vector vein
v0.3.3
Anglais | 简体中文 | 日本語
Construisez votre flux de travail d'automatisation avec la puissance de l'IA et votre base de connaissances personnelles.
Créez des workflows puissants avec simplement glisser-déposer, sans aucune programmation.
VectorVein est un logiciel de flux de travail AI sans code inspiré de Langchain et Langflow, conçu pour combiner les capacités puissantes des modèles de grande langue et permettre aux utilisateurs d'obtenir facilement des flux de travail intelligents et automatisés pour diverses tâches quotidiennes.
Vous pouvez découvrir la version en ligne de Vectorvein ici, sans avoir besoin de télécharger ou d'installer.
Documentation officielle du site Web en ligne
Après avoir téléchargé VectorVein à partir de la version, le programme créera un dossier "Data" dans le répertoire d'installation pour stocker la base de données et les ressources de fichiers statiques.
VectorVein est construit à l'aide de PyWebView, basé sur le noyau WebView2, vous devez donc installer l'exécution WebView2. Si le logiciel ne peut pas être ouvert, vous devrez peut-être télécharger le temps d'exécution WebView2 manuellement à partir de https://developer.microsoft.com/en-us/microsoft-edge/webview2/
Important
Si le logiciel ne peut pas être ouvert après la décompression, veuillez vérifier si le fichier .zip compressé téléchargé .zip est verrouillé. Vous pouvez résoudre ce problème en cliquant avec le bouton droit sur le package compressé et en sélectionnant "Unblock".
La plupart des workflows et des agents du logiciel impliquent l'utilisation de modèles de langage de grande envergure, vous devez donc au moins fournir une configuration utilisable pour un modèle grand langage. Pour les workflows, vous pouvez voir quels grands modèles de langue sont utilisés dans l'interface, comme indiqué dans l'image ci-dessous.

À partir de V0.2.10, VectorPulse sépare les points de terminaison de l'API et les configurations du modèle de langue grande, permettant plusieurs points de terminaison API pour le même modèle de langage grand.
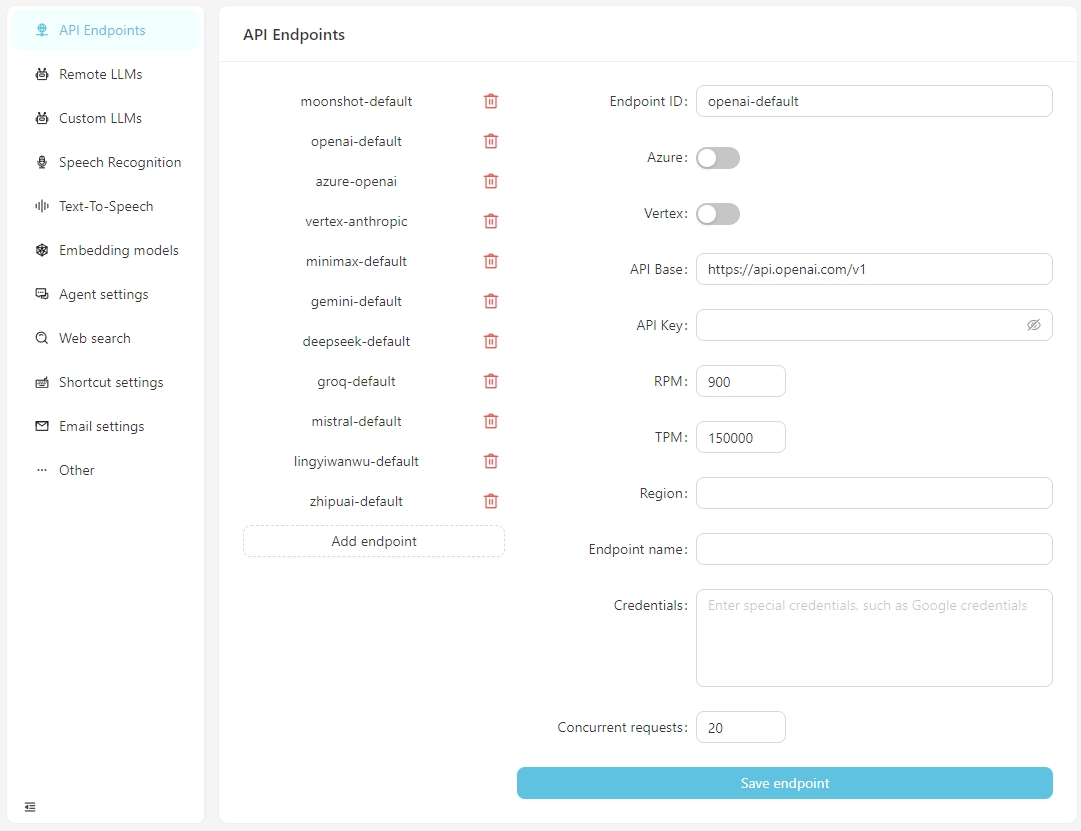
Après l'ouverture du logiciel normalement, cliquez sur le bouton Open Paramètres et vous pouvez configurer les informations pour chaque point de terminaison de l'API selon les besoins, ou ajouter des points de terminaison API personnalisés. Actuellement, les points de terminaison API prennent en charge les interfaces compatibles OpenAI, qui peuvent être connectées à des services en cours d'exécution localement tels que LM-studio, olllama, VLLM, etc.
