vector vein
v0.3.3
Inglês | 简体中文 | 日本語
Crie seu fluxo de trabalho de automação com o poder da IA e sua base de conhecimento pessoal.
Crie fluxos de trabalho poderosos com apenas arrastar e soltar, sem qualquer programação.
O Vectorvein é um software de fluxo de trabalho de IA sem código inspirado em Langchain e Langflow, projetado para combinar os poderosos recursos de grandes modelos de linguagem e permitir que os usuários obtenham facilmente fluxos de trabalho inteligentes e automatizados para várias tarefas diárias.
Você pode experimentar a versão online do Vectorvein aqui, sem a necessidade de baixar ou instalar.
Site oficial documentação online
Após o download do Vectorvein do lançamento, o programa criará uma pasta "dados" no diretório de instalação para armazenar o banco de dados e os recursos estáticos do arquivo.
O Vectorvein é construído usando o PywebView, com base no kernel do WebView2, então você precisa instalar o tempo de execução do WebView2. Se o software não puder ser aberto, pode ser necessário fazer o download do tempo de execução do WebView2 manualmente em https://developer.microsoft.com/en-us/microsoft-edge/webview2/
Importante
Se o software não puder ser aberto após a descompressão, verifique se o pacote compactado baixado. O arquivo .zip está bloqueado. Você pode resolver esse problema clicando com o botão direito do mouse no pacote compactado e selecionando "desbloqueio".
A maioria dos fluxos de trabalho e agentes do software envolve o uso de modelos de idiomas grandes de IA; portanto, você deve pelo menos fornecer uma configuração utilizável para um modelo de idioma grande. Para fluxos de trabalho, você pode ver quais modelos de idiomas grandes estão sendo usados na interface, conforme mostrado na imagem abaixo.

A partir da v0.2.10, o Vectorpulse separa os pontos de extremidade da API e as grandes configurações do modelo de linguagem, permitindo vários pontos de extremidade da API para o mesmo modelo de linguagem grande.
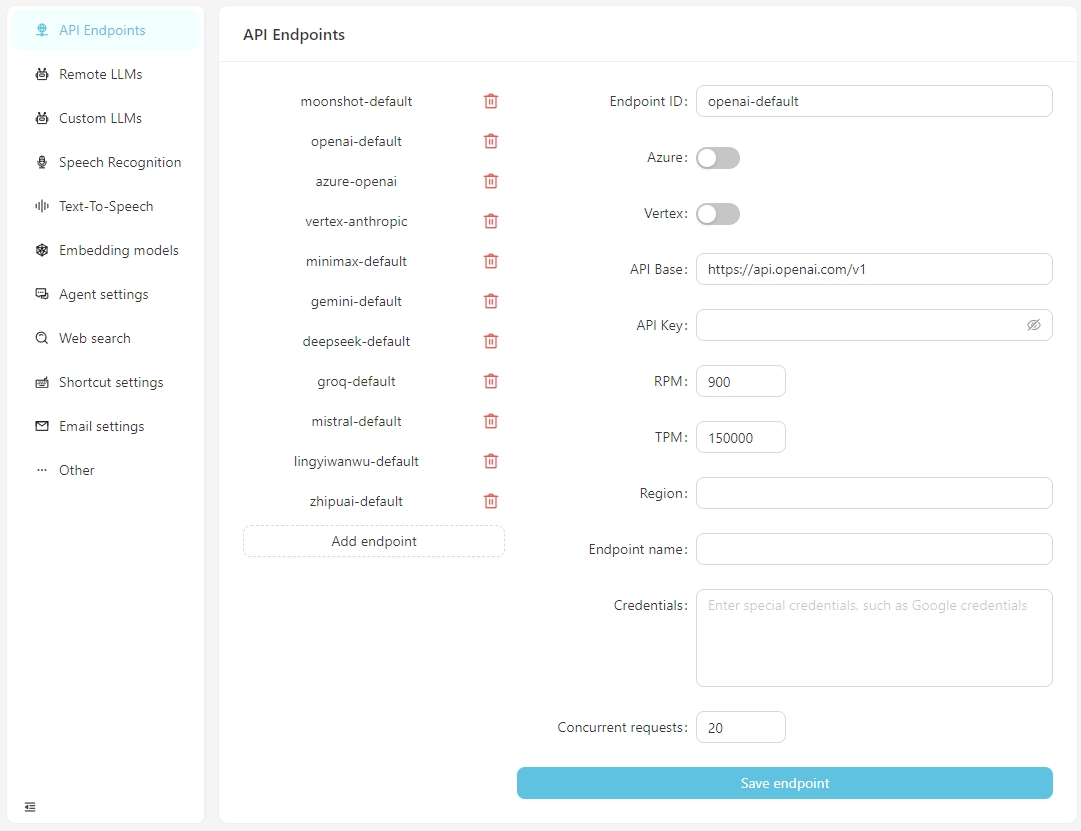
Depois que o software é aberto normalmente, clique no botão Abrir Configurações e você pode configurar as informações para cada terminal da API, conforme necessário ou adicionar pontos de extremidade personalizados da API. Atualmente, os pontos de extremidade da API suportam interfaces compatíveis com o OpenAI, que podem ser conectadas a serviços em execução localmente, como LM-Studio, Ollama, Vllm, etc.
