Lightzero
2024.12.10에 업데이트 된 Lightzero-V0.1.0
영어 | 简体中文 (단순화 된 중국어) | 문서 | Lightzero Paper | Unizero 종이 | Rezero 종이
Lightzero는 몬테 카를로 트리 검색 (MCT)과 심층 강화 학습 (RL)을 결합한 가볍고 효율적이며 이해하기 쉬운 오픈 소스 알고리즘 툴킷입니다. Lightzero에 대한 질문은 rag 기반 Q & A 보조자 인 Zeropal과 상담 할 수 있습니다.
? 배경
Alphazero와 Muzero가 예시 한 Monte Carlo Tree Search와 Deep Intercement Learning의 통합은 Go 및 Atari를 포함한 다양한 게임에서 전례없는 성능 수준을 달성했습니다. 이 고급 방법론은 또한 단백질 구조 예측 및 행렬 곱셈 알고리즘과 같은 과학 영역에서 상당한 진전을 이루었습니다. 다음은 Monte Carlo Tree Search 알고리즘 시리즈의 역사적 진화에 대한 개요입니다.
위의 그림은 Lightzero의 프레임 워크 파이프 라인입니다. 아래의 세 가지 핵심 모듈을 간략하게 소개합니다.
모델 : Model 네트워크 구조 초기화를위한 __init__ 함수와 네트워크의 전달 전파를 계산하기위한 forward 기능을 포함하여 네트워크 구조를 정의하는 데 사용됩니다.
정책 : Policy 네트워크가 업데이트되는 방식을 정의하고 learning 프로세스, collecting 프로세스 및 evaluation 프로세스의 세 가지 프로세스를 포함하여 환경과 상호 작용합니다.
MCTS : MCTS Monte Carlo 검색 트리의 구조와 정책과 상호 작용하는 방식을 정의합니다. MCT의 구현에는 ptree 및 ctree 에서 각각 구현 된 Python과 C ++의 두 가지 언어가 포함됩니다.
Lightzero의 파일 구조는 Lightzero_file_structure를 참조하십시오.
? 통합 알고리즘
Lightzero는 Pytorch가 MCTS 알고리즘 (때로는 Cython 및 CPP와 결합)을 구현하는 라이브러리입니다.
- 알파 자로
- Muzero
- 샘플링 된 Muzero
- 확률 적 무제로
- 효율적인 제로
- Gumbel Muzero
- Rezero
- Unizero
현재 Lightzero가 지원하는 환경 및 알고리즘은 아래 표에 나와 있습니다.
| Env./algo. | 알파 자로 | Muzero | 샘플링 된 Muzero | 효율적인 제로 | 샘플링 효율적인 제로 | Gumbel Muzero | 확률 적 무제로 | Unizero | 샘플링되지 않은 유니에로 | Rezero |
|---|
| Tictactoe | ✔ | ✔ | | | | ✔ | | ✔ | | |
| 고모 쿠 | ✔ | ✔ | | | | ✔ | | ✔ | | ✔ |
| 연결 4 | ✔ | ✔ | | | | | | ✔ | | ✔ |
| 2048 | --- | ✔ | | | | | ✔ | ✔ | | |
| 체스 | | | | | | | | | | |
| 가다 | | | | | | | | | | |
| 카트 폴 | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| 흔들리는 추 | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ | |
| LUNARLANDER | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Bipedalwalker | --- | ✔ | ✔ | ✔ | ✔ | ✔ | | | ✔ | |
| 아타리 | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| 심한 통제 | --- | --- | ✔ | --- | ✔ | | | | ✔ | |
| 무자코 | --- | ✔ | | ✔ | ✔ | | | | | |
| 마이너 리드 | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Bsuite | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| 메모리 | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Sumtothree (당구) | --- | | | | ✔ | | | | | |
| MetAdrive | --- | | | | ✔ | | | | | |
(1) : "" "는 해당 항목이 완성되고 잘 테스트되었음을 의미합니다.
(2) : ""는 해당 항목이 대기 목록에 있음을 의미합니다 (진행중인 작업).
(3) : "---"는이 알고리즘 이이 환경을 지원하지 않음을 의미합니다.
설치
다음 명령으로 GitHub 소스 코드에서 개발중인 최신 Lightzero를 설치할 수 있습니다.
git clone https://github.com/opendilab/LightZero.git
cd LightZero
pip3 install -e .
Lightzero는 현재 Linux 및 macOS 플랫폼에서만 컴파일을 지원합니다. 우리는이 지원을 Windows 플랫폼으로 확장하기 위해 적극적으로 노력하고 있습니다. 이 전환 중 인내심은 크게 감사합니다.
Docker와의 설치
또한 Lightzero 라이브러리를 실행하는 데 필요한 모든 종속성을 갖춘 환경을 설정하는 Dockerfile을 제공합니다. 이 Docker 이미지는 Ubuntu 20.04를 기반으로하며 다른 필요한 도구 및 라이브러리와 함께 Python 3.8을 설치합니다. Dockerfile을 사용하여 Docker 이미지를 만들고이 이미지에서 컨테이너를 실행하고 컨테이너 내부에서 Lightzero 코드를 실행하는 방법은 다음과 같습니다.
- Dockerfile 다운로드 : Dockerfile은 Lightzero 저장소의 루트 디렉토리에 있습니다. 이 파일을 로컬 컴퓨터로 다운로드하십시오.
- 빌드 컨텍스트 준비 : 로컬 컴퓨터에서 새 빈 디렉토리를 만들고 DockerFile을이 디렉토리로 이동 한 다음이 디렉토리로 이동하십시오. 이 단계는 빌드 프로세스 중에 불필요한 파일을 Docker 데몬으로 보내지 않도록하는 데 도움이됩니다.
mkdir lightzero-docker
mv Dockerfile lightzero-docker/
cd lightzero-docker/
- Docker Image 빌드 : 다음 명령을 사용하여 Docker 이미지를 작성하십시오. 이 명령은 dockerfile이 포함 된 디렉토리 내부에서 실행해야합니다.
docker build -t ubuntu-py38-lz:latest -f ./Dockerfile .
- 이미지에서 컨테이너를 실행하십시오 . 다음 명령을 사용하여 Bash Shell과 대화식 모드의 이미지에서 컨테이너를 시작하십시오.
docker run -dit --rm ubuntu-py38-lz:latest /bin/bash
- 컨테이너 내부에서 Lightzero 코드를 실행하십시오 : 컨테이너 내부에 있으면 다음 명령으로 예제 Python 스크립트를 실행할 수 있습니다.
python ./LightZero/zoo/classic_control/cartpole/config/cartpole_muzero_config.py
빠른 시작
Muzero 에이전트를 훈련시켜 카트 폴을 재생하십시오.
cd LightZero
python3 -u zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Muzero 에이전트를 훈련 시키십시오.
cd LightZero
python3 -u zoo/atari/config/atari_muzero_segment_config.py
Tictactoe를 연주하기 위해 Muzero 에이전트를 훈련시킵니다.
cd LightZero
python3 -u zoo/board_games/tictactoe/config/tictactoe_muzero_bot_mode_config.py
멍청한 대리인을 훈련 시키십시오.
cd LightZero
python3 -u zoo/atari/config/atari_unizero_segment_config.py
선적 서류 비치
Lightzero 문서는 여기에서 찾을 수 있습니다. 자습서와 API 참조가 포함되어 있습니다.
환경 및 알고리즘 사용자 정의에 관심이있는 사람들을 위해 관련 안내서를 제공합니다.
- 환경을 사용자 정의하십시오
- 알고리즘을 사용자 정의합니다
- 구성 파일을 설정하는 방법?
- 로깅 및 모니터링 시스템
궁금한 점이 있으시면 언제든지 저희에게 연락하십시오.