La base d'API pour LM-Studio est généralement http: // localhost: 1234 / v1 /
La base d'API pour Olllama est généralement http: // localhost: 11434 / v1 /
Veuillez configurer les informations spécifiques pour chaque modèle dans l'onglet Remote LLMs .
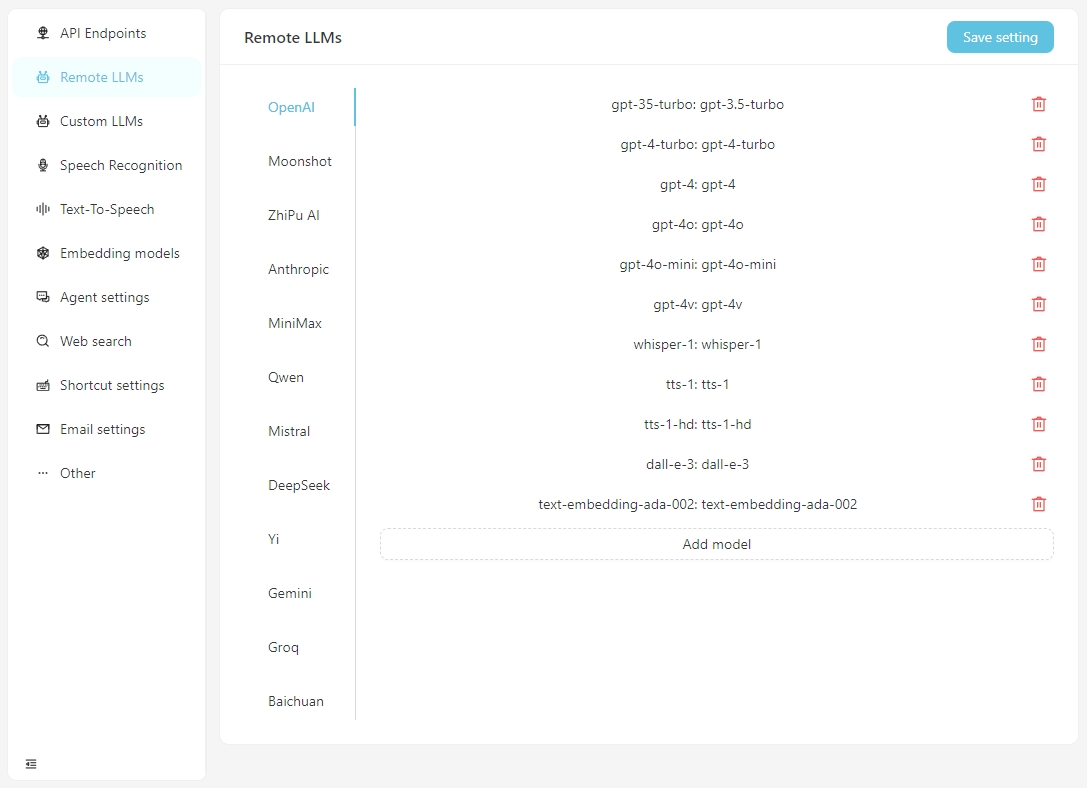
Cliquez sur n'importe quel modèle pour définir sa configuration spécifique, comme indiqué ci-dessous.
