Lightzero
Aktualisiert am 2024.12.10 Lightzero-V0.1.0
Englisch | 简体中文 (vereinfachtes Chinesisch) | Dokumentation | Lightzero -Papier | Unizero Paper | Rezer -Papier
Lightzero ist ein leichtes, effizientes und leicht verständliches Open-Source-Algorithmus-Toolkit, das die Monte-Carlo-Baumsuche (MCTs) und das Tiefenverstärkungslernen (RL) kombiniert. Bei Fragen zu Lightzero können Sie den RAG-basierten Q & A-Assistenten konsultieren: Zeropal.
? Hintergrund
Die Integration der Monte -Carlo -Baumsuche und des tiefen Verstärkungslernens, das von Alphazero und Muzero veranschaulicht wurde, hat in verschiedenen Spielen, einschließlich Go und Atari, beispiellose Leistungsstufen erreicht. Diese fortschrittliche Methodik hat auch signifikante Fortschritte in wissenschaftlichen Domänen wie die Proteinstrukturvorhersage und die Suche nach Matrixmultiplikationsalgorithmen gemacht. Das Folgende ist ein Überblick über die historische Entwicklung der Monte Carlo Tree Search Algorithmus -Serie:
Das obige Bild ist die Framework -Pipeline von Lightzero. Wir stellen kurz die drei Kernmodule unten vor:
Modell : Model wird verwendet, um die Netzwerkstruktur zu definieren, einschließlich der Funktion __init__ zur Initialisierung der Netzwerkstruktur und der forward zur Berechnung der Vorwärtsvermehrung des Netzwerks.
Richtlinie : Policy definiert die Art und Weise, wie das Netzwerk aktualisiert wird, und interagiert mit der Umgebung, einschließlich drei Prozessen: dem learning , dem collecting und dem evaluation .
MCTs : MCTS definiert die Struktur des Monte -Carlo -Suchbaums und die Art und Weise, wie er mit der Richtlinie interagiert. Die Implementierung von MCTs umfasst zwei Sprachen: Python und C ++, implementiert in ptree bzw. ctree .
Für die Dateistruktur von Lightzero finden Sie unter Lightzero_File_Structure.
? Integrierte Algorithmen
Lightzero ist eine Bibliothek mit einer Pytorch -Implementierung von MCTS -Algorithmen (manchmal in Kombination mit Cython und CPP), einschließlich:
- Alphazero
- Muzero
- Probiertes Muzero
- Stochastischer Muzero
- Effizienteszero
- Gumbel Muzero
- Rezero
- Unizero
Die derzeit von Lightzero unterstützten Umgebungen und Algorithmen sind in der folgenden Tabelle angezeigt:
| Env./algo. | Alphazero | Muzero | Probiertes Muzero | Effizienteszero | Probenahme effizientes Ozero | Gumbel Muzero | Stochastischer Muzero | Unizero | Probenahm Unizero | Rezero |
|---|
| Tictactoe | ✔ | ✔ | | | | ✔ | | ✔ | | |
| Gomoku | ✔ | ✔ | | | | ✔ | | ✔ | | ✔ |
| Connect4 | ✔ | ✔ | | | | | | ✔ | | ✔ |
| 2048 | --- | ✔ | | | | | ✔ | ✔ | | |
| Schach | | | | | | | | | | |
| Gehen | | | | | | | | | | |
| Kartpole | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| Pendel | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ | |
| Mondländer | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Bipedalwalker | --- | ✔ | ✔ | ✔ | ✔ | ✔ | | | ✔ | |
| Atari | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| DeepMind Control | --- | --- | ✔ | --- | ✔ | | | | ✔ | |
| Mujoco | --- | ✔ | | ✔ | ✔ | | | | | |
| Minigrid | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Bsuite | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Erinnerung | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Sumtothrohre (Billard) | --- | | | | ✔ | | | | | |
| Metadrive | --- | | | | ✔ | | | | | |
(1): "✔" bedeutet, dass der entsprechende Gegenstand fertig und gut getestet wird.
(2): "" bedeutet, dass sich der entsprechende Element in der Wartliste befindet (in Arbeit).
(3): "---" bedeutet, dass dieser Algorithmus diese Umgebung nicht unterstützt.
Installation
Sie können den neuesten Lightzero in der Entwicklung aus den GitHub -Quellcodes mit dem folgenden Befehl installieren:
git clone https://github.com/opendilab/LightZero.git
cd LightZero
pip3 install -e .
Bitte beachten Sie, dass Lightzero derzeit die Kompilierung nur auf Linux und macOS -Plattformen unterstützt. Wir arbeiten aktiv daran, diese Unterstützung auf die Windows -Plattform zu erweitern. Ihre Geduld während dieses Übergangs wird sehr geschätzt.
Installation mit Docker
Wir bieten auch eine Dockerfile, die eine Umgebung mit allen Abhängigkeiten einrichtet, die für die Lightzero -Bibliothek erforderlich sind. Dieses Docker -Bild basiert auf Ubuntu 20.04 und installiert Python 3.8 sowie andere erforderliche Tools und Bibliotheken. Hier erfahren Sie, wie Sie unsere Dockerfile verwenden, um ein Docker -Bild zu erstellen, einen Container aus diesem Bild auszuführen und den Lightzero -Code im Container auszuführen.
- Laden Sie die Dockerfile herunter : Die Dockerfile befindet sich im Stammverzeichnis des Lightzero -Repositorys. Laden Sie diese Datei auf Ihren lokalen Computer herunter.
- Bereiten Sie den Build -Kontext vor : Erstellen Sie ein neues leeres Verzeichnis auf Ihrer lokalen Maschine, verschieben Sie die Dockerfile in dieses Verzeichnis und navigieren Sie in dieses Verzeichnis. Dieser Schritt vermeiden Sie, unnötige Dateien während des Erstellungsprozesses an den Docker -Daemon zu senden.
mkdir lightzero-docker
mv Dockerfile lightzero-docker/
cd lightzero-docker/
- Erstellen Sie das Docker -Bild : Verwenden Sie den folgenden Befehl, um das Docker -Bild zu erstellen. Dieser Befehl sollte aus dem Verzeichnis ausgeführt werden, das die Dockerfile enthält.
docker build -t ubuntu-py38-lz:latest -f ./Dockerfile .
- Führen Sie einen Container aus dem Bild aus : Verwenden Sie den folgenden Befehl, um einen Container aus dem Bild im interaktiven Modus mit einer Bash -Shell aus zu starten.
docker run -dit --rm ubuntu-py38-lz:latest /bin/bash
- Führen Sie den Lightzero -Code im Container aus : Sobald Sie sich im Container befinden, können Sie das Beispiel Python -Skript mit dem folgenden Befehl ausführen:
python ./LightZero/zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Schneller Start
Trainieren Sie einen Muzero -Agenten, um Cartpole zu spielen:
cd LightZero
python3 -u zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Trainieren Sie einen Muzero -Agenten, um eine Pong zu spielen:
cd LightZero
python3 -u zoo/atari/config/atari_muzero_segment_config.py
Trainieren Sie einen Muzero -Agenten, um Tictactoe zu spielen:
cd LightZero
python3 -u zoo/board_games/tictactoe/config/tictactoe_muzero_bot_mode_config.py
Trainieren Sie einen Unizero -Agenten, um eine Pong zu spielen:
cd LightZero
python3 -u zoo/atari/config/atari_unizero_segment_config.py
Dokumentation
Die Lightzero -Dokumentation finden Sie hier. Es enthält Tutorials und die API -Referenz.
Für diejenigen, die sich für die Anpassung von Umgebungen und Algorithmen interessieren, bieten wir relevante Leitfäden an:
- Umgebungen anpassen
- Passen Sie Algorithmen an
- Wie setze ich Konfigurationsdateien ein?
- Protokollierungs- und Überwachungssystem
Wenn Sie Fragen haben, können Sie uns gerne zur Unterstützung kontaktieren.
Benchmark
Klicken Sie hier, um zu erweitern
- Im Folgenden finden Sie die Benchmark -Ergebnisse von Alphazero und Muzero bei drei Brettspielen: Tictactoe, Connect4, Gomoku.
