xtts webui
Deepspeed wheels for Windows
Proyek ini sekarang memiliki versi portabel, jadi Anda tidak perlu kesulitan menginstal semua dependensi.
Klik di sini untuk mengunduh
Anda tidak membutuhkan apa pun kecuali Windows dan kartu grafis NVIDIA dengan memori video 6 GB untuk menjalankannya.
Bahasa inggris
Rusia
Portugu
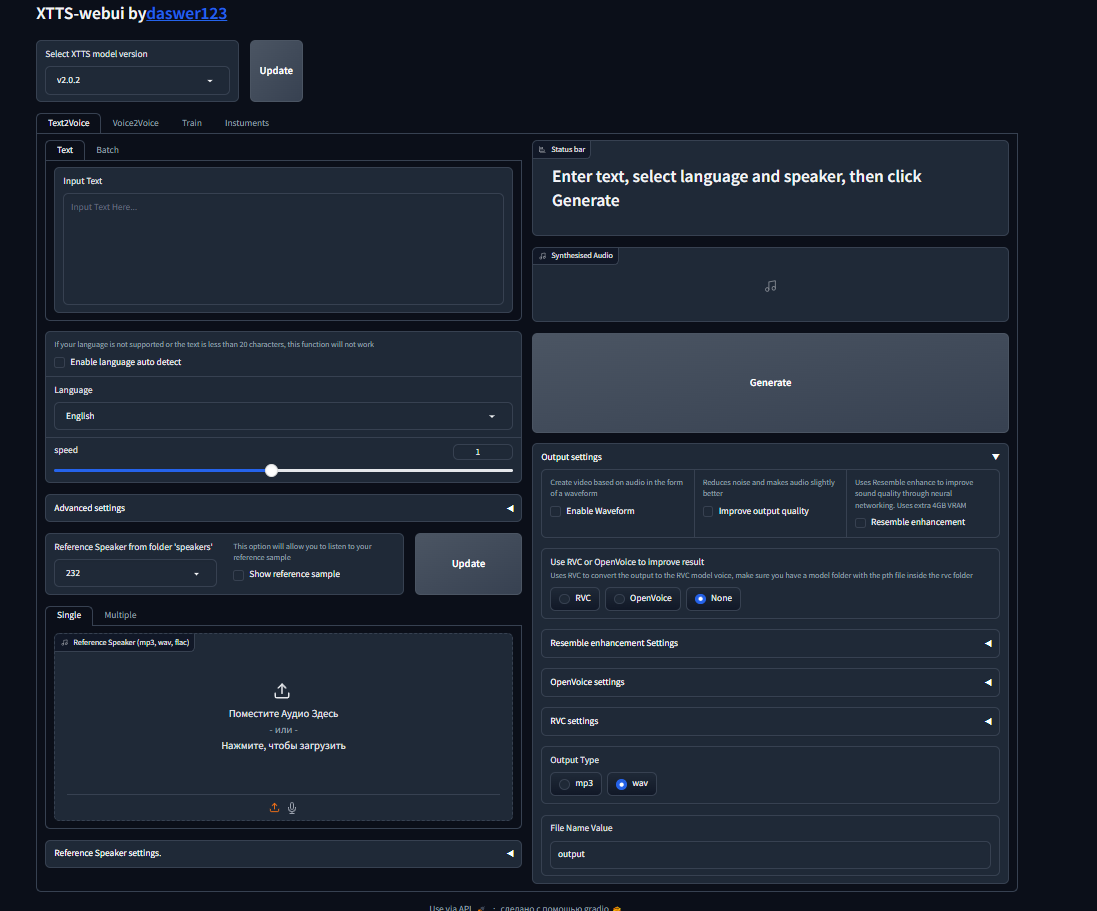
XTTS-WebUI adalah antarmuka web yang memungkinkan Anda memanfaatkan XTTS. Ada jaringan saraf lainnya di sekitar antarmuka ini yang akan meningkatkan hasil Anda. Anda juga dapat menyempurnakan model dan mendapatkan model suara berkualitas tinggi.
Gunakan UI Web ini melalui Google Colab
Harap pastikan Anda memiliki Python 3.10.x atau Python 3.11, CUDA 11.8 atau CUDA 12.1, Microsoft Builder Tools 2019 dengan paket C ++, dan FFMPEG diinstal
Untuk memulai:
Untuk memulai:
Ikuti langkah -langkah ini untuk instalasi:
Pastikan CUDA dipasang
Klon The Repository: git clone https://github.com/daswer123/xtts-webui
Navigasi ke direktori: cd xtts-webui
Buat lingkungan virtual: python -m venv venv
Aktifkan lingkungan virtual:
venvscriptsactivatesource venvbinactivateInstal Pytorch dan Torchaudio dengan perintah PIP:
pip install torch==2.1.1+cu118 torchaudio==2.1.1+cu118 --index-url https://download.pytorch.org/whl/cu118
Instal semua dependensi dari persyaratan.txt:
pip install -r requirements.txt
Untuk meluncurkan antarmuka, ikuti langkah -langkah ini:
Aktifkan lingkungan virtual Anda:
venv/scripts/activateAtau jika Anda berada di Linux,
source venv/bin/activateKemudian mulailah webui untuk xts dengan menjalankan perintah ini:
python app.pyBerikut adalah beberapa argumen runtime yang dapat digunakan saat memulai aplikasi:
| Argumen | Nilai default | Keterangan |
|---|---|---|
| -hs, --host | 127.0.0.1 | Tuan rumah untuk mengikat |
| -p, --port | 8010 | Nomor port untuk mendengarkan |
| -D, --Device | Cuda | Perangkat mana yang akan digunakan (CPU atau CUDA) |
| -sf,-speaker_folder | speaker/ | Direktori yang berisi sampel TTS |
| -O,-output | "keluaran/" | Direktori Output |
| -l,-bahasa | "mobil" | Bahasa WebUI, Anda dapat melihat terjemahan yang tersedia di folder i18n/lokal. |
| -ms,-model-sumber | "lokal" | Tentukan sumber model: 'API' untuk versi terbaru dari repositori, inferensi API atau 'lokal' untuk menggunakan inferensi lokal dan model v2.0.2 |
| -v, -version | "v2.0.2" | Anda dapat menentukan versi XTTS mana yang akan digunakan. Anda dapat menentukan nama model khusus untuk tujuan ini, masukkan folder dalam model dan tentukan nama folder di bendera ini |
| --lowvram | Aktifkan mode VRAM rendah yang mengganti model ke RAM saat tidak memproses secara aktif | |
| -DEEP SPEED | Aktifkan percepatan kecepatan deep. Bekerja di Windows on Python 3.10 dan 3.11 | |
| --membagikan | Memungkinkan berbagi antarmuka di luar komputer lokal | |
| --RVC | Aktifkan RVC pasca pemrosesan, semua model harus ditemukan di folder RVC |
Modul untuk RVC, Anda dapat mengaktifkan modul RVC untuk postprocess audio yang diterima untuk ini, Anda perlu menambahkan bendera -RVC jika Anda berjalan di konsol atau menulisnya ke file startup
Agar model berfungsi dalam pengaturan RVC, Anda harus memilih model yang harus Anda unggah terlebih dahulu ke folder Voice2Voice/RVC, model dan file indeks harus bersama, file indeks opsional, setiap model harus dalam folder terpisah.


