xtts webui
Deepspeed wheels for Windows
프로젝트에는 이제 휴대용 버전이 있으므로 모든 종속성을 설치하는 데 어려움을 겪을 필요가 없습니다.
다운로드하려면 여기를 클릭하십시오
당신은 그것을 실행하기 위해 6GB의 비디오 메모리가있는 Windows와 Nvidia 그래픽 카드 외에는 아무것도 필요하지 않습니다.
영어
러시아인
포르투갈
XTTS-webui는 XTTS를 최대한 활용할 수있는 웹 인터페이스입니다. 이 인터페이스 주변에는 결과를 향상시킬 다른 신경망이 있습니다. 모델을 미세 조정하고 고품질 음성 모델을 얻을 수도 있습니다.
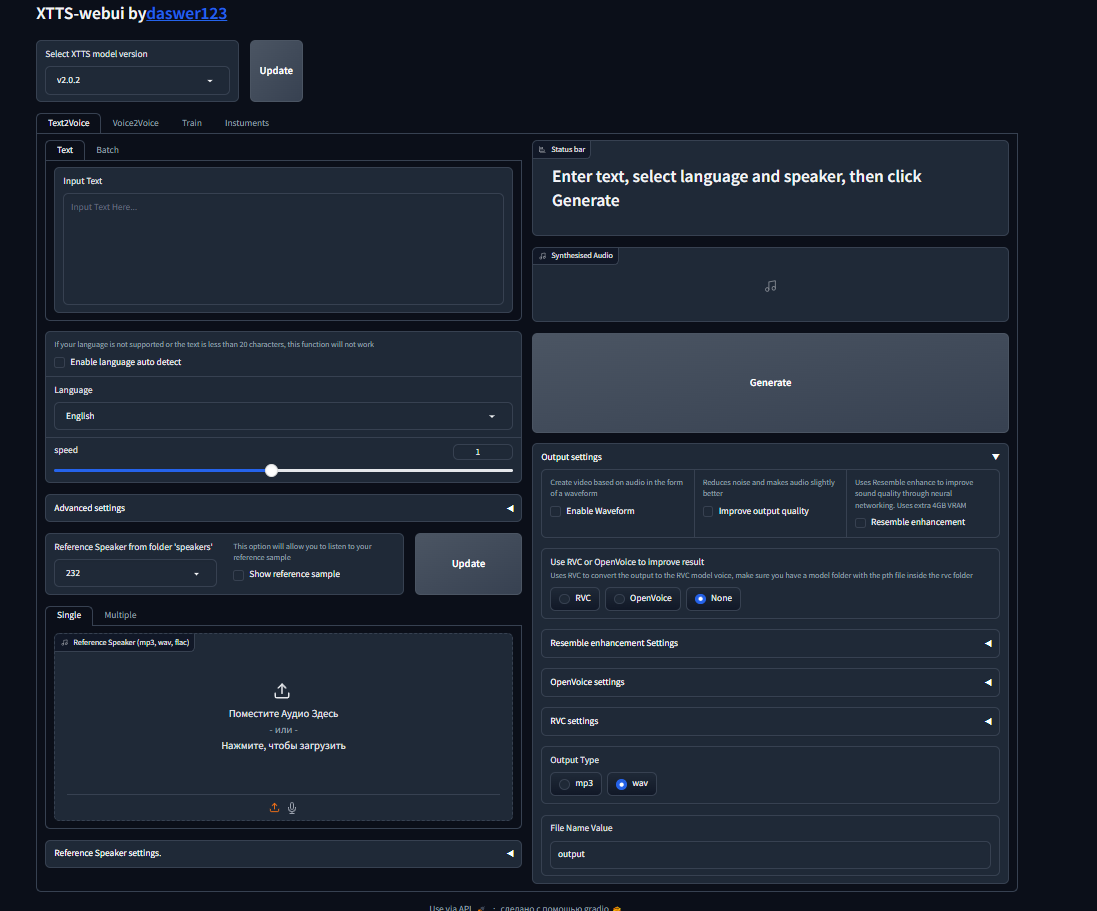
Google Colab을 통해이 웹 UI를 사용하십시오
Python 3.10.x 또는 Python 3.11, Cuda 11.8 또는 Cuda 12.1, C ++ 패키지가 포함 된 Microsoft Builder Tools 2019 및 FFMPEG가 설치되어 있는지 확인하십시오.
시작하려면 :
시작하려면 :
설치를 위해 다음 단계를 따르십시오.
CUDA 설치되어 있는지 확인하십시오
저장소 복제 : git clone https://github.com/daswer123/xtts-webui
디렉토리로 이동하십시오 : cd xtts-webui
가상 환경 생성 : python -m venv venv
가상 환경 활성화 :
venvscriptsactivatesource venvbinactivatePIP 명령으로 Pytorch 및 Torchaudio를 설치하십시오.
pip install torch==2.1.1+cu118 torchaudio==2.1.1+cu118 --index-url https://download.pytorch.org/whl/cu118
요구 사항에서 모든 종속성을 설치합니다 .txt :
pip install -r requirements.txt
인터페이스를 시작하려면 다음 단계를 따르십시오.
가상 환경 활성화 :
venv/scripts/activate또는 Linux에 있다면
source venv/bin/activate그런 다음이 명령을 실행하여 xtts 용 webui를 시작하십시오.
python app.py다음은 응용 프로그램을 시작할 때 사용할 수있는 몇 가지 런타임 인수입니다.
| 논쟁 | 기본값 | 설명 |
|---|---|---|
| -hs, -host | 127.0.0.1 | 묶는 호스트 |
| -P, -포트 | 8010 | 들을 포트 번호 |
| -d, - -디바이스 | 쿠다 | 사용할 장치 (CPU 또는 CUDA) |
| -sf,-speaker_folder | 스피커/ | TTS 샘플을 포함하는 디렉토리 |
| -o,-출력 | "산출/" | 출력 디렉토리 |
| -L,-언어 | "자동" | Webui Language, I18N/Locale 폴더에서 사용 가능한 번역을 볼 수 있습니다. |
| -ms,-모델 소스 | "현지의" | 모델 소스를 정의하십시오 : 리포지토리의 최신 버전의 'API', 로컬 추론 및 모델 v2.0.2 사용에 대한 '로컬'. |
| -v,-버전 | "v2.0.2" | 사용할 XTT의 XTT 버전을 지정할 수 있습니다. 이 목적에 대한 사용자 정의 모델의 이름을 지정할 수 있습니다. 폴더를 모델에 넣고이 플래그의 폴더 이름을 지정할 수 있습니다. |
| -lowvram | 적극적으로 처리하지 않을 때 모델을 RAM으로 전환하는 낮은 VRAM 모드 활성화 | |
| -깊이 속도 | 딥 스피드 가속도를 활성화합니다. Python 3.10 및 3.11의 Windows에서 작동합니다 | |
| --공유하다 | 로컬 컴퓨터 외부에서 인터페이스를 공유 할 수 있습니다 | |
| --rvc | RVC 후 처리 활성화는 모든 모델이 RVC 폴더에서 찾아야합니다. |
RVC 용 모듈, RVC 모듈이 수신 된 오디오를 후 처리 할 수 있도록 할 수 있습니다.
RVC 설정에서 모델이 작동하려면 먼저 Voice2Voice/RVC 폴더에 업로드 해야하는 모델을 선택해야합니다. 모델 및 인덱스 파일은 함께 있어야합니다. 색인 파일은 선택 사항이므로 각 모델은 별도의 폴더에 있어야합니다.


