chad
v7.0
Cari Google Dorks seperti Chad. Berdasarkan Ivan-SinceK/Nagooglesearch.
Diuji pada Kali Linux V2024.2 (64-bit).
Dibuat untuk tujuan pendidikan. Saya berharap ini akan membantu!
Rencana Masa Depan:
linkedin-user . pip3 install --upgrade playwright
playwright install chromiumPastikan setiap kali Anda meningkatkan ketergantungan penulis naskah Anda untuk menginstal ulang kromium; Jika tidak, Anda mungkin mendapatkan kesalahan menggunakan browser tanpa kepala di Chad Extractor.
pip3 install --upgrade google-chadgit clone https://github.com/ivan-sincek/chad && cd chad
python3 -m pip install --upgrade build
python3 -m build
python3 -m pip install dist/google_chad-7.0-py3-none-any.whlchad -q ' intitle:"index of /" intext:"parent directory" ' Apakah Anda mengatakan metagoofil?!
mkdir downloads
chad -q " ext:pdf OR ext:docx OR ext:xlsx OR ext:pptx " -s * .example.com -tr 200 -dir downloadsFitur Unduh File Chad didasarkan pada ketergantungan permintaan Python.
Chad Extractor adalah alat yang ampuh berdasarkan peritam Web Scrapy dan browser Chromium Headless, yang dirancang untuk mengikis konten web secara efisien; Tidak seperti ketergantungan permintaan Python, yang tidak dapat membuat HTML yang dikodekan JavaScript dan mudah diblokir oleh solusi anti-bot.
Terutama, chad extractor dirancang untuk mengekstrak dan memvalidasi data dari file hasil chad. Namun, ini juga dapat digunakan untuk mengekstrak dan memvalidasi data dari file plaintext dengan menggunakan opsi -pt .
Jika opsi -pt digunakan, file plaintext akan diperlakukan seperti respons server, dan logika ekstraksi akan diterapkan, diikuti oleh validasi. Ini juga berguna jika Anda ingin menguji ulang laporan Chad Extractor sebelumnya, misalnya, dengan menggunakan -res report.json -pt -o retest.json .
Siapkan file Google Dorks sebagai Social_Media_dorks.txt:
intext:"t.me/"
intext:"discord.com/invite/" OR intext:"discord.gg/invite/"
intext:"youtube.com/c/" OR intext:"youtube.com/channel/"
intext:"twitter.com/" OR intext:"x.com/"
intext:"facebook.com/"
intext:"instagram.com/"
intext:"tiktok.com/"
intext:"linkedin.com/in/" OR intext:"linkedin.com/company/"
Siapkan templat sebagai file social_media_template.json:
{
"telegram" :{
"extract" : " t \ .me \ /(?:(?!(?:share)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https:// " ,
"validate" : " <meta property= " og:title " content= " Telegram: Contact .+? " > "
},
"discord" :{
"extract" : " discord \ .(?:com|gg) \ /invite \ /[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https:// " ,
"validate" : " Invite Invalid " ,
"validate_browser" : true ,
"validate_browser_wait" : 6
},
"youtube" :{
"extract" : " youtube \ .com \ /(?:c|channel) \ /[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " <iframe.+?src= "\ /error \ ?src=404.+? " > " ,
"validate_cookies" :{
"SOCS" : " CAESEwgDEgk2OTk3ODk2MzcaAmVuIAEaBgiAn5S6Bg "
}
},
"twitter" :{
"extract" : " (?<=(?<!pic \ .)twitter|(?<!pic \ .)x) \ .com \ /(?:(?!(?:[ \ w]{2} \ /)*(?:explore|hashtag|home|i|intent|library|media|personalization|privacy|search|share|tos|widgets \ .js)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://x " ,
"validate" : " This account doesn.?t exist " ,
"validate_browser" : true ,
"validate_cookies" :{
"night_mode" : " 2 "
}
},
"facebook" :{
"extract" : " facebook \ .com \ /(?:(?!(?:about|dialog|gaming|groups|public|sharer|share \ .php|terms \ .php)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " This (?:content|page) isn't available " ,
"validate_browser" : true
},
"instagram" :{
"extract" : " instagram \ .com \ /(?:(?!(?:about|accounts|ar|explore|p)(?:(?: \ /| \ ?| \\ | " | \ <)*$|(?: \ /| \ ?| \\ | \" | \ <)[ \ s \ S]))[ \ w \ d \ . \ _ \ - \ + \ @]+)(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"extract_append" : " / " ,
"validate" : " Sorry, this page isn't available \ . " ,
"validate_browser" : true
},
"tiktok" :{
"extract" : " (?<!vt \ .)tiktok \ .com \ / \ @[ \ w \ d \ . \ _ \ - \ + \ @]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " Couldn't find this account "
},
"linkedin-company" :{
"extract" : " linkedin \ .com \ /company \ /[ \ w \ d \ . \ _ \ - \ + \ @ \ &]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " Page not found " ,
"validate_cookies" :{
"bcookie" : " v=2 " ,
"lang" : " v=2&lang=en-us "
}
},
"linkedin-user" :{
"extract" : " linkedin \ .com \ /in \ /[ \ w \ d \ . \ _ \ - \ + \ @ \ &]+(?<! \ .) " ,
"extract_prepend" : " https://www. " ,
"validate" : " An exact match for .+ could not be found \ . "
}
} Pastikan ekspresi reguler Anda hanya mengembalikan satu kelompok penangkap, misalnya, [1, 2, 3, 4] ; dan bukan seringkali, misalnya, [(1, 2), (3, 4)] .
