vector vein
v0.3.3
Inglés | 简体中文 | 日本語
Construya su flujo de trabajo de automatización con el poder de la IA y su base de conocimiento personal.
Cree flujos de trabajo potentes con solo arrastrar y soltar, sin ninguna programación.
Vectorvein es un software de flujo de trabajo AI sin código inspirado en Langchain y Langflow, diseñado para combinar las potentes capacidades de los modelos de idiomas grandes y permitir a los usuarios lograr fácilmente flujos de trabajo inteligentes y automatizados para varias tareas diarias.
Puede experimentar la versión en línea de Vectorvein aquí, sin necesidad de descargar o instalar.
Documentación oficial del sitio web en línea
Después de descargar VectorVein de la versión, el programa creará una carpeta de "datos" en el directorio de instalación para almacenar la base de datos y los recursos de archivos estáticos.
Vectorvein se crea con PyWebView, basado en el kernel WebView2, por lo que debe instalar el tiempo de ejecución WebView2. Si no se puede abrir el software, es posible que deba descargar el tiempo de ejecución de WebView2 manualmente desde https://developer.microsoft.com/en-us/microsoft-edge/webview2/
Importante
Si el software no se puede abrir después de la descompresión, verifique si el archivo .zip de paquete comprimido descargado está bloqueado. Puede resolver este problema haciendo clic derecho en el paquete comprimido y seleccionando "UNBLOCK".
La mayoría de los flujos de trabajo y los agentes en el software implican el uso de modelos de lenguaje grande de IA, por lo que al menos debe proporcionar una configuración utilizable para un modelo de lenguaje grande. Para los flujos de trabajo, puede ver qué modelos de idiomas grandes se están utilizando en la interfaz, como se muestra en la imagen a continuación.

A partir de V0.2.10, VectorPulse separa los puntos finales de API y las configuraciones de modelos de lenguaje grandes, lo que permite múltiples puntos finales de API para el mismo modelo de lenguaje grande.
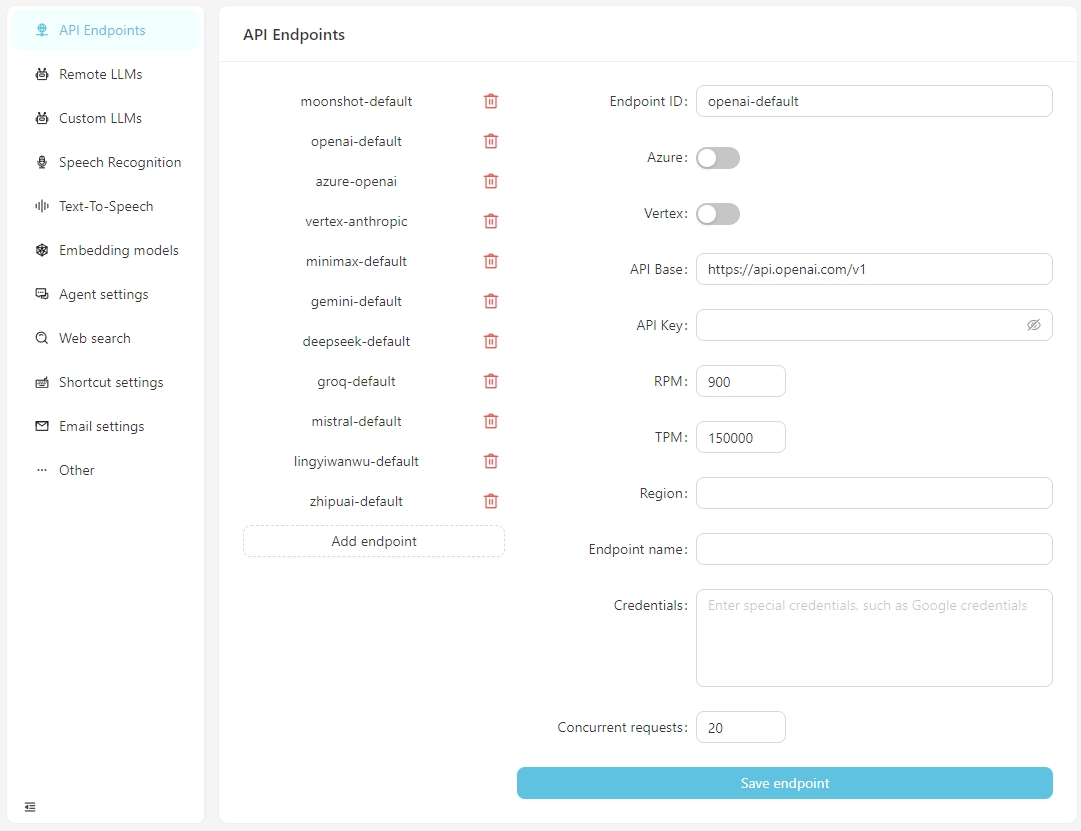
Después de que el software se abre normalmente, haga clic en el botón Abrir configuración y puede configurar la información para cada punto final de la API según sea necesario, o agregar puntos finales de API personalizados. Actualmente, los puntos finales de API admiten interfaces compatibles con OpenAI, que se pueden conectar a servicios de ejecución local como LM-Studio, Ollama, VLLM, etc.