기준
확장하려면 클릭하십시오
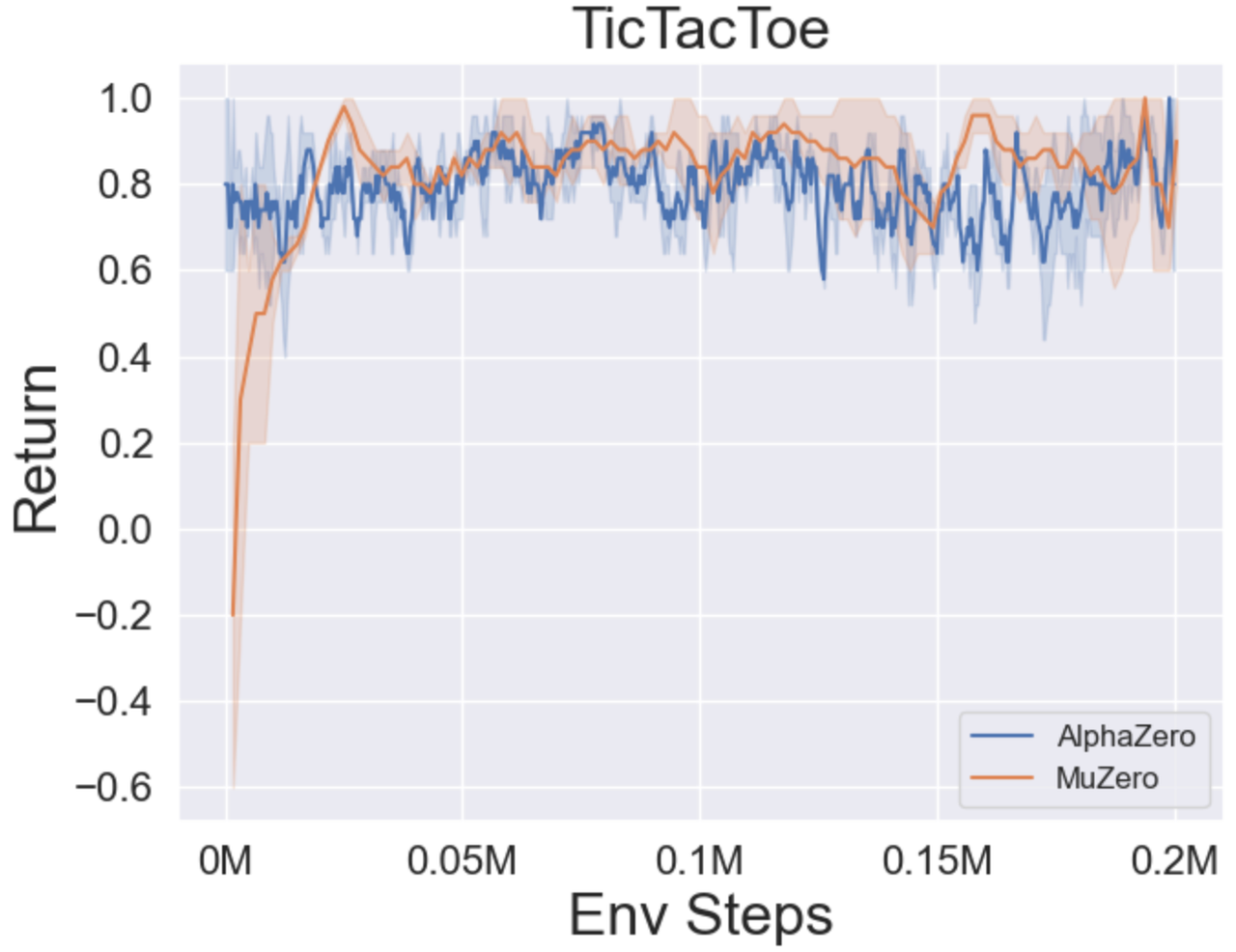
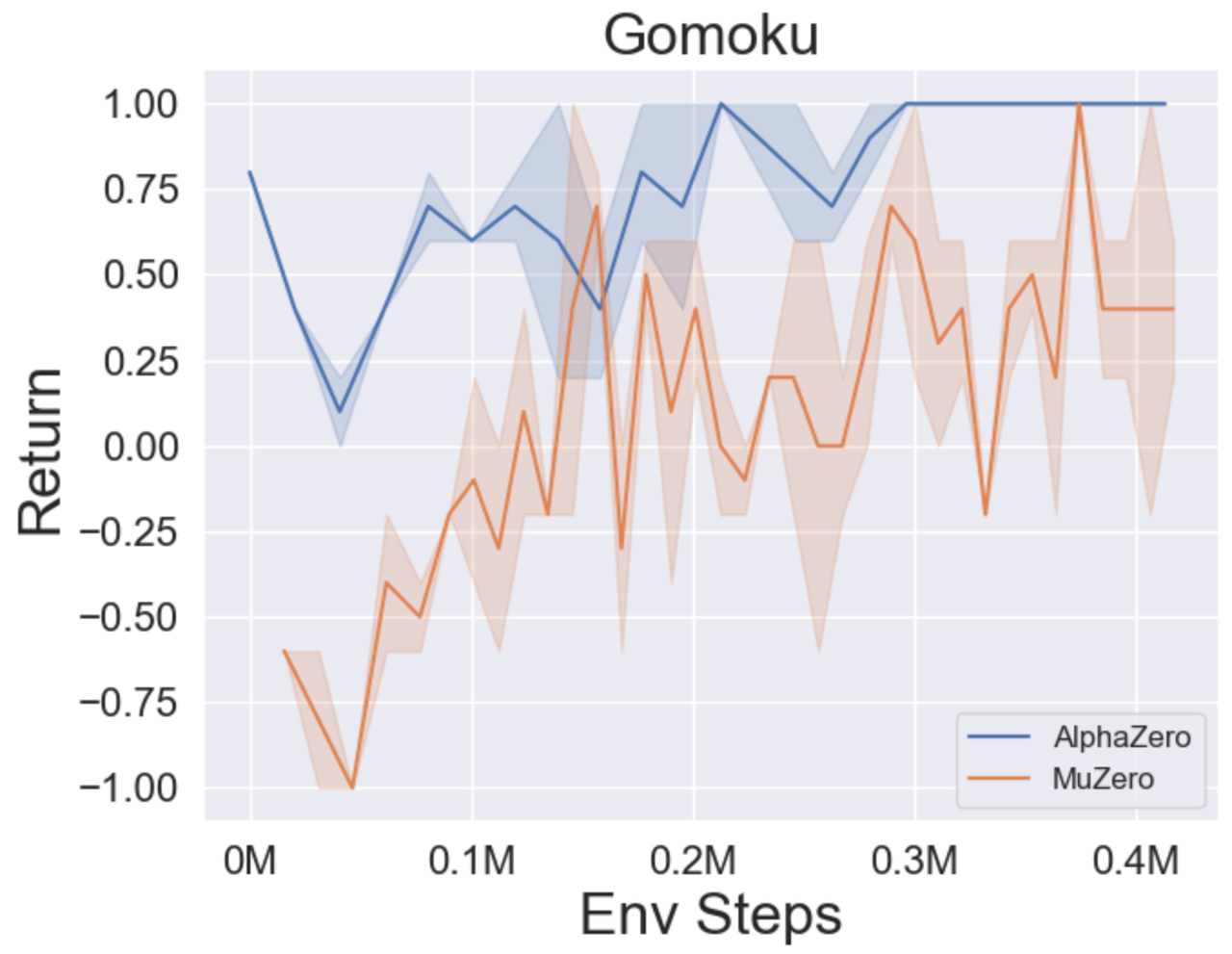
- 다음은 Tictactoe, Connect4, Gomoku의 세 가지 보드 게임에서 Alphazero와 Muzero의 벤치 마크 결과입니다.
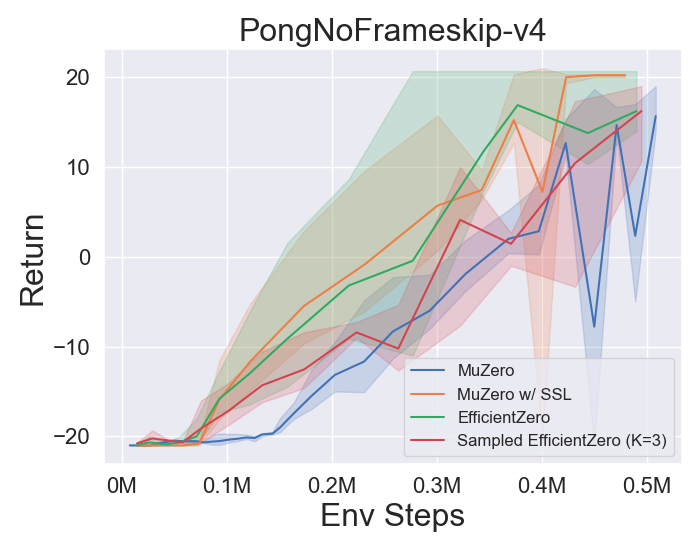
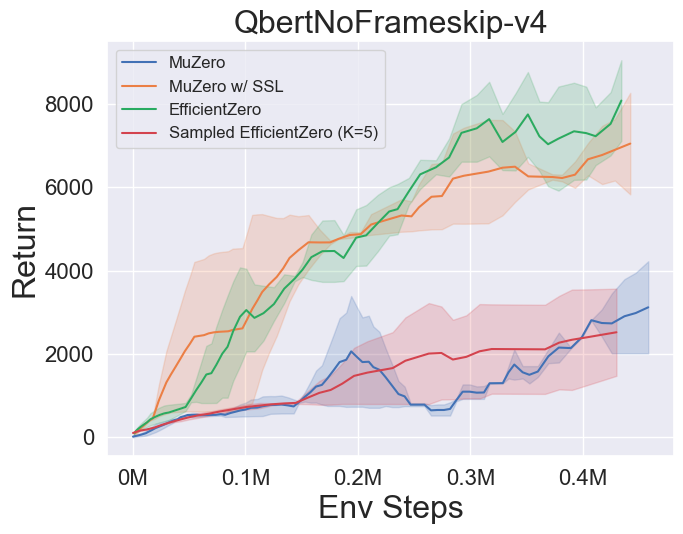
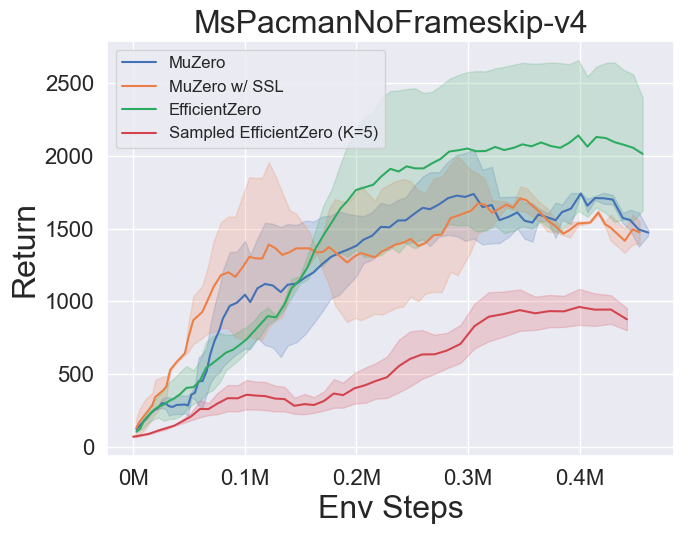
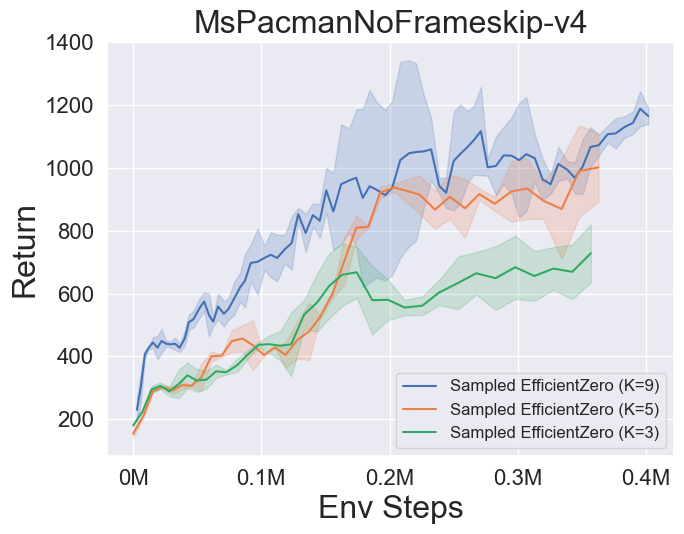
- 다음은 Atari의 3 개의 개별 액션 공간 게임에서 Muzero, Muzero w/ SSL, Engicativezero 및 Sampled Engicitied Zero의 벤치 마크 결과입니다.
