Ligero
Actualizado en 2024.12.10 Lightzero-V0.1.0
Inglés | 简体中文 (chino simplificado) | Documentación | Papel Lightzero | Papel Unizero | Papel rezaero
Lightzero es un kit de herramientas de algoritmo de código abierto ligero, eficiente y fácil de entender que combina la búsqueda de árboles de Monte Carlo (MCTS) y el aprendizaje de refuerzo profundo (RL). Para cualquier pregunta sobre Lightzero, puede consultar al asistente de preguntas y respuestas basadas en el trapo: Zeropal.
? Fondo
La integración de la búsqueda de árboles de Monte Carlo y el aprendizaje de refuerzo profundo, ejemplificado por Alphazero y Muzero, ha logrado niveles de rendimiento sin precedentes en varios juegos, incluidos Go y Atari. Esta metodología avanzada también ha hecho avances significativos en dominios científicos como la predicción de la estructura de proteínas y la búsqueda de algoritmos de multiplicación de matriz. La siguiente es una descripción general de la evolución histórica de la serie de algoritmo de búsqueda de árboles de Monte Carlo:
La imagen de arriba es la tubería marco de Lightzero. Presentamos brevemente los tres módulos básicos a continuación:
Modelo : Model se utiliza para definir la estructura de la red, incluida la función __init__ para inicializar la estructura de la red y la función forward para calcular la propagación del avance de la red.
Política : Policy define la forma en que se actualiza la red e interactúa con el entorno, incluidos tres procesos: el proceso learning , el proceso collecting y el proceso evaluation .
MCTS : MCTS define la estructura del árbol de búsqueda de Monte Carlo y la forma en que interactúa con la política. La implementación de MCT incluye dos idiomas: Python y C ++, implementados en ptree y ctree , respectivamente.
Para la estructura del archivo de LightZero, consulte LightZero_File_Structure.
? Algoritmos integrados
Lightzero es una biblioteca con una implementación de Pytorch de algoritmos MCTS (a veces combinados con Cython y CPP), que incluye:
- Alphazero
- Muzero
- Muestreado a muzero
- Muicero estocástico
- Eficientezero
- Gumbel MuZero
- Rezaero
- Unizero
Los entornos y algoritmos actualmente compatibles con LightZero se muestran en la tabla a continuación:
| Env./algo. | Alphazero | Muzero | Muestreado a muzero | Eficientezero | Muestra eficientezero | Gumbel MuZero | Muicero estocástico | Unizero | UNIATO DE MUESTRA | Rezaero |
|---|
| Tictacoe | ✔ | ✔ | | | | ✔ | | ✔ | | |
| Gomoku | ✔ | ✔ | | | | ✔ | | ✔ | | ✔ |
| Conectar4 | ✔ | ✔ | | | | | | ✔ | | ✔ |
| 2048 | --- | ✔ | | | | | ✔ | ✔ | | |
| Ajedrez | | | | | | | | | | |
| Ir | | | | | | | | | | |
| Carrito | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| Péndulo | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ | |
| Lunarlander | --- | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | |
| Bipedalwalker | --- | ✔ | ✔ | ✔ | ✔ | ✔ | | | ✔ | |
| Atari | --- | ✔ | | ✔ | ✔ | ✔ | ✔ | ✔ | | ✔ |
| Control profundo | --- | --- | ✔ | --- | ✔ | | | | ✔ | |
| Mujoco | --- | ✔ | | ✔ | ✔ | | | | | |
| Minigrídico | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Bsuite | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| Memoria | --- | ✔ | | ✔ | ✔ | | | ✔ | | |
| SumTothree (billar) | --- | | | | ✔ | | | | | |
| Metadrive | --- | | | | ✔ | | | | | |
(1): "✔" significa que el elemento correspondiente está terminado y bien probado.
(2): "" significa que el elemento correspondiente está en la lista de espera (trabajo en progreso).
(3): "---" significa que este algoritmo no es compatible con este entorno.
Instalación
Puede instalar el último LightZero en desarrollo desde los códigos de origen de GitHub con el siguiente comando:
git clone https://github.com/opendilab/LightZero.git
cd LightZero
pip3 install -e .
Tenga en cuenta que Lightzero actualmente admite la compilación solo en las plataformas Linux y macOS . Estamos trabajando activamente para extender este soporte a la plataforma Windows . Su paciencia durante esta transición es muy apreciada.
Instalación con Docker
También proporcionamos un DockerFile que establece un entorno con todas las dependencias necesarias para ejecutar la biblioteca Lightzero. Esta imagen de Docker se basa en Ubuntu 20.04 e instala Python 3.8, junto con otras herramientas y bibliotecas necesarias. Aquí le mostramos cómo usar nuestro DockerFile para construir una imagen Docker, ejecutar un contenedor desde esta imagen y ejecutar el código LightZero dentro del contenedor.
- Descargue DockerFile : The DockerFile se encuentra en el directorio raíz del repositorio de Lightzero. Descargue este archivo a su máquina local.
- Prepare el contexto de compilación : cree un nuevo directorio vacío en su máquina local, mueva el DockerFile a este directorio y navegue a este directorio. Este paso ayuda a evitar enviar archivos innecesarios al Docker Daemon durante el proceso de compilación.
mkdir lightzero-docker
mv Dockerfile lightzero-docker/
cd lightzero-docker/
- Construya la imagen Docker : use el siguiente comando para construir la imagen Docker. Este comando debe ejecutarse desde el interior del directorio que contiene DockerFile.
docker build -t ubuntu-py38-lz:latest -f ./Dockerfile .