La base API para LM-Studio es típicamente http: // localhost: 1234/v1/
La base API para Ollama es típicamente http: // localhost: 11434/v1/
Configure la información específica para cada modelo en la pestaña Remote LLMs .
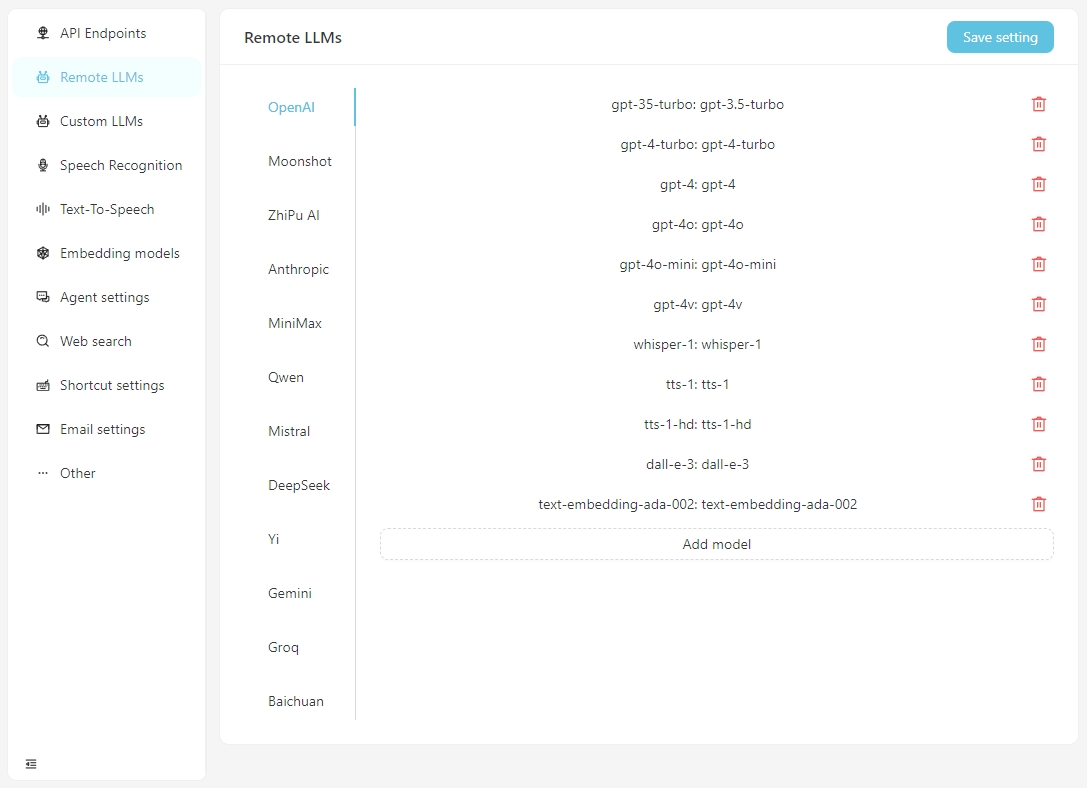
Haga clic en cualquier modelo para establecer su configuración específica, como se muestra a continuación.
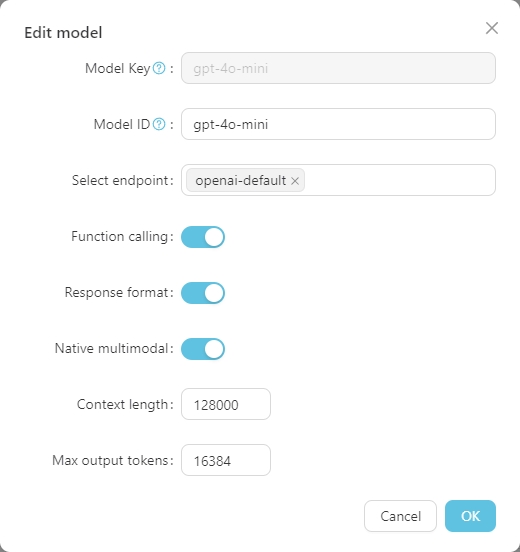
La Model Key es el nombre estándar del modelo grande y generalmente no necesita ser ajustado. El Model ID es el nombre utilizado durante la implementación real, que generalmente coincide con la Model Key . Sin embargo, en implementaciones como Azure Openai, la Model ID está definida por el usuario y, por lo tanto, debe ajustarse de acuerdo con la situación real.