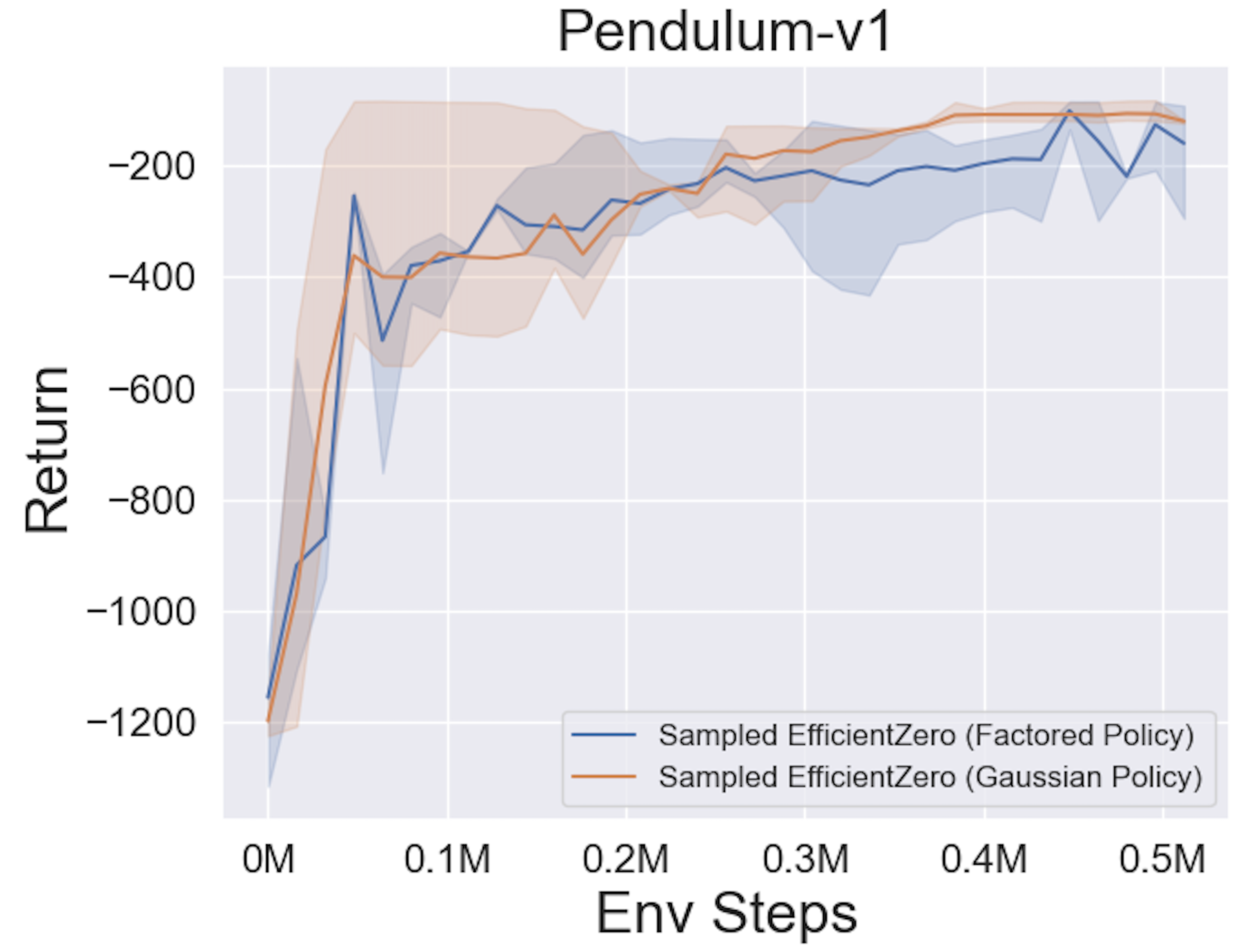
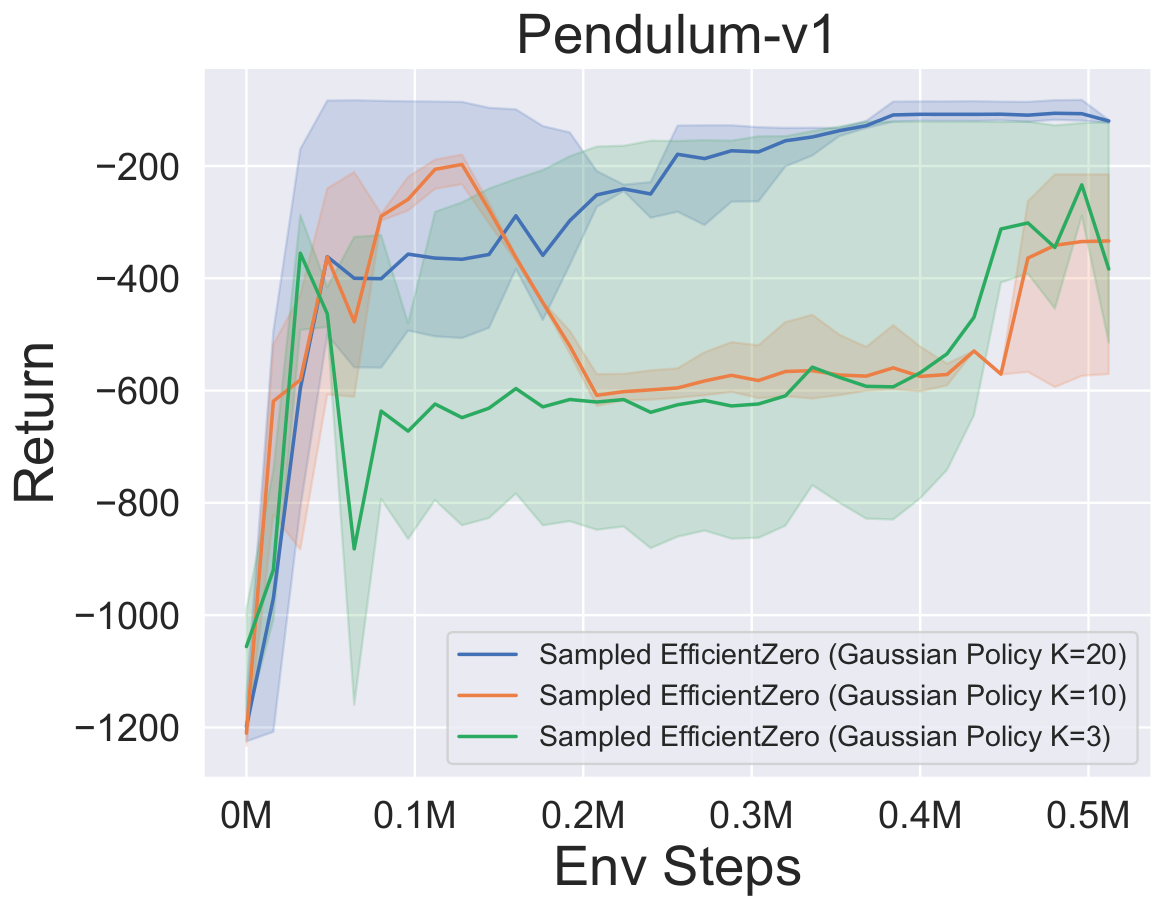
- 다음은 3 개의 고전적인 연속 액션 공간 게임에 대한
Factored/Gaussian 정책 표현과 함께 Sampled Engicitied Zero의 벤치 마크 결과 : Pendulum-V1, Lunarlandercontinous-V2, Bipedalwalker-V3 및 2 개의 Mujoco 연속 액션 스페이스 게임 : Hopper-V3, Walker2D-V3.
"Fortored Policy"는 에이전트가 범주 분포를 출력하는 정책 네트워크를 학습 함을 나타냅니다. 수동 이산 후, 5 개의 환경에 대한 동작 공간의 치수는 각각 11, 49 (7^2), 256 (4^4), 64 (4^3) 및 4096 (4^6)입니다. 반면, "가우스 정책"은 가우스 분포에 대한 매개 변수 (MU 및 Sigma)를 직접 출력하는 정책 네트워크를 학습하는 에이전트를 말합니다.
