Léger
Mis à jour le 2024.12.10 Lightzero-V0.1.0
Anglais | 简体中文 (chinois simplifié) | Documentation | Papier Lightzero | Papier Unizero | Papier de rezo
Lightzero est une boîte à outils d'algorithme d'algorithme open-source légère, efficace et facile à comprendre qui combine la recherche de monte carlo (MCTS) et l'apprentissage en renforcement profond (RL). Pour toute question sur Lightzero, vous pouvez consulter l'assistant de questions et réponses basé sur le chiffon: Zeropal.
? Arrière-plan
L'intégration de la recherche de Monte Carlo Tree et de l'apprentissage en renforcement profond, illustrée par Alphazero et Muzero, a atteint des niveaux de performance sans précédent dans divers jeux, notamment Go et Atari. Cette méthodologie avancée a également fait des progrès significatifs dans des domaines scientifiques comme la prédiction de la structure des protéines et la recherche d'algorithmes de multiplication matricielle. Ce qui suit est un aperçu de l'évolution historique de la série d'algorithmes de recherche de Monte Carlo Tree:
L'image ci-dessus est le pipeline de framework de LightZero. Nous introduisons brièvement les trois modules de base ci-dessous:
Modèle : Model est utilisé pour définir la structure du réseau, y compris la fonction __init__ pour initialiser la structure du réseau et la fonction forward pour calculer la propagation avant du réseau.
Politique : Policy définit la façon dont le réseau est mis à jour et interagit avec l'environnement, y compris trois processus: le processus learning , le processus collecting et le processus evaluation .
MCTS : MCTS définit la structure de l'arbre de recherche de Monte Carlo et la façon dont il interagit avec la politique. L'implémentation de MCTS comprend deux langues: Python et C ++, implémentées dans ptree et ctree , respectivement.
Pour la structure de fichiers de LightZero, veuillez vous référer à LightZero_File_structure.
? Algorithmes intégrés
LightZero est une bibliothèque avec une implémentation pytorch des algorithmes MCTS (parfois combinée avec Cython et CPP), y compris:
- Alphazer
- Muzero
- Muzero échantillonné
- Muzero stochastique
- Efficientzero
- Gumbel Muzero
- Rezo
- Unizero
Les environnements et les algorithmes actuellement pris en charge par LightZero sont indiqués dans le tableau ci-dessous:
| Env./algo. | Alphazer | Muzero | Muzero échantillonné | Efficientzero | Échantillonné efficace | Gumbel Muzero | Muzero stochastique | Unizero | Unizero échantillonné | Rezo |
|---|
| Tictactoe | ✔ | ✔ | | | | ✔ | | ✔ | | |
| Gomoku | ✔ | ✔ | | | | ✔ | | ✔ | | ✔ |
| Connect4 | ✔ | ✔ | | | | | | ✔ | | ✔ |
| 2048 | --- | ✔ | | | | | ✔ | ✔ | | |
| Échecs | | | | | | | | | | |
| Aller | | | | | | | | | | |
| Cartpole | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| Pendule | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ | |
| Lunarlander | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Bipède | --- | ✔ | ✔ | ✔ | ✔ | ✔ | | | ✔ | |
| Atari | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| Contrôle DeepMind | --- | --- | ✔ | --- | ✔ | | | | ✔ | |
| Mujoco | --- | ✔ | | ✔ | ✔ | | | | | |
| Minigride | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Bsuite | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Mémoire | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Sumtothree (billard) | --- | | | | ✔ | | | | | |
| Métadrive | --- | | | | ✔ | | | | | |
(1): "✔ ✔" signifie que l'élément correspondant est terminé et bien testé.
(2): "" signifie que l'élément correspondant est dans la liste d'attente (travail en cours).
(3): "---" signifie que cet algorithme ne prend pas en charge cet environnement.
Installation