Pastikan untuk melarikan diri dengan benar simbol spesifik ekspresi reguler dalam file template Anda, misalnya, pastikan untuk menghindari Dot . sebagai \. , dan maju slash / as \/ , dll.
Semua pencarian ekspresi reguler tidak sensitif.
Konten web yang diambil dari URL di file hasil Chad akan dicocokkan dengan semua ekspresi reguler (ditentukan oleh atribut extract ) dalam file template untuk menemukan data yang relevan sebanyak mungkin.
Untuk mengekstrak data tanpa validasi, cukup hilangkan atribut validate dari file templat yang diperlukan.
| Cakupan | Nama | Jenis | Diperlukan | Keterangan |
|---|---|---|---|---|
| ekstraksi | ekstrak | str | Ya | Kueri ekspresi reguler. |
| ekstraksi | ekstrak_prepend | str | TIDAK | String untuk diatur untuk semua data yang diekstraksi. |
| ekstraksi | ekstrak_append | str | TIDAK | String untuk ditambahkan ke data yang diekstraksi. |
| validasi | mengesahkan | str | TIDAK | Kueri ekspresi reguler. |
| validasi | Validate_Browser | bool | TIDAK | Apakah akan menggunakan browser tanpa kepala atau tidak. |
| validasi | validate_browser_wait | mengambang | TIDAK | Tunggu waktu dalam hitungan detik sebelum mengambil konten dari halaman browser tanpa kepala. |
| validasi | Validasi_Headers | Dict [str, str] | TIDAK | Header permintaan http dalam format nilai kunci. Header Cookie diabaikan. |
| validasi | validate_cookies | Dict [str, str] | TIDAK | HTTP meminta cookie dalam format nilai kunci. |
Tabel 1 - Atribut Template
chad -q social_media_dorks.txt -s * .example.com -tr 200 -pr 100 -o results.json
chad-extractor -t social_media_template.json -res results.json -o report.json Siapkan Domain / Subdomain sebagai File sites.txt , dengan cara yang sama Anda akan menggunakannya dengan site: Opsi di Google:
*.example.com
*.example.com -www
Berlari:
mkdir chad_results
IFS= $' n ' ; count=0 ; for site in $( cat sites.txt ) ; do count= $(( count + 1 )) ; echo " # ${count} | ${site} " ; chad -q social_media_dorks.txt -s " ${site} " -tr 200 -pr 100 -o " chad_results/results_ ${count} .json " ; done
chad-extractor -t social_media_template.json -res chad_results -o report.json -v Verifikasi secara manual jika URL media sosial yang rusak dalam results[summary][validated] rentan terhadap pengambilalihan:
{
"started_at" : " 2023-12-23 03:30:10 " ,
"ended_at" : " 2023-12-23 04:20:00 " ,
"summary" :{
"validated" :[
" https://t.me/does_not_exist " // might be vulnerable to takeover
],
"extracted" :[
" https://discord.com/invite/exists " ,
" https://t.me/does_not_exist " ,
" https://t.me/exists "
]
},
"failed" :{
"validation" :[],
"extraction" :[]
},
"full" :[
{
"url" : " https://example.com/about " ,
"results" :{
"telegram" :[
" https://t.me/does_not_exist " ,
" https://t.me/exists "
],
"discord" :[
" https://discord.com/invite/exists "
]
}
}
]
}Periode pendinginan Google dapat berkisar dari beberapa jam hingga satu hari penuh.