A base da API para LM-Studio é tipicamente http: // localhost: 1234/v1/
A base da API para Ollama é tipicamente http: // localhost: 11434/v1/
Configure as informações específicas para cada modelo na guia Remote LLMs .
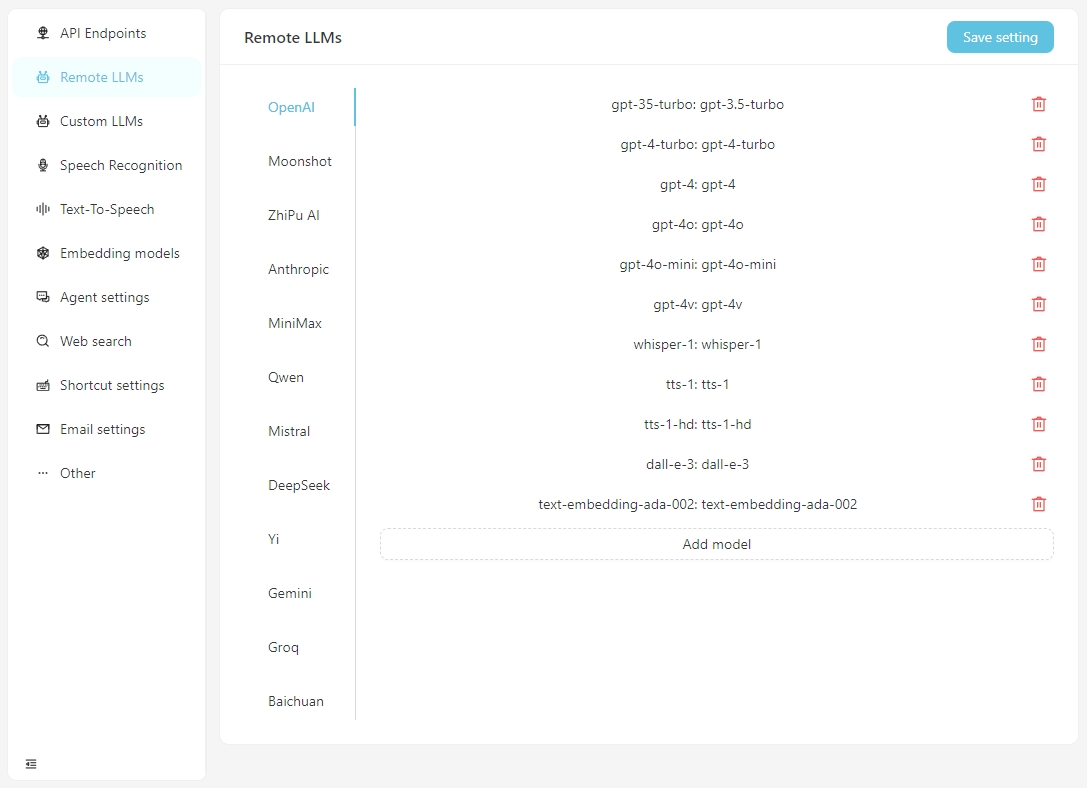
Clique em qualquer modelo para definir sua configuração específica, como mostrado abaixo.