Vous pouvez installer le dernier LightZero en développement à partir des codes source GitHub avec la commande suivante:
git clone https://github.com/opendilab/LightZero.git
cd LightZero
pip3 install -e .
Veuillez noter que LightZero prend actuellement en charge la compilation uniquement sur les plates-formes Linux et macOS . Nous travaillons activement à étendre ce support à la plate-forme Windows . Votre patience pendant cette transition est grandement appréciée.
Installation avec Docker
Nous fournissons également un dockerfile qui met en place un environnement avec toutes les dépendances nécessaires pour exécuter la bibliothèque Lightzero. Cette image Docker est basée sur Ubuntu 20.04 et installe Python 3.8, ainsi que d'autres outils et bibliothèques nécessaires. Voici comment utiliser notre dockerfile pour créer une image Docker, exécuter un conteneur à partir de cette image et exécuter du code LightZero à l'intérieur du conteneur.
- Téléchargez le dockerfile : le dockerfile est situé dans le répertoire racine du référentiel Lightzero. Téléchargez ce fichier sur votre machine locale.
- Préparez le contexte de construction : créez un nouveau répertoire vide sur votre machine locale, déplacez le Dockerfile dans ce répertoire et naviguez dans ce répertoire. Cette étape aide à éviter d'envoyer des fichiers inutiles au démon docker pendant le processus de construction.
mkdir lightzero-docker
mv Dockerfile lightzero-docker/
cd lightzero-docker/
- Créez l'image Docker : utilisez la commande suivante pour créer l'image Docker. Cette commande doit être exécutée à l'intérieur du répertoire qui contient le dockerfile.
docker build -t ubuntu-py38-lz:latest -f ./Dockerfile .
- Exécutez un conteneur à partir de l'image : utilisez la commande suivante pour démarrer un conteneur à partir de l'image en mode interactif avec un shell bash.
docker run -dit --rm ubuntu-py38-lz:latest /bin/bash
- Exécuter le code LightZero à l'intérieur du conteneur : une fois que vous êtes dans le conteneur, vous pouvez exécuter l'exemple de script Python avec la commande suivante:
python ./LightZero/zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Démarrage rapide
Former un agent Muzero pour jouer à Cartpole:
cd LightZero
python3 -u zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Entraînez un agent Muzero pour jouer à Pong:
cd LightZero
python3 -u zoo/atari/config/atari_muzero_segment_config.py
Formez un agent Muzero pour jouer à Tictactoe:
cd LightZero
python3 -u zoo/board_games/tictactoe/config/tictactoe_muzero_bot_mode_config.py
Formez un agent Unizero pour jouer à Pong:
cd LightZero
python3 -u zoo/atari/config/atari_unizero_segment_config.py
Documentation
La documentation Lightzero peut être trouvée ici. Il contient des tutoriels et la référence de l'API.
Pour ceux qui souhaitent personnaliser des environnements et des algorithmes, nous fournissons des guides pertinents:
- Personnaliser les environnements
- Personnaliser les algorithmes
- Comment définir des fichiers de configuration?
- Système de journalisation et de surveillance
Si vous avez des questions, n'hésitez pas à nous contacter pour un soutien.
Référence
Cliquez pour agrandir
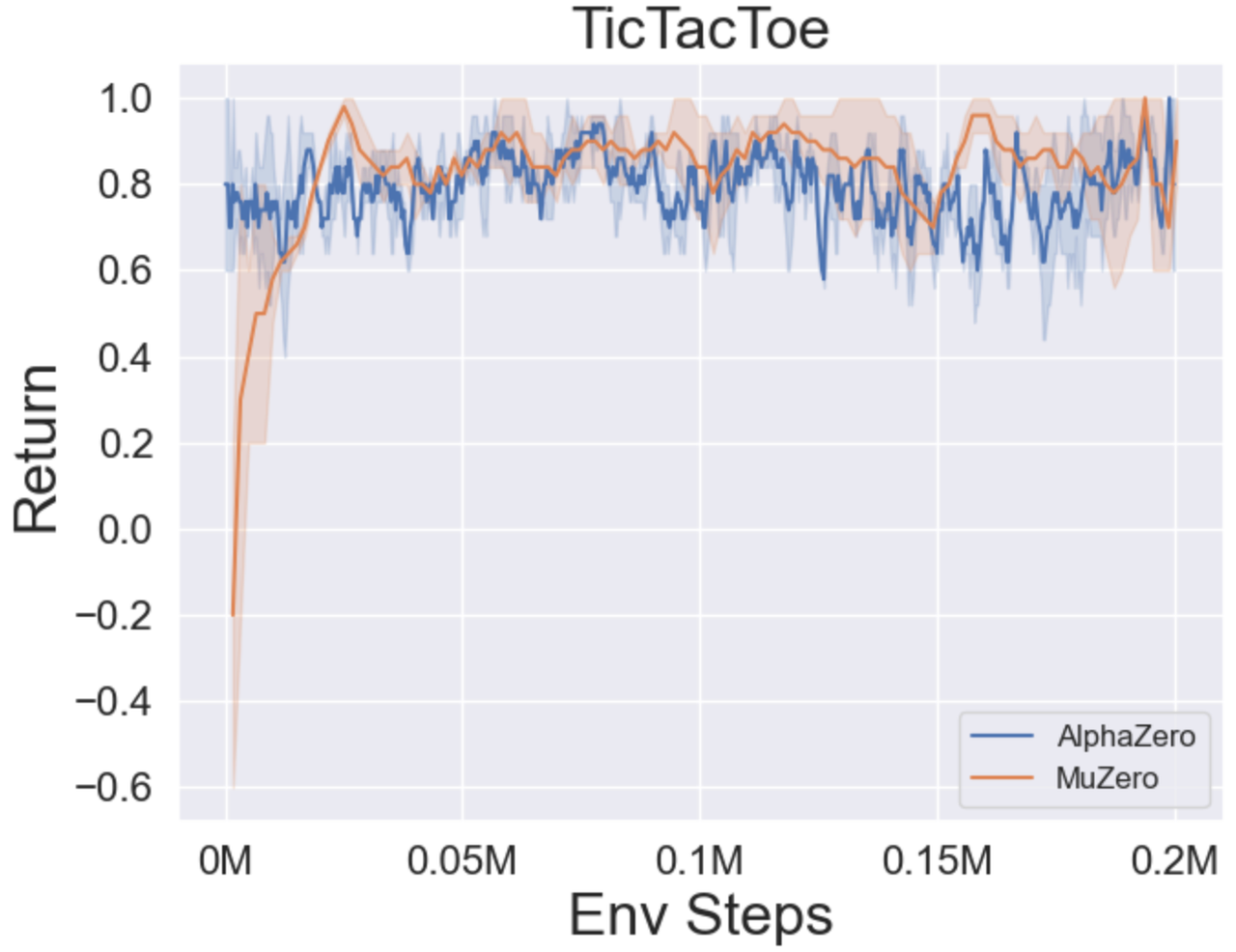
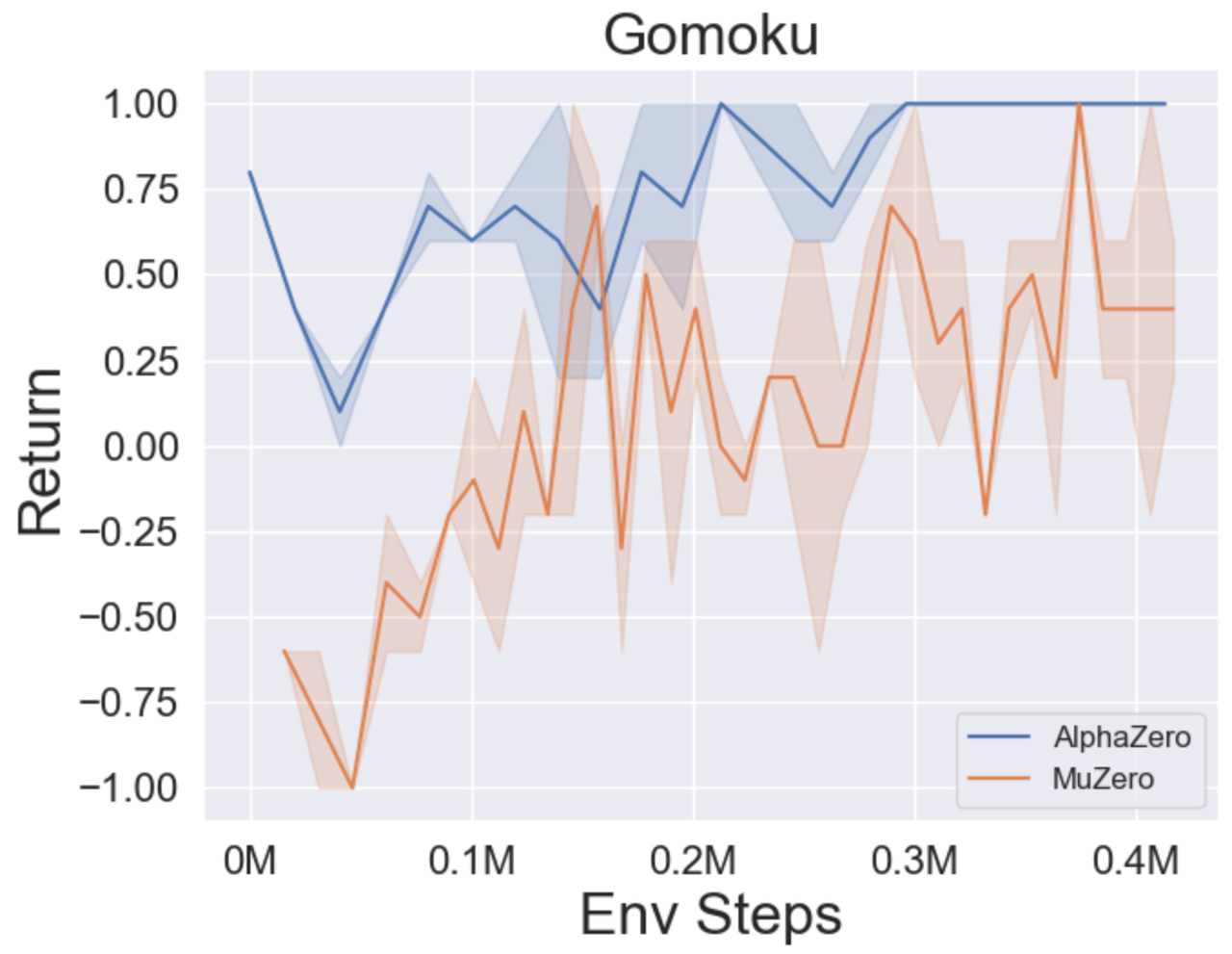
- Vous trouverez ci-dessous les résultats de référence d'Alphazero et Muzero sur trois jeux de société: Tictactoe, Connect4, Gomoku.
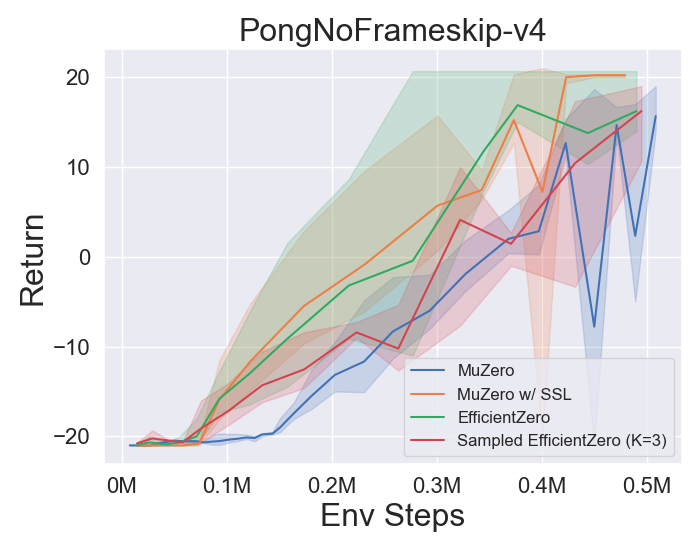
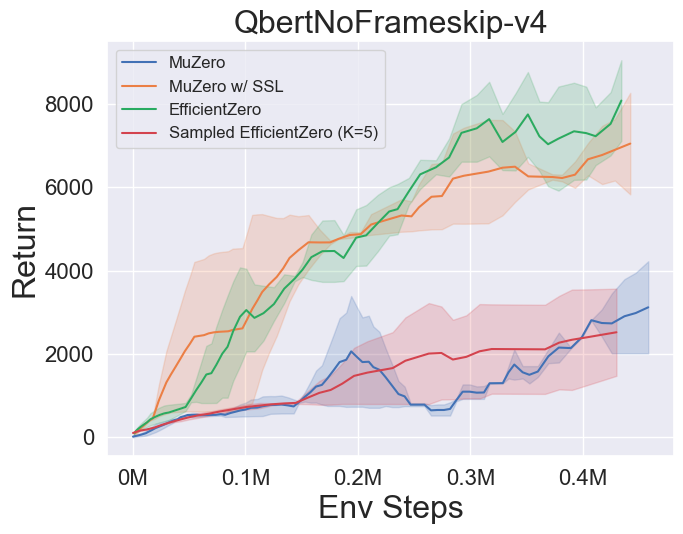
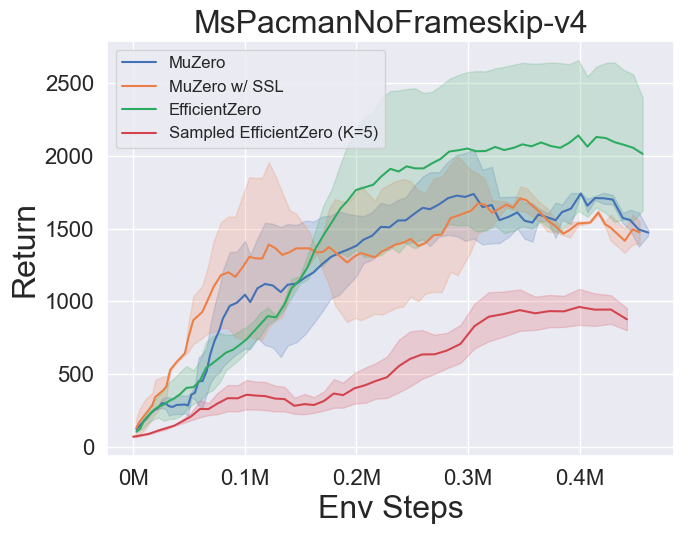
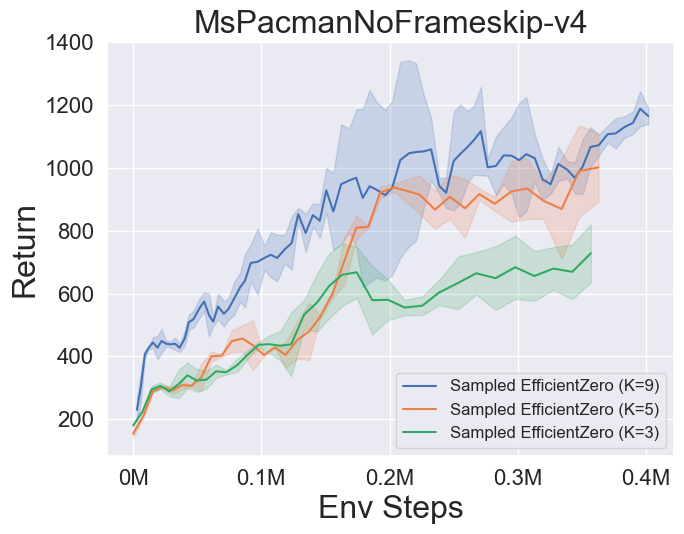
- Vous trouverez ci-dessous les résultats de référence de Muzero, Muzero W / SSL, efficacezero et échantillonné EfficientZero sur trois jeux d'espace d'action discrètes à Atari.