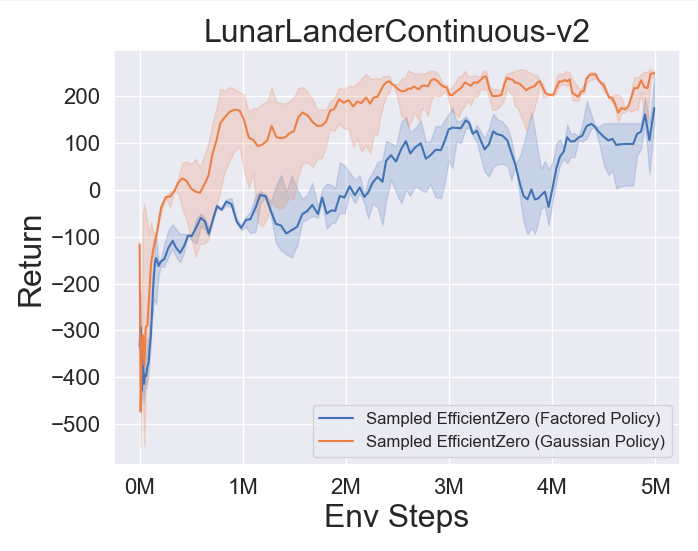
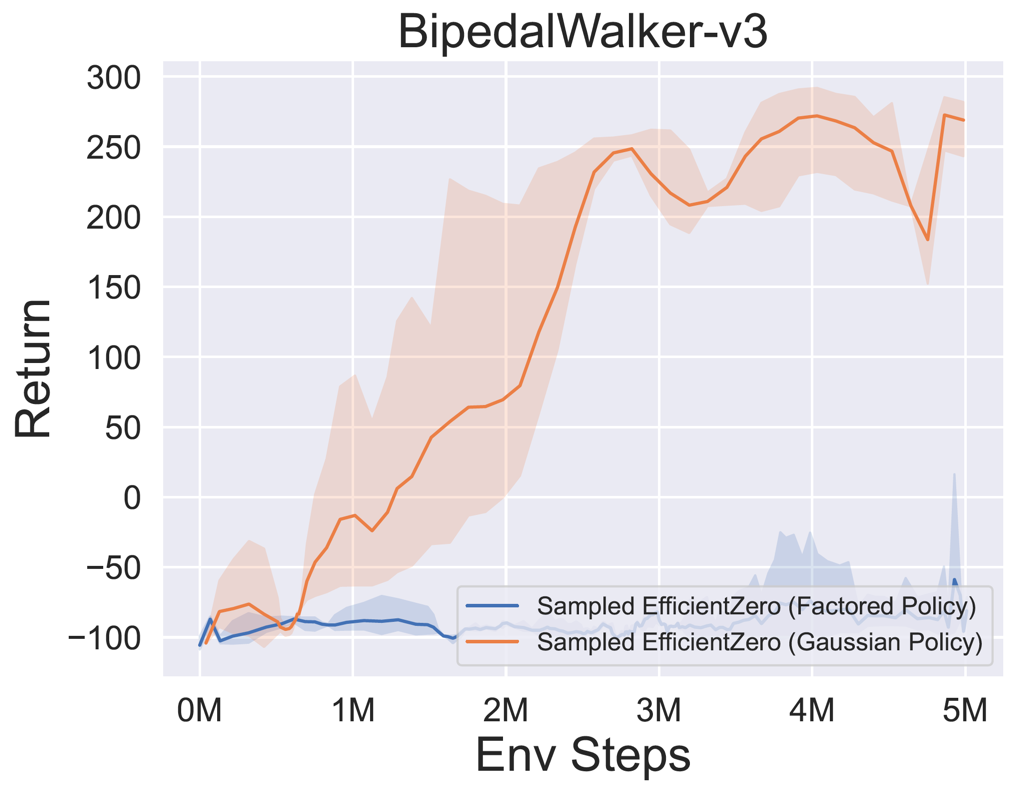
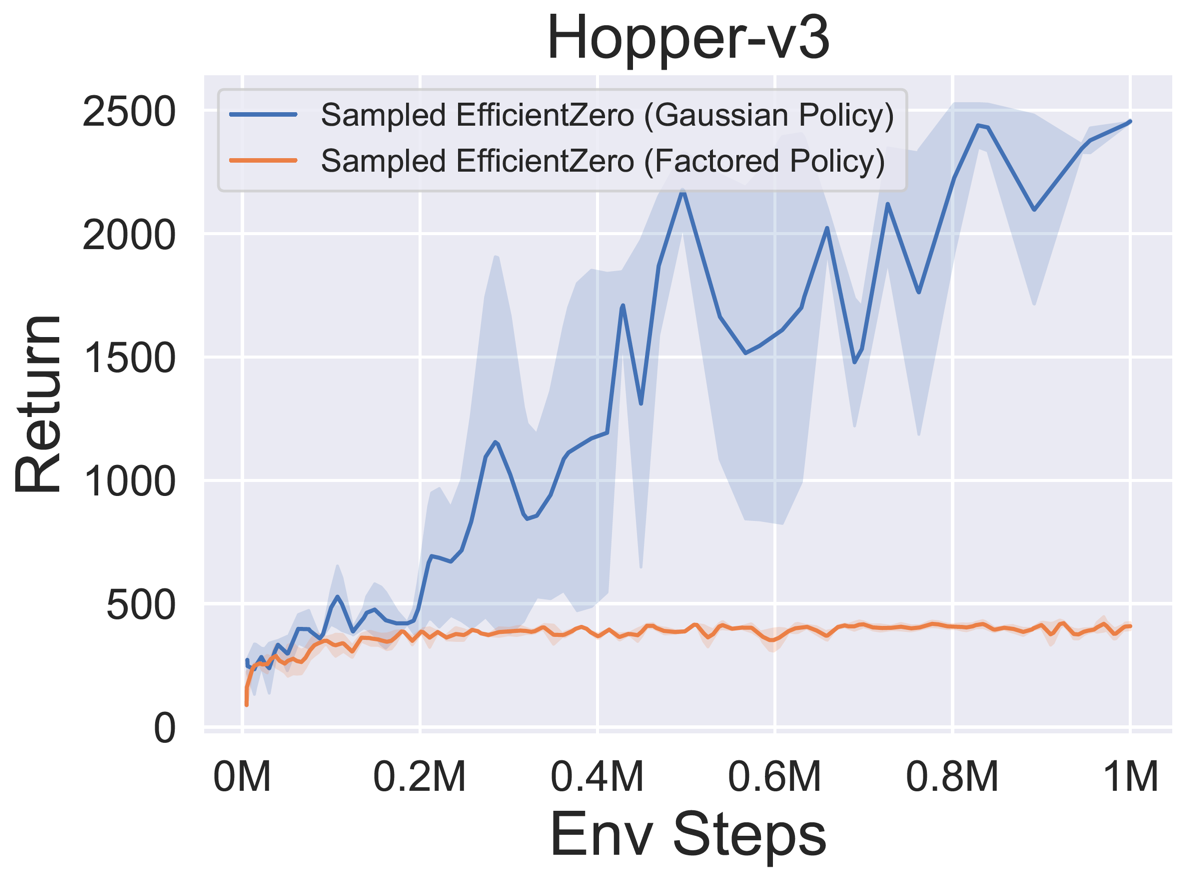
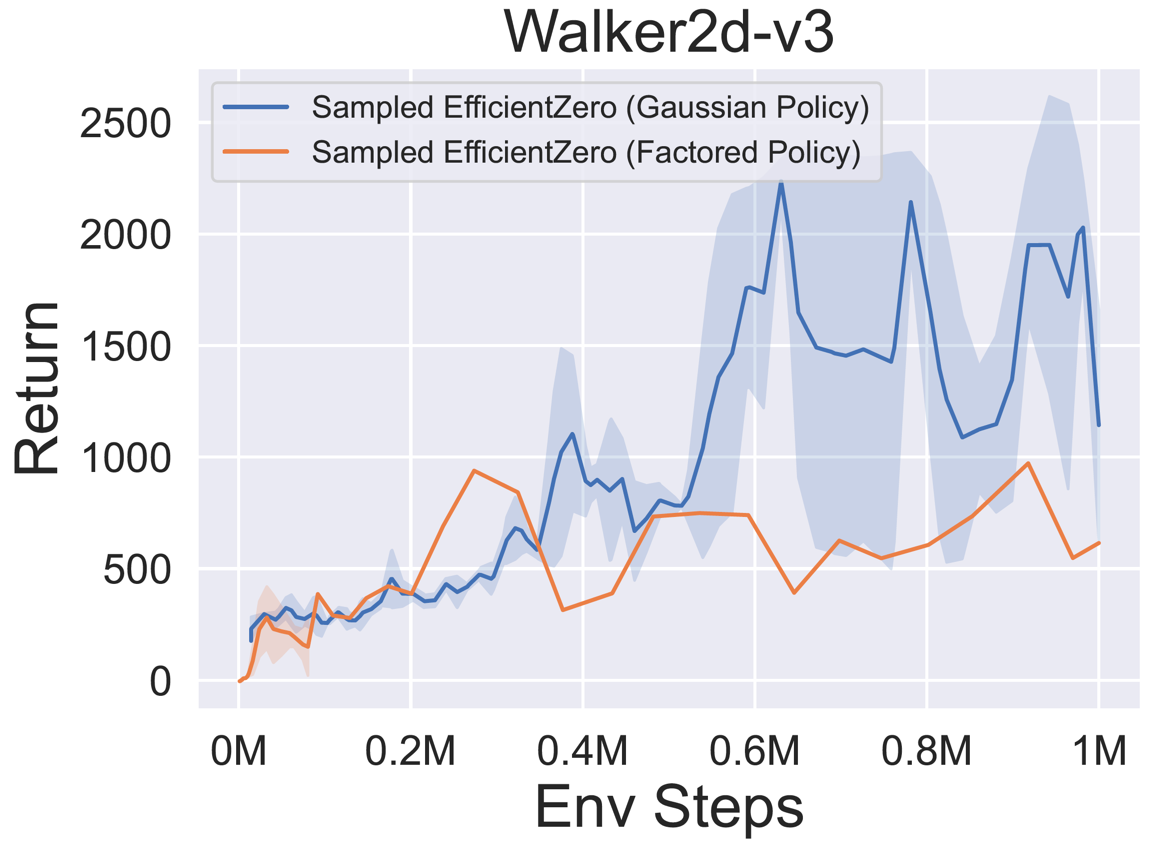
- 다음은 Pongnoframeskip-V4, MSPACMannoframeskip-V4, Gomoku 및 LunarlanderContinuous-V2의 네 가지 환경에서 Gumbelmuzero 및 Muzero (다른 시뮬레이션 비용에 따라)의 벤치 마크 결과입니다.