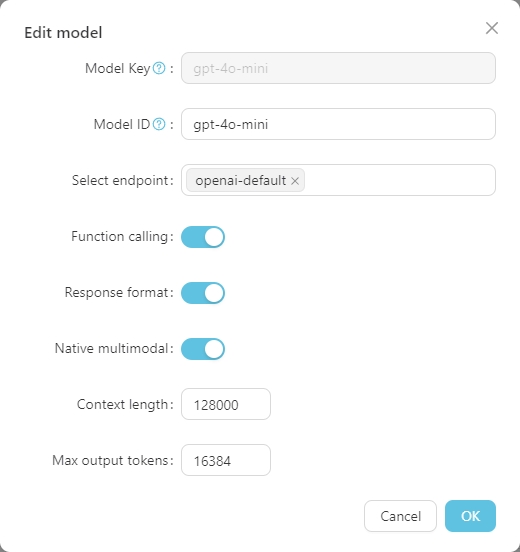
A Model Key é o nome padrão do modelo grande e geralmente não precisa ser ajustado. O Model ID é o nome usado durante a implantação real, que geralmente corresponde à Model Key . No entanto, em implantações como o Azure OpenAI, o Model ID é definido pelo usuário e, portanto, precisa ser ajustado de acordo com a situação real.
Se estiver usando um modelo de linguagem grande personalizado, preencha as informações de configuração do modelo personalizado na guia Custom LLMs . Atualmente, as interfaces compatíveis com o OpenAI são suportadas, como LM-Studio, Ollama, Vllm, etc.
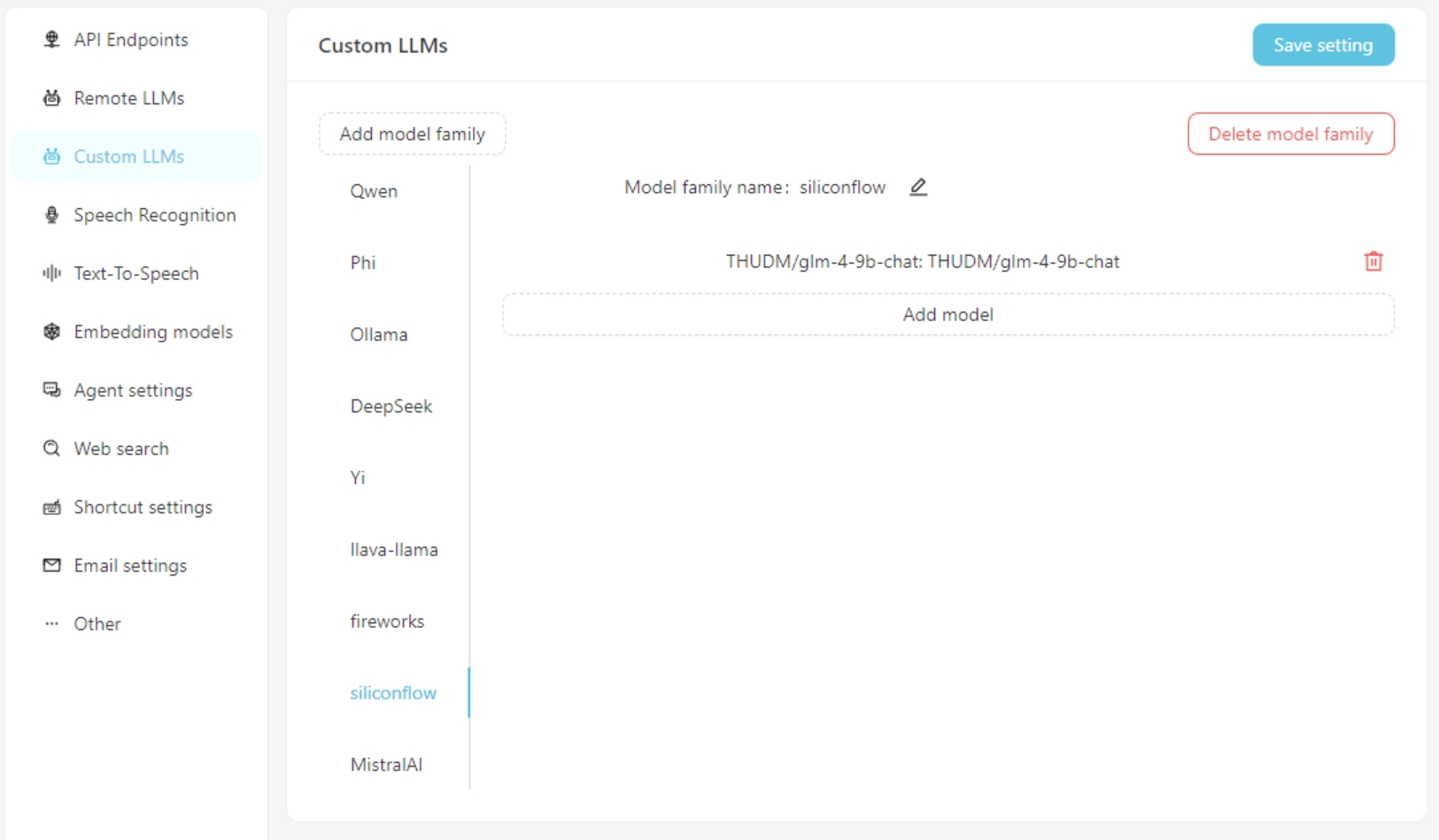
Primeiro, adicione uma família de modelos personalizados e adicione um modelo personalizado. Não se esqueça de clicar no botão Save Settings .