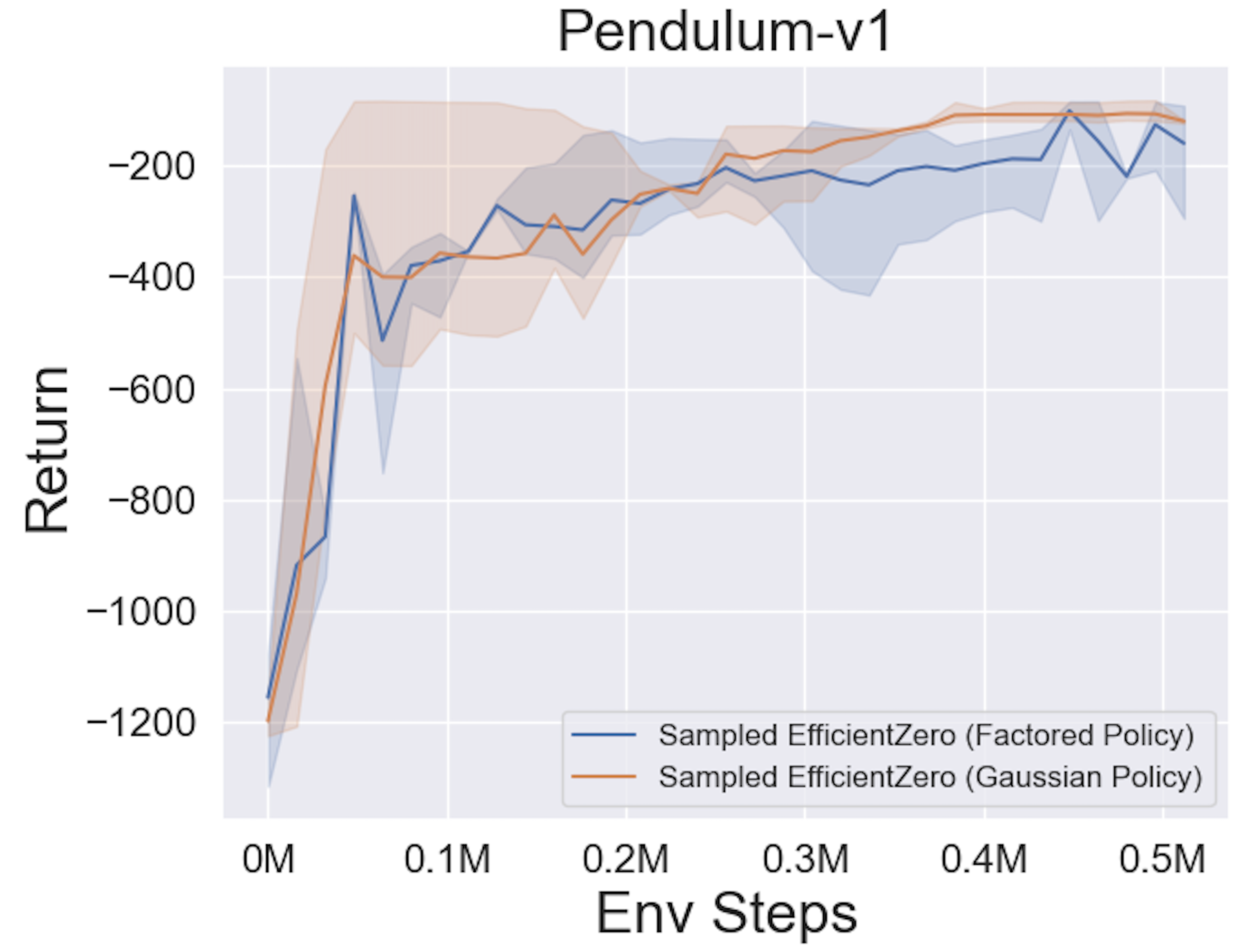
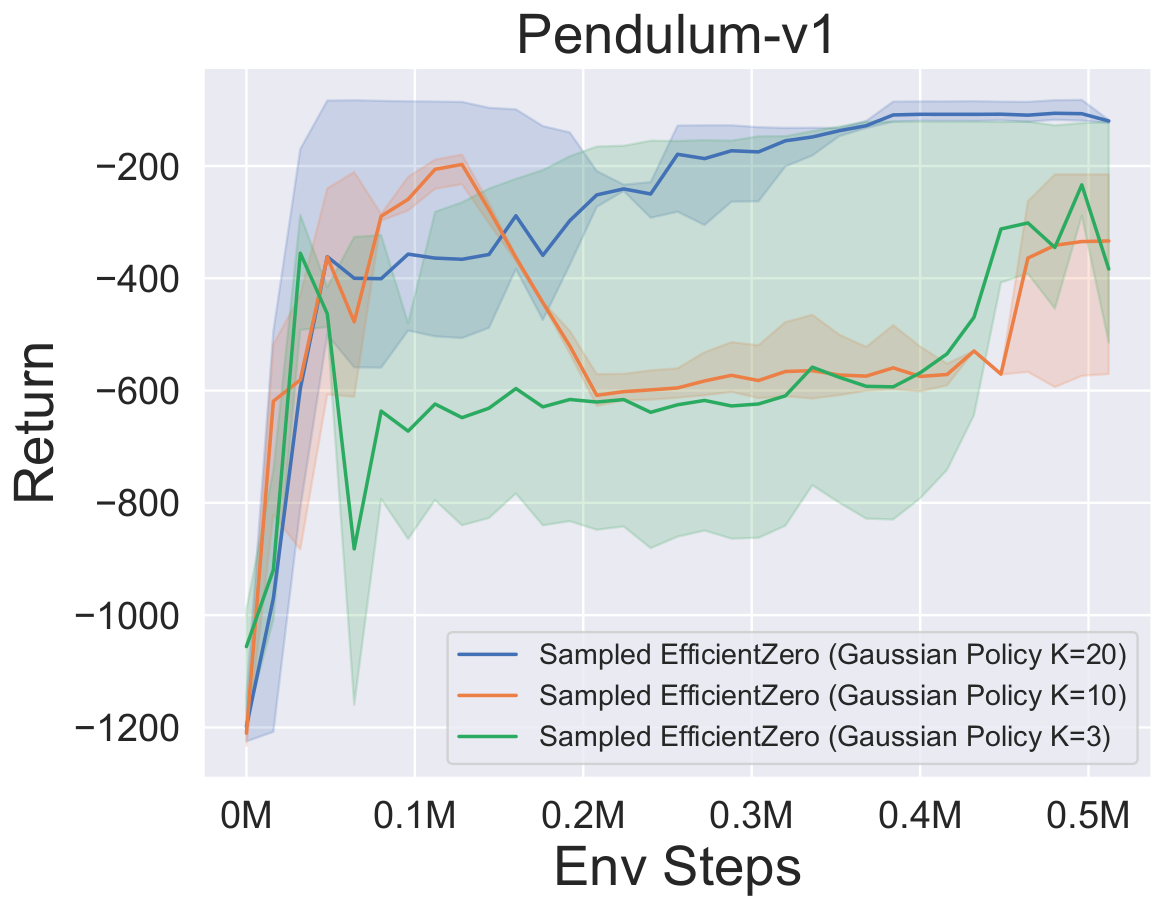
- Vous trouverez ci-dessous les résultats de référence d'EfficientTero échantillonné avec une représentation de politique
Factored/Gaussian sur trois jeux d'espace d'action continue classiques: Pendulum-V1, LunarlanderContinu-V2, Bipedalwalker-V3 et deux jeux spatiaux d'action continue mujoco: Hopper-V3, Walker2D-V3.
"Politique factorisée" indique que l'agent apprend un réseau de stratégie qui publie une distribution catégorique. Après discrétisation manuelle, les dimensions de l'espace d'action pour les cinq environnements sont 11, 49 (7 ^ 2), 256 (4 ^ 4), 64 (4 ^ 3) et 4096 (4 ^ 6), respectivement. D'un autre côté, la «politique gaussienne» fait référence à l'agent en apprenant un réseau de politique qui produit directement des paramètres (MU et Sigma) pour une distribution gaussienne.