- Ejecute un contenedor desde la imagen : use el siguiente comando para iniciar un contenedor desde la imagen en modo interactivo con un shell bash.
docker run -dit --rm ubuntu-py38-lz:latest /bin/bash
- Ejecute el código Lightzero dentro del contenedor : una vez que esté dentro del contenedor, puede ejecutar el script de Python de ejemplo con el siguiente comando:
python ./LightZero/zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Comienzo rápido
Entrena a un agente de Muzero para jugar Cartpole:
cd LightZero
python3 -u zoo/classic_control/cartpole/config/cartpole_muzero_config.py
Entrena a un agente de Muzero para jugar con Pong:
cd LightZero
python3 -u zoo/atari/config/atari_muzero_segment_config.py
Entrena a un agente de MuZero para que juegue Tictactoe:
cd LightZero
python3 -u zoo/board_games/tictactoe/config/tictactoe_muzero_bot_mode_config.py
Entrena a un agente de un abrigo para jugar Pong:
cd LightZero
python3 -u zoo/atari/config/atari_unizero_segment_config.py
Documentación
La documentación de Lightzero se puede encontrar aquí. Contiene tutoriales y la referencia de API.
Para aquellos interesados en personalizar entornos y algoritmos, proporcionamos guías relevantes:
- Personalizar entornos
- Personalizar algoritmos
- ¿Cómo establecer archivos de configuración?
- Sistema de registro y monitoreo
Si tiene alguna pregunta, no dude en contactarnos para obtener apoyo.
Punto de referencia
Haga clic para expandir
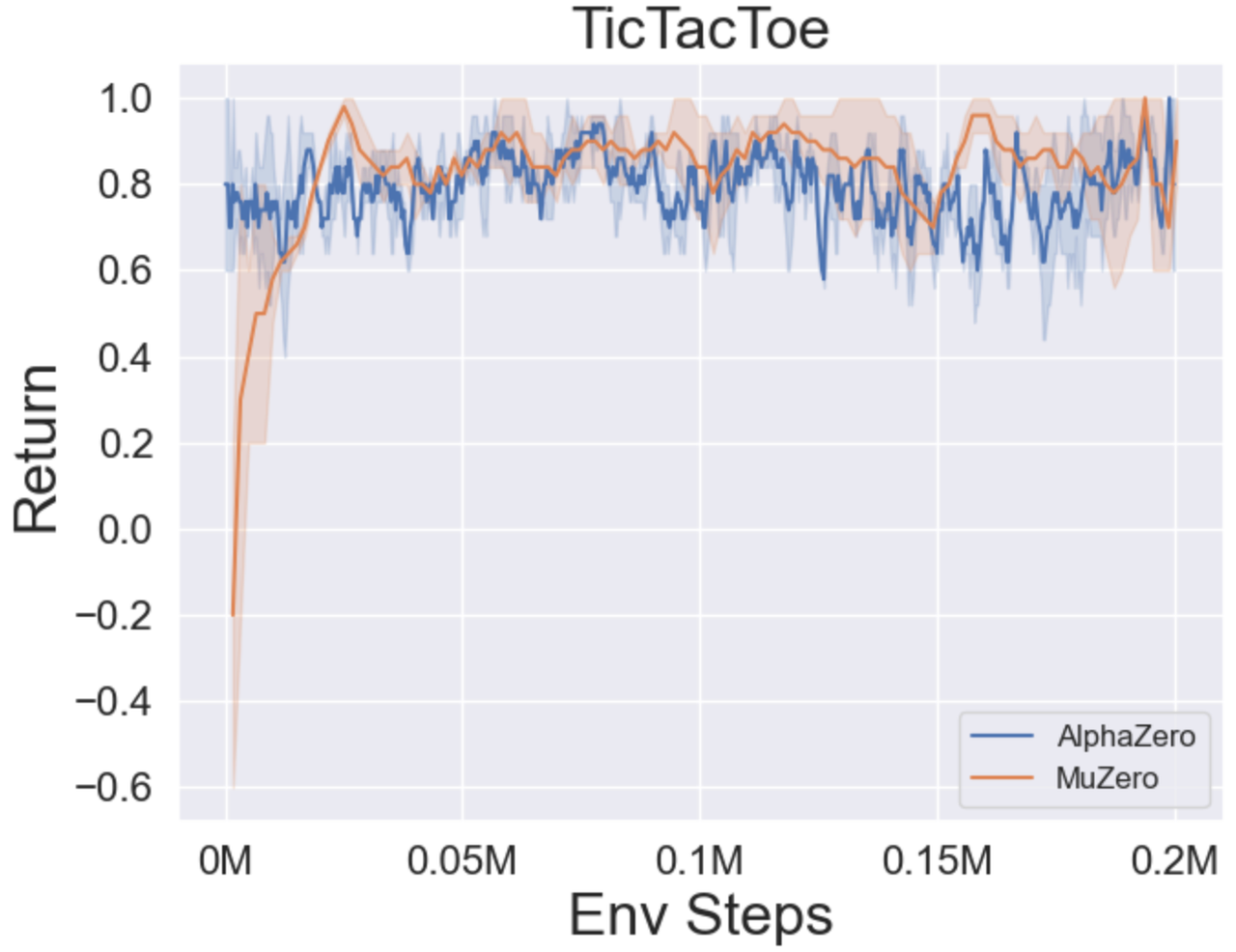
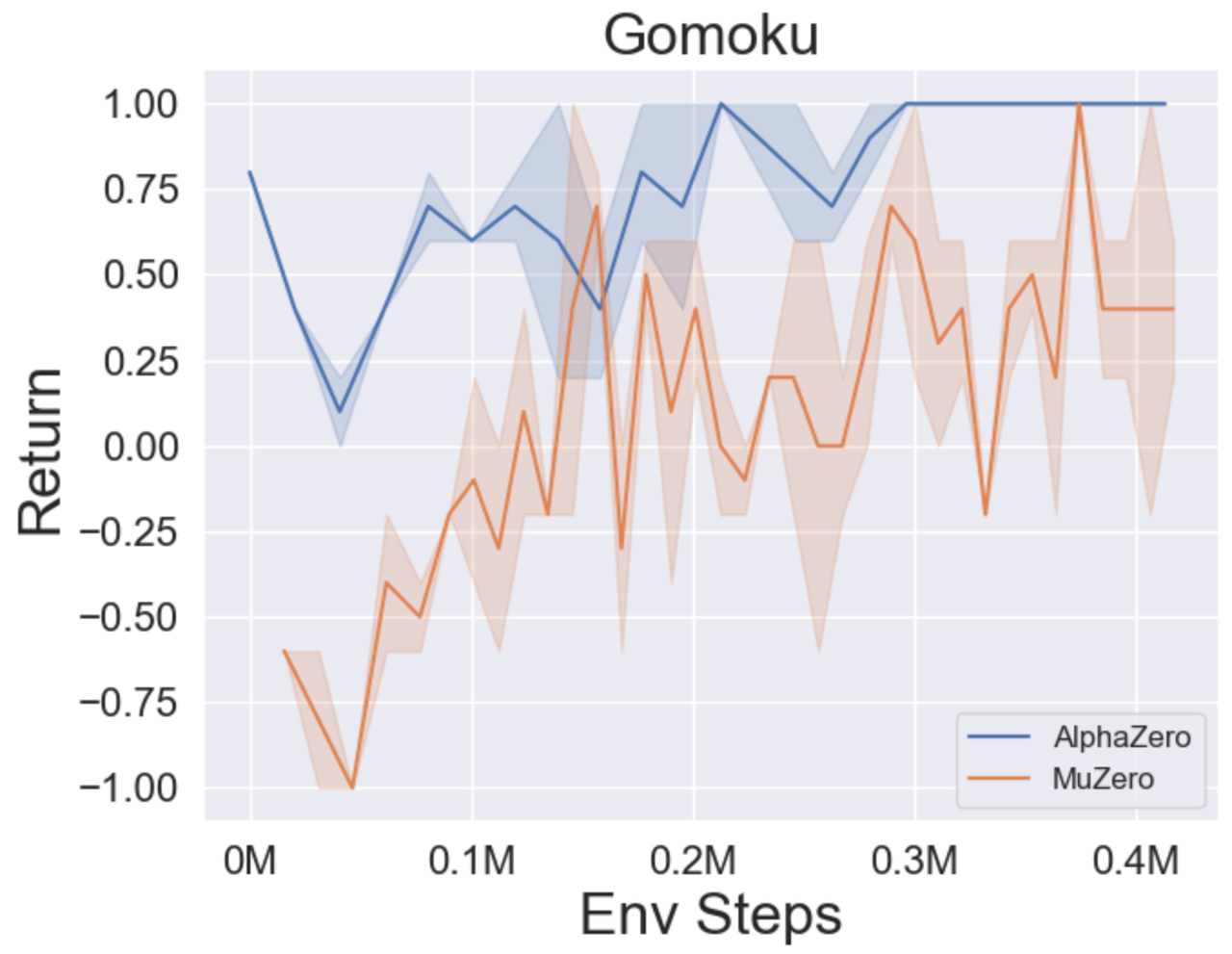
- A continuación se presentan los resultados de referencia de Alphazero y Muzero en tres juegos de mesa: Tictactoe, Connect4, Gomoku.