Si usa un modelo de lenguaje grande personalizado, complete la información de configuración del modelo personalizado en la pestaña Custom LLMs . Actualmente, las interfaces compatibles con OpenAI son compatibles, como LM-Studio, Ollama, VLLM, etc.
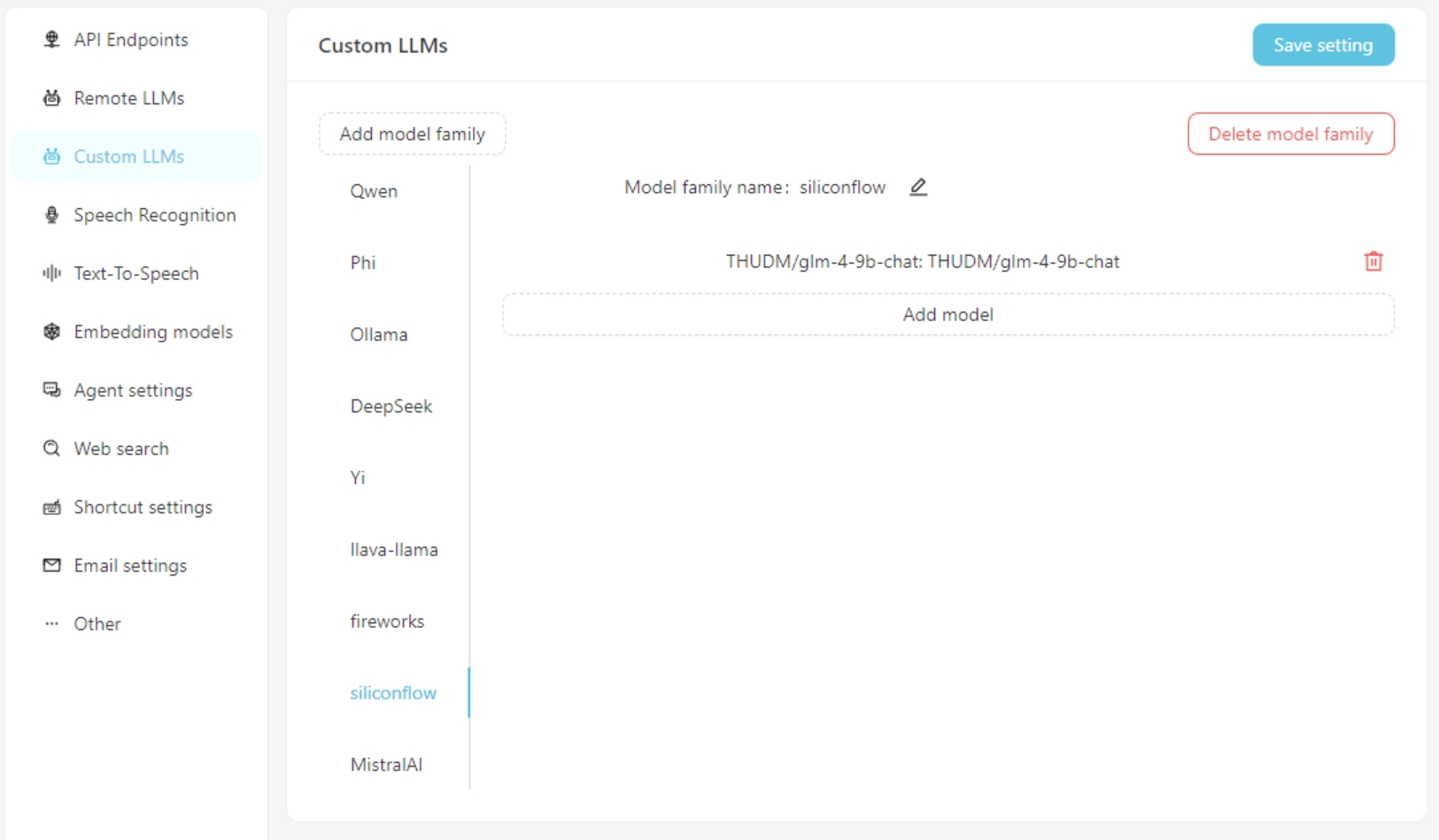
Primero, agregue una familia de modelo personalizado, luego agregue un modelo personalizado. No olvide hacer clic en el botón Save Settings .