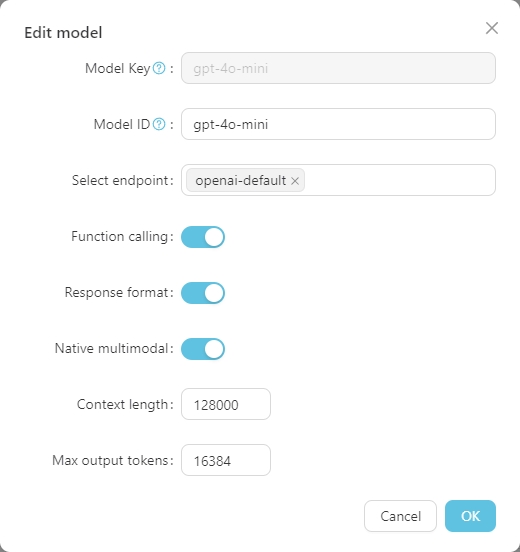
La Model Key est le nom standard du grand modèle et n'a généralement pas besoin d'être ajusté. L' Model ID est le nom utilisé pendant le déploiement réel, qui correspond généralement à la Model Key . Cependant, dans les déploiements comme Azure OpenAI, l' Model ID est défini par l'utilisateur et doit donc être ajusté en fonction de la situation réelle.
Si vous utilisez un modèle de langue grande personnalisé, remplissez les informations de configuration du modèle personnalisées sur l'onglet Custom LLMs . Actuellement, les interfaces compatibles avec OpenAI sont prises en charge, telles que LM-Studio, Olllama, Vllm, etc.
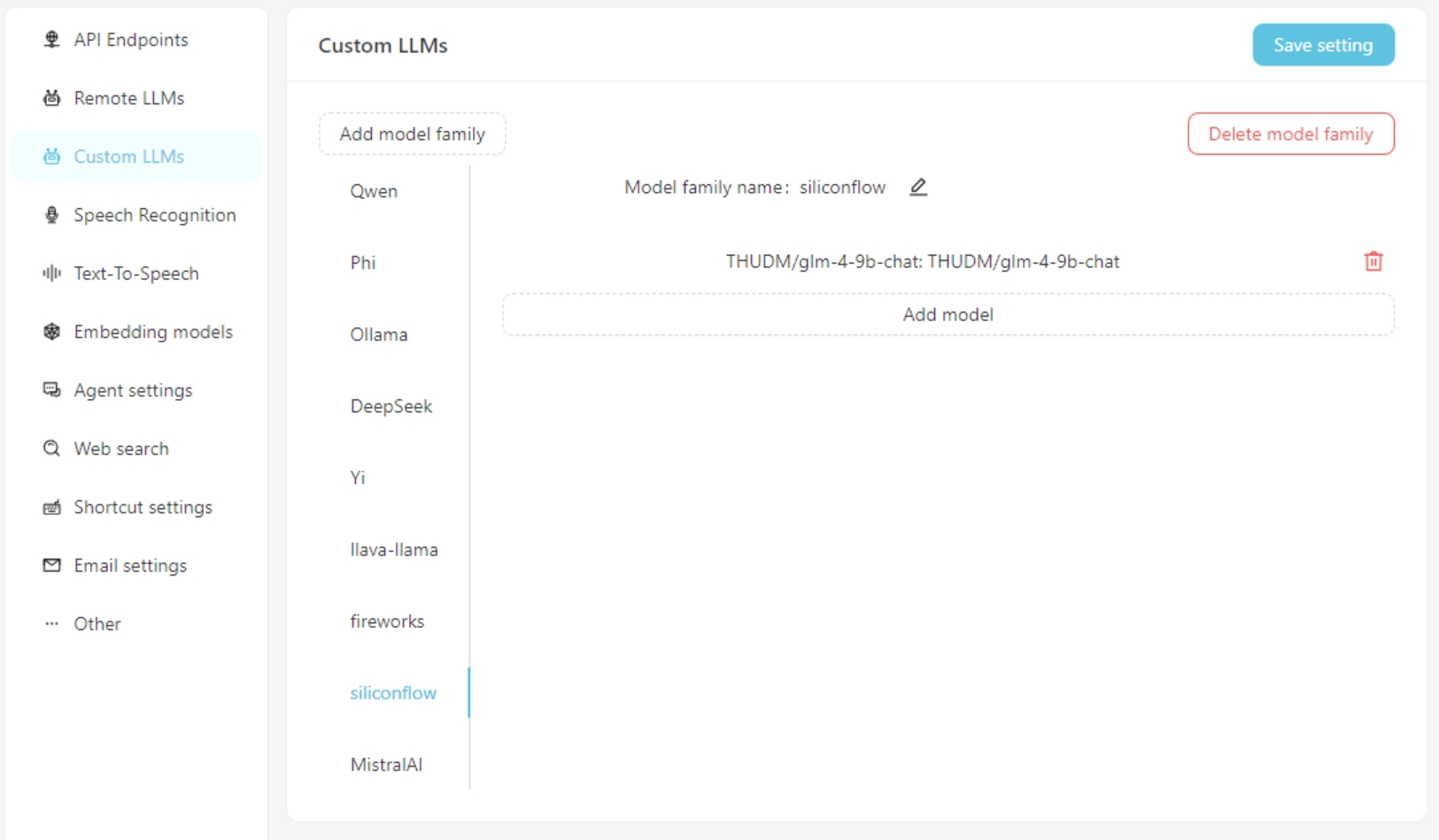
Tout d'abord, ajoutez une famille de modèles personnalisée, puis ajoutez un modèle personnalisé. N'oubliez pas de cliquer sur le bouton Save Settings .