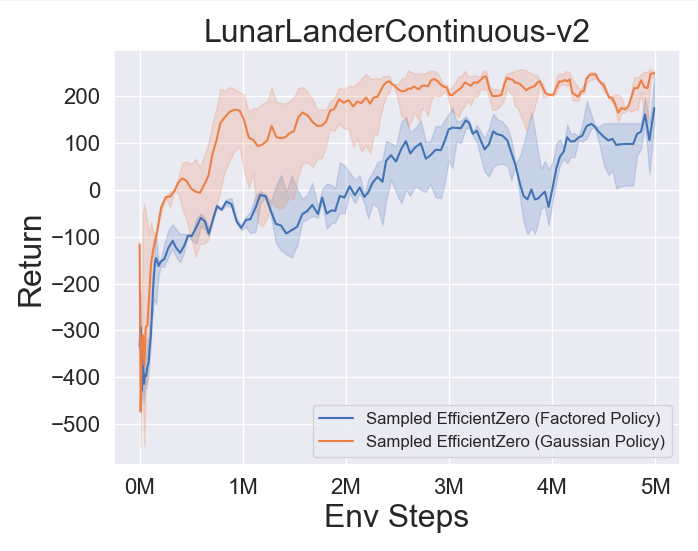
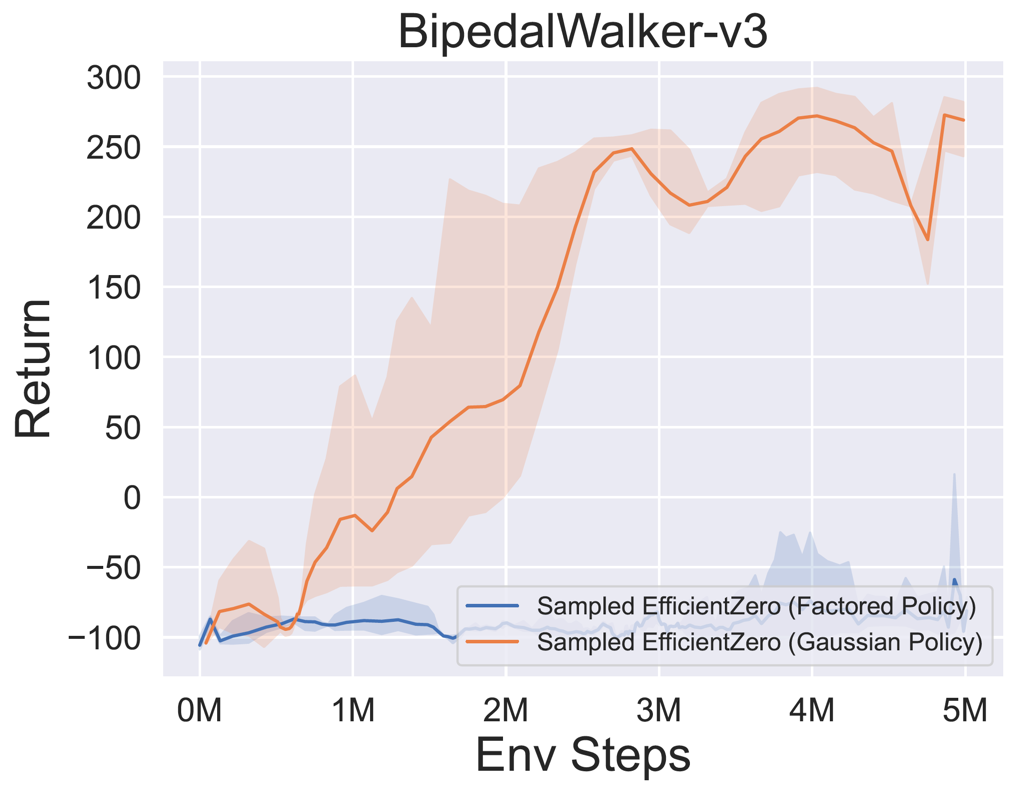
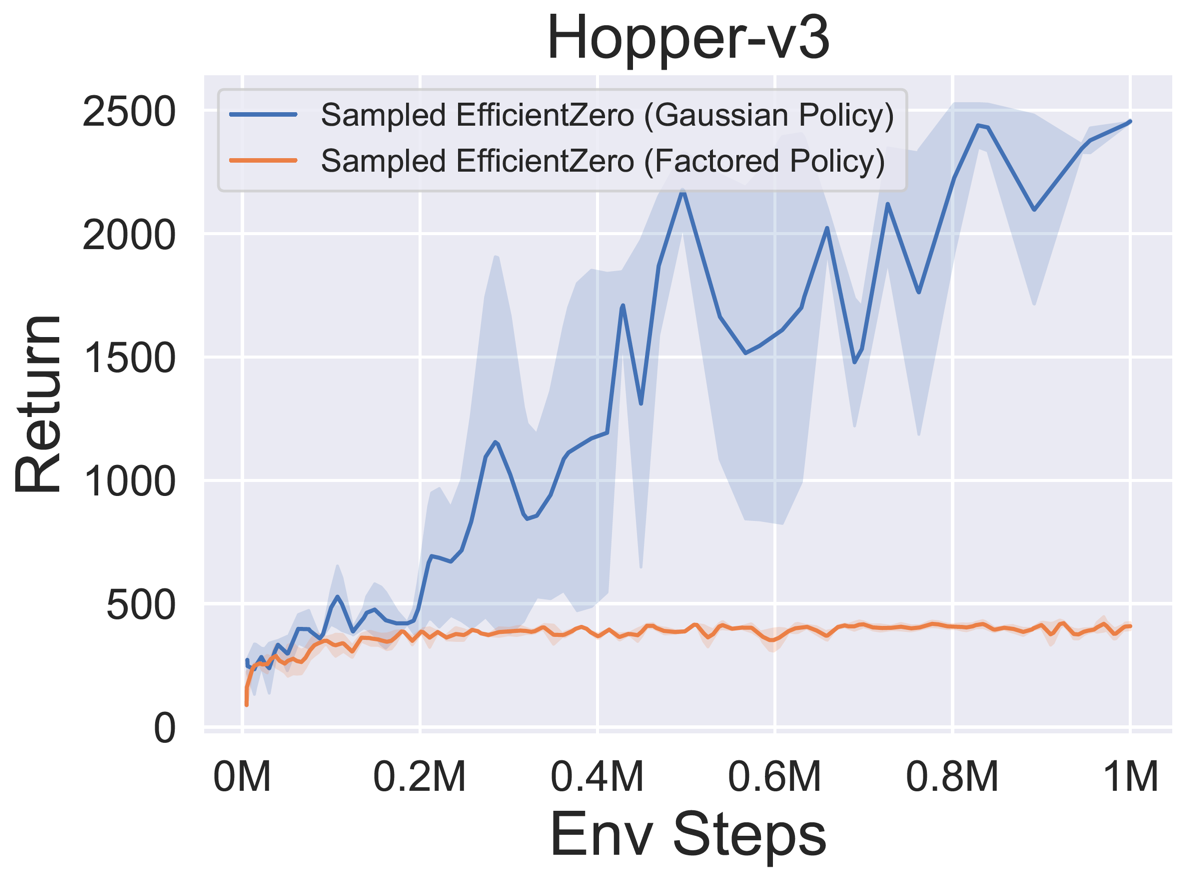
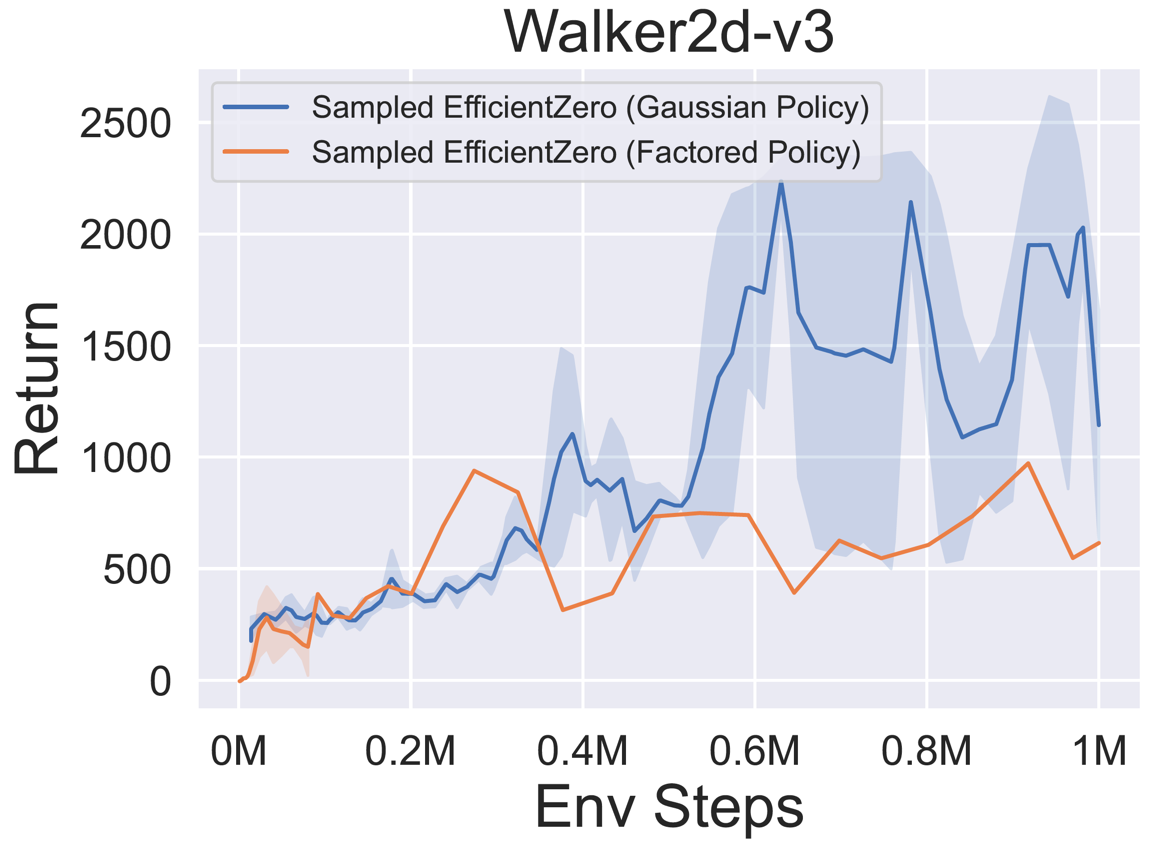
- Vous trouverez ci-dessous les résultats de référence de Gumbelmuzero et Muzero (sous un coût de simulation différent) sur quatre environnements: pongnoframeskip-v4, mspacmannoframeskip-v4, gomoku et lunarlanderContin-v2.