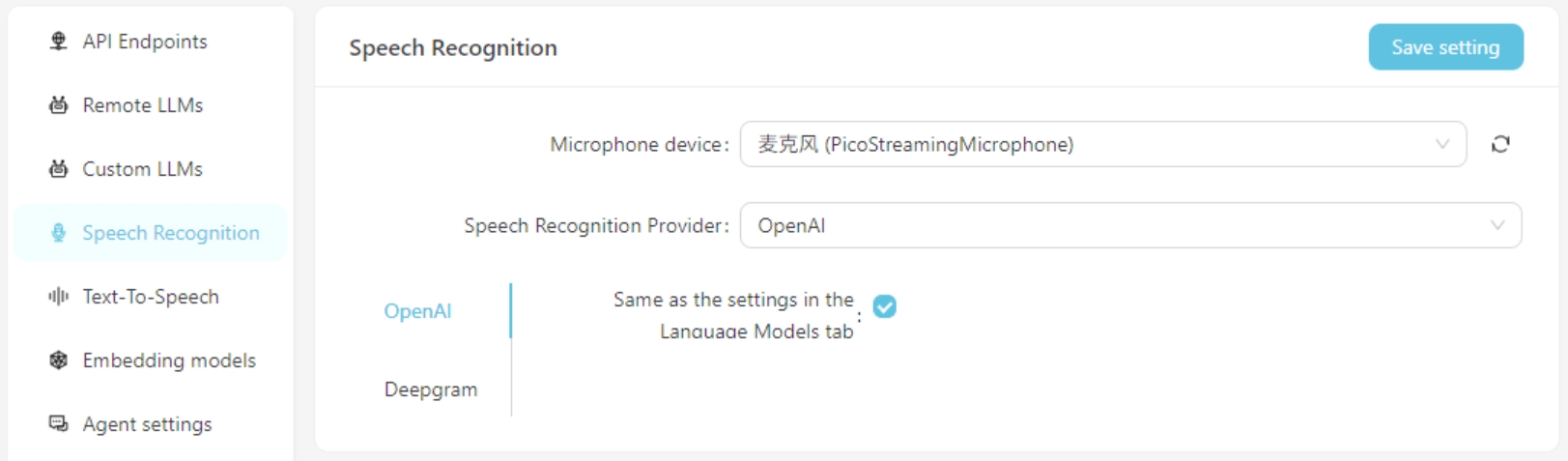
Actualmente, se apoyan los servicios de reconocimiento de voz de OpenAI/Deepgram. Para los servicios de OpenAI, puede usar la misma configuración que el modelo de idioma grande o configurar un servicio de reconocimiento de voz compatible con la API de OpenAI (como Groq).
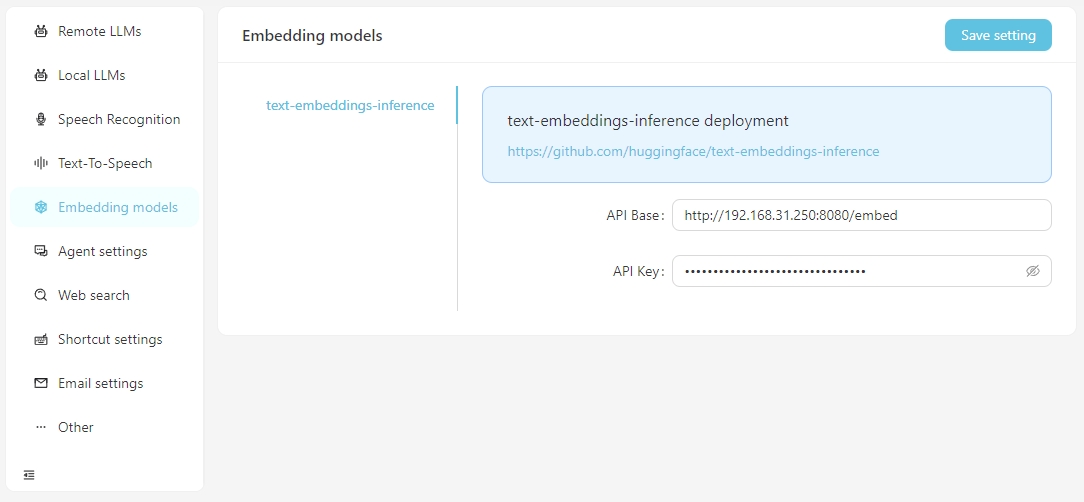
Cuando necesita realizar búsquedas vectoriales utilizando datos vectoriales, tiene la opción de utilizar servicios de incrustación proporcionados por OpenAI o configurar los servicios de incrustación locales en la configuración Embedding Model . Actualmente, los servicios de incrustación locales admitidos requieren que configure el texto-incrustaciones de incrustaciones usted mismo.