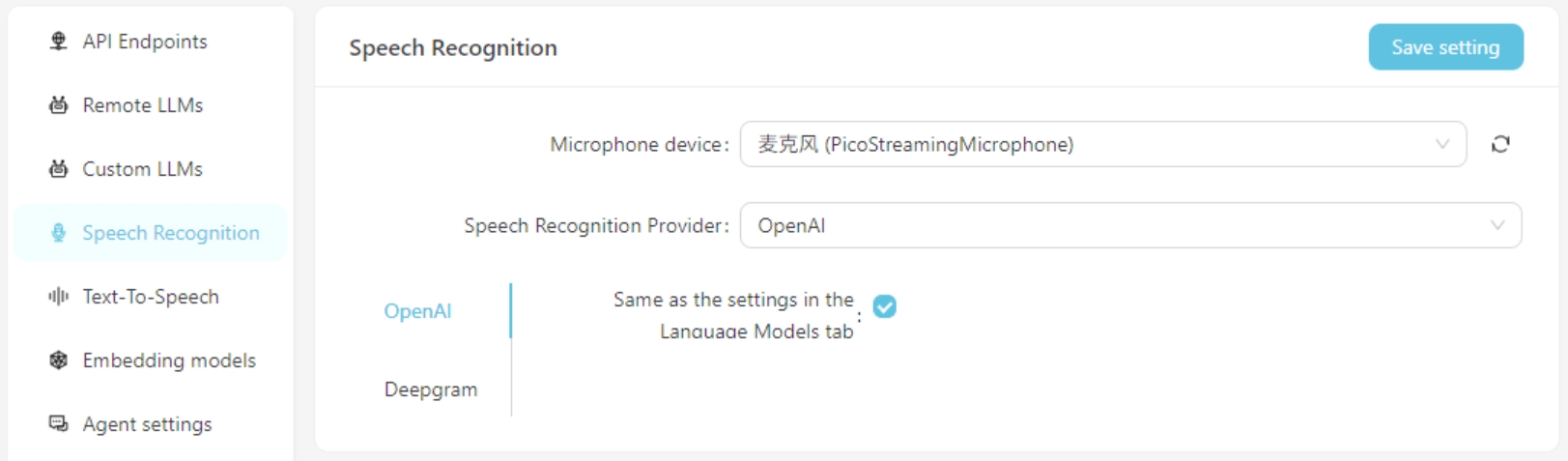
Actuellement, les services de reconnaissance vocale d'Openai / Deepgram sont pris en charge. Pour les services OpenAI, vous pouvez utiliser la même configuration que le modèle de grande langue ou configurer un service de reconnaissance vocale compatible avec l'API OpenAI (tel que GROQ).
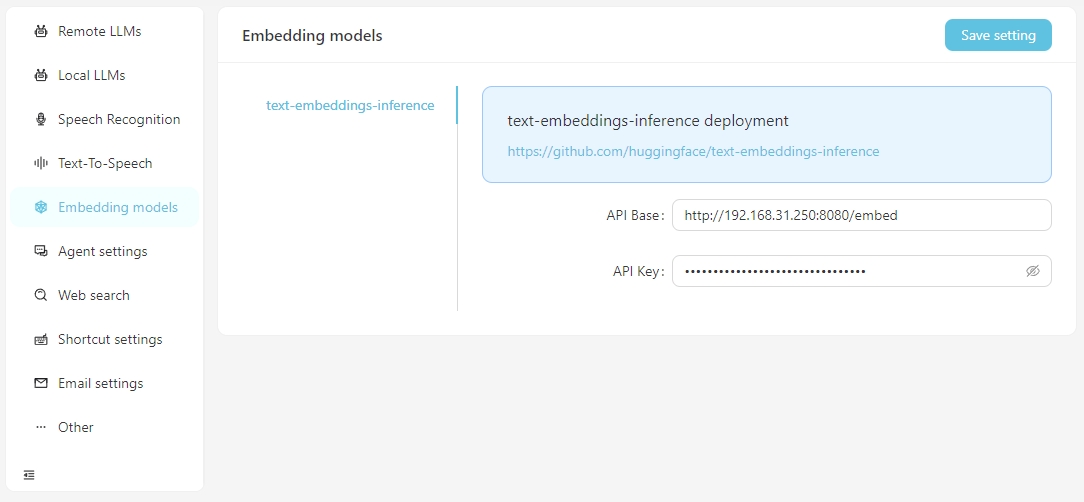
Lorsque vous devez effectuer des recherches vectorielles à l'aide de données vectorielles, vous avez la possibilité d'utiliser des services d'intégration fournis par OpenAI ou de configurer les services d'intégration locaux dans les paramètres Embedding Model . Actuellement, les services d'incorporation locaux pris en charge vous obligent à configurer vous-même de la configuration de Text-Embeddings.