Untuk menghindari mencapai batas laju Google dengan Chad, tingkatkan tidur minimum dan maksimum antara kueri Google dan/atau halaman; atau gunakan proxy gratis atau berbayar. Namun, proxy gratis sering diblokir dan tidak stabil.
Untuk mengunduh daftar proxy gratis, jalankan:
curl -s ' https://proxylist.geonode.com/api/proxy-list?limit=50&page=1&sort_by=lastChecked&sort_type=desc ' -H ' Referer: https://proxylist.geonode.com/ ' | jq -r ' .data[] | "(.protocols[])://(.ip):(.port)" ' > proxies.txtJika Anda menggunakan proxy, Anda mungkin ingin meningkatkan batas waktu permintaan, karena tanggapan akan membutuhkan waktu lebih lama untuk tiba.
Selain itu, untuk menghindari batasan tingkat pada platform seperti Instagram saat menggunakan Chad Extractor, pertimbangkan mengurangi jumlah permintaan bersamaan per domain dan meningkatkan waktu tidur dan tunggu.
Chad v7.0 ( github.com/ivan-sincek/chad )
Usage: chad -q queries [-s site ] [-x proxies ] [-o out ]
Example: chad -q queries.txt [-s *.example.com] [-x proxies.txt] [-o results.json]
DESCRIPTION
Search Google Dorks like Chad
QUERIES
File containing Google Dorks or a single query to use
-q, --queries = queries.txt | intext:password | "ext:tar OR ext:zip" | etc.
SITE
Domain[s] to search
-s, --site = example.com | sub.example.com | *.example.com | "*.example.com -www" | etc.
TIME
Get results not older than the specified time in months
-t, --time = 6 | 12 | 24 | etc.
TOTAL RESULTS
Total number of unique results
Default: 100
-tr, --total-results = 200 | etc.
PAGE RESULTS
Number of results per page - capped at 100 by Google
Default: randint(70, 100)
-pr, --page-results = 50 | etc.
MINIMUM QUERIES
Minimum sleep time in seconds between Google queries
Default: 75
-min-q, --minimum-queries = 120 | etc.
MAXIMUM QUERIES
Maximum sleep time between Google queries
Default: minimum + 50
-max-q, --maximum-queries = 180 | etc.
MINIMUM PAGES
Minimum sleep time between Google pages
Default: 15
-min-p, --minimum-pages = 30 | etc.
MAXIMUM PAGES
Maximum sleep time between Google pages
Default: minimum + 10
-max-p, --maximum-pages = 60 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random(-all) | curl/3.30.1 | etc.
PROXIES
File containing web proxies or a single web proxy to use
-x, --proxies = proxies.txt | http://127.0.0.1:8080 | etc.
DIRECTORY
Downloads directory
All downloaded files will be saved in this directory
-dir, --directory = downloads | etc.
THREADS
Number of files to download in parallel
Default: 5
-th, --threads = 20 | etc.
OUT
Output file
-o, --out = results.json | etc.
NO SLEEP ON START
Disable the safety feature to prevent triggering rate limits by accident
-nsos, --no-sleep-on-start
DEBUG
Enable debug output
-dbg, --debug
Chad Extractor v7.0 ( github.com/ivan-sincek/chad )
Usage: chad-extractor -t template -res results -o out [-s sleep] [-rs random-sleep]
Example: chad-extractor -t template.json -res chad_results -o report.json [-s 1.5 ] [-rs ]
DESCRIPTION
Extract and validate data from Chad results or plaintext files
TEMPLATE
File containing extraction and validation details
-t, --template = template.json | etc.
RESULTS
Directory containing Chad results or plaintext files, or a single file
If a directory is specified, files ending with '.report.json' will be ignored
-res, --results = chad_results | results.json | urls.txt | etc.
PLAINTEXT
Treat all the results as plaintext files / server responses
-pt, --plaintext
EXCLUDES
File containing regular expressions or a single regular expression to exclude content from the page
Applies only for extraction
-e, --excludes = regexes.txt | "<div id="seo">.+?</div>" | etc.
