xtts webui
Deepspeed wheels for Windows
Das Projekt verfügt jetzt über eine tragbare Version, sodass Sie sich nicht die Mühe machen müssen, alle Abhängigkeiten zu installieren.
Klicken Sie hier, um herunterzuladen
Sie brauchen nichts anderes als Windows und eine NVIDIA -Grafikkarte mit 6 GB Videospeicher, um sie auszuführen.
Englisch
Russisch
Português
XTTS-Webui ist eine Weboberfläche, mit der Sie das Beste aus XTTs nutzen können. Es gibt andere neuronale Netzwerke in dieser Oberfläche, die Ihre Ergebnisse verbessern. Sie können das Modell auch einstellen und ein hochwertiges Sprachmodell erhalten.
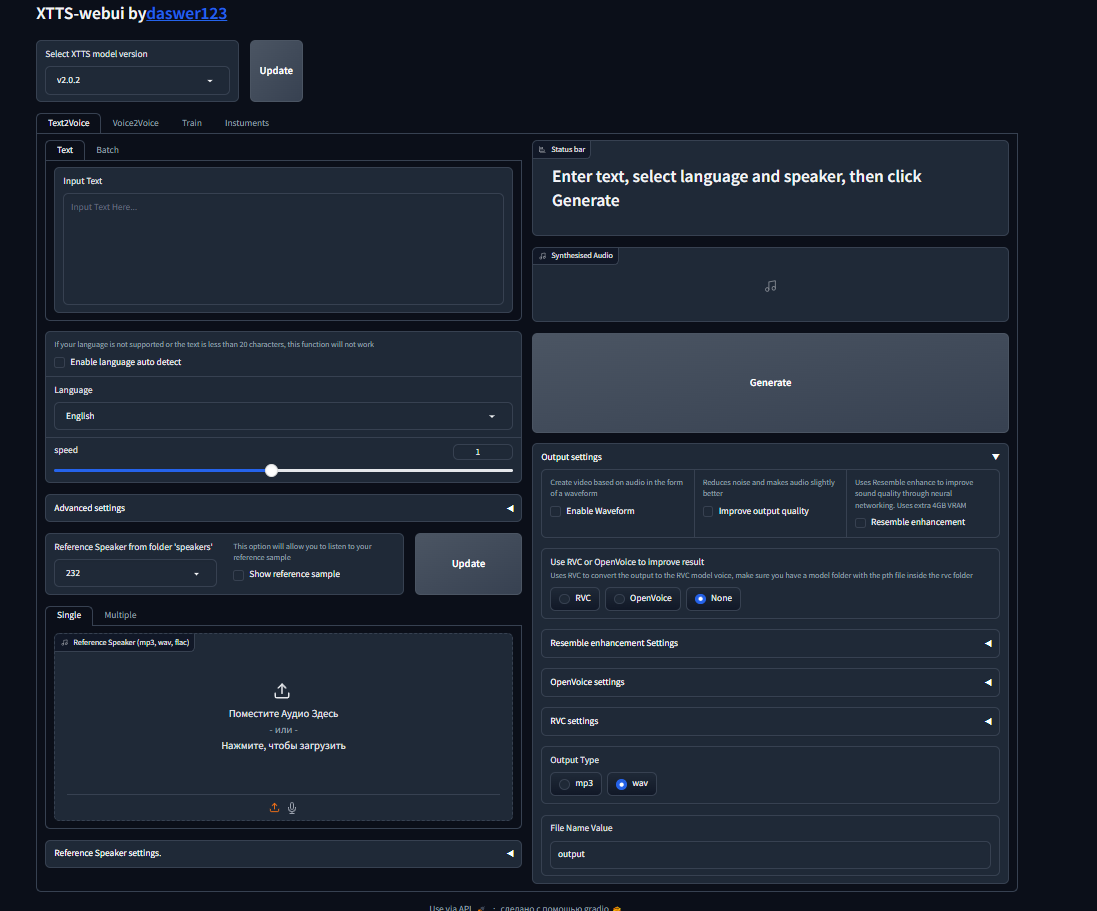
Verwenden Sie diese Web -Benutzeroberfläche über Google Colab
Bitte stellen Sie sicher
Um loszulegen:
Um loszulegen:
Befolgen Sie diese Schritte zur Installation:
Stellen Sie sicher, dass CUDA installiert ist
Klon das Repository: git clone https://github.com/daswer123/xtts-webui
Navigieren Sie in das Verzeichnis: cd xtts-webui
Erstellen Sie eine virtuelle Umgebung: python -m venv venv
Aktivieren Sie die virtuelle Umgebung:
venvscriptsactivatesource venvbinactivateInstallieren Sie Pytorch und Torchaudio mit PIP -Befehl:
pip install torch==2.1.1+cu118 torchaudio==2.1.1+cu118 --index-url https://download.pytorch.org/whl/cu118
Installieren Sie alle Abhängigkeiten von Anforderungen.txt:
pip install -r requirements.txt
Um die Schnittstelle zu starten, befolgen Sie bitte die folgenden Schritte:
Aktivieren Sie Ihre virtuelle Umgebung:
venv/scripts/activateoder wenn Sie unter Linux sind,
source venv/bin/activateStarten Sie dann das Webui für XTTs, indem Sie diesen Befehl ausführen:
python app.pyHier sind einige Laufzeitargumente, die beim Starten der Anwendung verwendet werden können:
| Argument | Standardwert | Beschreibung |
|---|---|---|
| -hs, -Host | 127.0.0.1 | Der Wirt zu binden an zu binden |
| -p, --port | 8010 | Die Portnummer zum Anhören |
| -d, -Gerät | CUDA | Welches Gerät zu verwenden (CPU oder CUDA) |
| -sf,-LEACHER_FOLDER | Sprecher/ | Verzeichnis mit TTS -Proben |
| -O,-Ausgabe | "Ausgabe/" | Ausgabeverzeichnis |
| -l,-Sprache | "Auto" | In Webui -Sprache können Sie die verfügbaren Übersetzungen im Ordner i18n/Gebietsschema sehen. |
| -Ms,-Modell-Source | "Lokal" | Definieren Sie die Modellquelle: 'API' für die neueste Version aus Repository, API -Inferenz oder „Lokal“ zur Verwendung lokaler Inferenz und Modell v2.0.2 |
| -v, -version | "v2.0.2" | Sie können angeben, welche Version von XTTs verwendet werden soll. Sie können den Namen des benutzerdefinierten Modells für diesen Zweck angeben. Stellen Sie den Ordner in Modelle ein und geben Sie den Namen des Ordners in diesem Flag an |
| -Lowvram | Aktivieren Sie den niedrigen VRAM -Modus, der das Modell auf RAM umschaltet, wenn sie nicht aktiv verarbeitet | |
| -Deepspeed | Aktivieren Sie die Beschleunigung der Deepspeed. Funktioniert unter Windows unter Python 3.10 und 3.11 | |
| --Aktie | Ermöglicht die gemeinsame Nutzung der Schnittstelle außerhalb des lokalen Computers | |
| -RVC | Aktivieren Sie die RVC-Nachbearbeitung. Alle Modelle sollten im RVC-Ordner lokalisieren |
Modul für RVC können Sie das RVC -Modul ermöglichen, das empfangene Audio dafür nachzuprobieren
Damit das Modell in RVC -Einstellungen funktioniert, müssen Sie ein Modell auswählen, das Sie zuerst in den Ordner Voice2Voice/RVC hochladen müssen. Das Modell und die Indexdatei müssen zusammen sein. Die Indexdatei ist optional. Jedes Modell muss sich in einem separaten Ordner befinden.