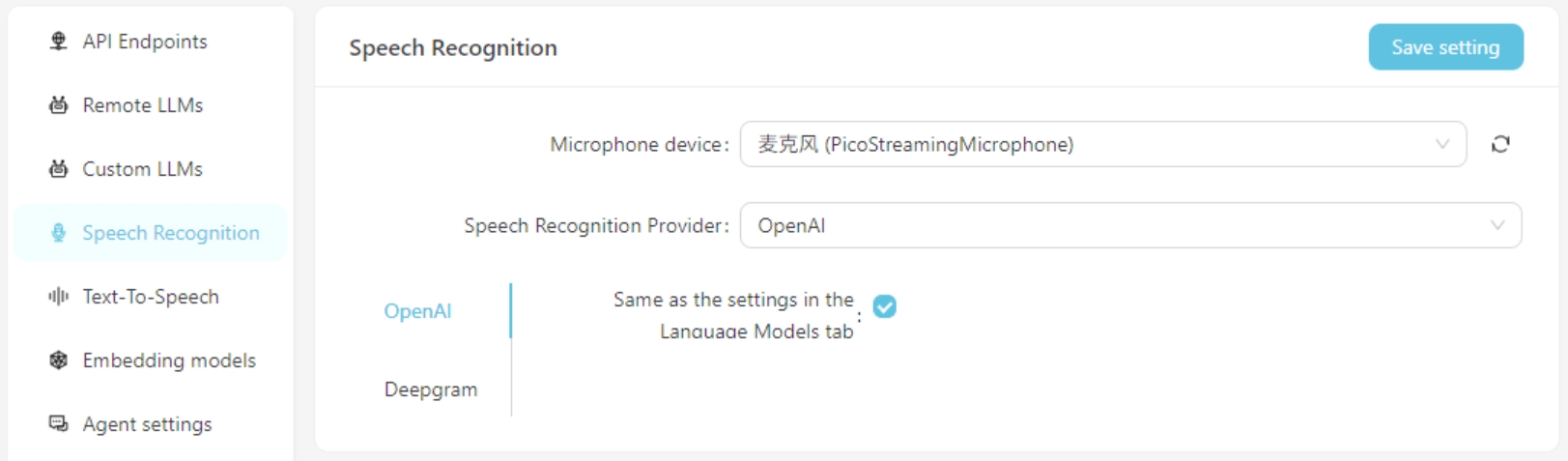
Atualmente, os serviços de reconhecimento de fala do OpenAI/Deepgram são suportados. Para serviços OpenAI, você pode usar a mesma configuração que o modelo de idioma grande ou configurar um serviço de reconhecimento de fala compatível com a API do OpenAI (como o GROQ).
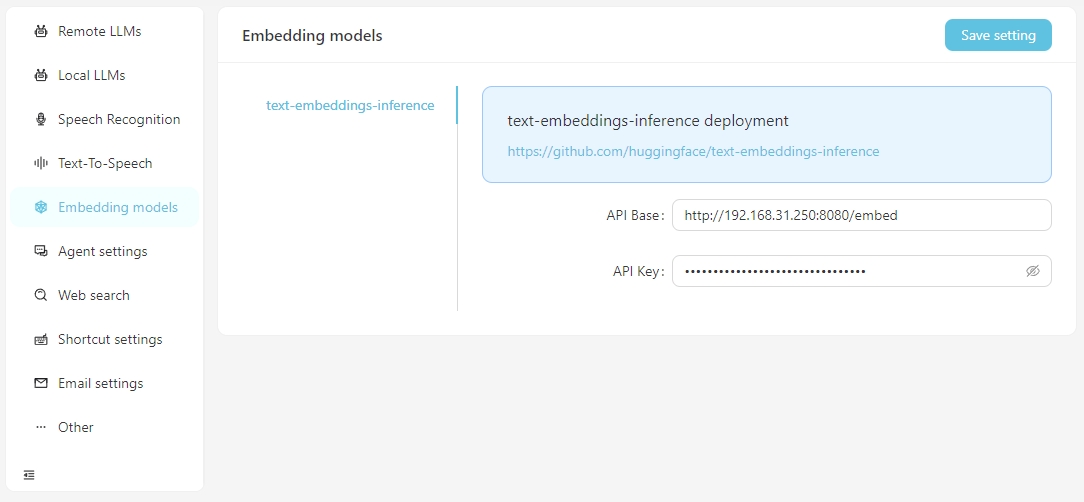
Quando você precisa executar pesquisas vetoriais usando dados vetoriais, você tem a opção de usar serviços de incorporação fornecidos pelo OpenAI ou configurar serviços locais de incorporação nas configurações Embedding Model . Atualmente, os serviços de incorporação local suportados exigem que você configure a inferência de incorporação de texto.