PLAYWRIGHT
Use Playwright's headless browser
Applies only for extraction
-p, --playwright
PLAYWRIGHT WAIT
Wait time in seconds before fetching the page content
Applies only for extraction
-pw, --playwright-wait = 0.5 | 2 | 4 | etc.
CONCURRENT REQUESTS
Number of concurrent requests
Default: 15
-cr, --concurrent-requests = 30 | 45 | etc.
CONCURRENT REQUESTS PER DOMAIN
Number of concurrent requests per domain
Default: 5
-crd, --concurrent-requests-domain = 10 | 15 | etc.
SLEEP
Sleep time in seconds between two consecutive requests to the same domain
-s, --sleep = 1.5 | 3 | etc.
RANDOM SLEEP
Randomize the sleep time between requests to vary between '0.5 * sleep' and '1.5 * sleep'
-rs, --random-sleep
AUTO THROTTLE
Auto throttle concurrent requests based on the load and latency
Sleep time is still respected
-at, --auto-throttle = 0.5 | 10 | 15 | 45 | etc.
RETRIES
Number of retries per URL
Default: 2
-r, --retries = 0 | 4 | etc.
REQUEST TIMEOUT
Request timeout in seconds
Default: 60
-rt, --request-timeout = 30 | 90 | etc.
USER AGENTS
User agents to use
Default: random-all
-a, --user-agents = user_agents.txt | random(-all) | curl/3.30.1 | etc.
PROXY
Web proxy to use
-x, --proxy = http://127.0.0.1:8080 | etc.
OUT
Output file
-o, --out = report.json | etc.
VERBOSE
Create additional supporting output files that end with '.report.json'
-v, --verbose
DEBUG
Enable debug output
-dbg, --debug
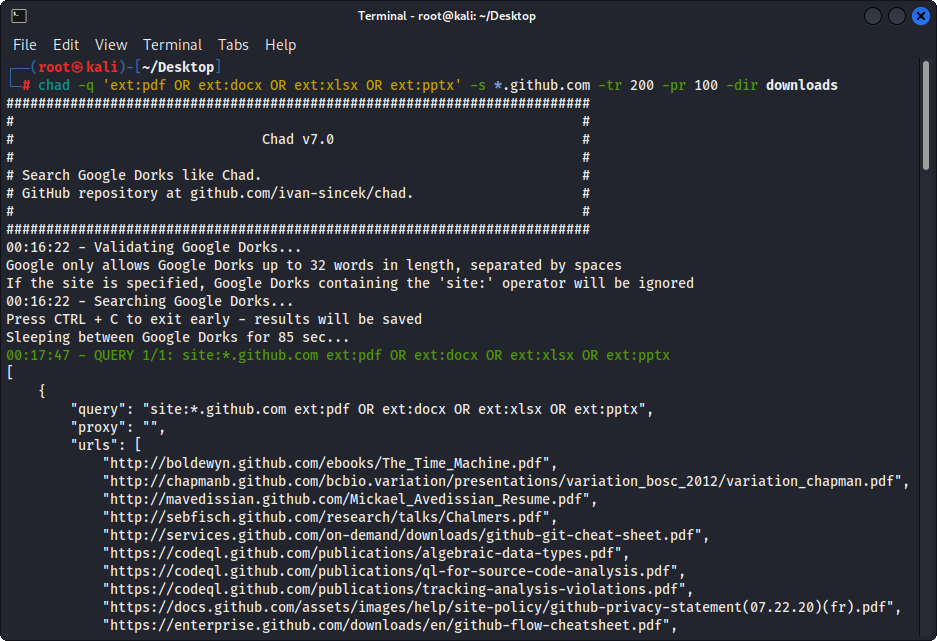
Gambar 1 - (Chad) Unduh File - Google Dork tunggal
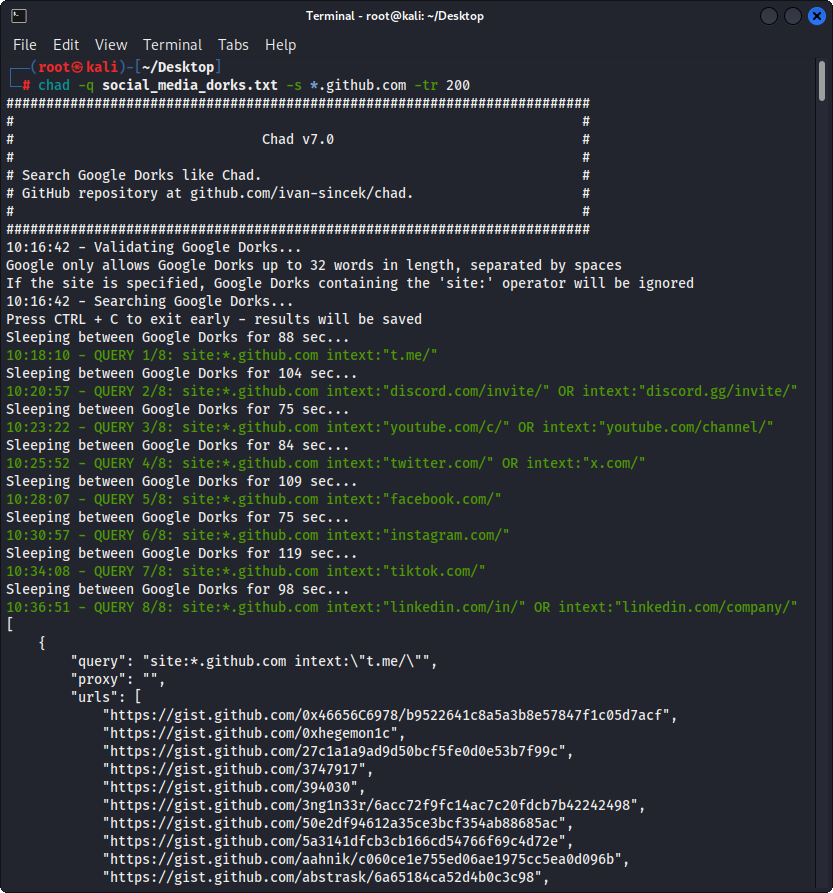
Gambar 2 - (Chad) Pembajakan Tautan Patah - Beberapa Google Dorks
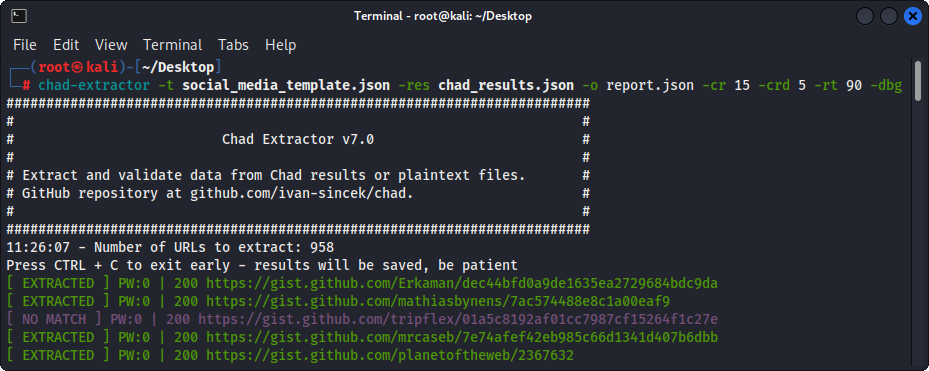
Gambar 3 - (Chad Extractor) Ekstraksi
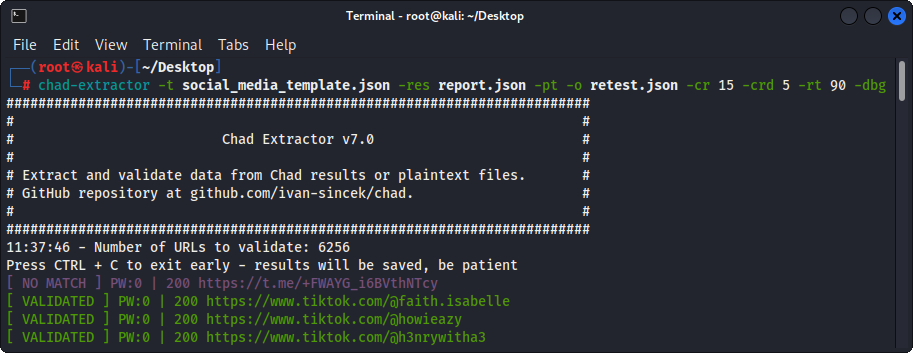
Gambar 4 - (Chad Extractor) Validasi