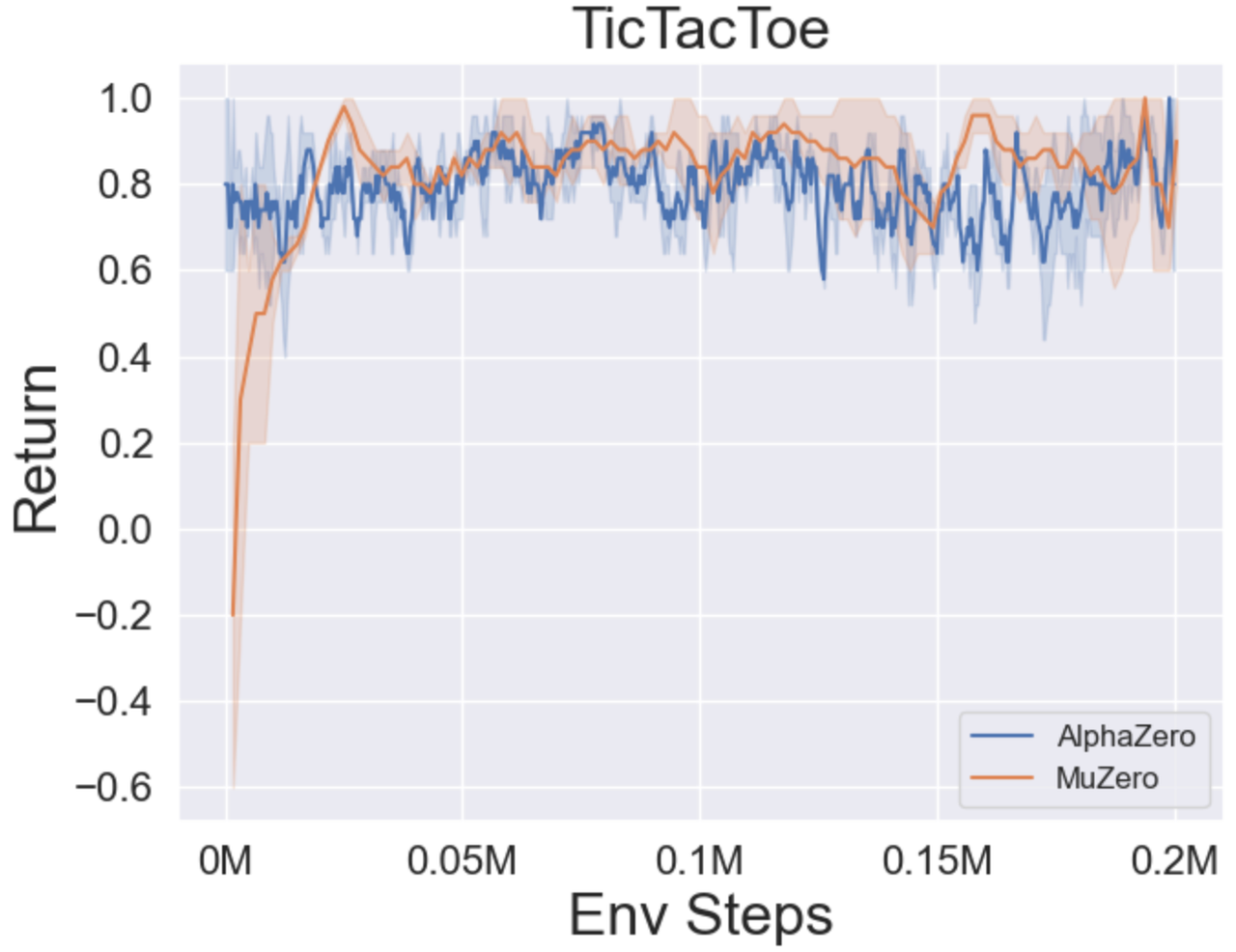
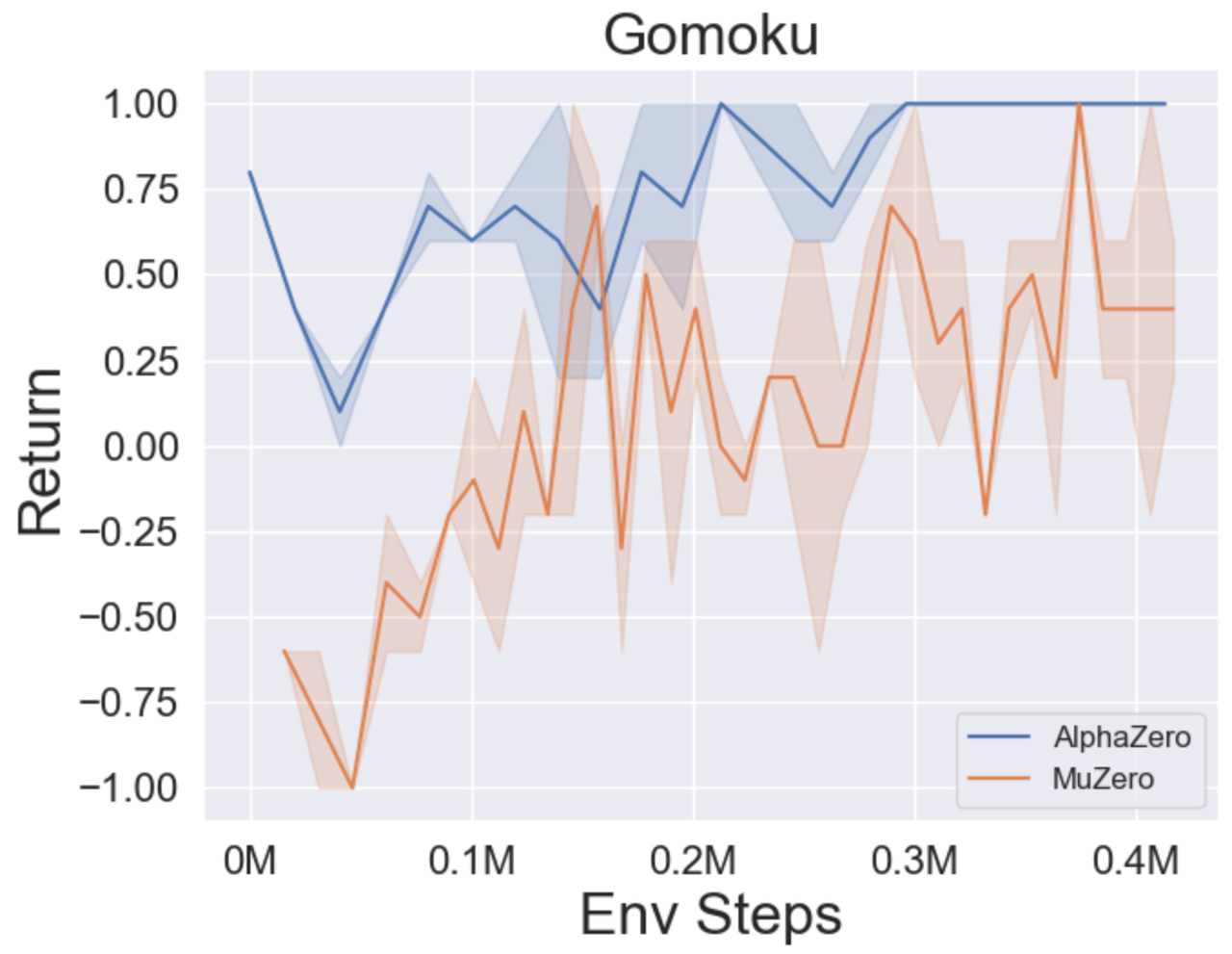
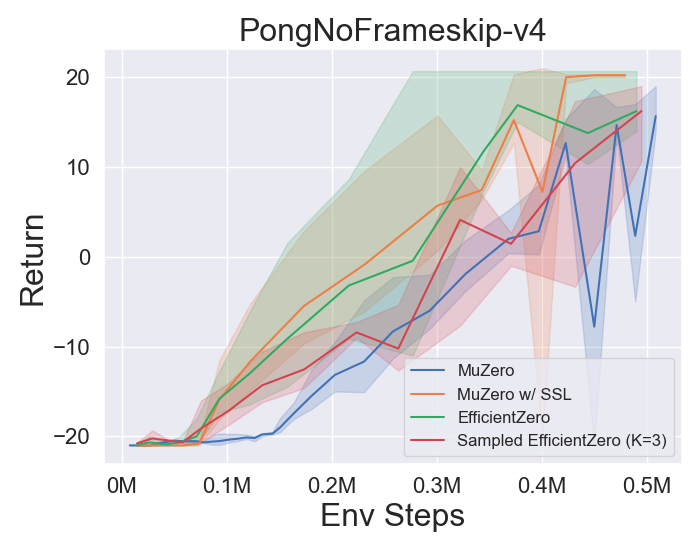
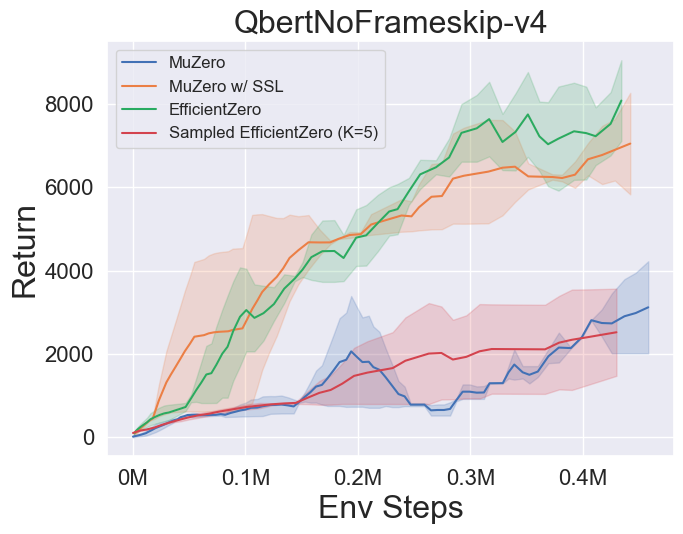
- Im Folgenden finden Sie die Benchmark -Ergebnisse von Muzero, Muzero mit SSL, Efficienzzero und EfficientZero auf drei diskreten Action Space -Spielen in Atari.