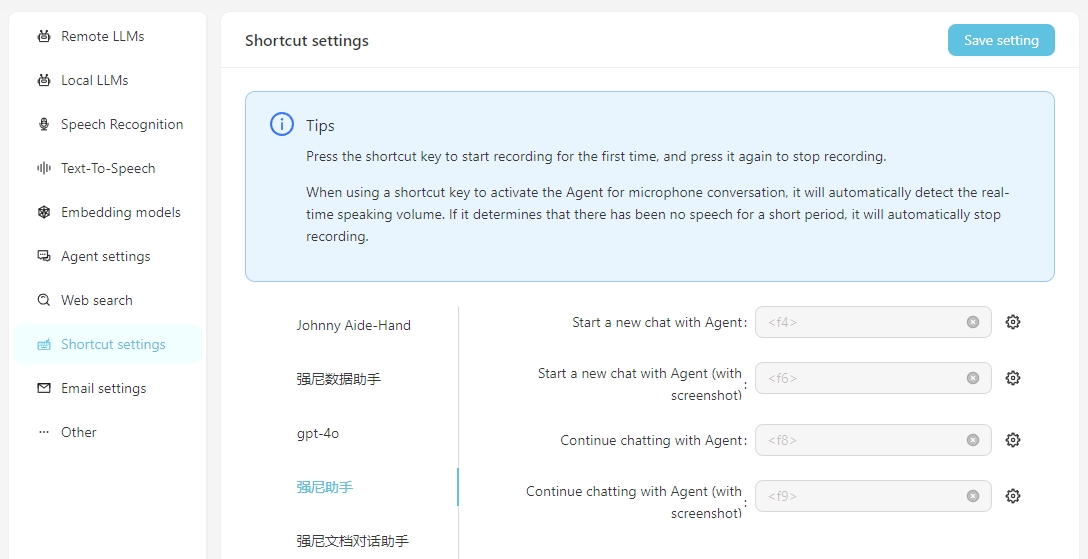
Pour faciliter l'utilisation quotidienne, vous pouvez configurer les raccourcis pour initier rapidement des conversations vocales avec l'agent. En lançant à travers le raccourci, vous pouvez interagir directement avec l'agent via la reconnaissance vocale. Il est important de s'assurer que le service de reconnaissance vocale est correctement configuré à l'avance.
Inclure la capture d'écran signifie que lors du démarrage de la conversation, une capture d'écran de l'écran sera prise et téléchargée comme un attachement à la conversation.
Pour utiliser votre propre API de diffusion stable locale, vous devez ajouter le paramètre --API à l'élément de démarrage de WebUi-user.bat, c'est-à-dire
set COMMANDLINE_ARGS=--api
Un flux de travail représente un processus de tâche de travail, y compris l'entrée, la sortie, et comment la saisie est traitée pour atteindre le résultat de sortie.
Exemples:
Traduction Workflow : l'entrée est un document Word en anglais, et la sortie est également un document Word. Vous pouvez concevoir un workflow pour traduire le document chinois d'entrée et générer une sortie de document chinois.
Mad Map Workflow : Si la sortie du workflow de traduction est changée en une carte mentale, vous pouvez obtenir un workflow qui lit un document Word en anglais et le résume en une carte mentale chinoise.
Résumé de l'article du flux de travail : Si la contribution du flux de travail de la carte mentale est changée en URL d'un article Web, vous pouvez obtenir un flux de travail qui lit un article Web et le résume en une carte mentale chinoise.
Classification automatique du flux de travail des plaintes des clients : l'entrée est un tableau contenant du contenu de la plainte, et vous pouvez personnaliser les mots clés qui doivent être classés, afin que les plaintes puissent être automatiquement classées. La sortie est un tableau Excel généré automatiquement contenant les résultats de classification.