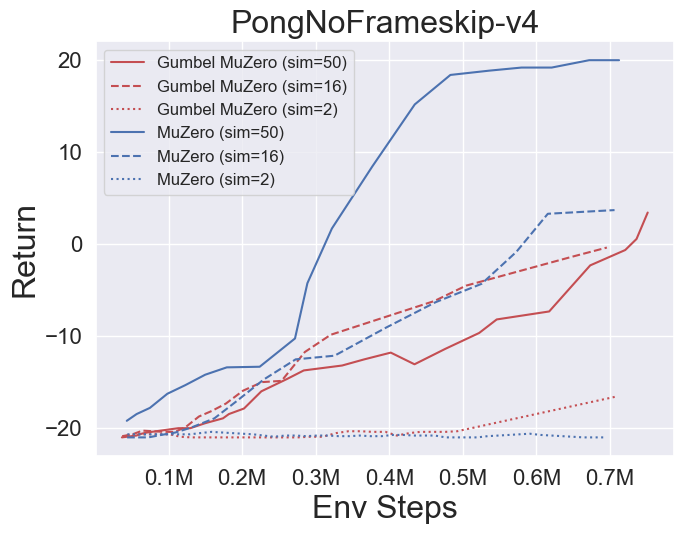
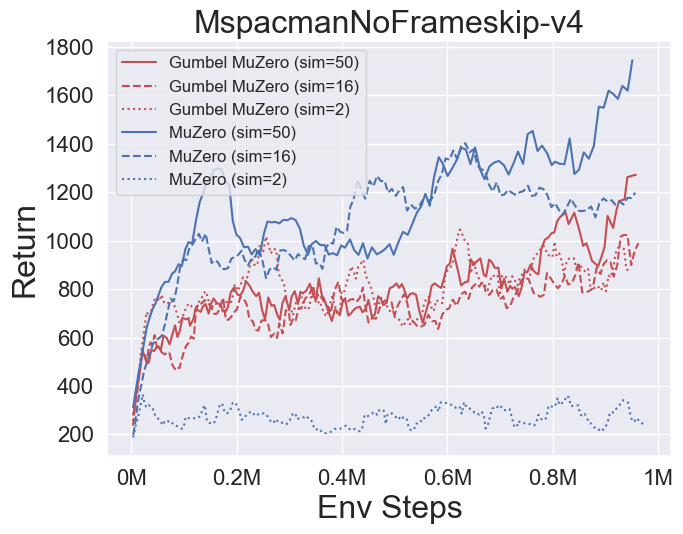
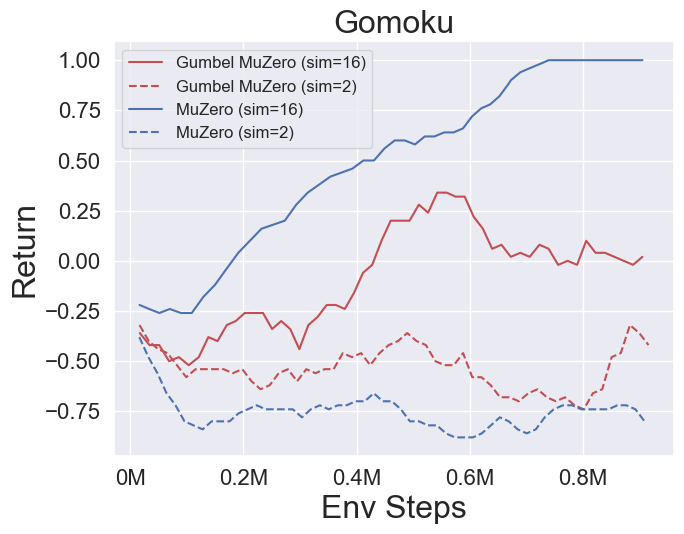
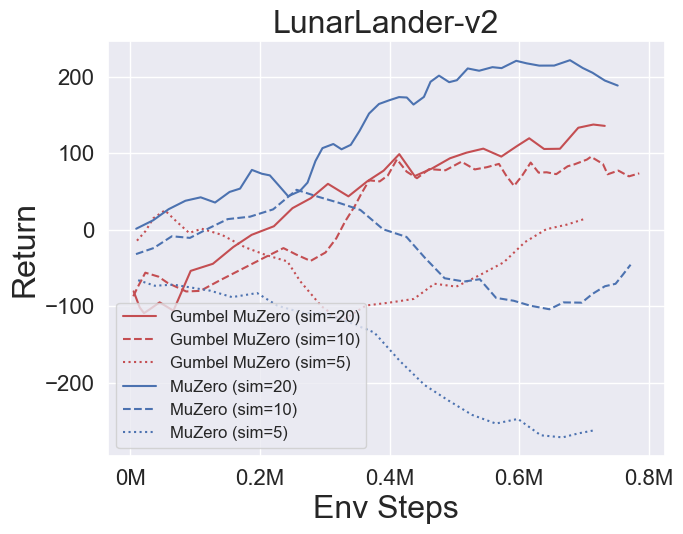
- 다음은 다양한 기회 수준 (Num_chances = 2 및 5)을 갖는 2048 환경에서 Stochasticmuzero 및 Muzero의 벤치 마크 결과입니다.
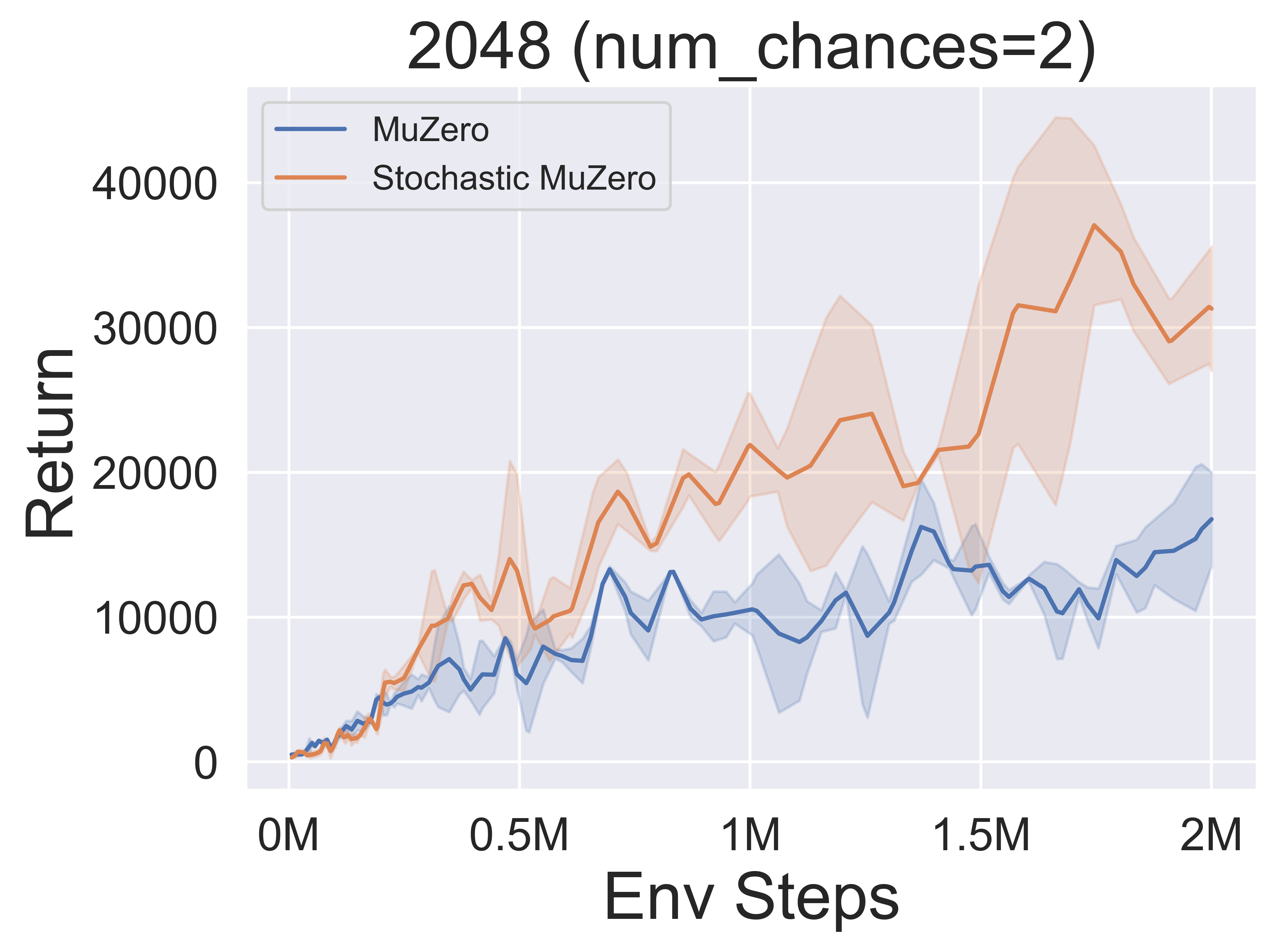
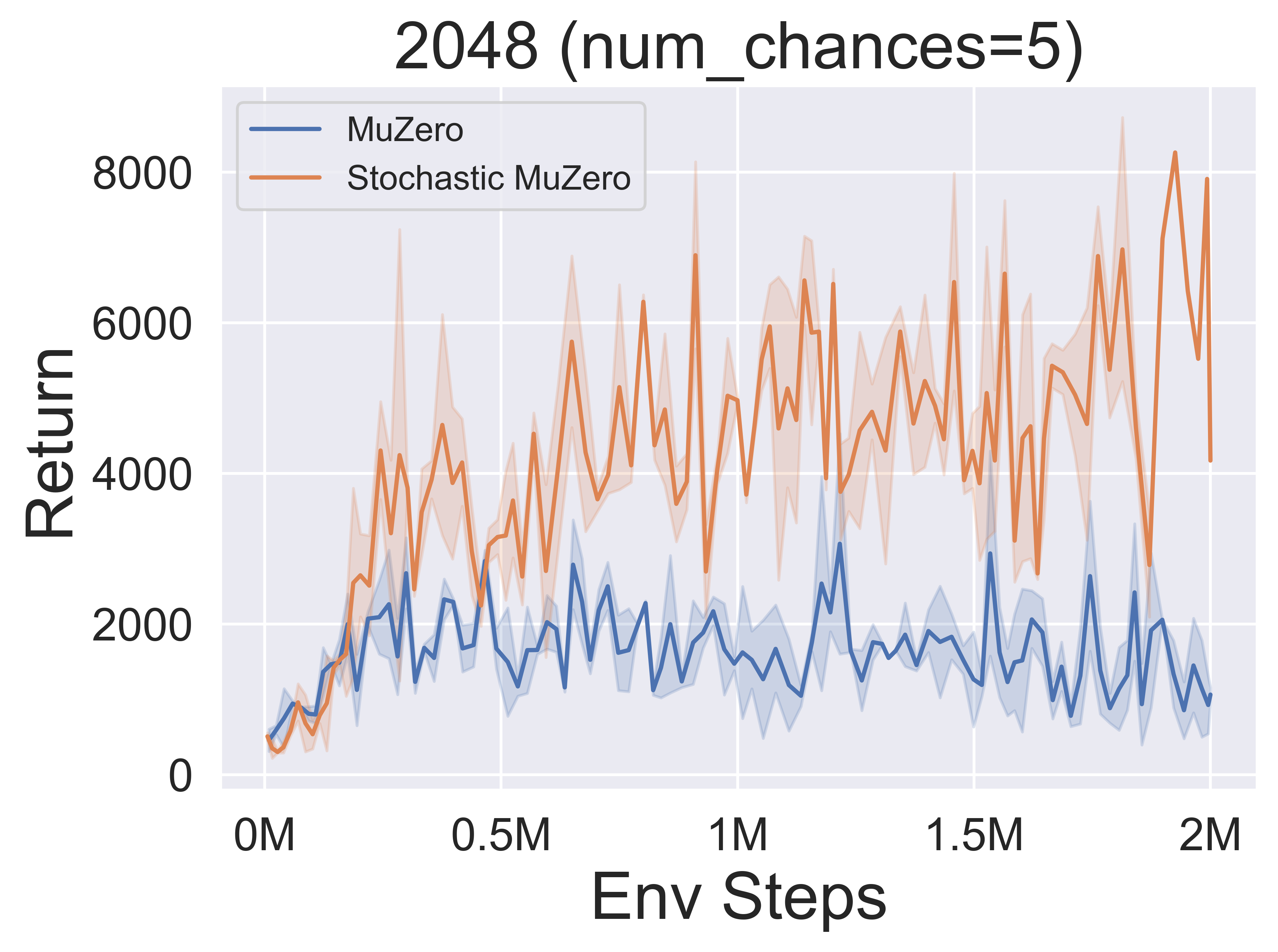
- 다음은 Minigrid 환경에서 Muzero w/ SSL의 다양한 MCTS 탐사 메커니즘의 벤치 마크 결과입니다.