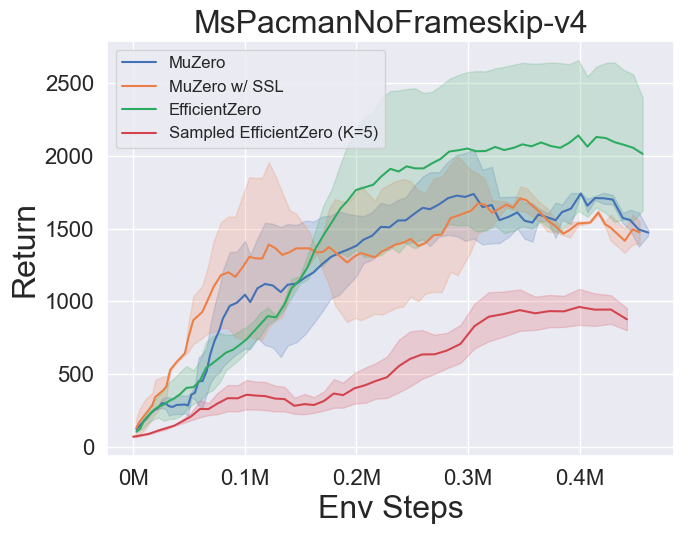
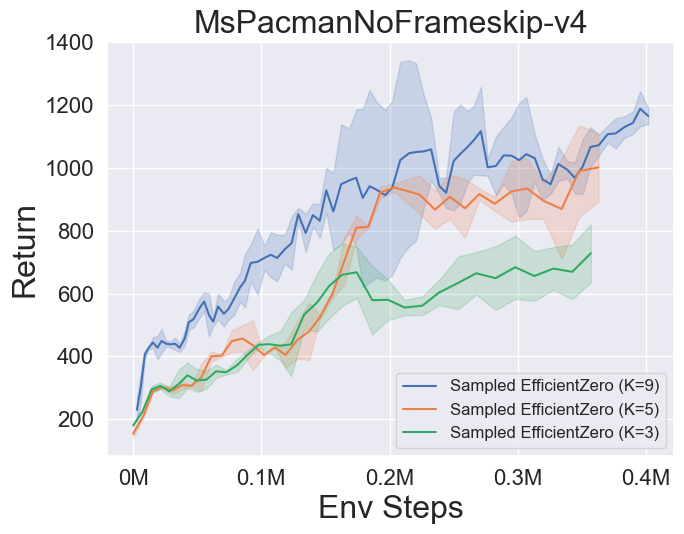
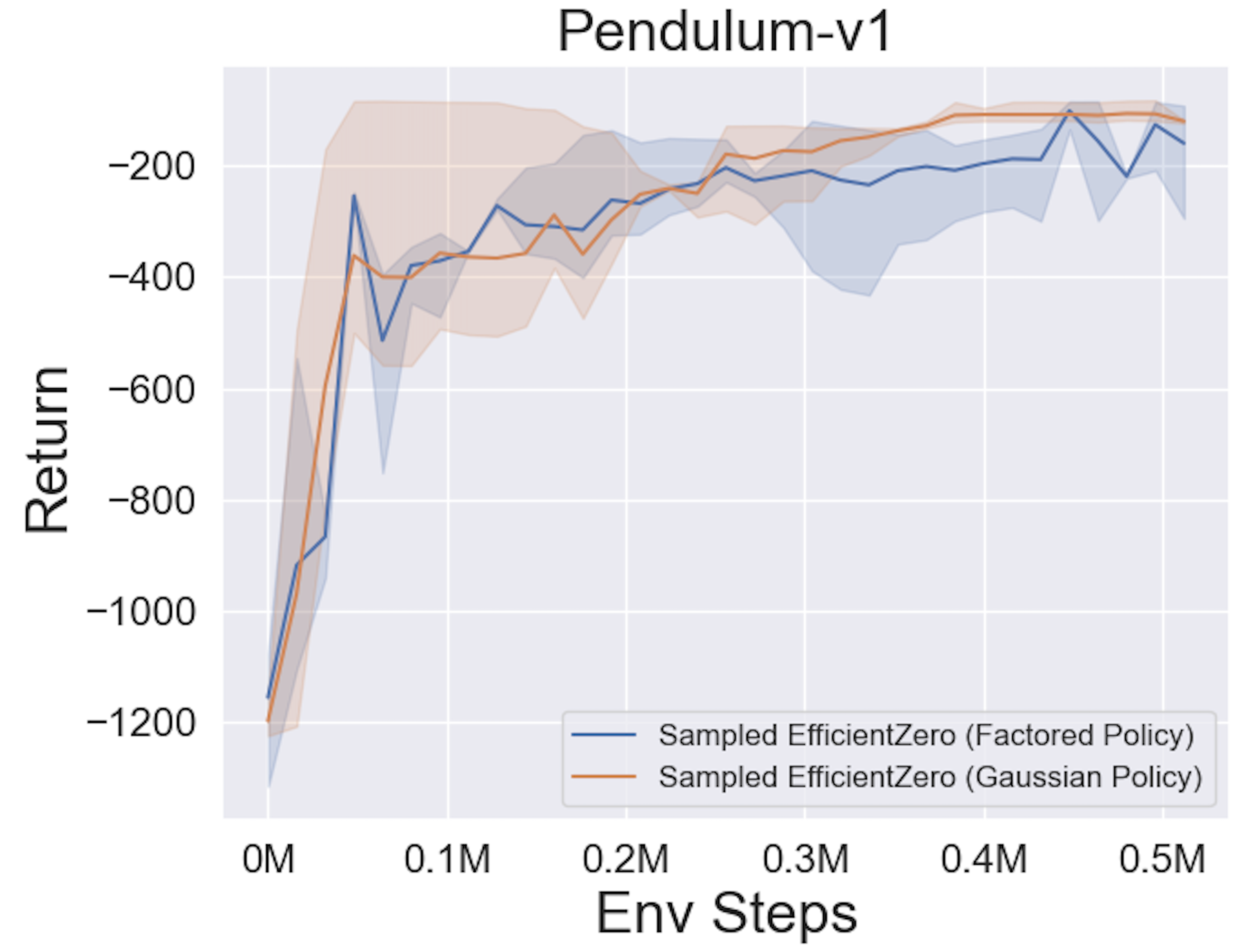
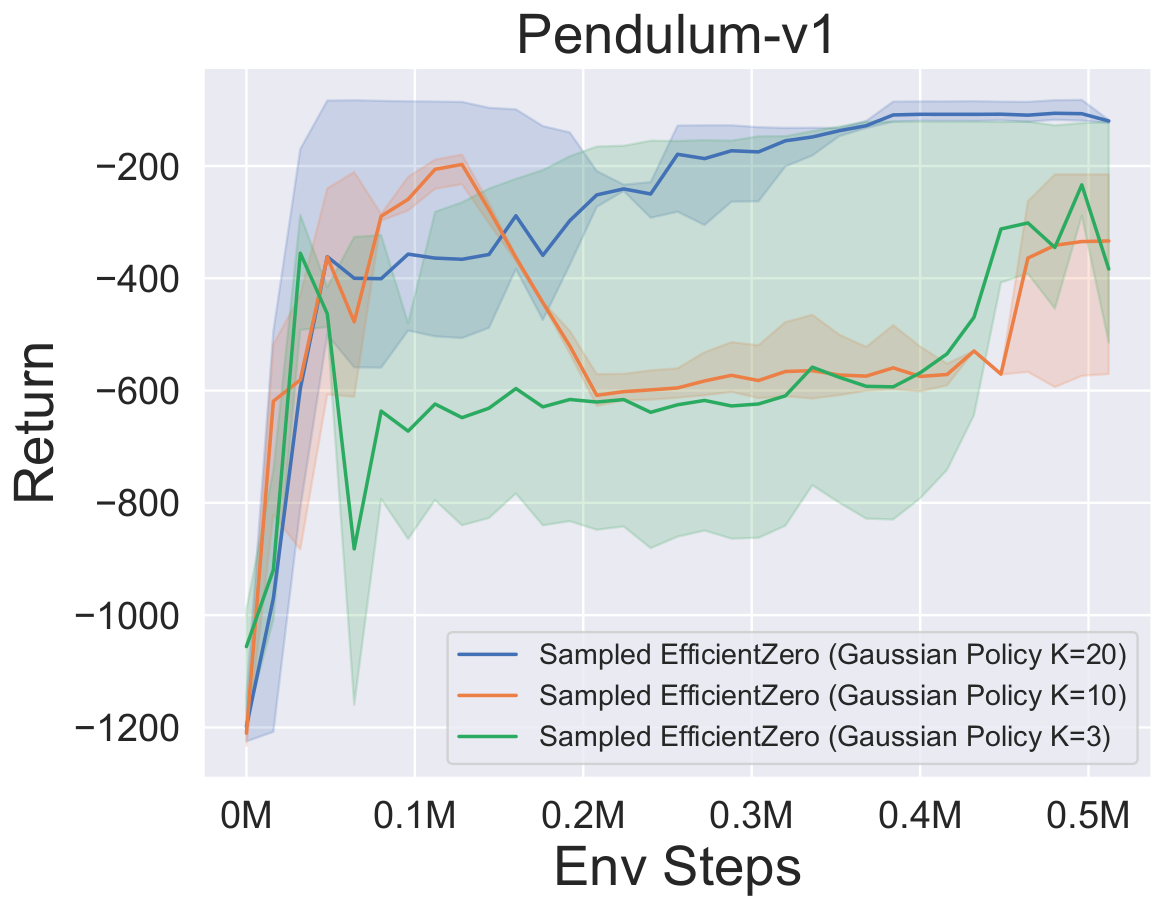
- Im Folgenden finden Sie die Benchmark-Ergebnisse von abgetastetem EfficientZero mit
Factored/Gaussian Politikvertretung bei drei klassischen kontinuierlichen Action Space-Spielen: Pendulum-V1, Lunarlandercontinous-V2, Bipedalwalker-V3 und zwei kontinuierliche Action-Raumspiele: Hopper-V3, Walker2D-V3.
"Factored Policy" gibt an, dass der Agent ein Richtliniennetzwerk lernt, das eine kategoriale Verteilung ausgibt. Nach manueller Diskretisierung betragen die Dimensionen des Aktionsraums für die fünf Umgebungen 11, 49 (7^2), 256 (4^4), 64 (4^3) bzw. 4096 (4^6). Andererseits bezieht sich "Gaußsche Richtlinie" auf das Agent, das ein Richtliniennetzwerk lernt, das Parameter (MU und Sigma) für eine Gaußsche Verteilung direkt ausgibt.