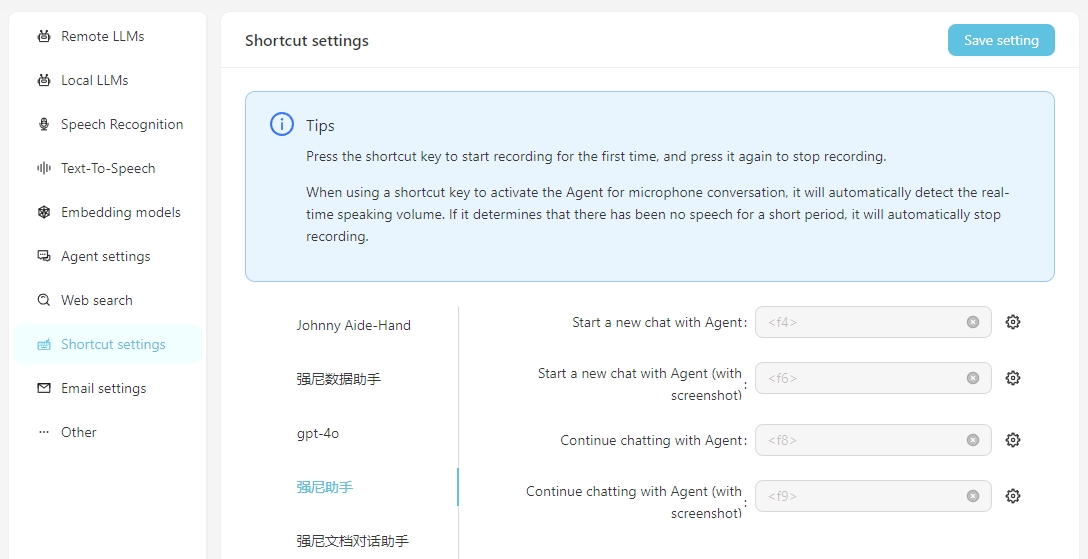
Para facilitar o uso diário, você pode configurar os atalhos para iniciar rapidamente conversas de voz com o agente. Ao lançar o atalho, você pode interagir diretamente com o agente por meio do reconhecimento de fala. É importante garantir que o serviço de reconhecimento de fala seja configurado corretamente com antecedência.
Inclua a captura de tela significa que, ao iniciar a conversa, uma captura de tela da tela será levada e enviada como um anexo à conversa.
Para usar sua própria API de difusão estável local, você precisa adicionar o parâmetro --api ao item de inicialização do webui-user.bat, ou seja,
set COMMANDLINE_ARGS=--api
Um fluxo de trabalho representa um processo de tarefa de trabalho, incluindo entrada, saída e como a entrada é processada para atingir o resultado da saída.
Exemplos:
Fluxo de trabalho de tradução : a entrada é um documento em inglês e a saída também é um documento do Word. Você pode projetar um fluxo de trabalho para traduzir o documento chinês de entrada e gerar uma saída de documento chinês.
Fluxo de trabalho do mapa mental : se a saída do fluxo de trabalho de tradução for alterada para um mapa mental, você poderá obter um fluxo de trabalho que lê um documento do Word em inglês e o resume em um mapa mental chinês.
Resumo do artigo da Web Fluxo de trabalho : Se a entrada do fluxo de trabalho do mapa mental for alterada para um URL de um artigo da Web, você poderá obter um fluxo de trabalho que lê um artigo da Web e o resume em um mapa mental chinês.
Classificação automática do fluxo de trabalho de reclamações do cliente : a entrada é uma tabela que contém conteúdo de reclamação e você pode personalizar as palavras -chave que precisam ser classificadas, para que as reclamações possam ser classificadas automaticamente. A saída é uma tabela Excel gerada automaticamente que contém os resultados da classificação.