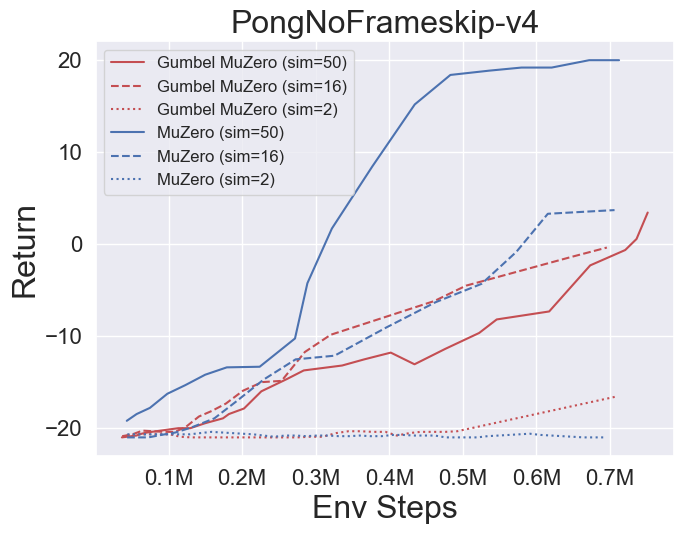
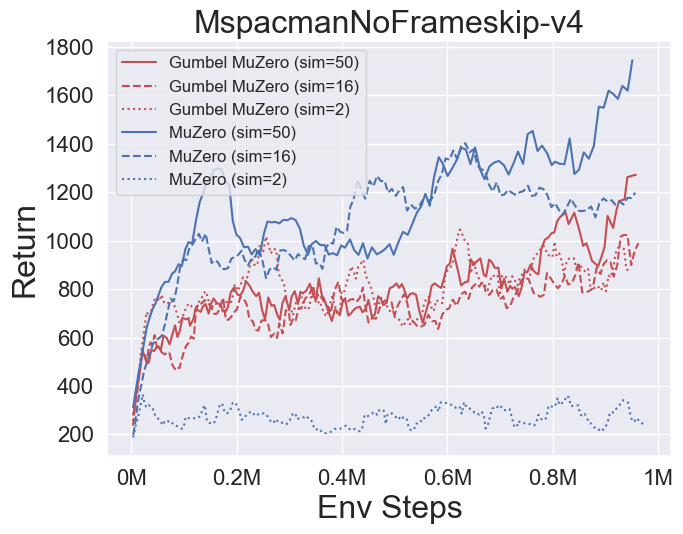
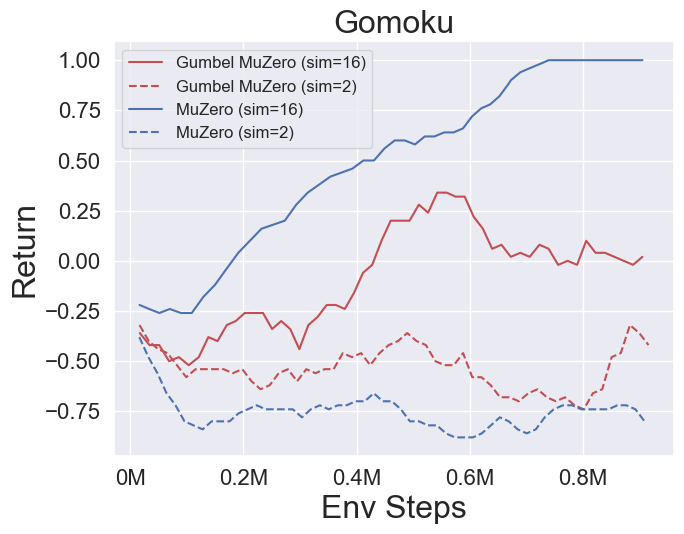
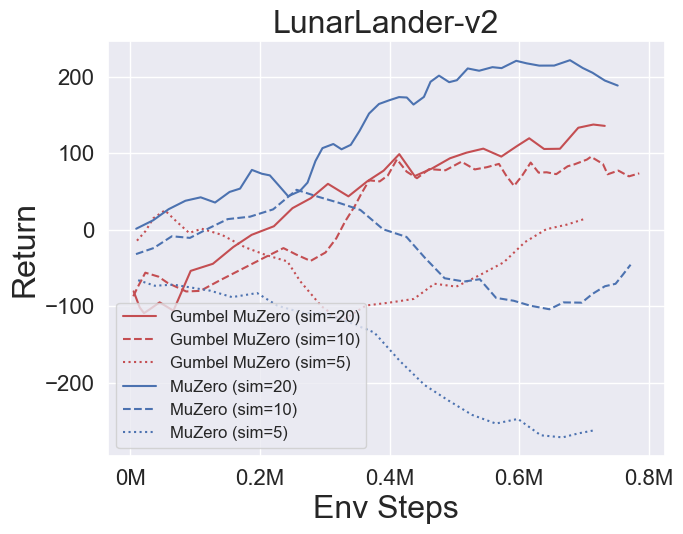
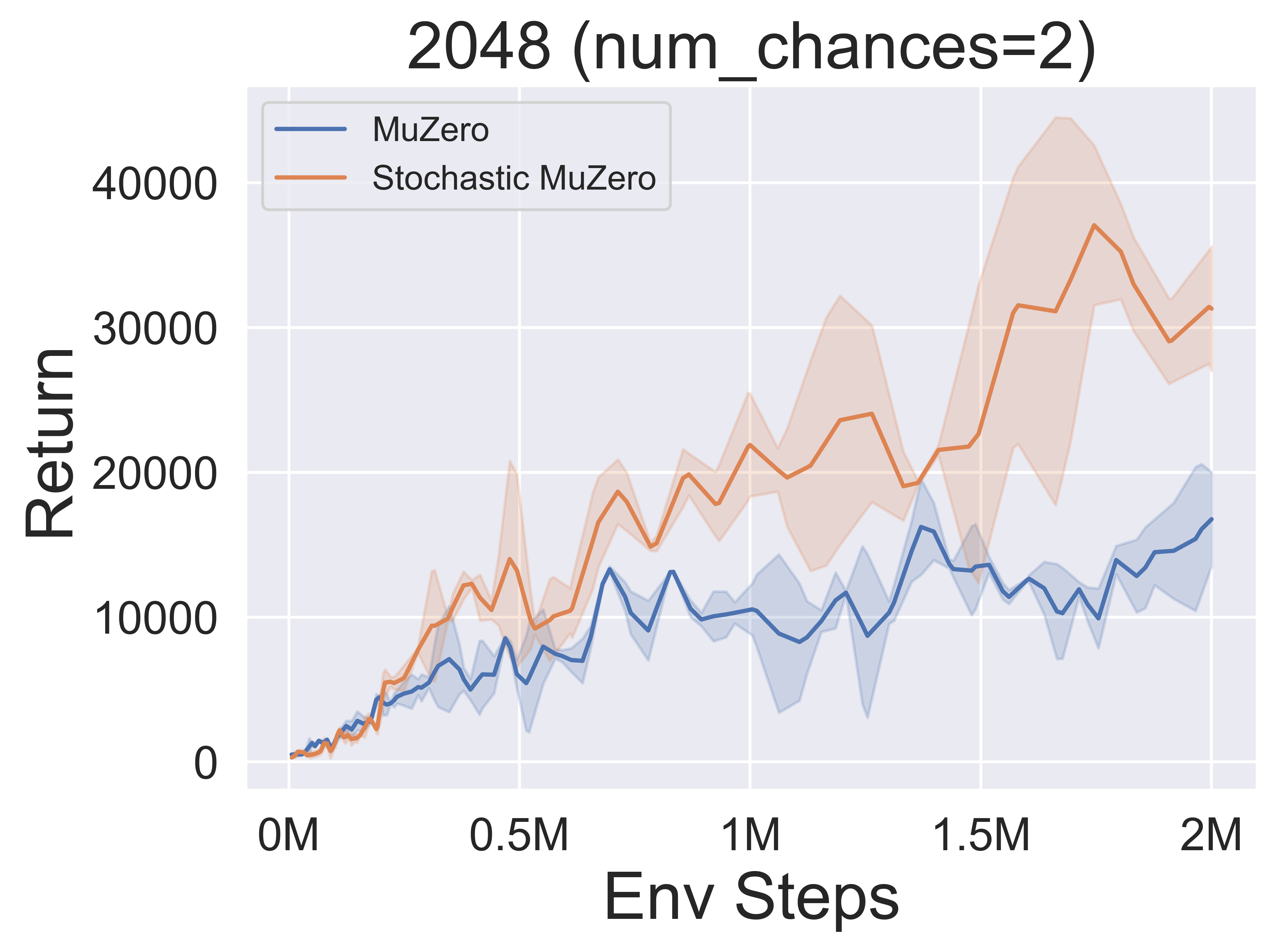
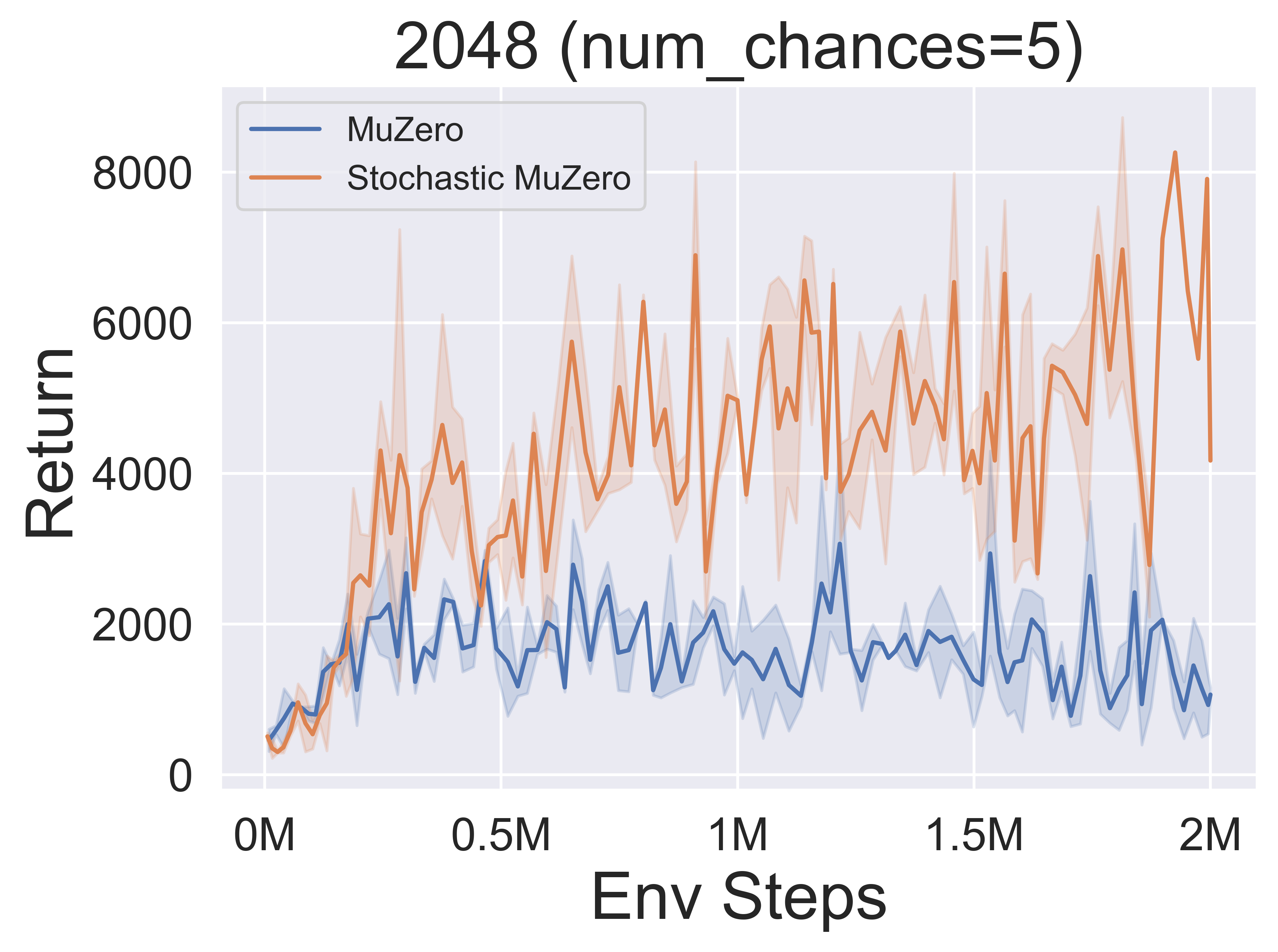
- Vous trouverez ci-dessous les résultats de référence de StochasticMuzero et Muzero sur l'environnement 2048 avec différents niveaux de chance (num_chances = 2 et 5).