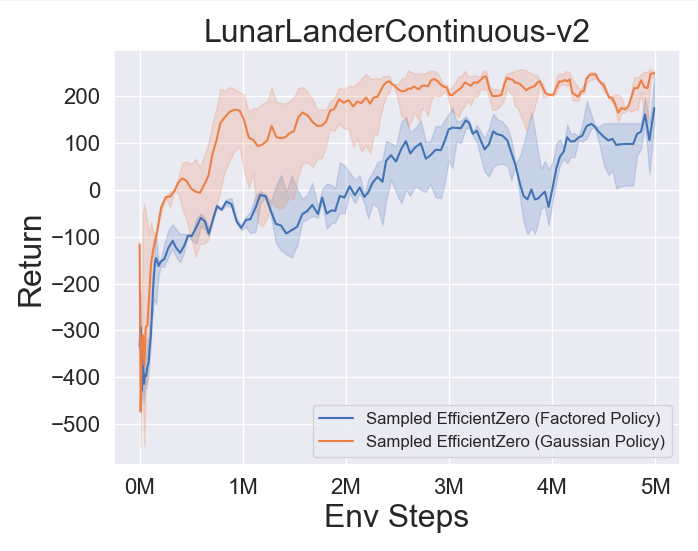
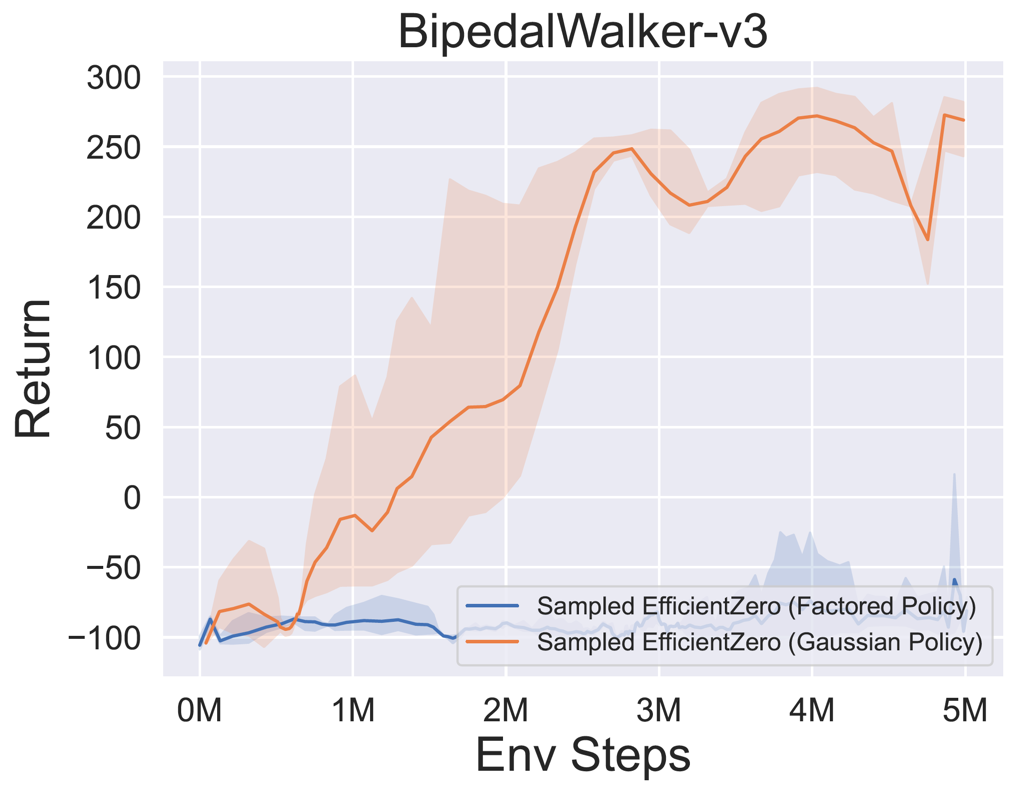
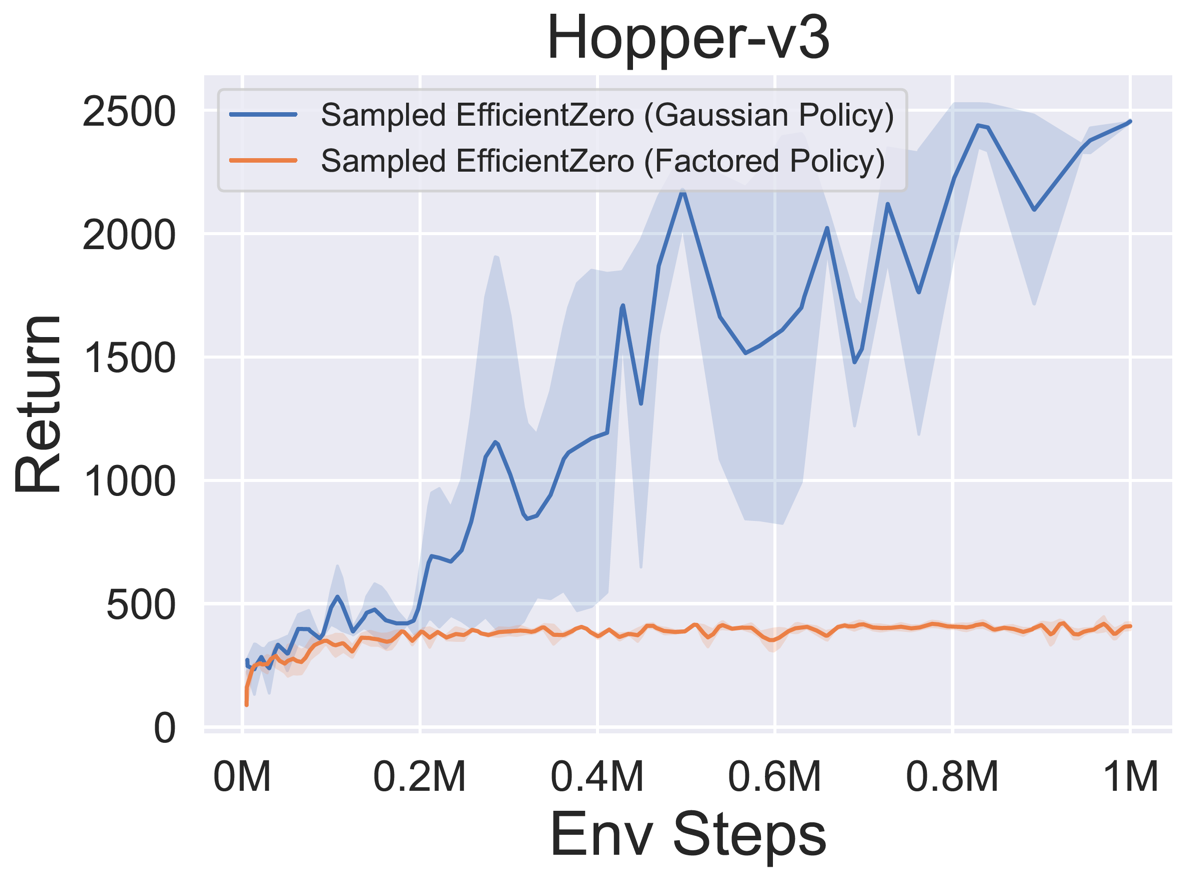
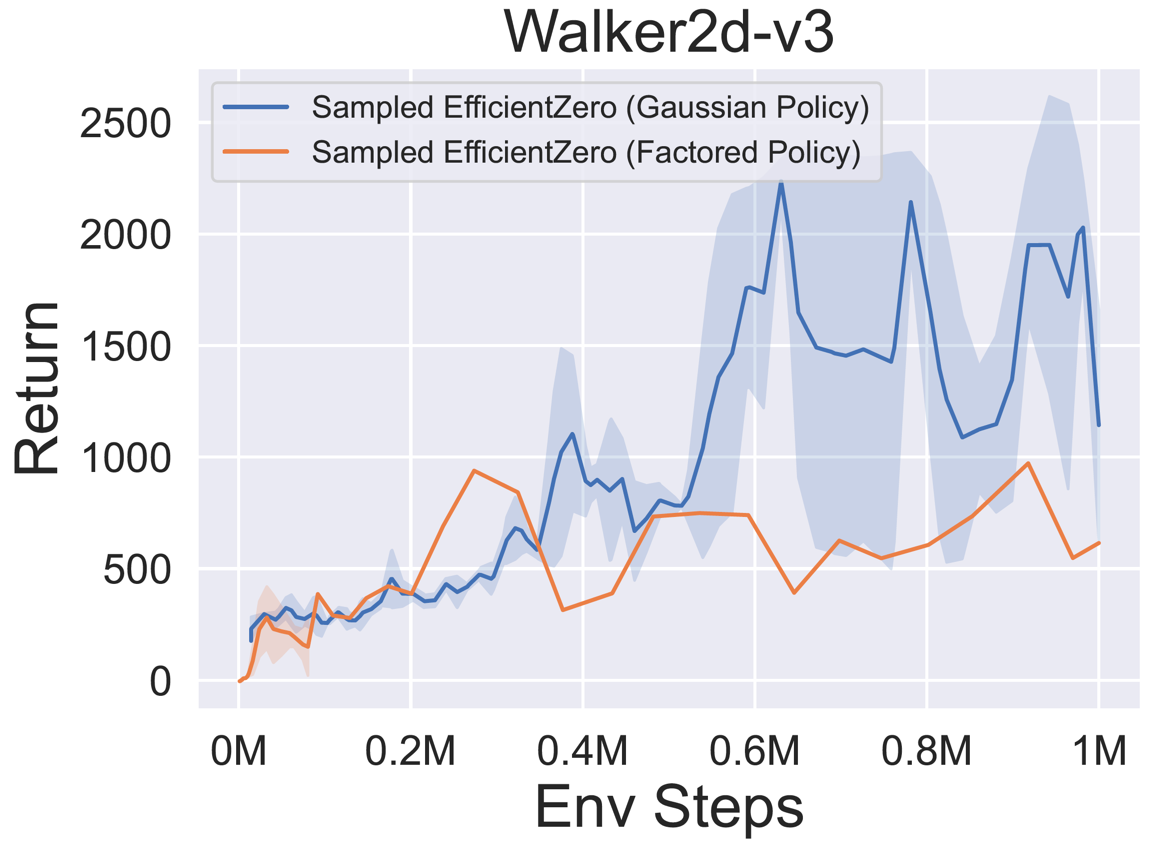
- Im Folgenden finden Sie die Benchmark-Ergebnisse von Gumbelmuzero und Muzero (unter verschiedenen Simulationskosten) in vier Umgebungen: PongnoFrameskip-V4, MspacmannoFrameskip-V4, Gomoku und Lunarlandercontinuous-V2.
