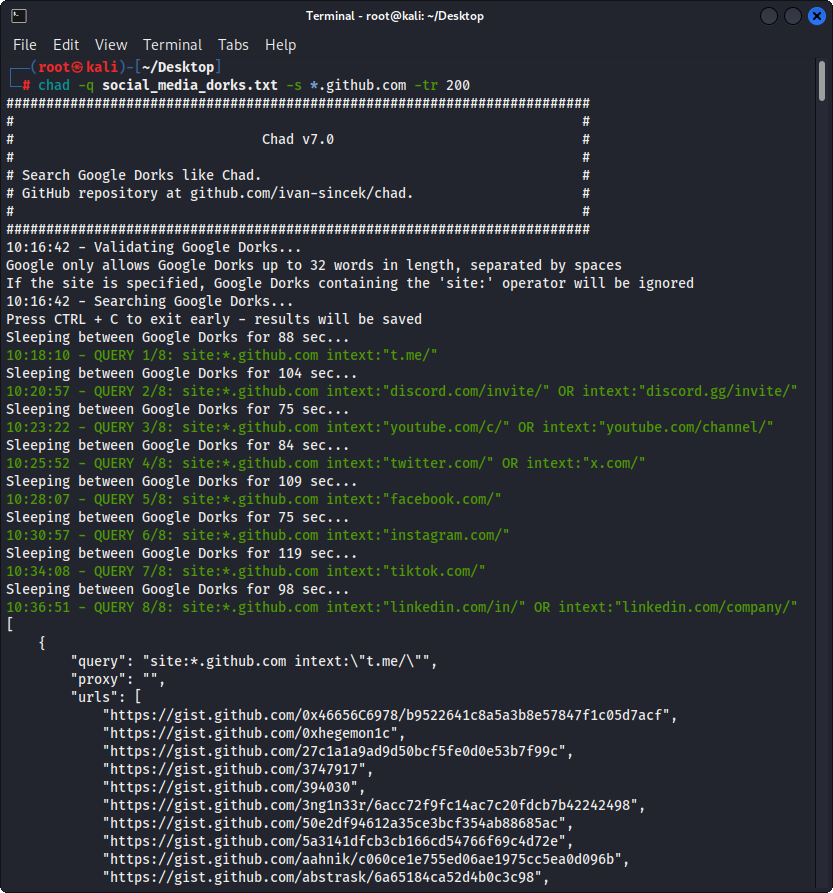
Abbildung 2 - (THAD) CLAUT LINK HIJACKING - Mehrere Google Dorks
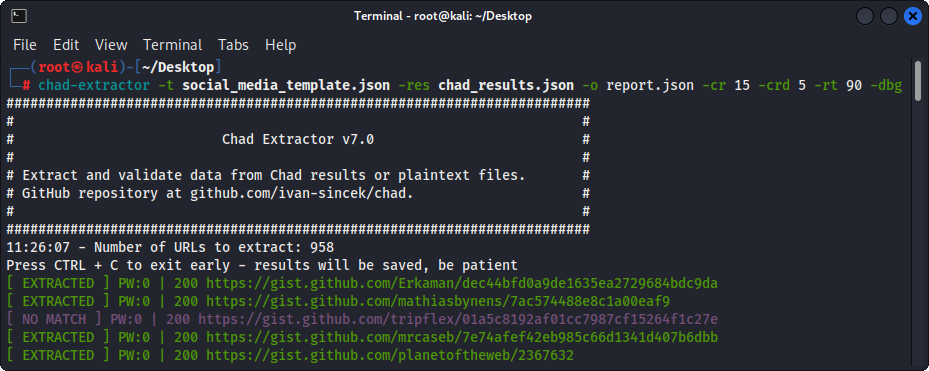
Abbildung 3 - (THAD -Extraktor) Extraktion
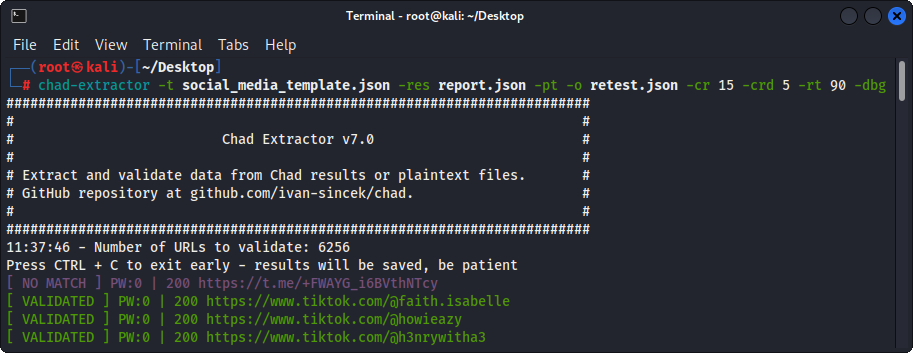
Abbildung 4 - (THAD -Extraktor) Validierung