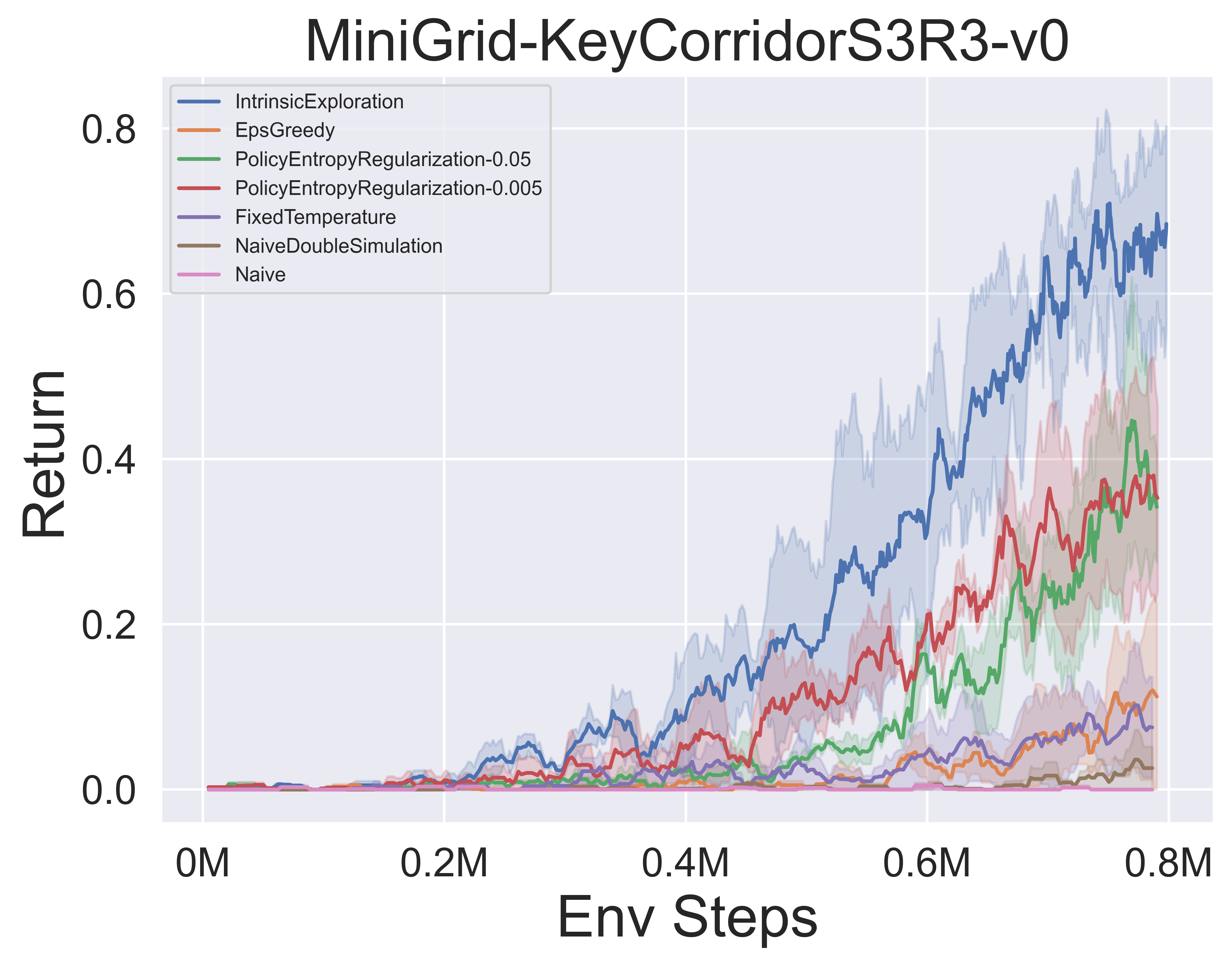
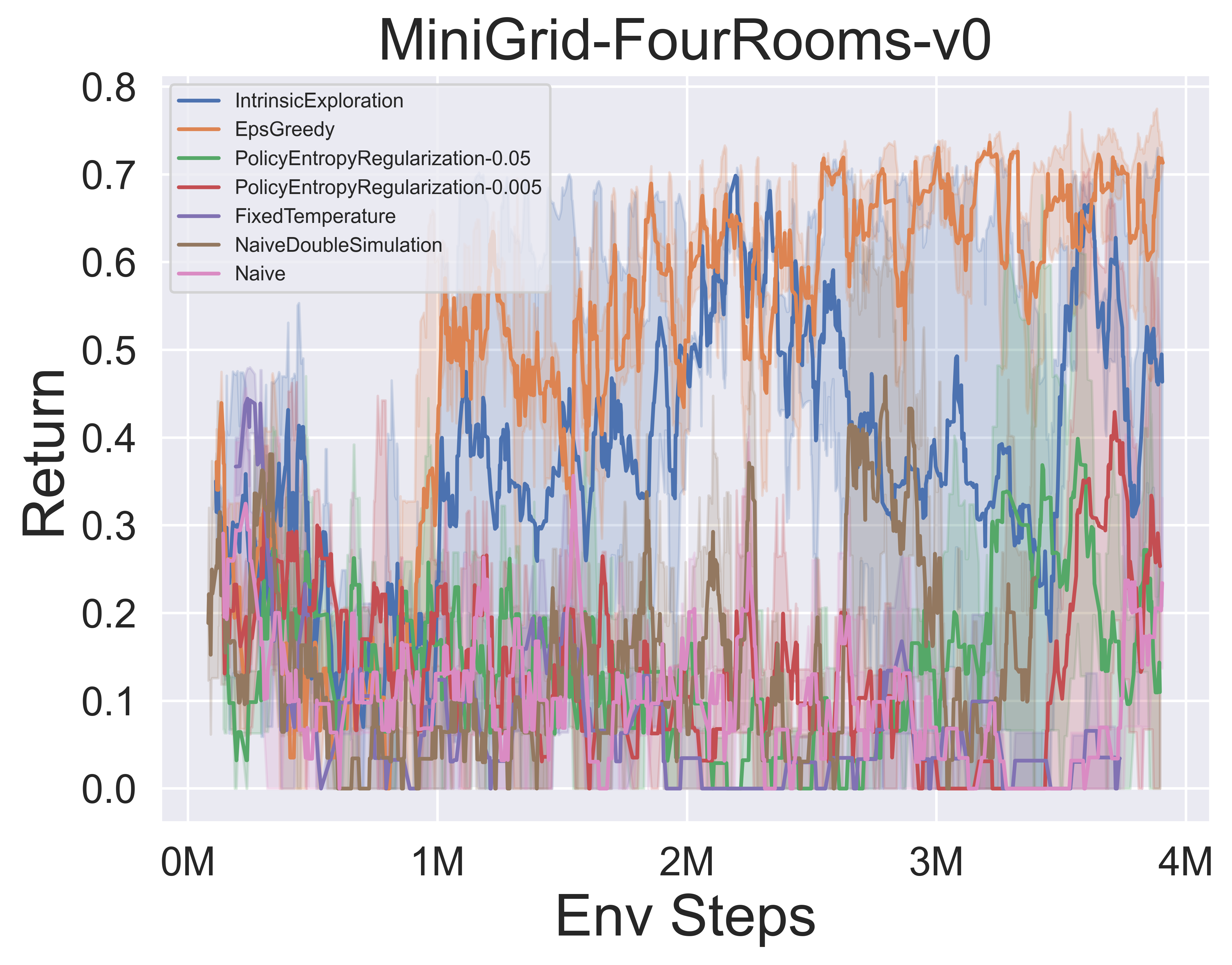
멋진 MCTS 노트
종이 노트
다음은 위의 알고리즘의 세부 논문 노트 (중국어)입니다.