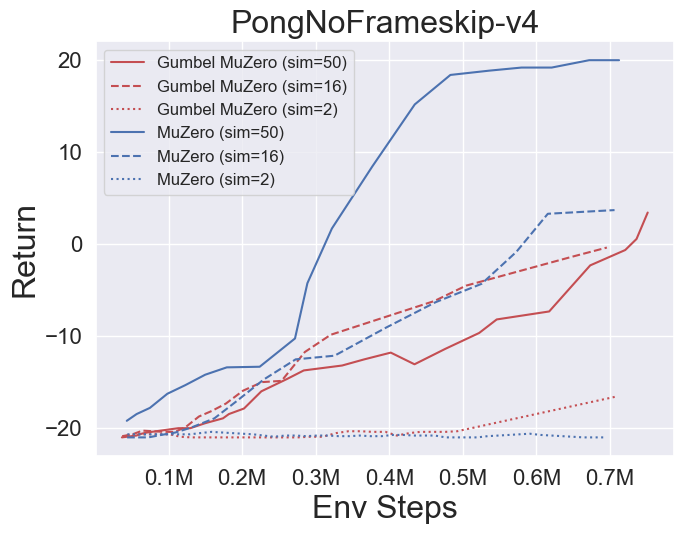
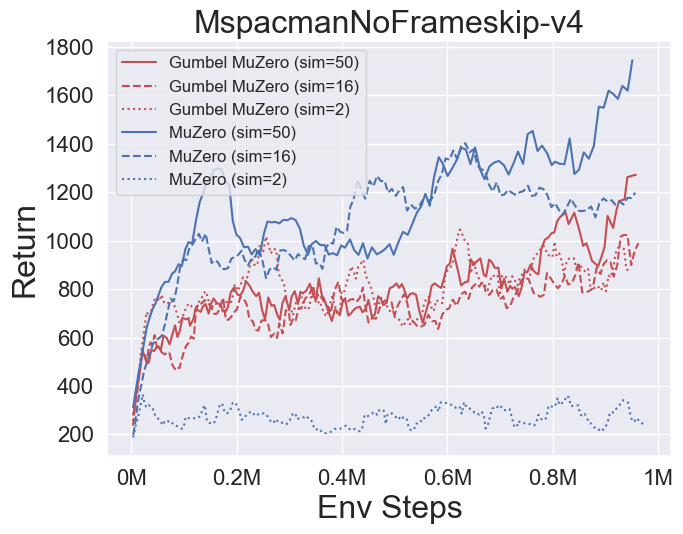
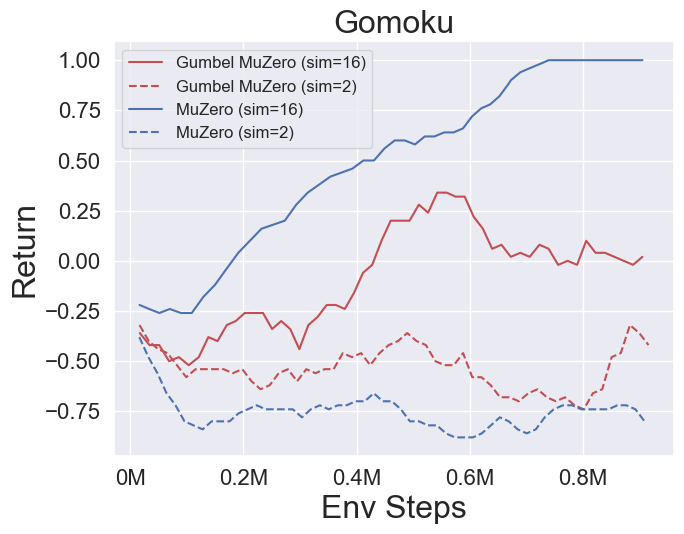
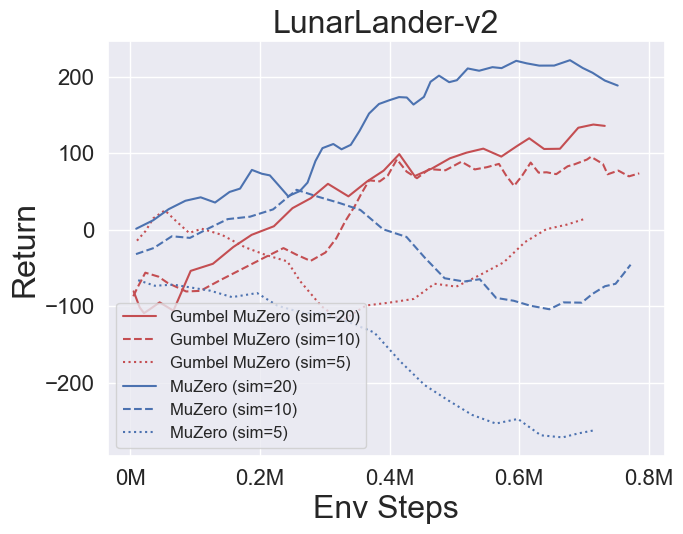
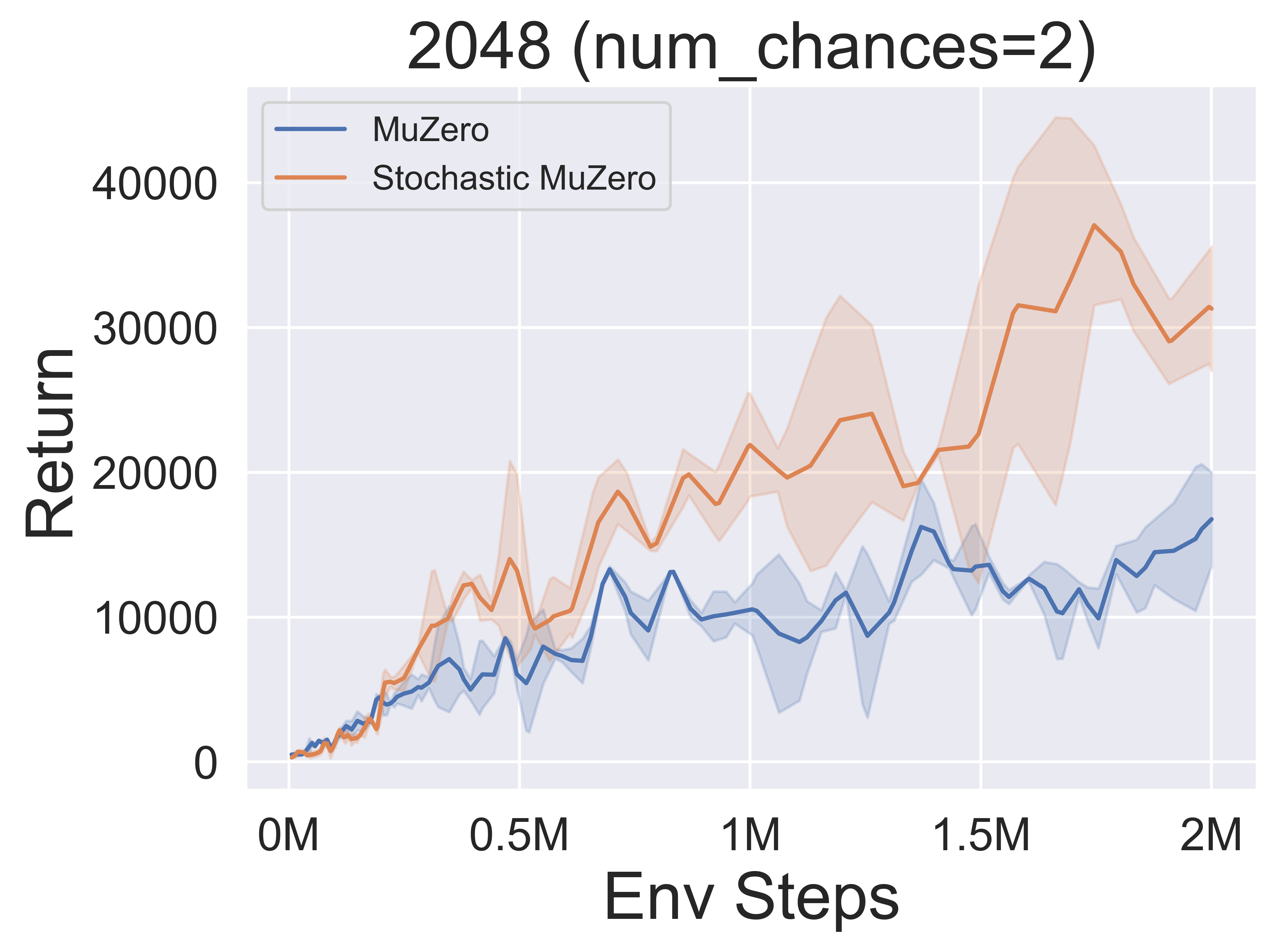
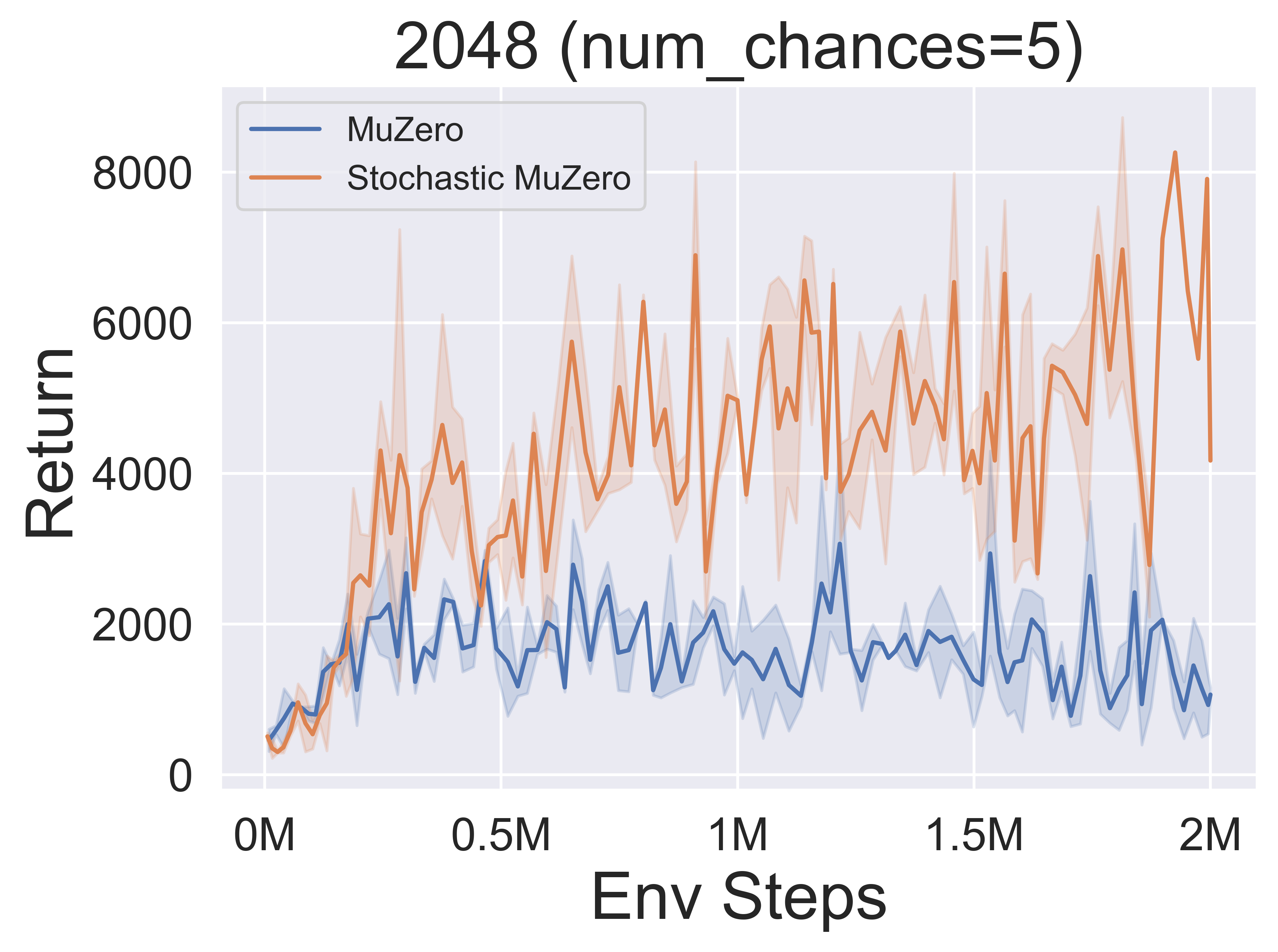
- Im Folgenden finden Sie die Benchmark -Ergebnisse von Stochasticmuzero und Muzero in der Umgebung von 2048 mit unterschiedlichem Zufall (num_chances = 2 und 5).