Cada fluxo de trabalho possui uma interface de usuário e uma interface do editor . A interface do usuário é usada para operações diárias de fluxo de trabalho e a interface do editor é usada para edição do fluxo de trabalho. Geralmente, depois de projetar um fluxo de trabalho, você só precisa executá -lo na interface do usuário e não precisa modificá -lo na interface do editor.
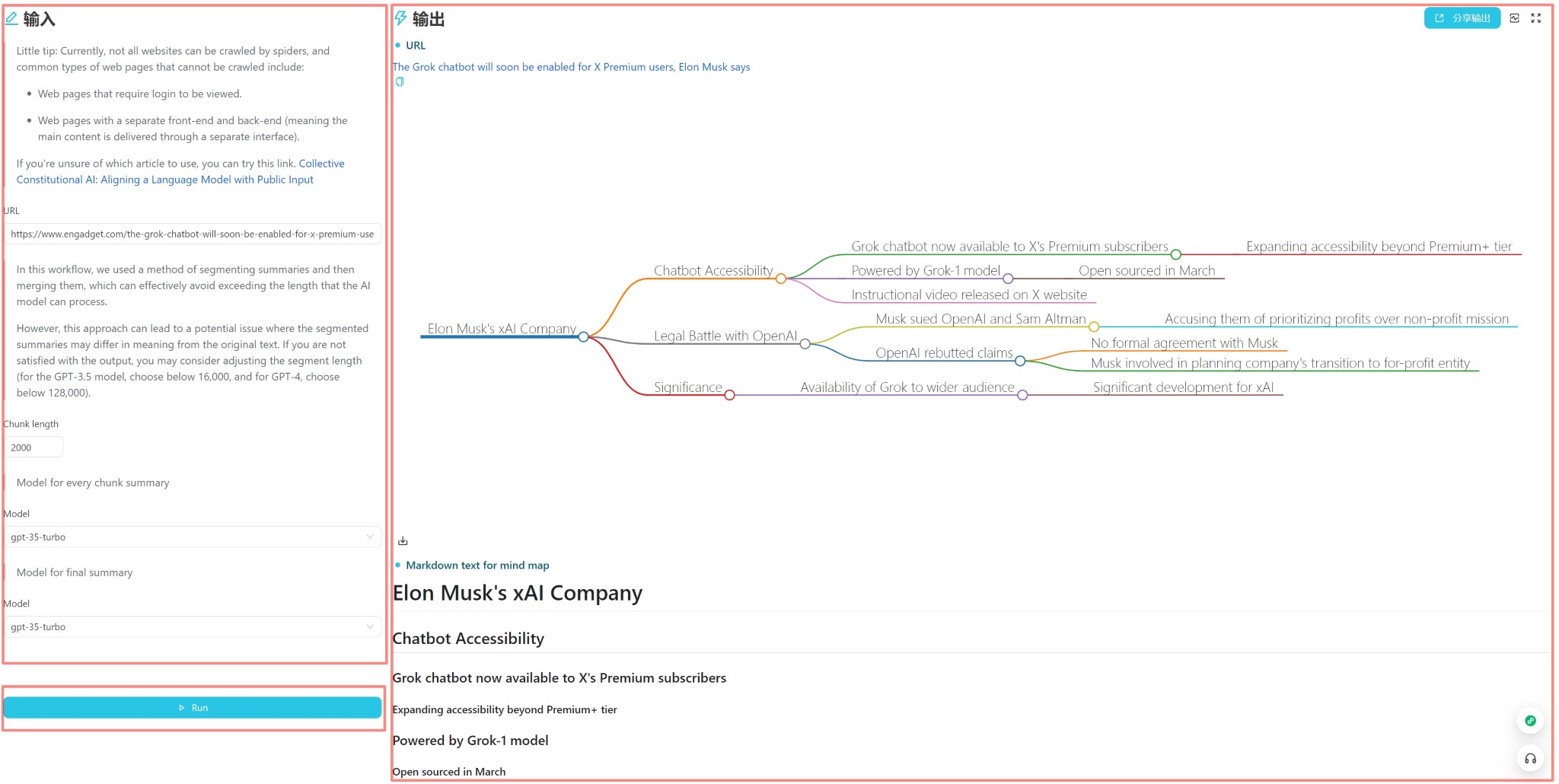
A interface do usuário é mostrada acima e é dividida em três partes: entrada, saída e gatilho (geralmente um botão de execução). Você pode inserir diretamente o conteúdo para uso diário, clique no botão Executar para ver o resultado da saída.