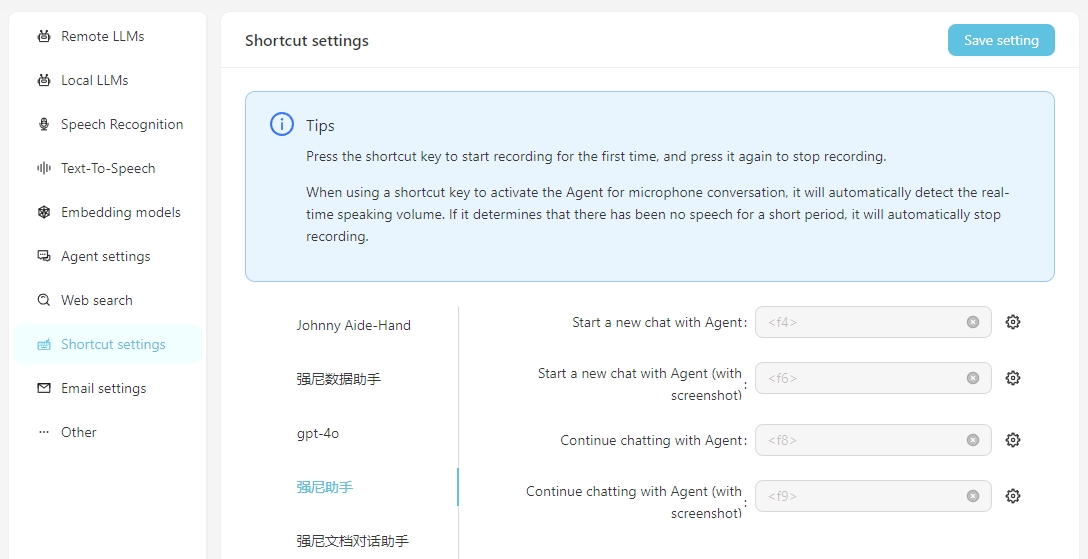
Para facilitar el uso diario, puede configurar accesos directos para iniciar rápidamente conversaciones de voz con el agente. Al lanzar a través del acceso directo, puede interactuar directamente con el agente a través del reconocimiento de voz. Es importante asegurarse de que el servicio de reconocimiento de voz esté configurado correctamente de antemano.
Incluya la captura de pantalla significa que al comenzar la conversación, una captura de pantalla de la pantalla se tomará y cargará como un archivo adjunto a la conversación.
Para usar su propia API de difusión estable local, debe agregar el parámetro --api al elemento de inicio de Webui-user.bat, es decir
set COMMANDLINE_ARGS=--api
Un flujo de trabajo representa un proceso de tarea de trabajo, incluida la entrada, la salida y cómo se procesa la entrada para alcanzar el resultado de la salida.
Ejemplos:
Flujo de trabajo de traducción : la entrada es un documento de Word en inglés, y la salida también es un documento de Word. Puede diseñar un flujo de trabajo para traducir el documento de entrada chino y generar una salida de documento chino.
Flujo de trabajo del mapa mental : si la salida del flujo de trabajo de traducción se cambia a un mapa mental, puede obtener un flujo de trabajo que lea un documento de Word en inglés y lo resume en un mapa mental chino.
Flujo de trabajo de resumen del artículo web : si la entrada del flujo de trabajo del mapa mental se cambia a una URL de un artículo web, puede obtener un flujo de trabajo que lea un artículo web y lo resume en un mapa mental chino.
Clasificación automática del flujo de trabajo de las quejas de los clientes : la entrada es una tabla que contiene contenido de queja, y puede personalizar las palabras clave que deben clasificarse, para que las quejas puedan clasificarse automáticamente. La salida es una tabla de Excel generada automáticamente que contiene los resultados de clasificación.