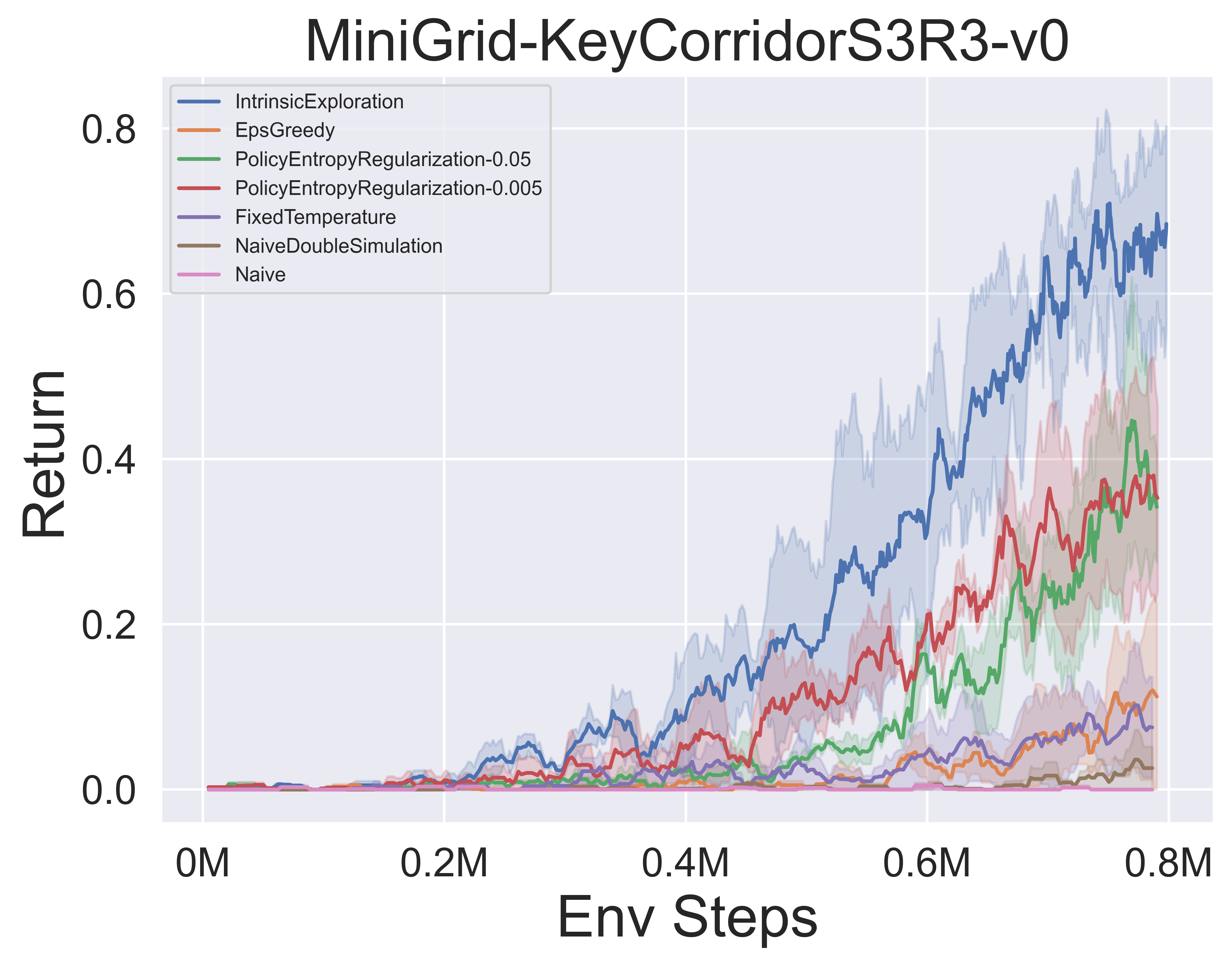
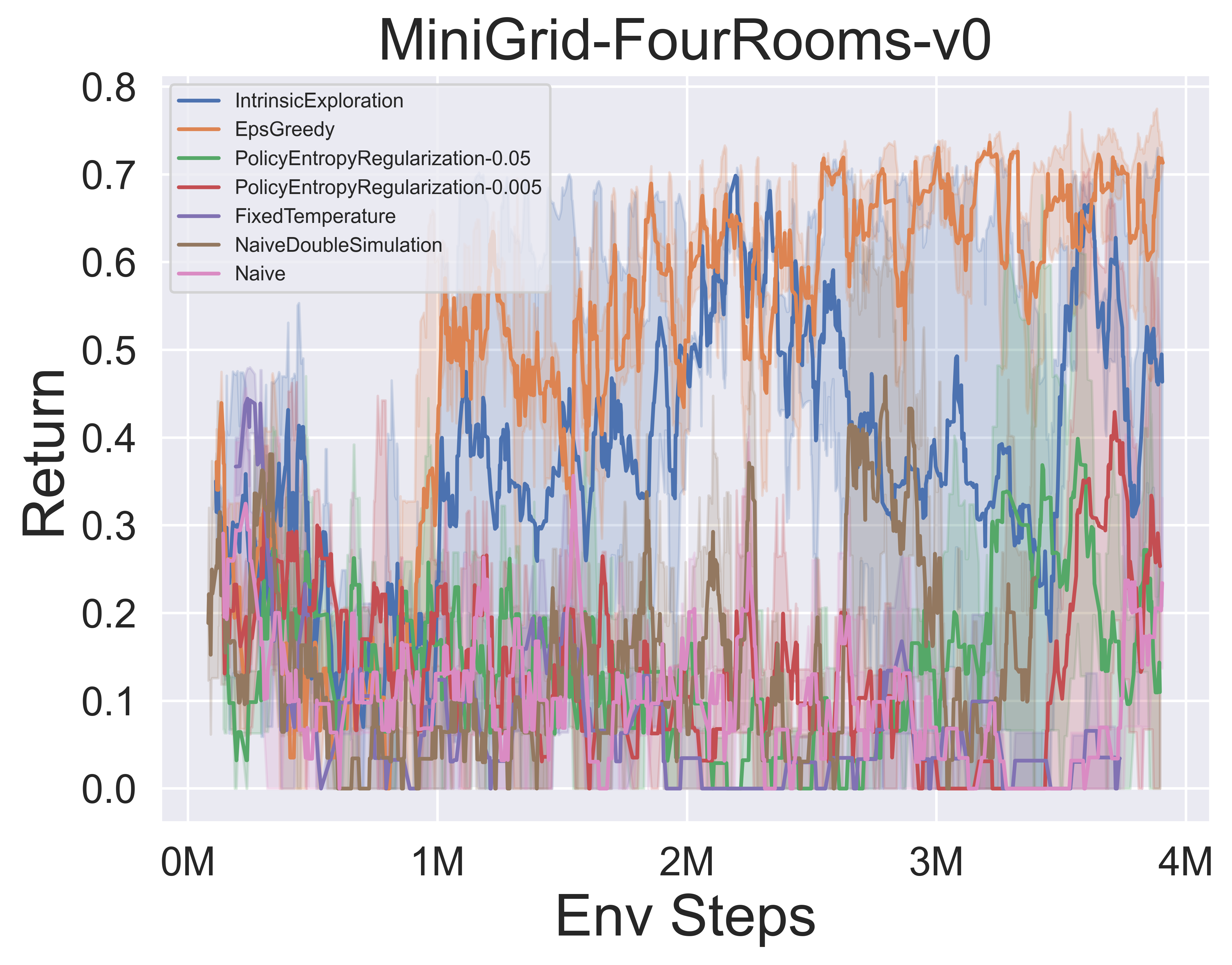
- Im Folgenden finden Sie die Benchmark -Ergebnisse verschiedener MCTS -Explorationsmechanismen von Muzero mit SSL in der minigridischen Umgebung.
Awesome-McTs Notizen
Papiernotizen
Im Folgenden finden Sie die detaillierten Papiernoten (auf Chinesisch) der obigen Algorithmen:
Klicken Sie hier, um zusammenzubrechen
- Alphazero
- Muzero
- Effizienteszero
- Probenahmemuzero
- Gumbelmuzero
- Stochasticmuzero
- NotationStable
Sie können sich auch auf die relevante Zhihu-Spalte (in Chinesisch) beziehen: eingehende Analyse von MCTS+RL-Grenztheorien und -Anwendungen.
Algo. Überblick
Im Folgenden finden Sie die Überblicke MCTS -Prinzipiagramme der obigen Algorithmen:
Klicken Sie hier, um zu erweitern
- MCTs
- Alphazero
- Muzero
- Effizienteszero
- Probenahmemuzero
- Gumbelmuzero
- Stochasticmuzero
Awesome-MCTS-Papiere
Hier finden Sie eine Sammlung von Forschungsarbeiten zur Monte -Carlo -Baumsuche . Dieser Abschnitt wird kontinuierlich aktualisiert, um die Grenze von MCTs zu verfolgen.