Para visualizar o fluxo de trabalho executado, clique em Records de execução do fluxo de trabalho , conforme mostrado na figura a seguir.
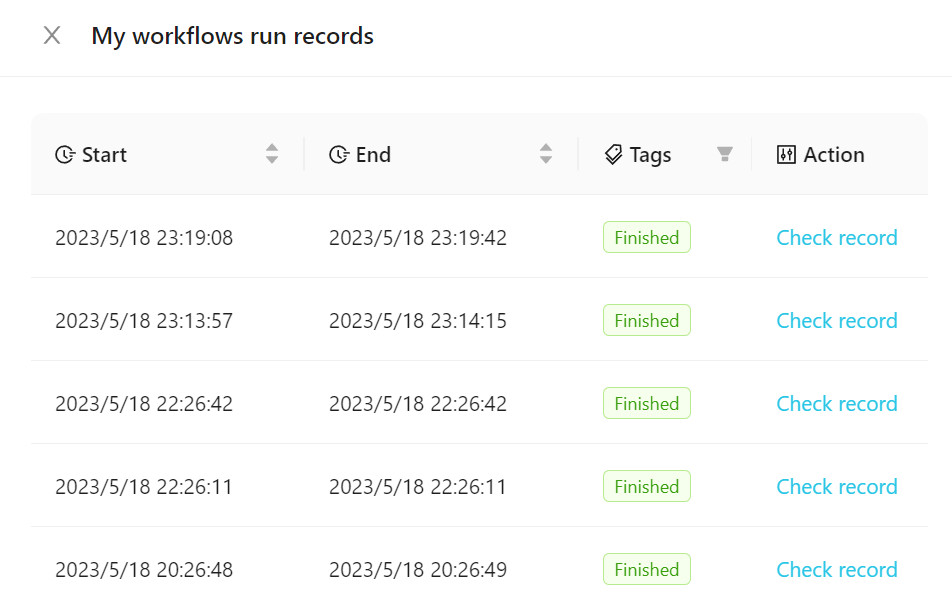
Você pode adicionar nossos modelos oficiais ao seu fluxo de trabalho ou criar um novo. Recomenda -se familiarizar -se com o uso de fluxos de trabalho usando modelos oficiais no início.
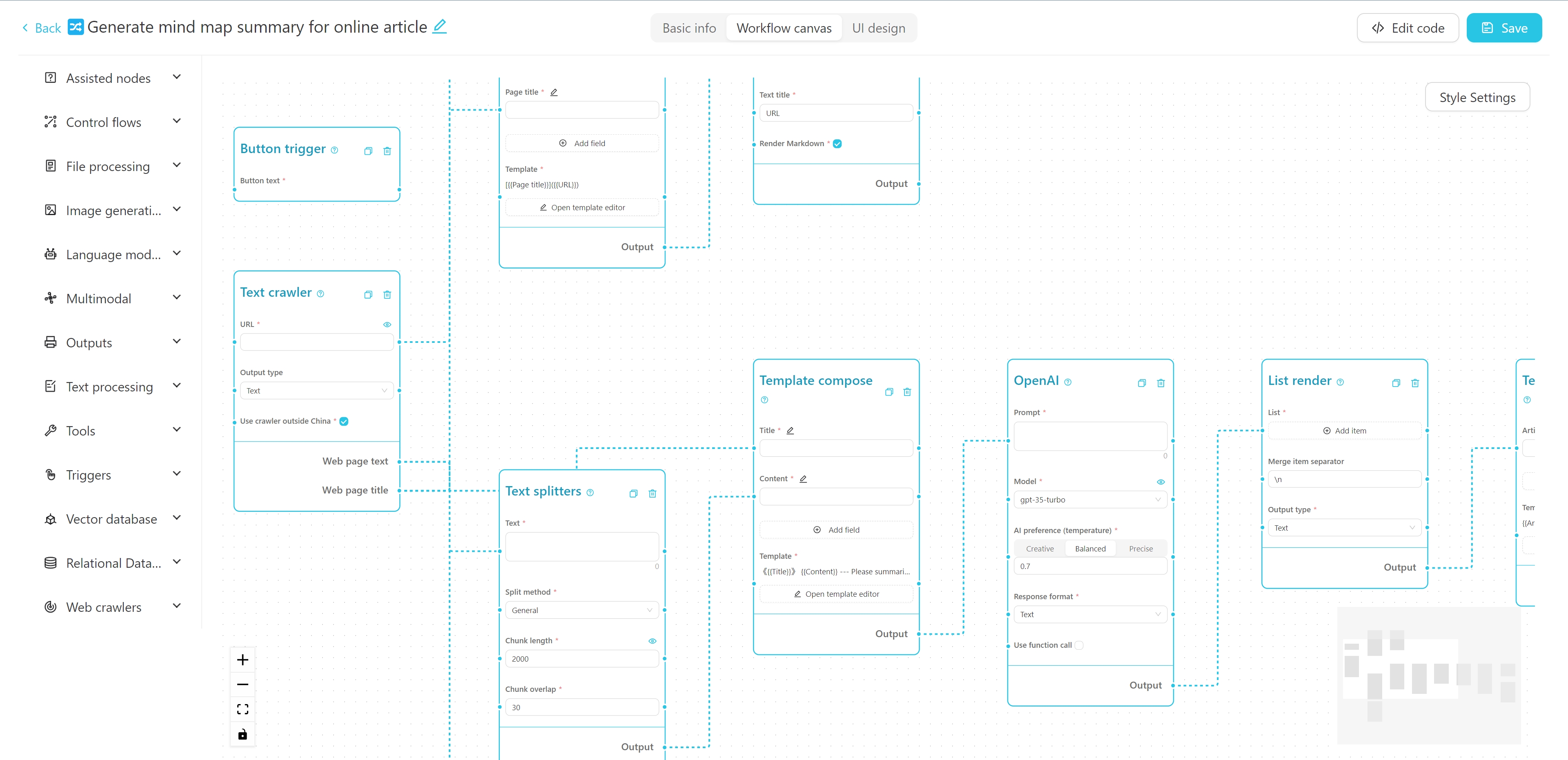
A interface do editor de fluxo de trabalho é mostrada acima. Você pode editar o nome, tags e descrição detalhada na parte superior. O lado esquerdo é a lista de nó do fluxo de trabalho e a direita é a tela do fluxo de trabalho. Você pode arrastar o nó desejado do lado esquerdo para a tela e conectar o nó através do fio para formar um fluxo de trabalho.
Você pode visualizar um tutorial sobre como criar um fluxo de trabalho de mapa mental de rastreador + AI de rastreamento AI aqui.
Você também pode experimentar este tutorial interativo on -line.
Back -end
Python 3.8 ~ Python 3.11
PDM instalado
Front-end
Vue3
Vite
Execute o seguinte comando no diretório de back -end para instalar dependências:
Instalação do PDM
PDM Install -g Mac
Normalmente, o PDM encontra automaticamente o Python do sistema e cria um ambiente virtual e instala dependências.
Após a instalação, execute o seguinte comando para iniciar o servidor de desenvolvimento de back -end e ver o efeito em execução:
PDM Run Dev
Se você precisar modificar o código do front -end, precisará executar o seguinte comando no diretório front -end para instalar dependências:
Instalação do PNPM
Ao puxar o código do projeto pela primeira vez, você também precisa executar