Cada flujo de trabajo tiene una interfaz de usuario y una interfaz editor . La interfaz de usuario se utiliza para operaciones diarias de flujo de trabajo, y la interfaz del editor se utiliza para la edición de flujo de trabajo. Por lo general, después de diseñar un flujo de trabajo, solo necesita ejecutarlo en la interfaz de usuario y no necesita modificarlo en la interfaz del editor.
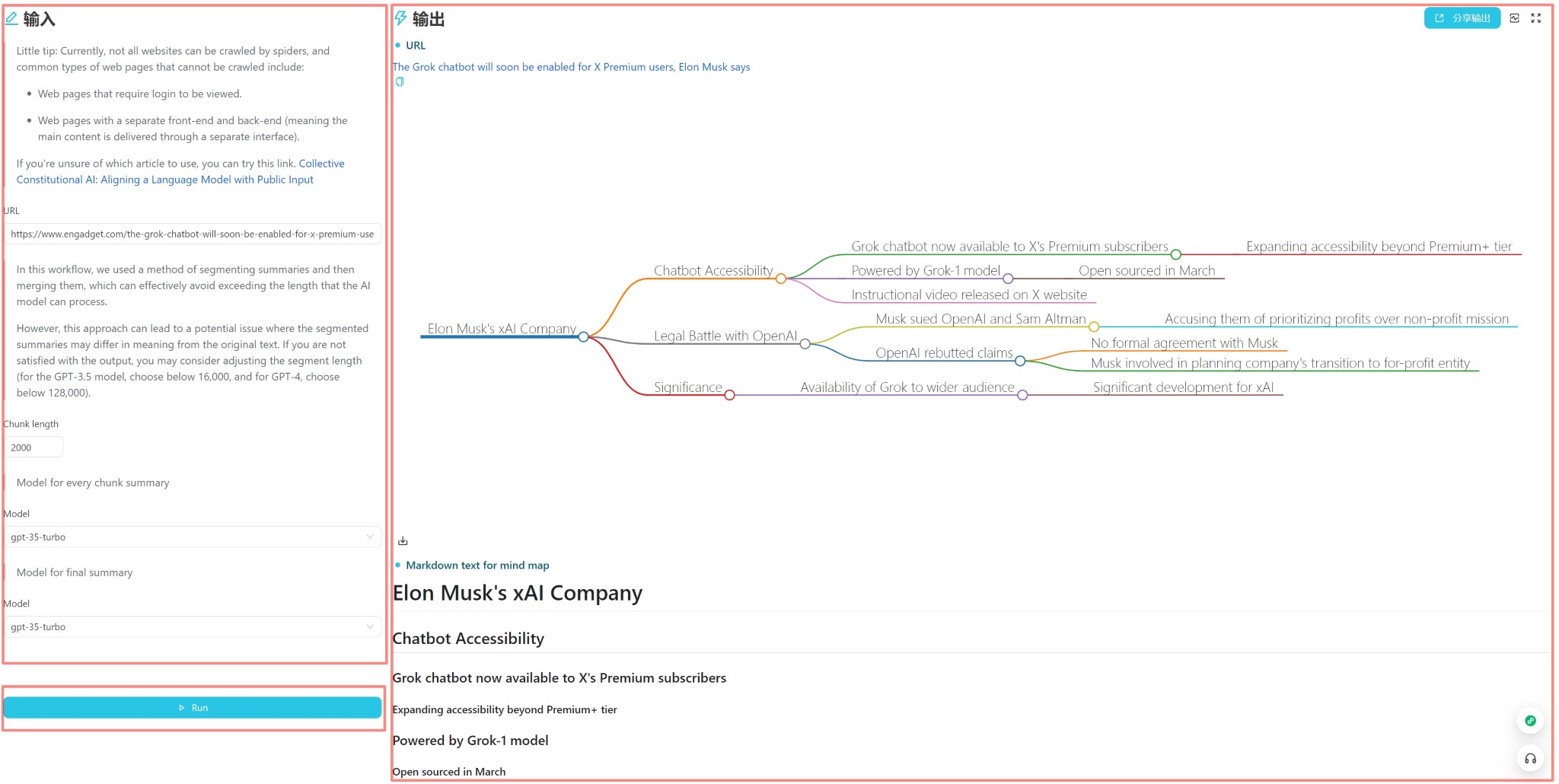
La interfaz de usuario se muestra arriba y se divide en tres partes: entrada, salida y activación (generalmente un botón de ejecución). Puede ingresar directamente el contenido para uso diario, haga clic en el botón Ejecutar para ver el resultado de salida.
Para ver el flujo de trabajo ejecutado, haga clic en los registros de ejecución del flujo de trabajo , como se muestra en la siguiente figura.