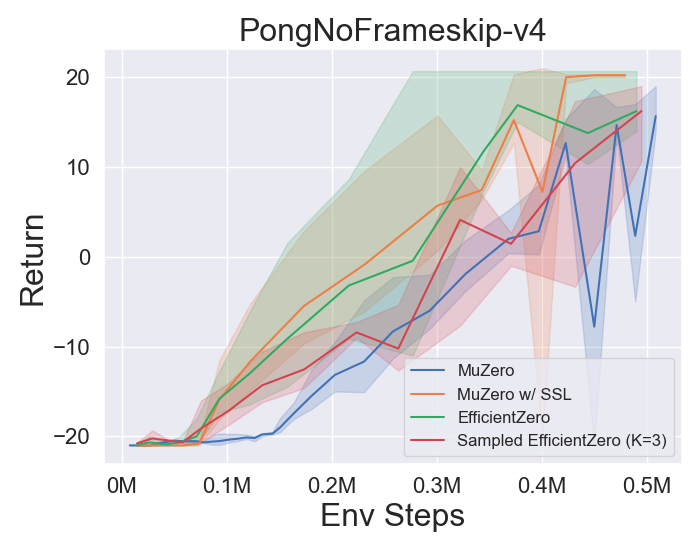
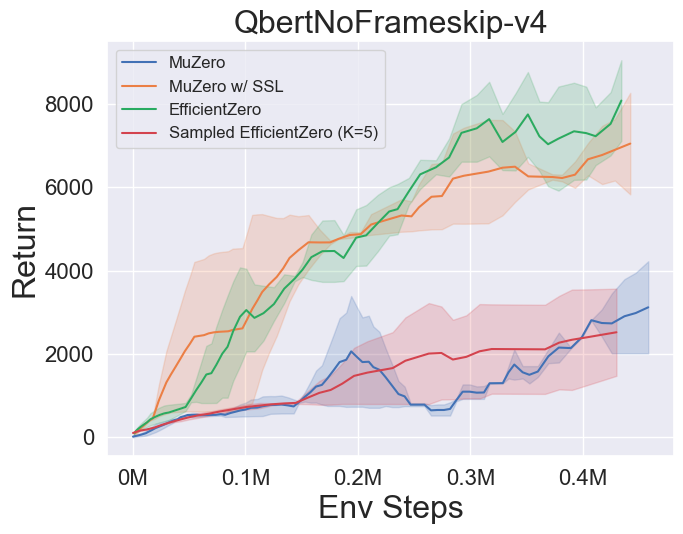
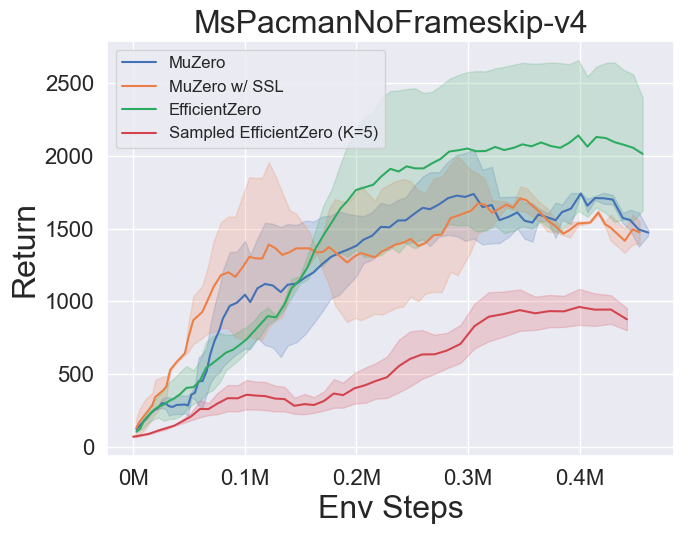
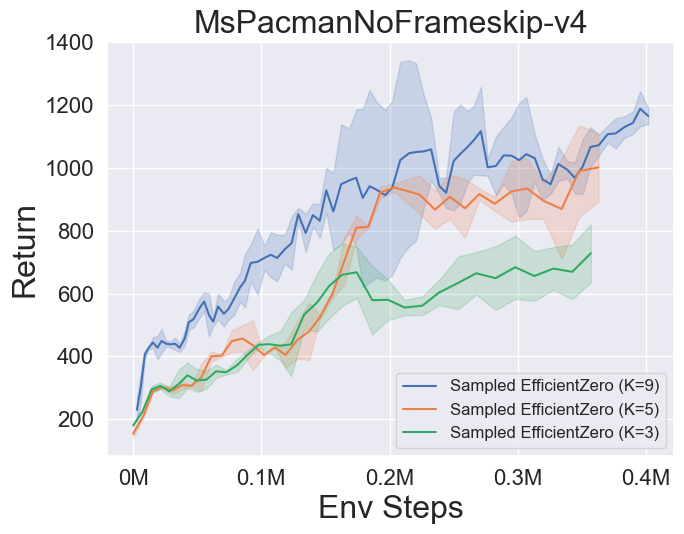
- A continuación se presentan los resultados de referencia de Múzero, MuZero con SSL, eficientezero y muestreó a EfficientZero en tres juegos espaciales de acción discretos en Atari.
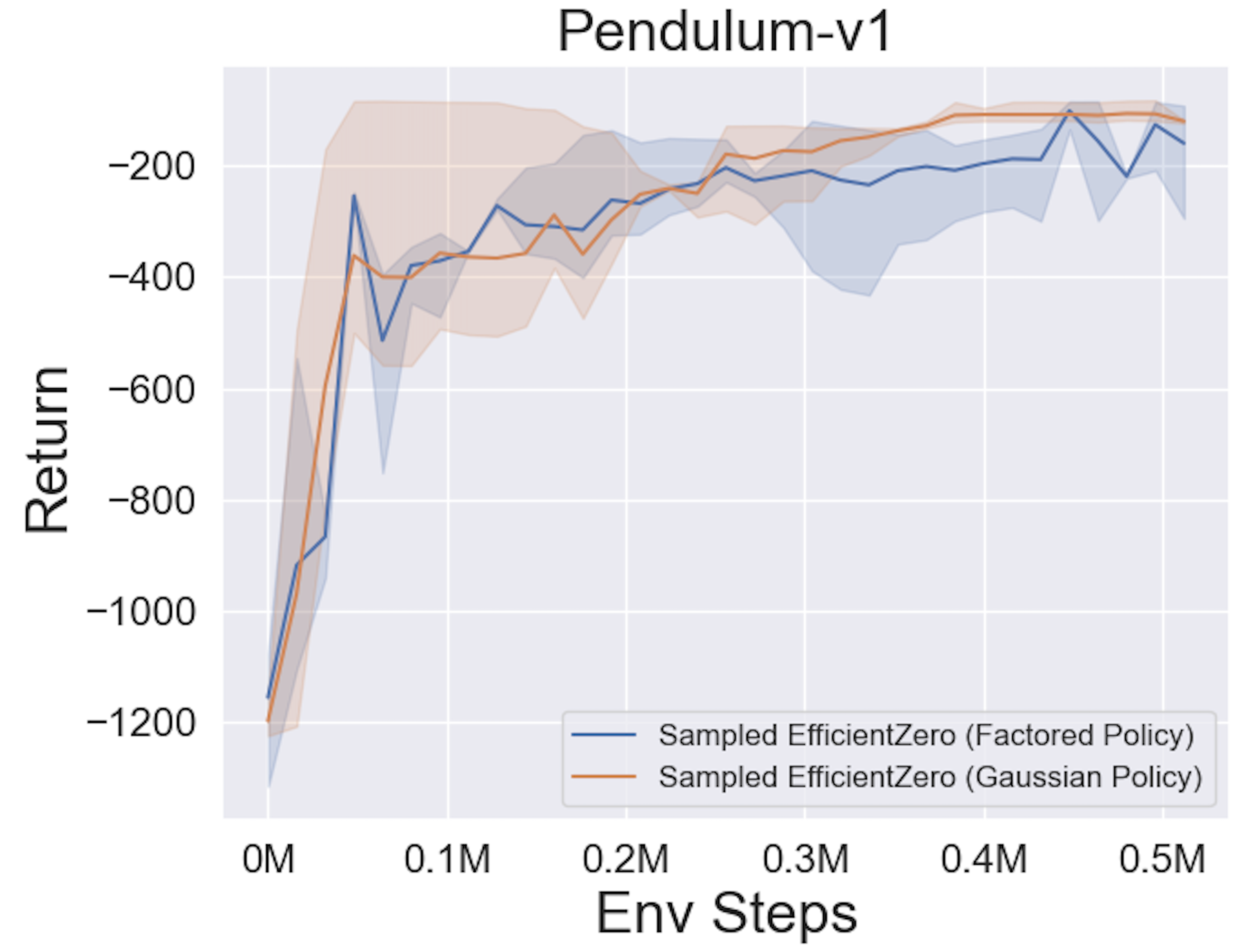