Schlüsselpapiere
Klicken Sie hier, um zu erweitern
Lightzero implementierte Serien
- 2018 Science Alphazero: Ein allgemeiner Algorithmus für Verstärkungslern, der Schach, Shogi und Selbstspiel durchläuft
- 2019 Muzero: Mastering Atari, Go, Schach und Shogi durch Planung mit einem erlernten Modell
- 2021 Efficienzyzero: Mastering von Atari -Spielen mit begrenzten Daten beherrschen
- 2021 Probenahme Muzero: Lernen und Planung in komplexen Aktionsräumen
- 2022 Stochastisches Muzero: Planung in stochastischen Umgebungen mit einem erlernten Modell
- 2022 Gumbel Muzero: Politikverbesserung durch Planung mit Gumbele
Alphagoer Serie
- 2015 Natural Alphago meistern das Spiel des GO mit tiefen neuronalen Netzwerken und Baumsuche
- 2017 Natural Alphago Zero, das das Spiel des GO ohne menschliches Wissen beherrscht
- 2019 ELF OpenGo: Eine Analyse und eine offene Neuauflagen von Alphazero
- 2023 Spiele der Spiele: Ein einheitlicher Lernalgorithmus für perfekte und unvollständige Informationsspiele
Muzero -Serie
- 2022 Online- und Offline -Verstärkungslernen durch Planung mit einem erlernten Modell
- 2021 Quantisierte Vektormodelle für die Planung
- 2021 MUELI: Kombination Verbesserungen der Politikoptimierung.
MCTS -Analyse
- 2020 Monte-Carlo-Baumsuche als regulierte Richtlinienoptimierung
- 2021 selbstkonsistente Modelle und Werte
- 2022 Konvers
- 2022 PNAs Erwerb von Schachkenntnissen in Alphazero.
MCTS -Anwendung
- 2023 Symbolische Physik Lernende: Entdecken Sie die Regierungsgleichungen über die Monte -Carlo -Baumsuche
- 2022 Nature entdeckt schnellere Matrix -Multiplikationsalgorithmen mit Verstärkungslernen
- 2022 Muzero mit Selbstwettbewerbsbekämpfung in der VP9-Videokomprimierung
- 2021 Douzero: Beherrschen Doudizhu mit selbst spielerem Lernen von Tiefverstärkung
- 2019 Kombination Planung und tiefes Verstärkungslernen bei taktischer Entscheidungsfindung für autonomes Fahren
Andere Papiere
Klicken Sie hier, um zu erweitern
ICML
- Skalierbare sichere Politikverbesserung über Monte Carlo Tree Search 2023
- Alberto Castellini, Federico Bianchi, Edoardo Zorzi, Thiago D. Simão, Alessandro Farinelli, Matthijs TJ Spaan
- Schlüssel: Safe Richtlinienverbesserung online mit einer MCTS -basierten Strategie, sichere Richtlinienverbesserung mit Baseline -Bootstrapping
- Expenv: Gridworld und Sysadmin
- Effizientes Lernen für Alphazero über Pfadkonsistenz 2022
- Dengwei Zhao, Shikui Tu, Lei Xu
- Schlüssel: Begrenzte Menge an Selbstspielern, Pfadkonsistenz (PC) Optimalität
- Expenv: Go, Othello, Gomoku
- Visualisierung von Muzero -Modellen 2021
- Joery A. de Vries, Ken S. Voskuil, Thomas M. Moerland, Aske Plaat
- Schlüssel: Visualisierung des value -äquivalenten Dynamikmodells, Aktionstrajektorien divergieren, zwei Regularisierungstechniken
- Expenv: Cartpole und Mountaincar.
- Konvexe Regularisierung in Monte-Carlo-Baumsuche 2021
- Tuan Dam, Carlo D'Ramo, Jan Peters, Joni Pajarinen
- Schlüssel: Backup-Operatoren der Entropie-Regularisierung, Bedauernanalyse, Tsallis etropy,
- Expenv: Synthetischer Baum, Atari
- Informationsteilchenfilterbaum: Ein Online-Algorithmus für POMDPS mit glaßenbasierten Belohnungen zu kontinuierlichen Domänen 2020
- Johannes Fischer, Ömer Sahin Tas
- Schlüssel: Kontinuierliche POMDP, Partikelfilterbaum, Informationsbasierte Belohnungsformung, Informationssammlung.
- Expenv: pomdps.jl Framework
- Code
- Retro*: Retrosynthetische Planung mit neuronaler Führung A* Search 2020
- Binghong Chen, Chengtao Li, Hanjun Dai, Le Song
- Schlüssel: Chemische retrosynthetische Planung, ein*-ähnlicher Algorithmus auf Neuralbasis, Andor Tree
- Expenv: USPTO -Datensätze
- Code
ICLR
- Der Update-Äquivalenzrahmen für die Planung der Entscheidungszeit 2024
- Samuel Sokota, Gabriele Farina, David J. Wu, Hengyuan Hu, Kevin A. Wang, J Zico Kolter, Noam Brown
- Schlüssel: Spiele imperfect-Information, Suche, Entscheidungszeitplanung, Aktualisierungsäquivalenz
- Expenv: Hanabi, 3x3 abrupte dunkle Hex und Phantom-Tic-Tac-Toe
- Effizientes Multi-Agent-Verstärkungslernen durch Planung 2024
- Qihan Liu, Jianing Ye, Xiaoteng MA, Jun Yang, bin Liang, Chongjie Zhang
- Schlüssel: Multi-Agent-Verstärkungslernen, Planung, Multi-Agent-MCTs
- Expenv: SMAC, Mondlander, Mujoco und Google Research Football
- Werden Sie ein kompetenter Spieler mit begrenzten Daten, indem Sie reine Videos 2023 ansehen
- Weirui Ye, Yunsheng Zhang, Pieter Abbeel, Yang Gao
- Schlüssel: Vorausbildung aus handlungsfreien Videos, FICC-Objektiv (Forward-Inverse Cycle Consistency) basierend auf der Quantisierung von Vektor, der Phase vor dem Training, der Feinabstimmung.
- Expenv: Atari
- Richtlinienbasierte Selbstwettkämpfe für Planungsprobleme 2023
- Jonathan Pirnay, Quirin Göttl, Jakob Burger, Dominik Gerhard Grimm
- Schlüssel: Selbstkonkurrenz, finden Sie starke Flugbahnen, indem Sie mögliche Strategien seines vergangenen Selbst planen.
- ExpenV: Problem mit dem Reisebericht und dem Problem der Job-Shop-Planung.
- Erklären Sie temporale Diagrammmodelle durch einen Explorer-Navigator-Framework 2023
- Wenwen Xia, Mincai Lai, Caihua Shan, Yao Zhang, Xinnan Dai, Xiang Li, Dongsheng Li
- Schlüssel: Temporal GNN Explorer, ein Explorer, der die Ereignis -Teilmengen mit MCTs findet, ein Navigator, der die Korrelationen zwischen Ereignissen lernt und den Suchraum reduziert.
- Expenv: Wikipedia und Reddit, synthetische Datensätze
- Speedyzero: Mastering Atari mit begrenzten Daten und Zeit 2023
- Yixuan Mei, Jiaxuan Gao, Weirui Ye, Shaohuai Liu, Yang Gao, Yi Wu
- Schlüssel: Distributed RL -System, Prioritätsauflust, abgeschnittene LARS
- Expenv: Atari
- Effiziente Offline -Richtlinienoptimierung mit einem gelernten Modell 2023
- Zichen Liu, Siyi Li, Wee Sun Lee, Shuicheng Yan, Zhongwen Xu
- Schlüssel: Regulierter einstufiger modellbasiertes Algorithmus für Offline-RL
- Expenv: Atari , Bsuite
- Code
- Aktivierung willkürlicher Übersetzungsziele mit adaptiver Baumsuche 2022
- Wang Ling, Wojciech Stokowiec, Domenic Donato, Chris Dyer, Lei Yu, Laurent Sartran, Austin Matthews
- Schlüssel: Adaptive Baumsuche, Übersetzungsmodelle, autoregressive Modelle,
- Expenv: Chinesisch -englische und paschtisch -englische Aufgaben von WMT2020, Deutsch - englisch von WMT2014
- Was ist falsch mit Deep Learning in der Baumsuche nach kombinatorischer Optimierung 2022
- Maximili1an Bötther, Otto Kißig, Martin Taraz, Sarel Cohen, Karen Seidel, Tobias Friedrich
- Schlüssel: Kombinatorische Optimierung, Open-Source-Benchmark-Suite für das maximal unabhängige Set-Problem, eine eingehende Analyse des beliebten geführten Baumsuchalgorithmus, vergleichen
- ExpENV: NP-harte Maximum unabhängige Set.
- Code
- Monte-Carlo Planung und Lernen mit den Schätzungen des Sprachaktionswertes 2021 2021
- Youngsoo Jang, Seokin Seo, Jongmin Lee, Kee-Eung Kim
- Schlüssel: Monte-Carlo-Baumsuche mit sprachgetriebener Erkundung, lokal optimistische Sprachwertschätzungen.
- Expenv: Interaktive Fiktion (IF) Spiele
- Praktische massiv parallele Monte-Carlo-Baumsuche auf molekulares Design 2021
- Xiufeng Yang, Tanuj Kr Aasawat, Kazuki Yoshizoe
- Schlüssel: Massiv parallele Monte-Carlo-Baumsuche, molekulares Design, Hash-gesteuerte parallele Suche,
- ExpENV: Octanol-Wasser-Partitionskoeffizient (LOW), bestraft durch die synthetische Zugänglichkeit (SA) und große Ringstrafe.
- Beobachten Sie die Unbeobachteten: Ein einfacher Ansatz zur Parallelisierung von Monte Carlo Tree Search 2020
- Anji Liu, Jianshu Chen, Mingze Yu, Yu Zhai, Xuewen Zhou, Ji Liu
- Schlüssel: Parallele Monte-Carlo-Baumsuche, Partition des Baumes effizient in Unterbäume und vergleichen Sie das Beobachtungsverhältnis jedes Prozessors.