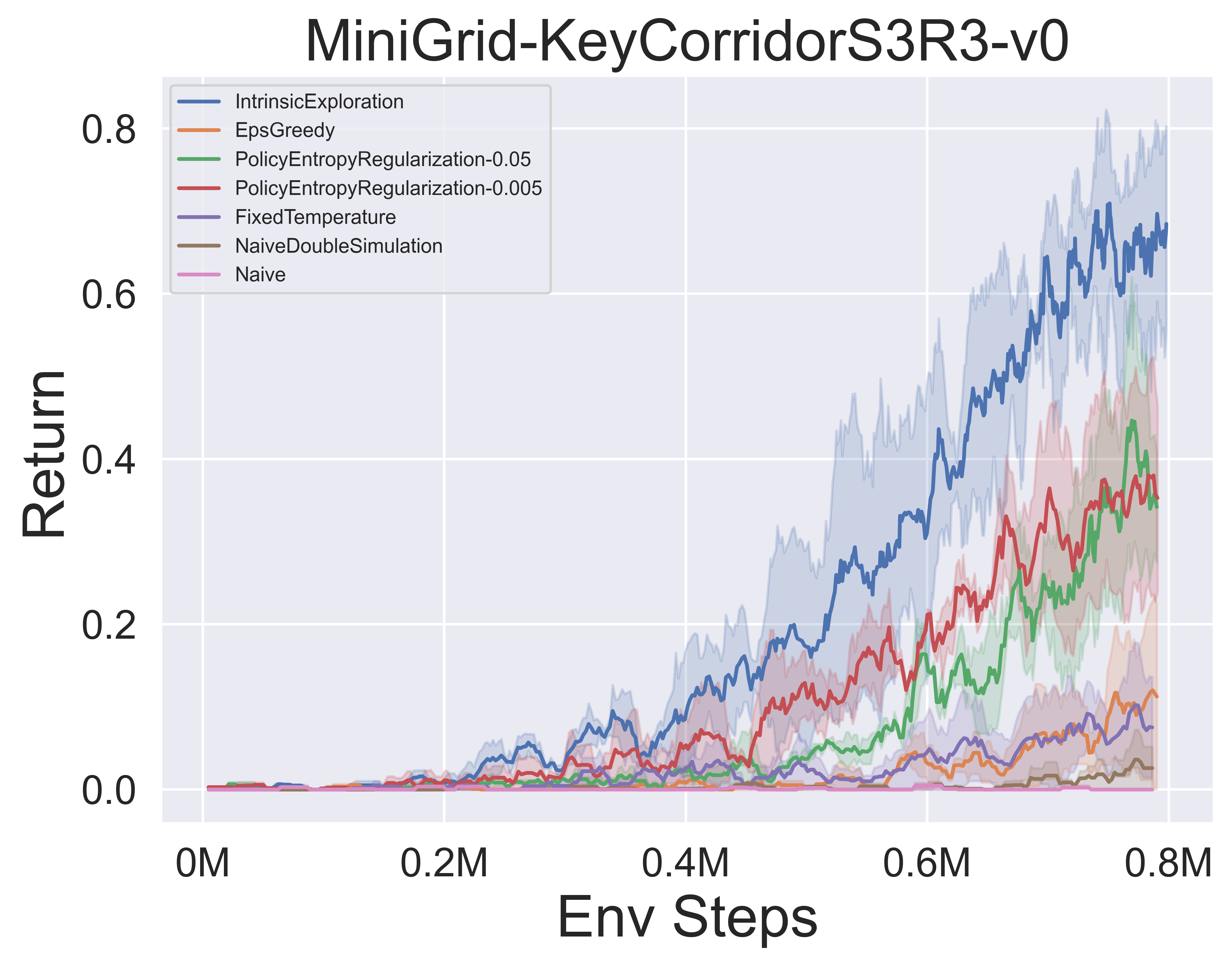
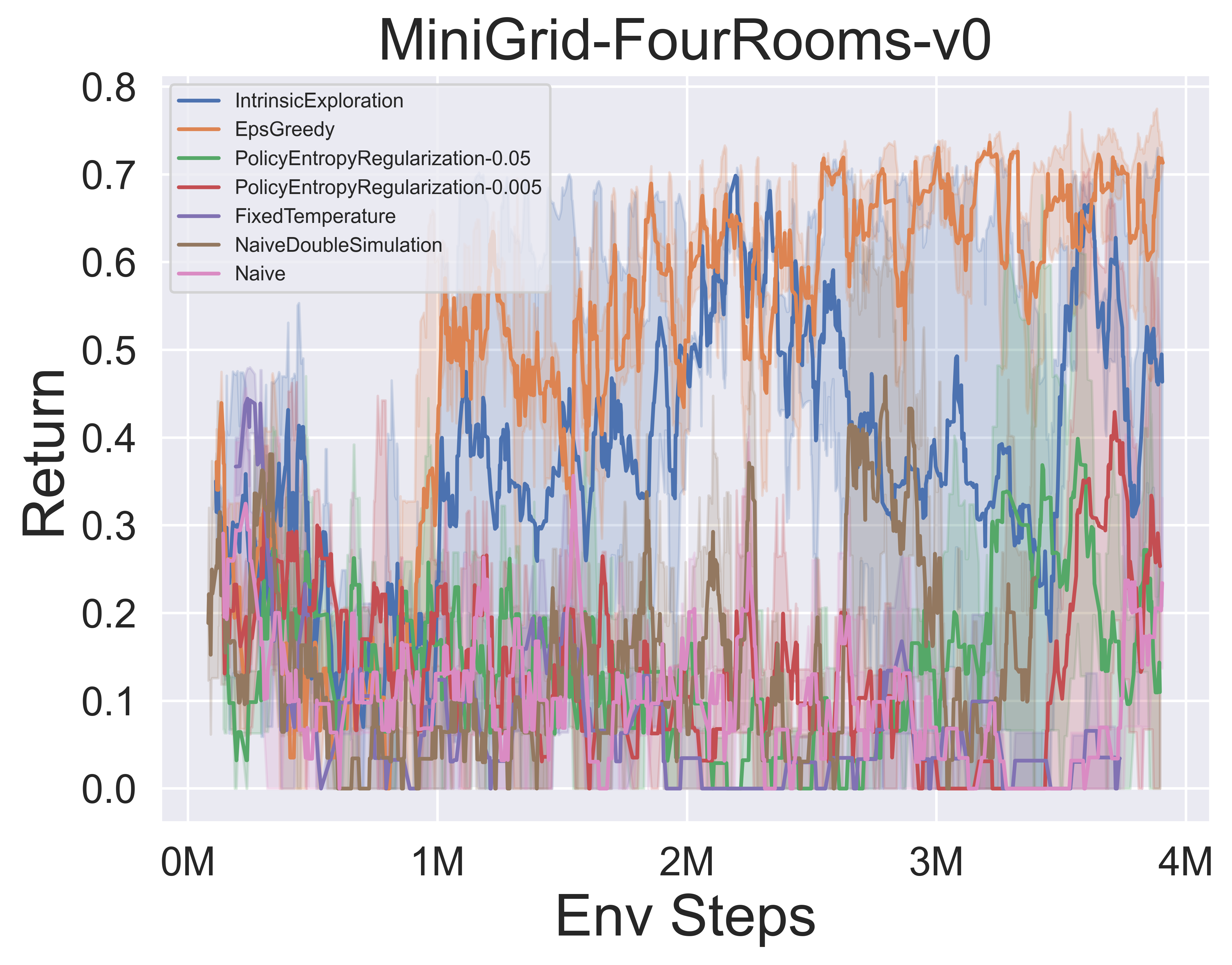
- Vous trouverez ci-dessous les résultats de référence de divers mécanismes d'exploration MCTS de Muzero W / SSL dans l'environnement minimigride.