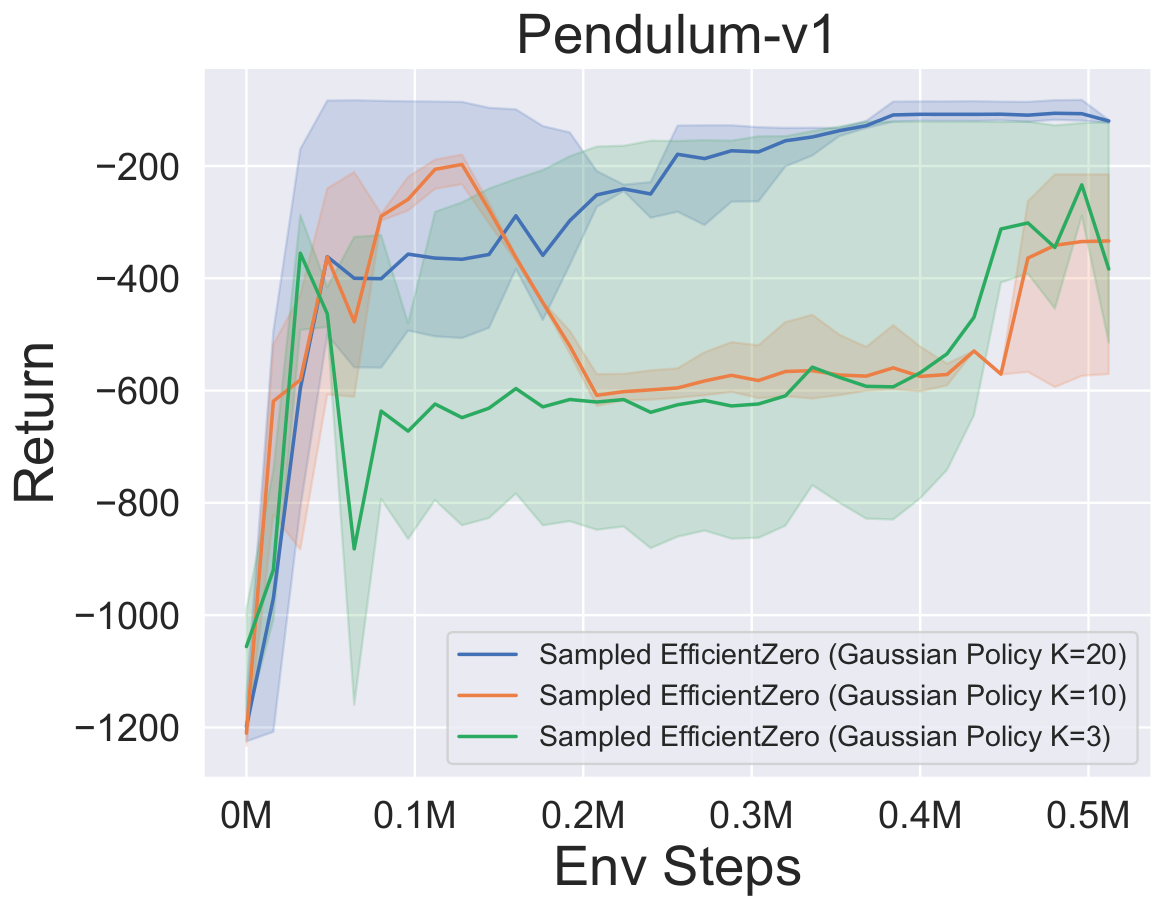
- A continuación se presentan los resultados de referencia de la muestra de política eficiente muestreada con una representación de política
Factored/Gaussian en tres juegos clásicos de espacios de acción continua: Pendulum-V1, Lunarlandercontinuous-V2, Bipedalwalker-V3 y dos Juegos Espaciales de Acción Continua Mujoco: Hopper-V3, Walker2D-V3.