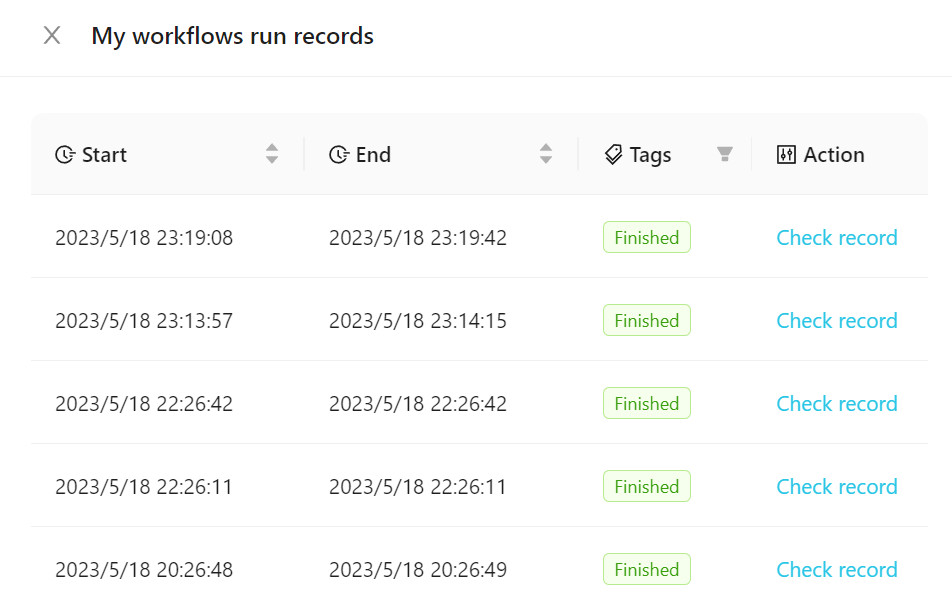
Puede agregar nuestras plantillas oficiales a su flujo de trabajo o crear una nueva. Se recomienda familiarizarse con el uso de flujos de trabajo utilizando plantillas oficiales al principio.
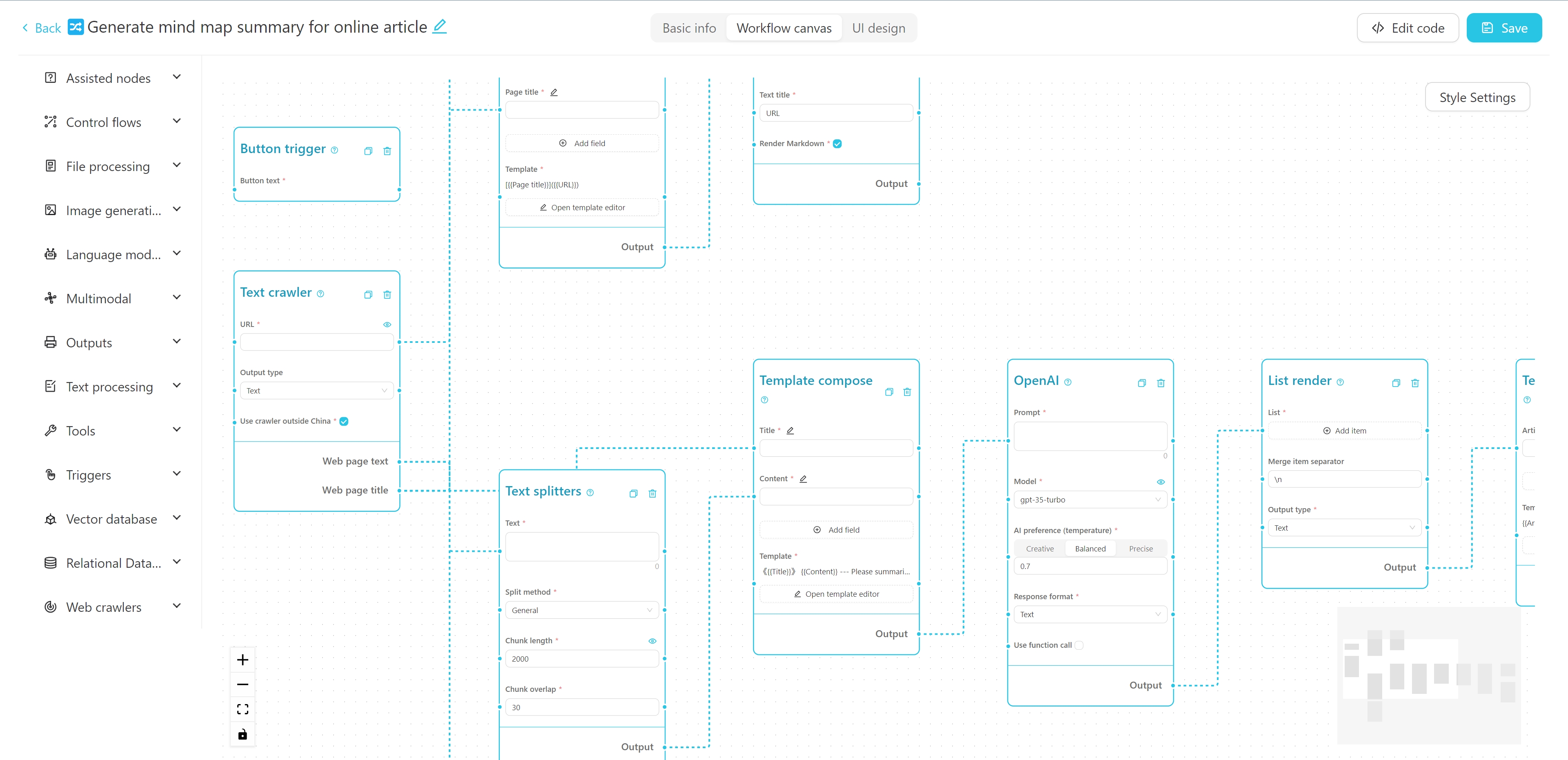
La interfaz del editor de flujo de trabajo se muestra arriba. Puede editar el nombre, las etiquetas y la descripción detallada en la parte superior. El lado izquierdo es la lista de nodos del flujo de trabajo, y la derecha es el lienzo del flujo de trabajo. Puede arrastrar el nodo deseado desde el lado izquierdo hasta el lienzo, y luego conectar el nodo a través del cable para formar un flujo de trabajo.
Puede ver un tutorial sobre la creación de un flujo de trabajo de mapa mental de resumen de Crawler + AI aquí.
También puede probar este tutorial interactivo en línea.
Backend
Python 3.8 ~ Python 3.11
PDM instalado
Interfaz
VUE3
Vite
Ejecute el siguiente comando en el directorio de backend para instalar dependencias:
instalación de PDM
PDM Install -G Mac
Normalmente, PDM encontrará automáticamente el Python del sistema y creará un entorno virtual e instalará dependencias.
Después de la instalación, ejecute el siguiente comando para iniciar el servidor de desarrollo de backend y ver el efecto de ejecución:
PDM Run Dev
Si necesita modificar el código frontend, debe ejecutar el siguiente comando en el directorio frontend para instalar dependencias:
instalación de PNPM
Al extraer el código del proyecto por primera vez, también debe ejecutar
pnpm installpara instalar las dependencias frontales.Si no necesita desarrollar ningún código frontal, puede copiar directamente la carpeta
webdesde la versión de versión en la carpetabackend.