Notes impressionnantes-MCT
Notes de papier
Voici les notes de papier détaillées (en chinois) des algorithmes ci-dessus:
Cliquez pour s'effondrer
- Alphazer
- Muzero
- Efficientzero
- Échantillon
- Glumbelmuzero
- Stochasticmuzero
- Notation
Vous pouvez également vous référer à la colonne Zhihu pertinente (en chinois): analyse approfondie des théories et applications de la frontière MCTS + RL.
Algo. Aperçu
Voici les diagrammes de principe MCTS de vue d'ensemble des algorithmes ci-dessus:
Cliquez pour agrandir
- MCTS
- Alphazer
- Muzero
- Efficientzero
- Échantillon
- Glumbelmuzero
- Stochasticmuzero
Papiers impressionnants-mcts
Voici une collection d'articles de recherche sur la recherche de Monte Carlo Tree . Cette section sera continuellement mise à jour pour suivre la frontière de MCTS.
Papiers clés
Cliquez pour agrandir
Série implémentée de LightZero
- Science 2018 Alphazero: un algorithme général d'apprentissage en renforcement qui maîtrise les échecs, le shogi et le jeu de soi
- 2019 Muzero: Mastering Atari, Go, Chess et Shogi en planifiant avec un modèle savant
- 2021 Efficientzero: Mastering Atari Games avec des données limitées
- 2021 Muzero échantillonné: apprentissage et planification dans des espaces d'action complexes
- 2022 Stochastic Muzero: planification dans des environnements stochastiques avec un modèle savant
- 2022 Gumbel Muzero: Amélioration des politiques par planification avec Gumbel
Série Alphago
- 2015 Nature Alphago Mastering the Game of Go with Deep Neural Networks and Tree Search
- 2017 Nature Alphago Zero Mastering the Game of Go Without Human Knowledge
- 2019 ELF OpenGO: Analyse et réimplémentation ouverte d'Alphazero
- 2023 Étudiant des jeux: un algorithme d'apprentissage unifié pour les jeux d'information parfaits et imparfaits
Série Muzero
- 2022 Apprentissage en ligne et hors ligne par planification avec un modèle savant
- 2021 Vector Modèles quantifiés de planification
- 2021 MUESLI: combinant des améliorations de l'optimisation des politiques.
Analyse MCTS
- 2020 Recherche d'arbres Monte-Carlo comme optimisation de stratégie régularisée
- 2021 modèles et valeurs auto-cohérentes
- 2022 Les politiques adversaires battent le niveau professionnel GO AIS
- 2022 PNAS Acquisition des connaissances d'échecs en Alphazer.
Application MCTS
- 2023 Apprenant de physique symbolique: Découvrir les équations gouvernantes via la recherche d'arbre Monte Carlo
- 2022 Nature Découvrir des algorithmes de multiplication matriciels plus rapides avec apprentissage par renforcement
- 2022 Muzero avec auto-compétition pour le contrôle des taux dans la compression vidéo VP9
- 2021 Douzero: maîtriser Doudizhu avec un apprentissage en renforcement profond de sa play
- 2019 combinant la planification et l'apprentissage en renforcement profond dans la prise de décision tactique pour la conduite autonome
Autres papiers
Cliquez pour agrandir
ICML
- Amélioration des politiques sûres évolutives via la recherche de monte carlo-arbre 2023
- Alberto Castellini, Federico Bianchi, Edoardo Zorzi, Thiago D. Simão, Alessandro Farinelli, Matthijs TJ Spaan
- Clé: Amélioration sûre des politiques en ligne à l'aide d'une stratégie basée sur le MCT
- EXPENV: Gridworld et Sysadmin
- Apprentissage efficace pour Alphazero via la cohérence du chemin 2022
- Dengwei Zhao, Shikui Tu, Lei Xu
- Clé: quantité limitée d'auto-plays, cohérence du chemin (PC)
- EXPENV: GO, Othello, Gomoku
- Visualiser les modèles Muzero 2021
- Joery A. De Vries, Ken S. Voskuil, Thomas M. Moerland, Aske Plaat
- Clé: Visualiser le modèle de dynamique équivalent de valeur, les trajectoires d'action divergent, deux techniques de régularisation
- EXPENV: Cartpole et Mountaincar.
- Regularisation convexe dans la recherche d'arbres Monte-Carlo 2021
- Dam Tuan, Carlo d'Eramo, Jan Peters, Joni Pajarinen
- Clé: opérateurs de sauvegarde de régularisation d'entropie, analyse de regret, tsallis Etropy,
- EXPENV: arbre synthétique, Atari
- Informations sur le filtre de particules: un algorithme en ligne pour les POMDP avec des récompenses basées sur la croyance sur les domaines continu 2020
- Johannes Fischer, Ömer Sahin Tas
- Clé: POMDP continu, arbre de filtre à particules, mise en forme de récompense basée sur l'information, collecte d'informations.
- EXPENV: Framework POMDPS.JL
- Code
- Retro *: Apprentissage de la planification rétrosynthétique avec guidé neuronal a * Search 2020
- Binghong Chen, Chengtao Li, Hanjun Dai, Le Song
- Clé: Planification rétrosynthétique chimique, algorithme de type A * basé sur le neuronal, ANDOR Tree
- EXPENV: ensembles de données USPTO
- Code
ICLR
- Le cadre d'équivalence de mise à jour pour la planification du temps de décision 2024
- Samuel Sokota, Gabriele Farina, David J Wu, Hengyuan HU, Kevin A. Wang, J Zico Kolter, Noam Brown
- Clé: jeux d'informations imparfaits, recherche, planification du temps de décision, équivalence de mise à jour
- EXPENV: Hanabi, 3x3 Hex sombre brusque et Phantom Tic-Tac-Toe
- Apprentissage efficace du renforcement multi-agents par planification 2024
- Qihan Liu, Jianing Ye, Xiaoteng MA, Jun Yang, Bin Liang, Chongjie Zhang
- Clé: Apprentissage en renforcement multi-agents, planification, MCT multi-agents
- Expenv: SMAC, Lunarlander, Mujoco et Google Research Football
- Devenir un joueur compétent avec des données limitées en regardant des vidéos pures 2023
- Weirui Ye, Yunsheng Zhang, Pieter Abbeel, Yang Gao
- Clé: pré-formation à partir de vidéos sans action, objectif de cohérence du cycle vers l'avant (FICC) basé sur la quantification vectorielle, la phase de pré-formation, la phase de réglage fin.
- Expenv: Atari
- Auto-compétition basée sur les politiques pour les problèmes de planification 2023
- Jonathan Pirnay, Quirin Göttl, Jakob Burger, Dominik Gerhard Grimm
- Clé: auto-compétition, trouvez de fortes trajectoires en planifiant contre les stratégies possibles de son passé.
- EXPENV: Problème des vendeurs itinérants et le problème de planification de l'emploi.
- Expliquer les modèles de graphiques temporels via un framework Explorer-Navigator 2023
- Wenwen Xia, Mincai Lai, Caihua Shan, Yao Zhang, Xinnan Dai, Xiang Li, Dongsheng Li
- Clé: Temporal GNN Explicateur, un explorateur pour trouver les sous-ensembles d'événements avec MCTS, un navigateur qui apprend les corrélations entre les événements et aide à réduire l'espace de recherche.
- EXPENV: Wikipedia et Reddit, ensembles de données synthétiques
- SpeedyZero: Mastering Atari avec des données et un temps limités 2023
- Yixuan mei, jiaxuan gao, weirui ye, shaohuai liu, yang gao, yi wu
- Clé: Système RL distribué, actualisation prioritaire, Lars coupé
- Expenv: Atari
- Optimisation efficace de politique hors ligne avec un modèle appris 2023
- Zichen Liu, Siyi Li, Wee Sun Lee, Shicheng Yan, Zhongwen Xu
- Clé: Algorithme basé sur un modèle régularisé pour Offline-RL
- EXPENV: Atari , Bsuite
- Code
- Activer les objectifs de traduction arbitraire avec une recherche d'arborescence adaptative 2022
- Wang Ling, Wojciech Stokowiec, Domenic Donato, Chris Dyer, Lei Yu, Laurent Sartran, Austin Matthews
- Clé: recherche d'arborescence adaptative, modèles de traduction, modèles autorégressifs,
- EXPENV: Tâches chinoises-anglais et pachto - anglaise de WMT2020, allemand - anglais de WMT2014
- Quel est le problème avec l'apprentissage en profondeur dans la recherche d'arbres pour l'optimisation combinatoire 2022
- Maximi1an Böther, Otto Kißig, Martin Taraz, Sarel Cohen, Karen Seidel, Tobias Friedrich
- Clé: optimisation combinatoire, suite de référence open source pour le problème de jeu indépendant maximum NP-dur, une analyse approfondie de l'algorithme de recherche d'arborescence guidée populaire, comparez les implémentations de recherche d'arbres à d'autres solveurs
- EXPENV: ensemble indépendant maximum NP-Dur-Hard.
- Code
- Planification et apprentissage de Monte-Carlo avec les estimations de la valeur de l'action linguistique 2021
- Youngoo Jang, Seokin Seo, Jongmin Lee, Kee-Eung Kim
- Clé: Recherche d'arbres Monte-Carlo avec exploration axée sur le langage, estimations de valeur du langage optimiste localement.
- Expenv: jeux de fiction interactive (IF)
- Recherche d'arbres monte-car-carrlo pratique massivement parallèle appliquée à la conception moléculaire 2021
- Xiufeng Yang, Tanuj Kr Aasawat, Kazuki Yoshizoe
- Clé: Recherche d'arbres Monte-Carlo parallèle massivement parallèle, conception moléculaire, recherche parallèle par hachage,
- EXPENV: Coefficient de partition d'octanol-eau (LOGP) pénalisé par l'accessibilité synthétique (SA) et le score de pénalité à gros anneau.