"Política factorizada" indica que el agente aprende una red de políticas que genera una distribución categórica. Después de la discretización manual, las dimensiones del espacio de acción para los cinco entornos son 11, 49 (7^2), 256 (4^4), 64 (4^3) y 4096 (4^6), respectivamente. Por otro lado, la "política gaussiana" se refiere al agente que aprende una red de políticas que genera directamente los parámetros (MU y Sigma) para una distribución gaussiana.
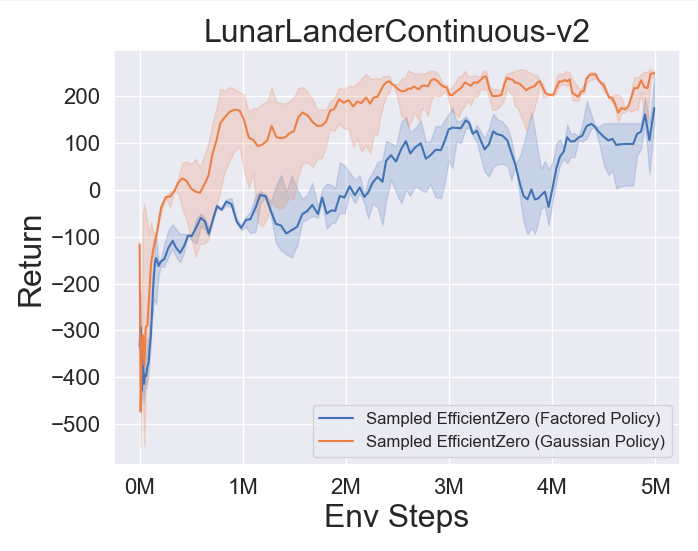
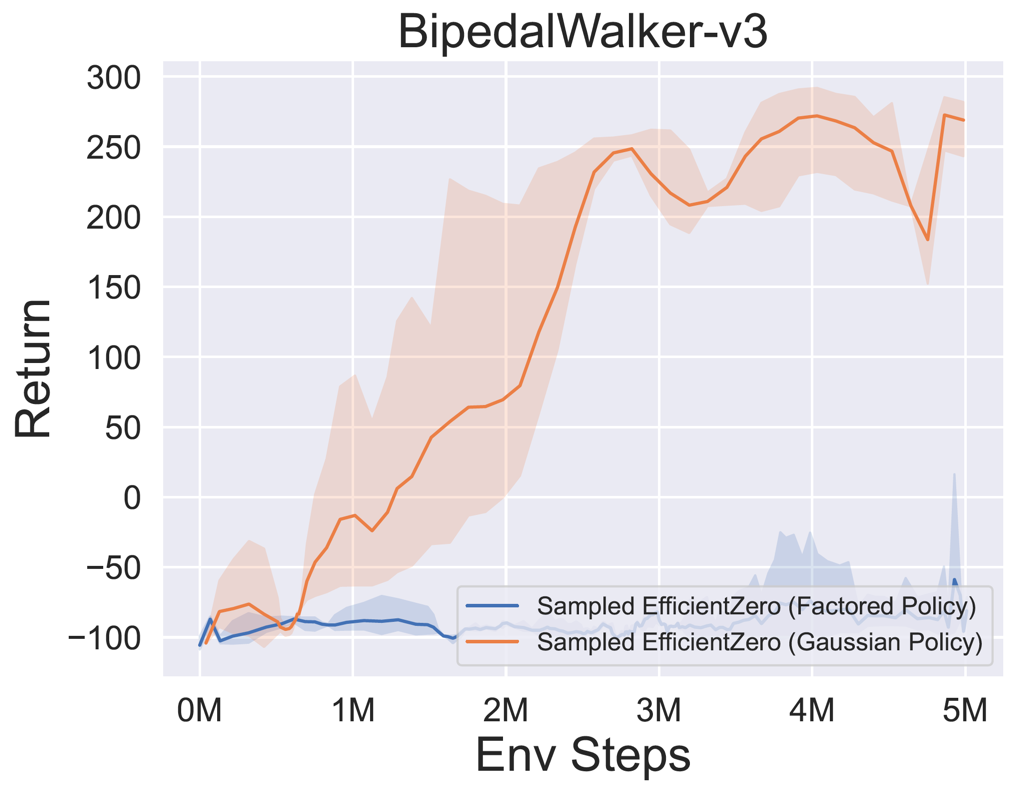
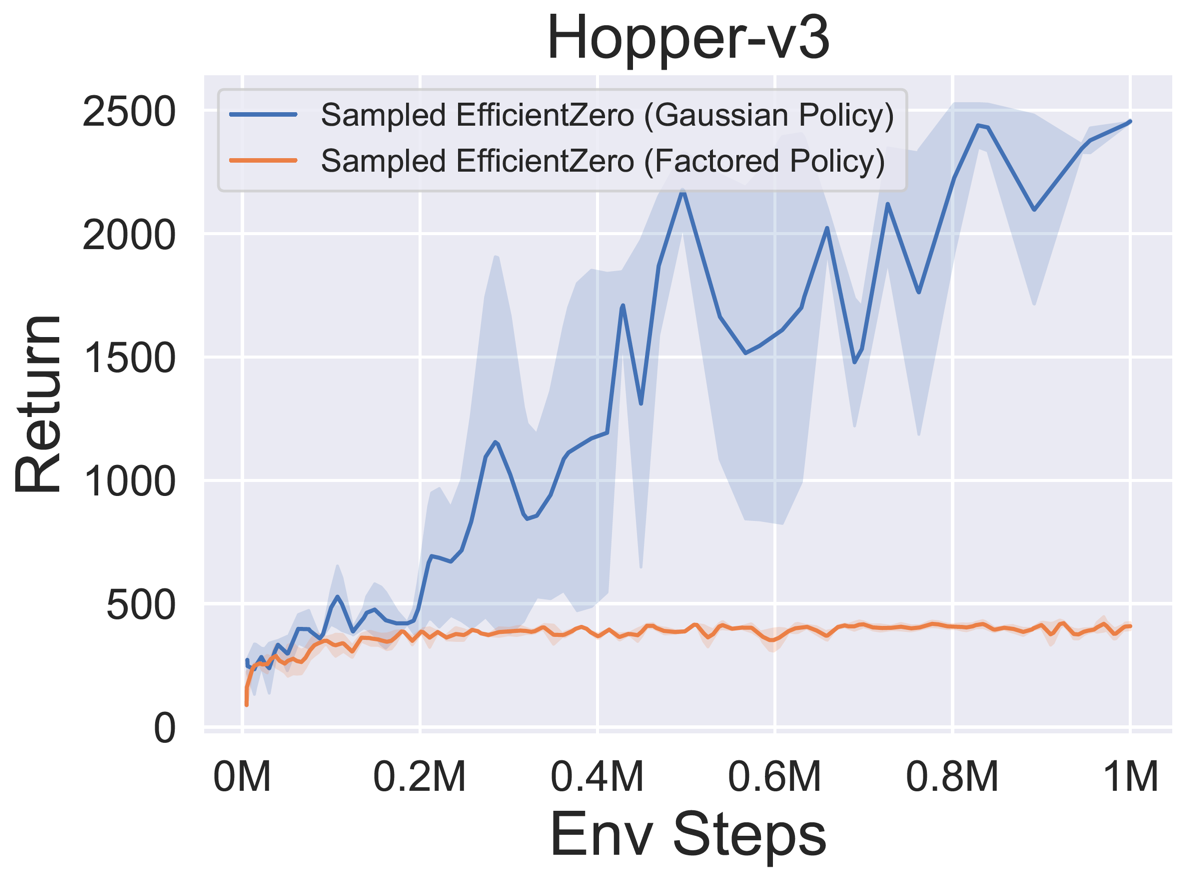
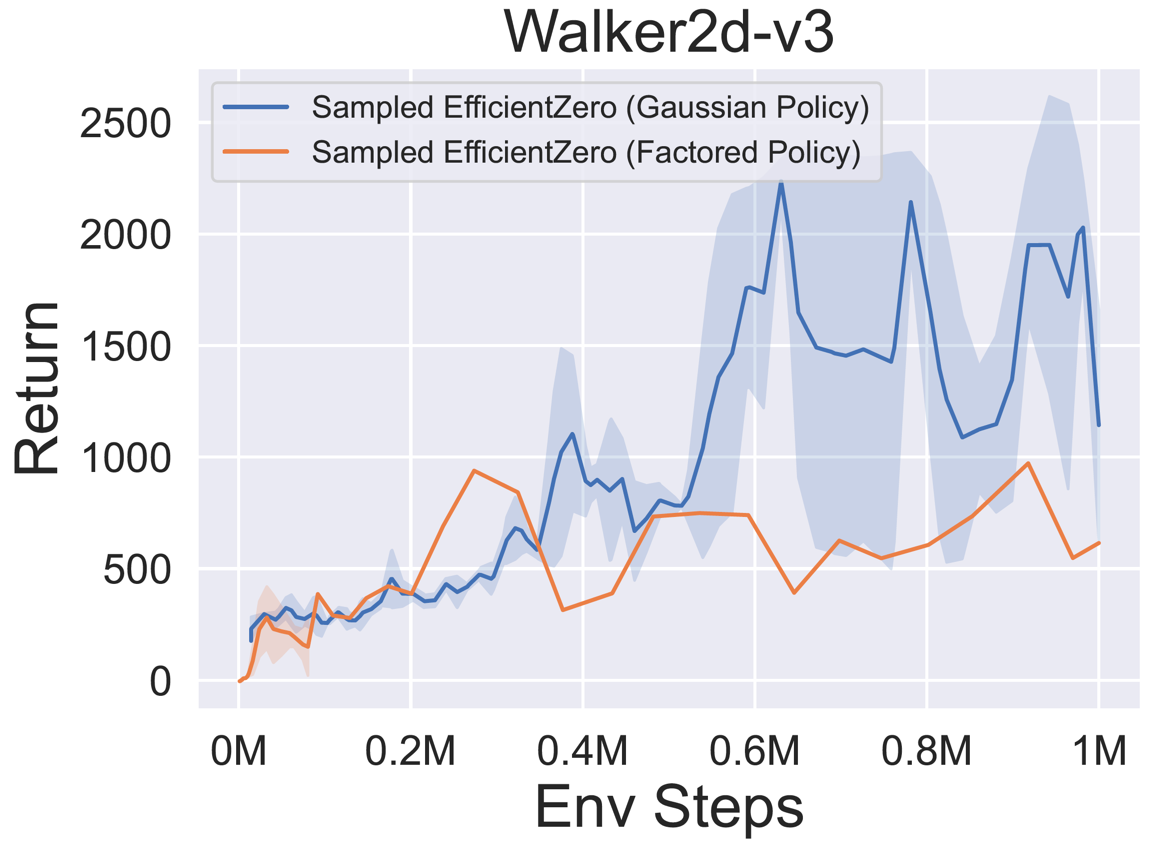
- A continuación se presentan los resultados de referencia de GumbelmuZero y Muzero (bajo un costo de simulación diferente) en cuatro entornos: Pongnoframeskip-V4, Mspacmannoframeskip-V4, Gomoku y LunarlanderContinuous-V2.