pnpm installpara instalar as dependências front-end.Se você não precisar desenvolver nenhum código front-end, poderá copiar diretamente a pasta
webda versão de liberação na pasta debackend.
Após a instalação das dependências do front -end, você precisa compilar o código do front -end no diretório de arquivos estático do back -end. Uma instrução de atalho foi fornecida no projeto. Execute o seguinte comando no diretório de back -end para embalar e copiar os recursos do front -end:
PDM Run Build-Front
Aviso
Antes de fazer alterações na estrutura do banco de dados, faça backup do seu banco de dados (localizado em my_database.db no diretório data configurado), caso contrário, você poderá perder dados.
Se você modificou a estrutura do modelo em backend/models , precisará executar os seguintes comandos no diretório backend para atualizar a estrutura do banco de dados:
Primeiro, digite o ambiente Python:
PDM Run Python
De modelos importando create_migrationscreate_migrações ("migration_name") # nome de acordo com as alterações feitas Após a operação, um novo arquivo de migração será gerado no diretório de backend/migrations , com o nome do arquivo Formato xxx_migration_name.py . Recomenda -se verificar primeiro o conteúdo do arquivo de migração para garantir que esteja correto e, em seguida, reinicie o programa principal. O programa principal executará automaticamente a migração.
O projeto usa o PyInstaller para embalagens. Execute o seguinte comando no diretório de back -end para empacotá -lo em um arquivo executável:
PDM Run Build
Após a embalagem, o arquivo executável será gerado no diretório back -end/dist .
O Vectorvein é um software de código aberto que suporta uso pessoal não comercial. Consulte a licença para acordos específicos.