붕괴하려면 클릭하십시오
- 알파 자로
- Muzero
- 효율적인 제로
- SampledMuzero
- 검 벨무 제로
- Stochasticmuzero
- 표현할 수 없습니다
또한 관련 Zhihu 열 (중국어) : MCTS+RL 프론티어 이론 및 응용 프로그램의 심층 분석을 참조하십시오.
알고. 개요
다음은 위의 알고리즘의 개요 MCTS 원칙 다이어그램입니다.
확장하려면 클릭하십시오
- 맥트
- 알파 자로
- Muzero
- 효율적인 제로
- SampledMuzero
- 검 벨무 제로
- Stochasticmuzero
멋진 MCTS 논문
다음은 Monte Carlo Tree Search에 관한 연구 논문 모음입니다. 이 섹션은 MCT의 국경을 추적하기 위해 지속적으로 업데이트됩니다.
주요 논문
확장하려면 클릭하십시오
Lightzero는 시리즈를 구현했습니다
- 2018 Science Alphazero : Chess, Shogi를 마스터하고 자체 플레이를하는 일반적인 강화 학습 알고리즘
- 2019 Muzero : 학습 된 모델로 계획하여 Atari, Go, Chess 및 Shogi 마스터
- 2021 효율적인 Zero : 데이터가 제한된 Atari 게임 마스터 링
- 2021 샘플링 된 Muzero : 복잡한 액션 공간에서의 학습 및 계획
- 2022 확률 론적 Muzero : 학습 된 모델로 확률 론적 환경에서의 계획
- 2022 Gumbel Muzero : Gumbel과의 계획을 통한 정책 개선
알파고 시리즈
- 2015 Nature Alphago Deep Neural Networks 및 Tree Search와 함께 이동 게임 마스터 링
- 2017 Nature Alphago Zero 인간 지식없이 Go의 게임 마스터 링
- 2019 ELF Opengo : Alphazero의 분석 및 공개 재 구현
- 2023 게임의 학생 : 완벽하고 불완전한 정보 게임을위한 통일 학습 알고리즘
Muzero 시리즈
- 2022 학습 된 모델로 계획하여 온라인 및 오프라인 강화 학습
- 2021 계획을위한 벡터 양자화 모델
- 2021 Muesli : 정책 최적화의 개선을 결합합니다.
MCTS 분석
- 2020 정규화 된 정책 최적화로서 Monte-Carlo 트리 검색
- 2021 자기 일관된 모델과 가치
- 2022 적대적 정책은 전문 수준의 GO AI를 이겼습니다
- 2022 Alphazero에서 체스 지식의 PNAS 획득.
MCTS 응용 프로그램
- 2023 Symbolic Physics Learner : Monte Carlo Tree Search를 통한 통치 방정식 발견
- 2022 자연 강화 학습을 통한 더 빠른 매트릭스 곱셈 알고리즘 발견
- 2022 VP9 비디오 압축에서 속도 제어를위한 자체 경쟁이있는 Muzero
- 2021 Douzero : 자기 놀이 깊은 강화 학습을 통해 Doudizhu를 마스터 링
- 2019 자율 주행을위한 전술적 의사 결정에서 계획과 깊은 강화 학습 결합
다른 논문
확장하려면 클릭하십시오
ICML
- Monte Carlo Tree Search 2023을 통한 확장 가능한 안전 정책 개선
- Alberto Castellini, Federico Bianchi, Edoardo Zorzi, Thiago D. Simão, Alessandro Farinelli, Matthijs TJ Spaan
- 키 : MCTS 기반 전략을 사용하여 온라인으로 안전한 정책 개선, 기본 부트 스트랩을 통한 안전한 정책 개선
- Expenv : Gridworld 및 Sysadmin
- 경로 일관성 2022를 통한 알파 자로에 대한 효율적인 학습
- Dengwei Zhao, Shikui Tu, Lei Xu
- 키 :자가 놀이, 경로 일관성 (PC) 최적 성의 제한된 양
- Expenv :가, 오델로, 고모쿠
- Muzero 모델 시각화 2021
- Joery A. de Vries, Ken S. Voskuil, Thomas M. Moerland, Aske Plaat
- 키 : 값 등가 역학 모델 시각화, 액션 궤적 분산, 두 가지 정규화 기술
- Expenv : 카트 폴과 산악.
- Monte-Carlo Tree Search 2021의 볼록 정규화
- Tuan Dam, Carlo D 'Eramo, Jan Peters, Joni Pajarinen
- 키 : 엔트로피-정규화 백업 연산자, 후회 분석, tsallis etropy,
- Expenv : 합성 트리, Atari
- 정보 입자 필터 트리 : 연속 도메인에 대한 신념 기반 보상이있는 POMDP에 대한 온라인 알고리즘 2020
- 요하네스 피셔, Ömer Sahin Tas
- 키 : 연속 POMDP, 입자 필터 트리, 정보 기반 보상 형성, 정보 수집.
- Expenv : pomdps.jl 프레임 워크
- 암호
- 레트로* : 신경 안내 A* Search 2020을 통한 후퇴 계획 학습
- Binghong Chen, Chengtao Li, Hanjun Dai, Le Song
- 키 : 화학적 역동 성 계획, 신경 기반 A*-유사 알고리즘, 및 트리
- Expenv : USPTO 데이터 세트
- 암호
ICLR
- 의사 결정 시간 계획을위한 업데이트 동등성 프레임 워크 2024
- Samuel Sokota, Gabriele Farina, David J Wu, Hengyuan Hu, Kevin A. Wang, J Zico Kolter, Noam Brown
- 키 : 불완전한 정보 게임, 검색, 의사 결정 시간 계획, 업데이트 동등성
- Expenv : Hanabi, 3x3 갑작스런 Dark Hex 및 Phantom Tic-Tac-Toe
- 계획에 의한 효율적인 다중 에이전트 강화 학습 2024
- Qihan Liu, Jianing Ye, Xiaoteng MA, Jun Yang, Bin Liang, Chongjie Zhang
- 키 : 다중 에이전트 강화 학습, 계획, 다중 에이전트 MCT
- Expenv : SMAC, Lunarlander, Mujoco 및 Google Research Football
- 순수 비디오를 시청하여 제한된 데이터를 가진 능숙한 플레이어가 되십시오 2023
- Weirui Ye, Yunsheng Zhang, Pieter Abbeel, Yang Gao
- 키 : 벡터 양자화, 사전 훈련 단계, 미세 조정 단계를 기반으로 한 조상이없는 비디오, FICC (Forward Inverse Cycle 일관성) 목표.
- Expenv : Atari
- 계획 문제에 대한 정책 기반 자체 경쟁 2023
- Jonathan Pirnay, Quirin Göttl, Jakob Burger, Dominik Gerhard Grimm
- 키 : 자기 경쟁, 과거 자아의 가능한 전략에 대해 계획하여 강력한 궤적을 찾으십시오.
- Expenv : 여행 판매원 문제 및 작업 상점 일정 문제.
- Explorer-Navigator Framework 2023을 통해 시간적 그래프 모델을 설명합니다
- Wenwen Xia, Mincai Lai, Caihua Shan, Yao Zhang, Xinnan Dai, Xiang Li, Dongsheng Li
- 키 : Temporal GNN 설명자, 이벤트 간의 상관 관계를 배우고 검색 공간을 줄이는 데 도움이되는 네비게이터 인 MCTS와 이벤트 하위 집합을 찾는 탐험가입니다.
- Expenv : Wikipedia 및 Reddit, 합성 데이터 세트
- Speedyzero : 제한된 데이터와 시간이 제한된 Atari 마스터 링 2023
- Yixuan Mei, Jiaxuan Gao, Weirui Ye, Shaohuai Liu, Yang Gao, Yi Wu
- 키 : 분산 된 RL 시스템, 우선 순위 새로 고침, 클리핑 LARS
- Expenv : Atari
- 학습 된 모델 2023을 사용한 효율적인 오프라인 정책 최적화
- Zichen Liu, Siyi Li, Wee Sun Lee, Shuicheng Yan, Zhongwen Xu
- 키 : 오프라인 -RL에 대한 정규화 된 1 단계 모델 기반 알고리즘
- Expenv : Atari, Bsuite
- 암호
- 적응 형 트리 검색 2022로 임의의 번역 목표 활성화
- Wang Ling, Wojciech Stokowiec, Domenic Donato, Chris Dyer, Lei Yu, Laurent Sartran, Austin Matthews
- 키 : 적응 형 트리 검색, 번역 모델, 자동 회귀 모델,
- Expenv : WMT2020, WMT2014의 중국어 - 영어 및 파쉬토 - 영어 작업
- 조합 최적화를위한 나무 검색 2022에서 딥 러닝의 문제점
- Maximili1an Böther, Otto Kißig, Martin Taraz, Sarel Cohen, Karen Seidel, Tobias Friedrich
- 키 : 조합 최적화, NP-HARD 최대 독립 세트 문제에 대한 오픈 소스 벤치 마크 스위트, 인기있는 가이드 트리 검색 알고리즘의 심층 분석, 트리 검색 구현을 다른 솔버와 비교하십시오.
- EXPENV : NP-HARD 최대 독립 세트.
- 암호
- 언어 행동 가치 추정 2021 몬테-카를로 계획 및 학습
- Youngsoo Jang, Seokin Seo, Jongmin Lee, Kee-Eung Kim
- 키 : 언어 중심의 탐사, 국부적으로 낙관적 인 언어 가치 추정치가있는 Monte-Carlo 트리 검색.
- Expenv : 대화식 소설 (IF) 게임
- 분자 설계 2021에 적용되는 실용적인 대규모 병렬 몬테-카를로 트리 검색
- Xiufeng Yang, Tanuj KR Aasawat, Kazuki Yoshizoe
- 키 : 대규모 평행 몬테-카를로 트리 검색, 분자 설계, 해시 중심 병렬 검색,
- EXPENV : 합성 접근성 (SA) 및 대형 링 페널티 스코어에 의해 처벌 된 옥탄올-물 분할 계수 (LOGP).