Después de instalar las dependencias frontend, debe compilar el código frontend en el directorio de archivos estáticos del backend. Se ha proporcionado una instrucción de acceso directo en el proyecto. Ejecute el siguiente comando en el directorio de backend para empacar y copiar los recursos frontend:
PDM Run Build-Front
Advertencia
Antes de realizar cambios en la estructura de la base de datos, realice una copia de seguridad de su base de datos (ubicada en my_database.db en su directorio data configurado), de lo contrario, puede perder datos.
Si ha modificado la estructura del modelo en backend/models , debe ejecutar los siguientes comandos en el directorio backend para actualizar la estructura de la base de datos:
Primero, ingrese al entorno de Python:
PDM Run Python
de modelos import crear_migrationscreate_migrations ("migration_name") # nombre de acuerdo con los cambios realizados Después de la operación, se generará un nuevo archivo de migración en el directorio backend/migrations , con el formato de nombre de archivo xxx_migration_name.py . Se recomienda verificar primero el contenido del archivo de migración para asegurarse de que sea correcto y luego reiniciar el programa principal. El programa principal ejecutará automáticamente la migración.
El proyecto utiliza Pyinstaller para el embalaje. Ejecute el siguiente comando en el directorio de backend para empaquetarlo en un archivo ejecutable:
PDM Run Build
Después del embalaje, el archivo ejecutable se generará en el directorio de backend/DIST .
Vectorvein es un software de código abierto que admite el uso personal no comercial. Consulte la licencia para obtener acuerdos específicos.