Chaque workflow a une interface utilisateur et une interface d'éditeur . L'interface utilisateur est utilisée pour les opérations quotidiennes du flux de travail et l'interface de l'éditeur est utilisée pour l'édition de flux de travail. Habituellement, après la conception d'un flux de travail, vous n'avez besoin que de l'exécuter dans l'interface utilisateur et n'avez pas besoin de le modifier dans l'interface de l'éditeur.
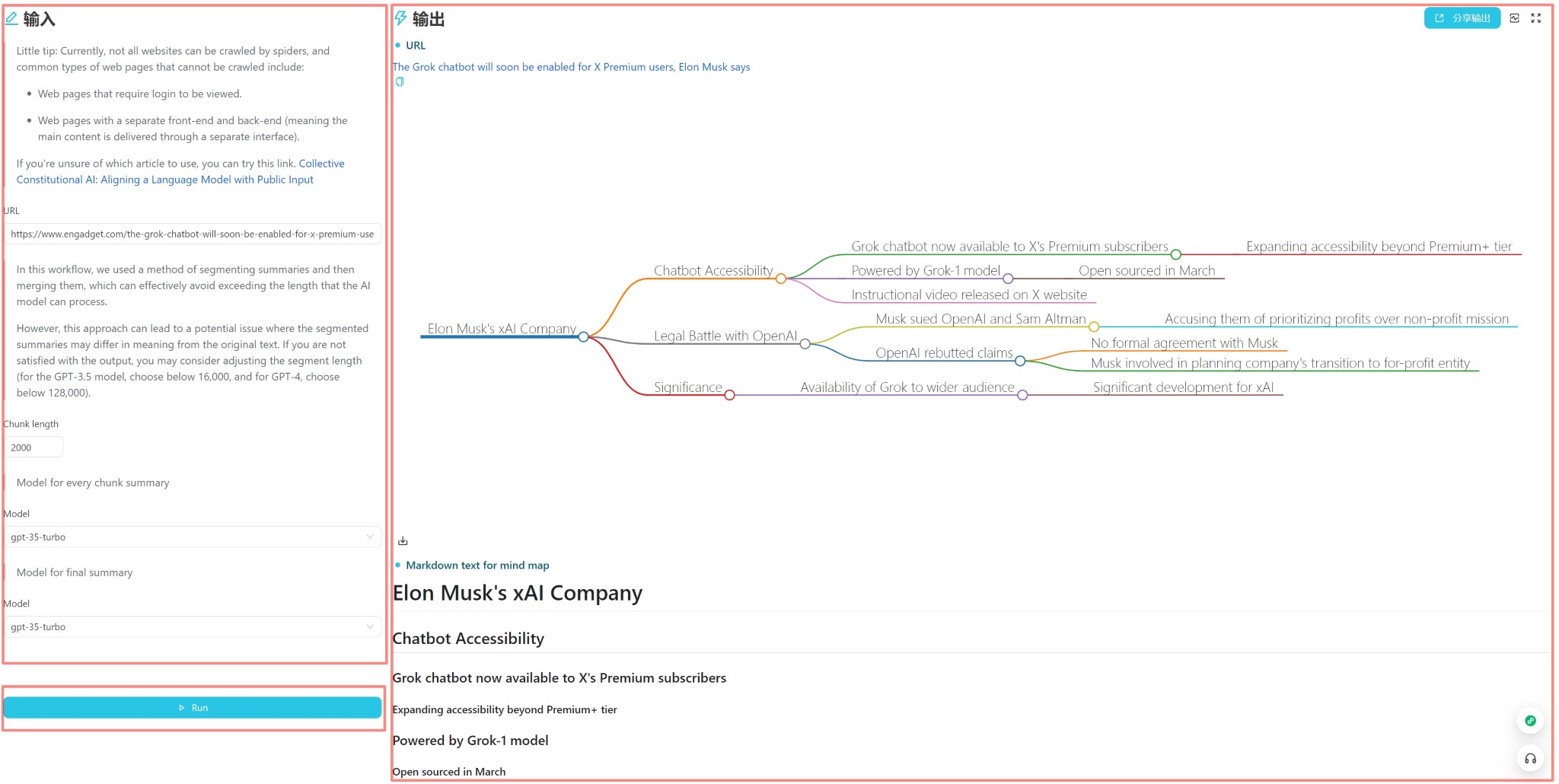
L'interface utilisateur est indiquée ci-dessus et est divisée en trois parties: entrée, sortie et déclencheur (généralement un bouton d'exécution). Vous pouvez saisir directement le contenu pour une utilisation quotidienne, cliquez sur le bouton Exécuter pour voir le résultat de sortie.