- Expenv: Geschwindigkeits- und Leistungsvergleich beim Joy-City-Spiel, durchschnittliche Episodenrendite im Atari-Spiel
- Code
- Erlernen des Planens in hohen Dimensionen über neuronale Explorationsbäume 2020
- Binghong Chen, Bo Dai, Qinjie Lin, Guo Ye, Han Liu, Le Song
- Schlüssel: Meta -Pfadplanungsalgorithmus, nutzt eine neue neuronale Architektur, die vielversprechende Suchanweisungen aus Problemstrukturen lernen kann.
- Expenv: Ein 2D -Arbeitsbereich mit einem 2 DOF (Freiheitsgrade) Punktroboter, einem 3 Dof -Stick -Roboter und einem 5 Dof -Schlangenroboter
Neurips
- Lightzero: Ein einheitlicher Benchmark für die Monte -Carlo -Baumsuche in allgemeinen sequentiellen Entscheidungsszenarien 2023
- Yazhe Niu, Yuan Pu, Zhenjie Yang, Xueyan Li, Tong Zhou, Jiyuan Ren, Shuai Hu, Hongsheng Li, Yu Liu
- Schlüssel: Der erste einheitliche Benchmark für die Bereitstellung von MCTs/Muzero in allgemeinen sequentiellen Entscheidungsszenarien.
- Expenv: ClassicControl, Box2d, Atari, Mujoco, Gobigger, Minigrid, Tictactoe, Connectfour, Gomoku, 2048 usw.
- Großsprachenmodelle als gewundenter Kenntnis der groß angelegten Aufgabenplanung 2023
- Zirui Zhao, Wee Sun Lee, David Hsu
- Schlüssel: World Model (LLM) und die LLM-induzierte Richtlinie können in MCTs kombiniert werden, um die Aufgabenplanung zu skalieren.
- ExpenV: Multiplikation, Reiseplanung, Objektummeldung
- Monte Carlo Tree -Suche mit Boltzmann Exploration 2023
- Michael Maler, Mohamed Baiumy, Nick Hawes, Bruno Lacerda
- Schlüssel: Boltzmann Exploration mit MCTs, optimale Aktionen für das maximale Entropieziel entsprechen nicht unbedingt optimalen Aktionen für das ursprüngliche Ziel, zwei verbesserte Algorithmen.
- Expenv: Die gefrorene Seeumgebung, das Segelproblem, Go
- Verallgemeinerte gewichtete Pfadkonsistenz für die Beherrschung von Atari -Spielen 2023
- Dengwei Zhao, Shikui Tu, Lei Xu
- Schlüssel: Verallgemeinerte gewichtete Pfadkonsistenz, ein Gewichtungsmechanismus.
- Expenv: Atari
- Beschleunigung der Monte -Carlo -Baumsuche mit Wahrscheinlichkeit Baumzustand Abstraktion 2023
- Yangqing Fu, Ming Sun, Buqing Nie, Yue Gao
- Schlüssel: Wahrscheinlichkeit Baumzustand Abstraktion, Transitivität und Aggregationsfehler gebunden
- Expenv: Atari, Cartpole, Mondlander, Gomoku
- Denkzeit mit Bedacht ausgeben: Beschleunigen von MCTs mit virtuellen Erweiterungen 2022
- Weirui ye, Pieter Abbeel, Yang Gao
- Schlüssel: Berechnung im Vergleich zu Performancem, virtuelle Erweiterungen, Denkzeit adaptiv verbringen.
- Expenv: Atari, 9x9 Go
- Planung für ein effizientes Nachahmungslernen 2022
- Zhao-Heng Yin, Weirui Ye, Qifeng Chen, Yang Gao
- Schlüssel: Verhaltensklonen , Konverselles Nachahmungslernen (AIL) , MCTS-basiert RL.
- Expenv: DeepMind Control Suite
- Code
- Bewertung jenseits der Aufgabenleistung: Analyse von Konzepten in Alphazero in Hex 2022
- Charles Lovering, Jessica Zosa Foren, George Konidaris, Ellie Pavlick, Michael L. Littman
- Schlüssel: Alphazeros interne Darstellungen, Modelluntersuchungs- und Verhaltenstests, wie diese Konzepte im Netzwerk erfasst werden.
- Expenv: Hex
- Sind Alphazero-ähnliche Agenten robust gegenüber kontroversen Störungen? 2022
- Li-Cheng Lan, Huan Zhang, Ti-Rong Wu, Meng-Yu Tsai, I-Chen Wu, 4 Cho-Jui Hsieh
- Schlüssel: Gegentliche Zustände, erster kontroverser Angriff auf Go AIS.
- Expenv: Geh
- Monte Carlo Tree-Abstieg für die Schwarzbox-Optimierung 2022
- Yaoguang Zhai, Sicun Gao
- Schlüssel: Black-Box-Optimierung, wie man mit dem Stichprobenabfall weiter integrieren, um eine schnellere Optimierung zu erzielen.
- ExpENV: Synthetische Funktionen für nichtlineare Optimierung, Probleme der Verstärkung von Lernproblemen in Mujoco -Fortbewegungsumgebungen und Optimierungsprobleme bei der Suche nach neuronalen Architektur (NAS).
- Monte Carlo Tree Search -basierte variable Auswahl für hochdimensionale Bayes'sche Optimierung 2022
- Lei Song ∗, Ke Xue ∗, Xiaobin Huang, Chao Qian
- Schlüssel: Ein niedrigdimensionaler Unterraum über MCTs optimiert im Unterraum mit jedem Bayesian-Optimierungsalgorithmus.
- Expenv: NAS-Bench-Probleme und Mujoco-Fortbewegung
- Monte Carlo Tree -Suche mit iterativ verfeinerten Zustandsabstraktionen 2021
- Samuel Sokota, Caleb Ho, Zaheen Ahmad, J. Zico Kolter
- Schlüssel: Stochastische Umgebungen, fortschreitende Erweiterung, Abstraktionsraffinierung
- Expenv: Blackjack, Trap, fünf bis fünf GO.
- Deep Synoptic Monte Carlo Planung in Aufklärungsschach 2021 2021
- Gregory Clark
- Schlüssel: Unvollkommene Informationen, Glaubenszustand mit einem ungewichteten Partikelfilter, einer neuartigen stochastischen Abstraktion von Informationszuständen.
- Expenv: Aufklärungsschach auf Erkenntnis
- Poly-Hoot: Monte-Carlo-Planung in kontinuierlichen Raum-MDPs mit nicht-asymptotischer Analyse 2020
- Weichao Mao, Kaiqing Zhang, Qiaomin Xie, Tamer Ba¸sar
- Schlüssel: Kontinuierliche Zustandsbereiche, hierarchische optimistische Optimierung.
- Expenv: Cartpole, umgekehrtes Pendel, Swing-up und Mondlander.
- Lern-
- Linnan Wang, Rodrigo Fonseca, Yuandong Tian
- Schlüssel: Lernt die Partition des Suchraums mit einigen Stichproben, einer nichtlinearen Entscheidungsgrenze und lernt ein lokales Modell, um gute Kandidaten auszuwählen.
- Expenv: Mujoco-Fortbewegungsaufgaben, kleine Benchmarks,
- Mix and Match: Ein optimistischer Baumsuchansatz für Lernmodelle aus Mischungsverteilungen 2020
- Matthew Faw, Rajat Sen, Karthikeyan Shanmugam, Konstantine Caramanis, Sanjay Shakkottai
- Schlüssel: Kovariate Verschiebungsproblem, Mix & Match kombiniert stochastische Gradientenabfälle (SGD) mit optimistischer Baumsuche und Modellwiederverwendung (sich teilweise geschulte Modelle mit Proben aus verschiedenen Mischungsverteilungen entwickeln)
- Code
Andere Konferenz oder Journal
- Lernen zu stoppen: Dynamische Simulation Monte-Carlo-Baumsuche AAAI 2021.
- Auf Monte Carlo Tree Search and verstärkten Lernjournal für künstliche Intelligenzforschung 2017.
- Beispieleffizientes neuronaler Architektur-Suche nach Lernmaßnahmen für Monte Carlo Tree Search IEEE-Transaktionen zur Musteranalyse und Maschinenintelligenz 2022.
Feedback und Beitrag
Dateien Sie ein Problem auf GitHub
Öffnen oder an unserem Diskussionsforum teilnehmen
Diskutieren Sie auf Lightzero Discord Server
Wenden Sie sich an unsere E -Mail ([email protected])
Wir schätzen alle Feedback und Beiträge zur Verbesserung von Lightzero, sowohl Algorithmen als auch Systemdesigns.
? Zitat
@article{niu2024lightzero,
title={LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios},
author={Niu, Yazhe and Pu, Yuan and Yang, Zhenjie and Li, Xueyan and Zhou, Tong and Ren, Jiyuan and Hu, Shuai and Li, Hongsheng and Liu, Yu},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
@article{pu2024unizero,
title={UniZero: Generalized and Efficient Planning with Scalable Latent World Models},
author={Pu, Yuan and Niu, Yazhe and Ren, Jiyuan and Yang, Zhenjie and Li, Hongsheng and Liu, Yu},
journal={arXiv preprint arXiv:2406.10667},
year={2024}
}
@article{xuan2024rezero,
title={ReZero: Boosting MCTS-based Algorithms by Backward-view and Entire-buffer Reanalyze},
author={Xuan, Chunyu and Niu, Yazhe and Pu, Yuan and Hu, Shuai and Liu, Yu and Yang, Jing},
journal={arXiv preprint arXiv:2404.16364},
year={2024}
}? Anerkennung
Dieses Projekt wurde teilweise auf den folgenden Pionierarbeiten zu Github -Repositorys entwickelt. Wir bedanken uns für diese grundlegenden Ressourcen:
- https://github.com/opendilab/di-engine
- https://github.com/deepmind/mctx
- https://github.com/yewr/efficienzzero
- https://github.com/werker-duvaud/muzero-general
Wir möchten uns bei den folgenden Mitwirkenden @Paparazz1, @karroyan, @nighood, @jayyoung0802, @timothijoe, @tutuhuss, @harryxuancy, @puyuan1996, @hansbug für ihre wertvollen Beiträge und die Unterstützung dieser Algorithm Library.
Vielen Dank an alle, die zu diesem Projekt beigetragen haben:
- Lizenz
Der gesamte Code in diesem Repository befindet sich unter Apache -Lizenz 2.0.
(Zurück nach oben)