- 관찰되지 않은 시청 : Monte Carlo Tree Search 2020 병렬화에 대한 간단한 접근 방식
- Anji Liu, Jianshu Chen, Mingze Yu, Yu Zhai, Xuewen Zhou, Ji Liu
- 키 : 병렬 Monte-Carlo 트리 검색, 트리를 하위 트리로 효율적으로 분할하고 각 프로세서의 관찰 비율을 비교하십시오.
- Expenv : Joy-City 게임의 속도와 성능 비교, Atari 게임의 평균 에피소드 리턴
- 암호
- 신경 탐사 탐색 나무를 통해 높은 차원의 계획 배우기 2020
- Binghong Chen, Bo Dai, Qinjie Lin, Guo Ye, Han Liu, Le Song
- 키 : 메타 경로 계획 알고리즘은 문제 구조에서 유망한 검색 방향을 배울 수있는 새로운 신경 구조를 이용합니다.
- EXPENV : 2 DOF (자유도) 포인트 로봇, 3 DOF 스틱 로봇 및 5 DOF 뱀 로봇이있는 2D 작업 공간
신경관
- Lightzero : 일반적인 순차적 결정 시나리오에서 Monte Carlo Tree 검색을위한 통합 벤치 마크 2023
- Yazhe Niu, Yuan PU, Zhenjie Yang, Xueyan Li, Tong Zhou, Jiyuan Ren, Shuai Hu, Hongsheng Li, Yu Liu
- 키 : 일반적인 순차적 의사 결정 시나리오에서 MCTS/MUZERO를 배치하기위한 최초의 통합 벤치 마크.
- Expenv : ClassicControl, Box2d, Atari, Mujoco, Gobigger, Minigrid, Tictactoe, Connectfour, Gomoku, 2048 등
- 대규모 작업 계획을위한 상식 지식으로서 대규모 언어 모델 2023
- Zirui Zhao, Wee Sun Lee, David Hsu
- 키 : World Model (LLM) 및 LLM 유발 정책을 MCTS로 결합하여 작업 계획을 확장 할 수 있습니다.
- Expenv : 곱셈, 여행 계획, 물체 재 배열
- Boltzmann Exploration 2023과 몬테 카를로 트리 검색
- Michael Painter, Mohamed Baioumy, Nick Hawes, Bruno Lacerda
- 키 : Boltzmann MCTS의 탐색, 최대 엔트로피 목표에 대한 최적의 동작이 반드시 원래 목표, 두 개의 개선 된 알고리즘에 대한 최적의 동작에 해당하는 것은 아닙니다.
- Expenv : 얼어 붙은 호수 환경, 항해 문제
- Atari Games 2023 마스터 링을위한 일반화 된 가중 경로 일관성
- Dengwei Zhao, Shikui Tu, Lei Xu
- 키 : 일반화 된 가중 경로 일관성, 가중 메커니즘.
- Expenv : Atari
- 확률 트리 상태 추상화 2023과 함께 몬테 카를로 트리 검색 가속화
- Yangqing Fu, Ming Sun, Buqing Nie, Yue Gao
- 키 : 확률 트리 상태 추상화, 전달 및 집계 오류 제한
- Expenv : Atari, Cartpole, Lunarlander, Gomoku
- 현명하게 생각하는 시간 보내기 : 가상 확장으로 MCT 가속화 2022
- Weirui Ye, Pieter Abbeel, Yang Gao
- 키 : 계산 대 성능, 가상 확장, 적응 적으로 생각하는 시간을 보내십시오.
- Expenv : Atari, 9x9 Go
- 샘플 효율적인 모방 학습 계획 2022
- Zhao-Heng Yin, Weirui Ye, Qifeng Chen, Yang Gao
- 키 : 행동 클로닝, AIL (Adversarial Imitation Learning), MCTS 기반 RL.
- Expenv : Deepmind Control Suite
- 암호
- 작업 성과를 넘어서 평가 : hex 2022의 알파 자로의 개념 분석
- Charles Lovering, Jessica Zosa Forde, George Konidaris, Ellie Pavlick, Michael L. Littman
- 키 : Alphazero의 내부 표현, 모델 조사 및 행동 테스트, 이러한 개념이 네트워크에서 캡처되는 방법.
- Expenv : 16 진
- 알파 자로와 같은 작용제는 적대적 섭동에 견고합니까? 2022
- Li-Cheng Lan, Huan Zhang, Ti-Rong Wu, Meng-Yu Tsai, I-Chen Wu, 4 Cho-Jui Hsieh
- 키 : 적대적 상태, GO AIS에 대한 최초의 적대적 공격.
- Expenv :가
- 블랙 박스 최적화를위한 몬테 카를로 트리 출신 2022
- Yaoguang Zhai, Sicun Gao
- 키 : 블랙 박스 최적화, 더 빠른 최적화를 위해 샘플 기반 하강을 추가로 통합하는 방법.
- Expenv : 비선형 최적화, Mujoco 운동 환경의 강화 학습 문제 및 신경 아키텍처 검색 (NAS)의 최적화 문제를위한 합성 기능.
- 몬테 카를로 트리 검색 기반 변수 선택 고차원 베이지안 최적화 2022
- Lei Song *, Ke Xue *, Xiaobin Huang, Chao Qian
- 키 : MCTS를 통한 저 차원 하위 공간은 베이지안 최적화 알고리즘으로 서브 스페이스에서 최적화합니다.
- Expenv : Nas-Bench 문제 및 Mujoco 운동
- 반복적으로 정제 상태 추상화와 몬테 카를로 트리 검색 2021
- Samuel Sokota, Caleb Ho, Zaheen Ahmad, J. Zico Kolter
- 키 : 확률 론적 환경, 점진적 확대, 추상화 정제
- Expenv : 블랙 잭, 함정, 5 x 5 go.
- 정찰 맹인 체스 2021의 깊은 시놉 틱 몬테 카를로 계획
- 그레고리 클라크
- 키 : 불완전한 정보, 비가 중 입자 필터가있는 신념 상태, 정보 상태의 새로운 확률 적 추상화.
- Expenv : 정찰 장님 체스
- 폴리 풋
- Weichao Mao, Kaiqing Zhang, Qiaomin Xie, Tamer Ba¸sar
- 키 : 연속 상태 액션 공간, 계층 적 낙관적 최적화.
- Expenv : 카트 폴, 역 진자, 스윙 업 및 Lunarlander.
- Monte Carlo Tree Search 2020을 사용한 블랙 박스 최적화를위한 검색 공간 파티션 학습
- Linnan Wang, Rodrigo Fonseca, Yuandong Tian
- 키 : 비선형 결정 경계 인 몇 가지 샘플을 사용하여 검색 공간의 파티션을 배우고 좋은 후보자를 선택하는 로컬 모델을 배웁니다.
- Expenv : Mujoco 운동 작업, 소규모 벤치 마크,
- 믹스 앤 매치 : 혼합 분포의 학습 모델에 대한 낙관적 인 트리 검색 접근 방식 2020
- Matthew Faw, Rajat Sen, Karthikeyan Shanmugam, Constantine Caramanis, Sanjay Shakkottai
- 키 : 공변량 시프트 문제, Mix & Match는 확률 적 구배 출신 (SGD)을 낙관적 인 트리 검색 및 모델 재사용 (다른 혼합 분포의 샘플로 부분적으로 훈련 된 모델을 발전 함)을 결합합니다.
- 암호
다른 회의 또는 저널
- 중지 학습 : 동적 시뮬레이션 Monte-Carlo Tree Search AAAI 2021.
- Monte Carlo Tree 검색 및 강화 학습 저널 오브 인공 지능 연구 저널 2017.
- Monte Carlo 트리 검색에 대한 학습 행동에 의한 샘플 효율적인 신경 아키텍처 검색 패턴 분석 및 기계 인텔리전스에 대한 IEEE 트랜잭션 2022.
피드백 및 기여
GitHub에 문제를 제기하십시오
토론 포럼에 열리거나 참여하십시오
Lightzero Discord Server에 대해 토론하십시오
이메일 ([email protected])에 문의하십시오.
알고리즘 및 시스템 설계 모두 Lightzero를 개선하기위한 모든 피드백과 기여에 감사드립니다.
? 소환
@article{niu2024lightzero,
title={LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios},
author={Niu, Yazhe and Pu, Yuan and Yang, Zhenjie and Li, Xueyan and Zhou, Tong and Ren, Jiyuan and Hu, Shuai and Li, Hongsheng and Liu, Yu},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
@article{pu2024unizero,
title={UniZero: Generalized and Efficient Planning with Scalable Latent World Models},
author={Pu, Yuan and Niu, Yazhe and Ren, Jiyuan and Yang, Zhenjie and Li, Hongsheng and Liu, Yu},
journal={arXiv preprint arXiv:2406.10667},
year={2024}
}
@article{xuan2024rezero,
title={ReZero: Boosting MCTS-based Algorithms by Backward-view and Entire-buffer Reanalyze},
author={Xuan, Chunyu and Niu, Yazhe and Pu, Yuan and Hu, Shuai and Liu, Yu and Yang, Jing},
journal={arXiv preprint arXiv:2404.16364},
year={2024}
}? 감사의 말
이 프로젝트는 GitHub 리포지토리의 다음 선구자 작품을 기반으로 부분적으로 개발되었습니다. 우리는 이러한 기초 자원에 대해 깊은 감사를 표합니다.
- https://github.com/opendilab/di-engine
- https://github.com/deepmind/mctx
- https://github.com/yewr/efficelezero
- https://github.com/werner-duvaud/muzero-general
우리는 다음 기고자 @paparazz1, @karroyan, @nighood, @jayyoung0802, @timothijoe, @tutuhuss, @harryxuanancy, @hansbug, @hansbug, @hansbug 및 @hansbug,이 알고리즘에 대한 특별한 기여를합니다.
이 프로젝트에 기여한 모든 분들께 감사드립니다.
? ️ 라이센스
이 저장소 내의 모든 코드는 Apache License 2.0에 있습니다.
(뒤로 맨 위로)