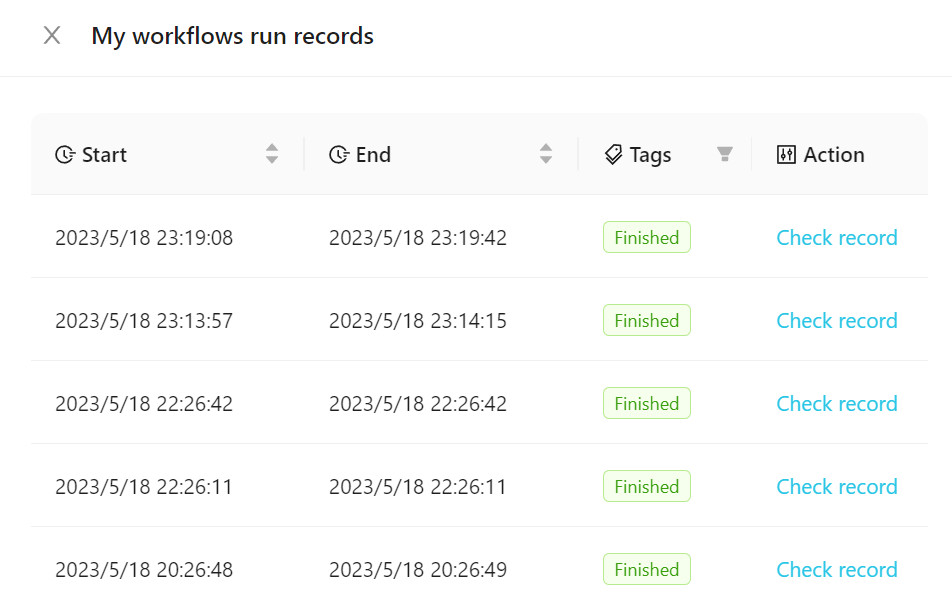
Pour afficher le flux de travail exécuté, cliquez sur Workflow Exécuter des enregistrements , comme indiqué dans la figure suivante.
Vous pouvez ajouter nos modèles officiels à votre flux de travail ou en créer un nouveau. Il est recommandé de vous familiariser avec l'utilisation de workflows en utilisant des modèles officiels au début.
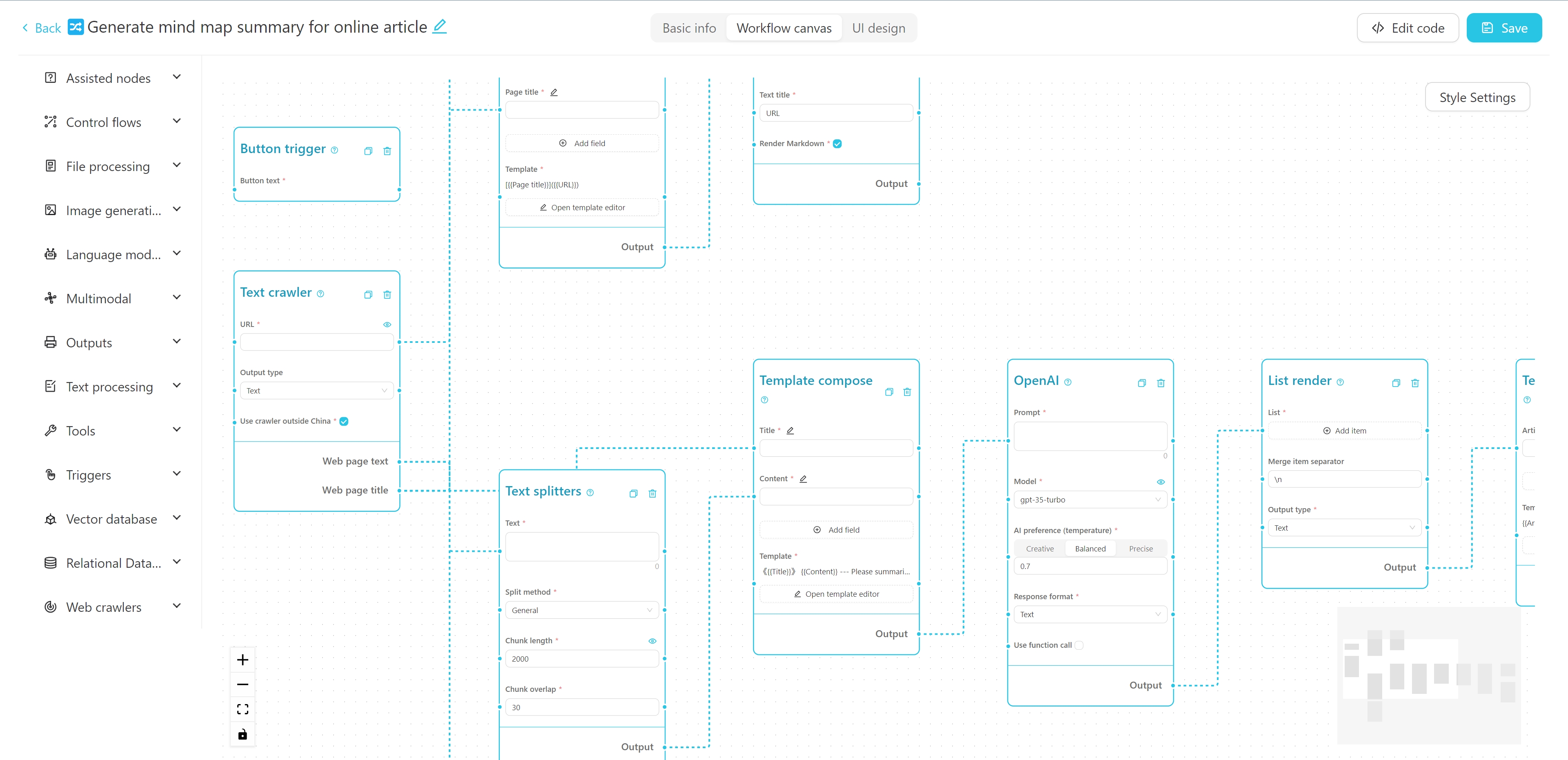
L'interface de l'éditeur de workflow est indiquée ci-dessus. Vous pouvez modifier le nom, les balises et la description détaillée en haut. Le côté gauche est la liste des nœuds du workflow, et la droite est la toile du workflow. Vous pouvez faire glisser le nœud souhaité du côté gauche vers la toile, puis connecter le nœud via le fil pour former un workflow.
Vous pouvez afficher un tutoriel sur la création d'un flux de travail de Crawler + Résumé AI ici.
Vous pouvez également essayer ce tutoriel interactif en ligne.
Backend
Python 3.8 ~ Python 3.11
PDM installé
L'extrémité avant
Vue3
Vite
Exécutez la commande suivante dans le répertoire backend pour installer les dépendances:
Installation PDM
PDM Install -g Mac
Normalement, PDM trouvera automatiquement le Python du système et créera un environnement virtuel et installe les dépendances.
Après l'installation, exécutez la commande suivante pour démarrer le serveur de développement backend et voir l'effet en cours d'exécution:
PDM Run Dev
Si vous devez modifier le code Frontend, vous devez exécuter la commande suivante dans le répertoire Frontend pour installer les dépendances:
Installation de PNPM
Lorsque vous tirez le code du projet pour la première fois, vous devez également exécuter
pnpm installpour installer les dépendances frontales.Si vous n'avez pas du tout besoin de développer un code frontal, vous pouvez copier directement le dossier