- Regardez les non observés: une approche simple pour paralléliser la recherche de monte carlo 2020
- Anji Liu, Jianshu Chen, Mingze Yu, Yu Zhai, Xuewen Zhou, Ji Liu
- Clé: Recherche parallèle de l'arbre Monte-Carlo, partitionner efficacement l'arbre en sous-arbres, comparer le rapport d'observation de chaque processeur.
- EXPENV: SPEALUP ET PERFORMANCE DE PERFORMANCE SUR JOY-CITY GAME, RETOUR DE L'ÉPÉNISE MOYENNE SUR ATARI GAME
- Code
- Apprendre à planifier en dimensions élevées via les arbres d'exploration neuronale 2020
- Binghong Chen, Bo Dai, Qinjie Lin, Guo Ye, Han Liu, Le Song
- Clé: Meta Path Planning Algorithme, exploite une nouvelle architecture neuronale qui peut apprendre des directions de recherche prometteuses à partir de structures de problèmes.
- EXPENV: un espace de travail 2D avec un robot Point 2 DOF (degrés de liberté), un robot de bâton à 3 DOF et un robot de serpent à 5 DOF
Nezier
- Lightzero: une référence unifiée pour la recherche de Monte Carlo Tree dans les scénarios de décision séquentiels généraux 2023
- Yazhe Niu, Yuan Pu, Zhenjie Yang, Xueyan Li, Tong Zhou, Jiyuan Ren, Shuai Hu, Hongsheng Li, Yu Liu
- Clé: la première référence unifiée pour déployer MCTS / Muzero dans les scénarios de décision séquentiels généraux.
- EXPENV: ClassicControl, Box2d, Atari, Mujoco, Gobigger, Minigrid, Tictactoe, ConnectFour, Gomoku, 2048, etc.
- Modèles de grande langue comme connaissances de bon sens pour la planification des tâches à grande échelle 2023
- Zirui Zhao, Wee Sun Lee, David Hsu
- Clé: World Model (LLM) et la politique induite par LLM peuvent être combinés dans MCTS, pour augmenter la planification des tâches.
- EXPENV: Multiplication, planification des voyages, réarrangement des objets
- Recherche d'arbre Monte Carlo avec Boltzmann Exploration 2023
- Michael Painter, Mohamed Baioumy, Nick Hawes, Bruno Lacerda
- Clé: Boltzmann Exploration avec MCTS, actions optimales pour l'objectif d'entropie maximal ne correspond pas nécessairement à des actions optimales pour l'objectif d'origine, deux algorithmes améliorés.
- Expenv: l'environnement du lac gelé, le problème de la voile, allez
- Cohérence généralisée de chemin pondéré pour la maîtrise des jeux Atari 2023
- Dengwei Zhao, Shikui Tu, Lei Xu
- Clé: cohérence généralisée du chemin pondéré, un mécanisme de pondération.
- Expenv: Atari
- Accélération de la recherche de monte carlo avec une abstraction de l'état d'arbre de probabilité 2023
- Yangqing Fu, Ming Sun, Buqing Nie, Yue Gao
- Clé: Abstraction de l'état de l'arborescence de probabilité, transitivité et erreur d'agrégation liées
- EXPENV: Atari, Cartpole, Lunarlander, Gomoku
- Passer du temps à réfléchir judicieusement: accélérer les MCT avec des extensions virtuelles 2022
- Weirui Ye, Pieter Abbeel, Yang Gao
- Clé: Échangez le calcul par rapport aux extensions virtuelles, passez du temps de manière adaptative.
- EXPENV: Atari, 9x9 Go
- Planification de l'échantillon Imitation efficace Apprentissage 2022
- Zhao-Heng Yin, Weirui Ye, Qifeng Chen, Yang Gao
- Clé: Clonage comportemental , Apprentissage par imitation adversaire (AIL) , RL basé sur MCTS.
- EXPENV: Suite de contrôle DeepMind
- Code
- Évaluation au-delà de la performance des tâches: analyse des concepts dans Alphazero dans Hex 2022
- Charles Lovering, Jessica Zosa Forde, George Konidaris, Ellie Pavlick, Michael L. Littman
- Clé: les représentations internes d'Alphazero, le sondage du modèle et les tests comportementaux, comment ces concepts sont capturés dans le réseau.
- Expenv: Hex
- Les agents de type Alphazero sont-ils robustes aux perturbations contradictoires? 2022
- Li-Cheng Lan, Huan Zhang, Ti-Rong Wu, Meng-Yu Tsai, I-Chen Wu, 4 Cho-Jui Hsieh
- Clé: états contradictoires, première attaque contradictoire sur Go Ais.
- Expenv: allez
- Descente Monte Carlo Tree pour l'optimisation de la boîte noire 2022
- Yaoguang Zhai, Sicun Gao
- Clé: Optimisation de la boîte noire, comment intégrer davantage la descente basée sur des échantillons pour une optimisation plus rapide.
- EXPENV: Fonctions synthétiques pour l'optimisation non linéaire, les problèmes d'apprentissage du renforcement dans les environnements de locomotion Mujoco et les problèmes d'optimisation dans la recherche d'architecture neuronale (NAS).
- Sélection variable basée sur la recherche de Monte Carlo Tree pour une optimisation bayésienne de grande dimension 2022
- Lei Song ∗, Ke Xue ∗, Xiaobin Huang, Chao Qian
- Clé: Un sous-espace de faible dimension via MCTS, optimise dans le sous-espace avec tout algorithme d'optimisation bayésien.
- EXPENV: Problèmes NAS-Bench et locomotion Mujoco
- Recherche de monte carlo avec des abstractions d'état raffinant de manière itérative 2021
- Samuel Sokota, Caleb HO, Zaheen Ahmad, J. Zico Kolter
- Clé: environnements stochastiques, élargissement progressif, raffinage d'abstraction
- EXPENV: Blackjack, piège, cinq sur cinq Go.
- Synoptique profonde Monte Carlo Planification dans la reconnaissance Blind Échecs 2021
- Gregory Clark
- Clé: Informations imparfaites, état de croyance avec un filtre de particules non pondéré, une nouvelle abstraction stochastique des états d'information.
- EXPENV: Échecs aveugles de reconnaissance
- Poly-Hoot: Planification de Monte-Carlo dans des MDP d'espace continu avec analyse non asymptotique 2020
- Weichao Mao, Kaiqing Zhang, Qiaomin Xie, Tamer Ba¸sar
- Clé: Espaces d'action d'action continue, optimisation optimiste hiérarchique.
- Expenv: Cartpole, pendule inversé, swing-up et lunarlander.
- Apprentissage de la partition de l'espace pour l'optimisation de la boîte noire à l'aide de la recherche de Monte Carlo Tree 2020
- Linnan Wang, Rodrigo Fonseca, Yuandong Tian
- Clé: apprend la partition de l'espace de recherche à l'aide de quelques échantillons, une limite de décision non linéaire et apprend un modèle local pour choisir de bons candidats.
- Expenv: tâches de locomotion Mujoco, références à petite échelle,
- Mélange et assortir: une approche optimiste de recherche d'arbres pour les modèles d'apprentissage à partir des distributions de mélange 2020
- Matthew Faw, Rajat Sen, Karthikeyan Shanmugam, Constantine Caramanis, Sanjay Shakkottai
- Clé: le problème de décalage covariable, le mélange et le match combinent la descente de gradient stochastique (SGD) avec la recherche et la réutilisation optimistes des arbres (évolution de modèles partiellement formés avec des échantillons de différentes distributions de mélange)
- Code
Autre conférence ou journal
- Apprendre à s'arrêter: Simulation dynamique Monte-Carlo Tree Search AAAI 2021.
- Sur Monte Carlo Tree Search and Renforcement Learning Journal of Artificial Intelligence Research 2017.
- Recherche d'architecture neuronale économe en échantillons en apprenant les actions de la recherche de monte Carlo Recherche IEEE sur l'analyse des modèles et l'intelligence machine 2022.
Rétroaction et contribution
Déposez un problème sur GitHub
Ouvrez ou participez à notre forum de discussion
Discuter sur Lightzero Discord Server
Contactez notre e-mail ([email protected])
Nous apprécions toutes les commentaires et contributions pour améliorer Lightzero, à la fois les algorithmes et les conceptions du système.
? Citation
@article{niu2024lightzero,
title={LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios},
author={Niu, Yazhe and Pu, Yuan and Yang, Zhenjie and Li, Xueyan and Zhou, Tong and Ren, Jiyuan and Hu, Shuai and Li, Hongsheng and Liu, Yu},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
@article{pu2024unizero,
title={UniZero: Generalized and Efficient Planning with Scalable Latent World Models},
author={Pu, Yuan and Niu, Yazhe and Ren, Jiyuan and Yang, Zhenjie and Li, Hongsheng and Liu, Yu},
journal={arXiv preprint arXiv:2406.10667},
year={2024}
}
@article{xuan2024rezero,
title={ReZero: Boosting MCTS-based Algorithms by Backward-view and Entire-buffer Reanalyze},
author={Xuan, Chunyu and Niu, Yazhe and Pu, Yuan and Hu, Shuai and Liu, Yu and Yang, Jing},
journal={arXiv preprint arXiv:2404.16364},
year={2024}
}? Remerciements
Ce projet a été développé en partie basé sur les travaux pionniers suivants sur les référentiels GitHub. Nous exprimons notre profonde gratitude pour ces ressources fondamentales:
- https://github.com/opendilab/di-engine
- https://github.com/deepmind/mctx
- https://github.com/yewr/efficientzero
- https://github.com/werner-duvaud/muzero-general
Nous tenons à nous remercier particulièrement les contributeurs suivants @ Paparazz1, @karroyan, @nigheood, @ jayyoung0802, @timothijoe, @tutuhuss, @harryxuancy, @ puyuan1996, @hansbug pour leurs précieux contributions et leur soutien à cette bibliothèque d'algorithme.
Merci à tous ceux qui ont contribué à ce projet:
«Licence
Tout le code de ce référentiel est sous la licence 2.0 Apache.
(Retour en haut)