webà partir de la version de version dans le dossierbackend.
Une fois les dépendances de frontend installées, vous devez compiler le code Frontend dans le répertoire de fichiers statique du backend. Une instruction de raccourci a été fournie dans le projet. Exécutez la commande suivante dans le répertoire backend pour emballer et copier les ressources frontend:
pdm run build-front
Avertissement
Avant d'apporter des modifications à la structure de la base de données, veuillez sauvegarder votre base de données (située sur my_database.db dans votre répertoire data configuré), sinon vous pouvez perdre des données.
Si vous avez modifié la structure du modèle dans backend/models , vous devez exécuter les commandes suivantes dans le répertoire backend pour mettre à jour la structure de la base de données:
Tout d'abord, entrez dans l'environnement Python:
PDM Run Python
From Models Import Create_MigrationsCreate_Migrations ("Migration_name") # Nom Selon les modifications apportées Après l'opération, un nouveau fichier de migration sera généré dans le répertoire backend/migrations , avec le format de nom de fichier xxx_migration_name.py . Il est recommandé de vérifier d'abord le contenu du fichier de migration pour s'assurer qu'il est correct, puis de redémarrer le programme principal. Le programme principal exécutera automatiquement la migration.
Le projet utilise Pyinstaller pour l'emballage. Exécutez la commande suivante dans le répertoire backend pour l'emballer dans un fichier exécutable:
build pdm run
Après emballage, le fichier exécutable sera généré dans le répertoire backend / dist .
VectorVein est un logiciel open source qui prend en charge une utilisation personnelle non commerciale. Veuillez vous référer à la licence pour des accords spécifiques.