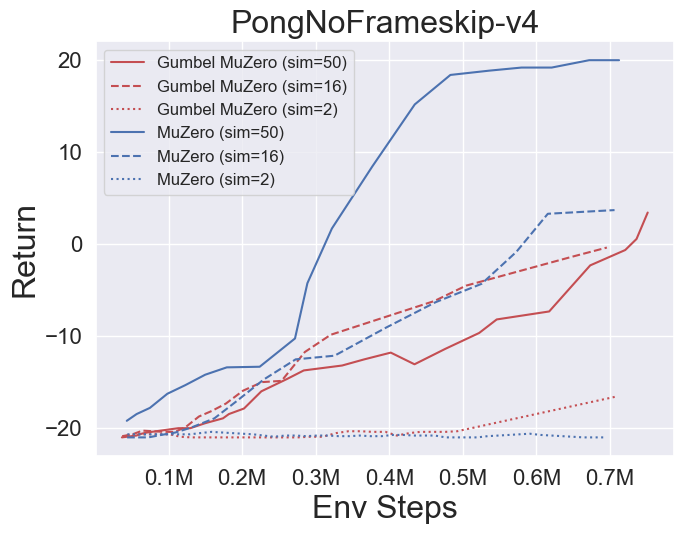
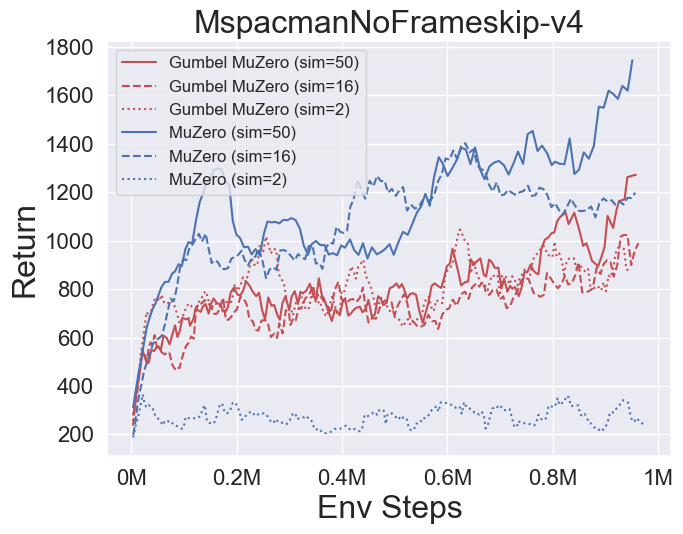
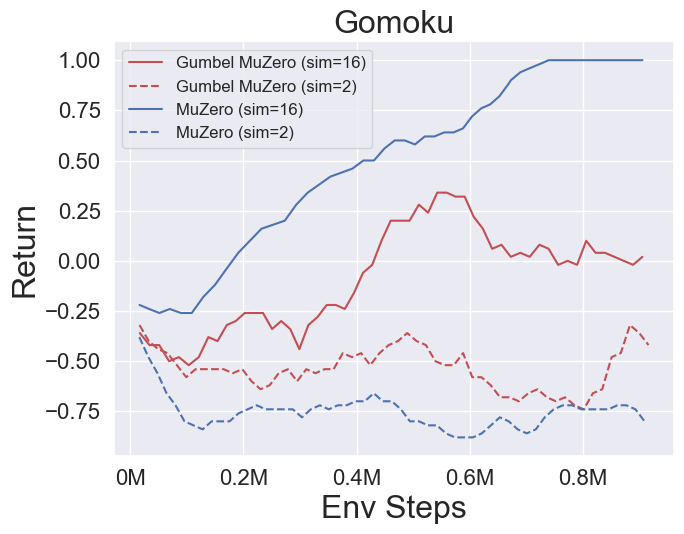
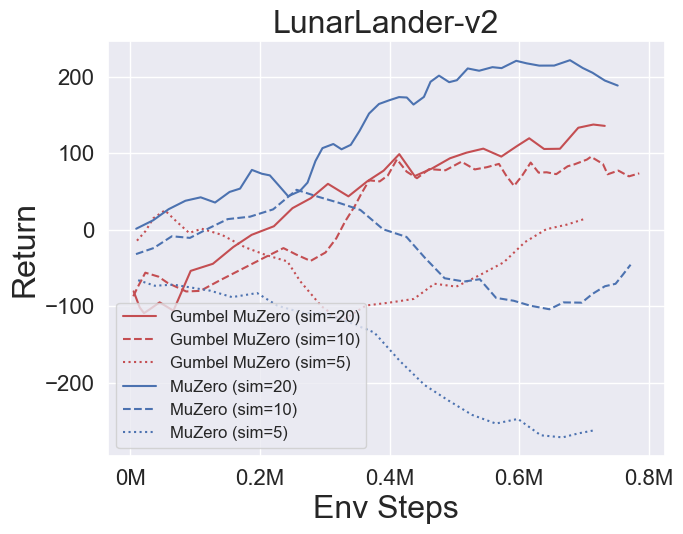
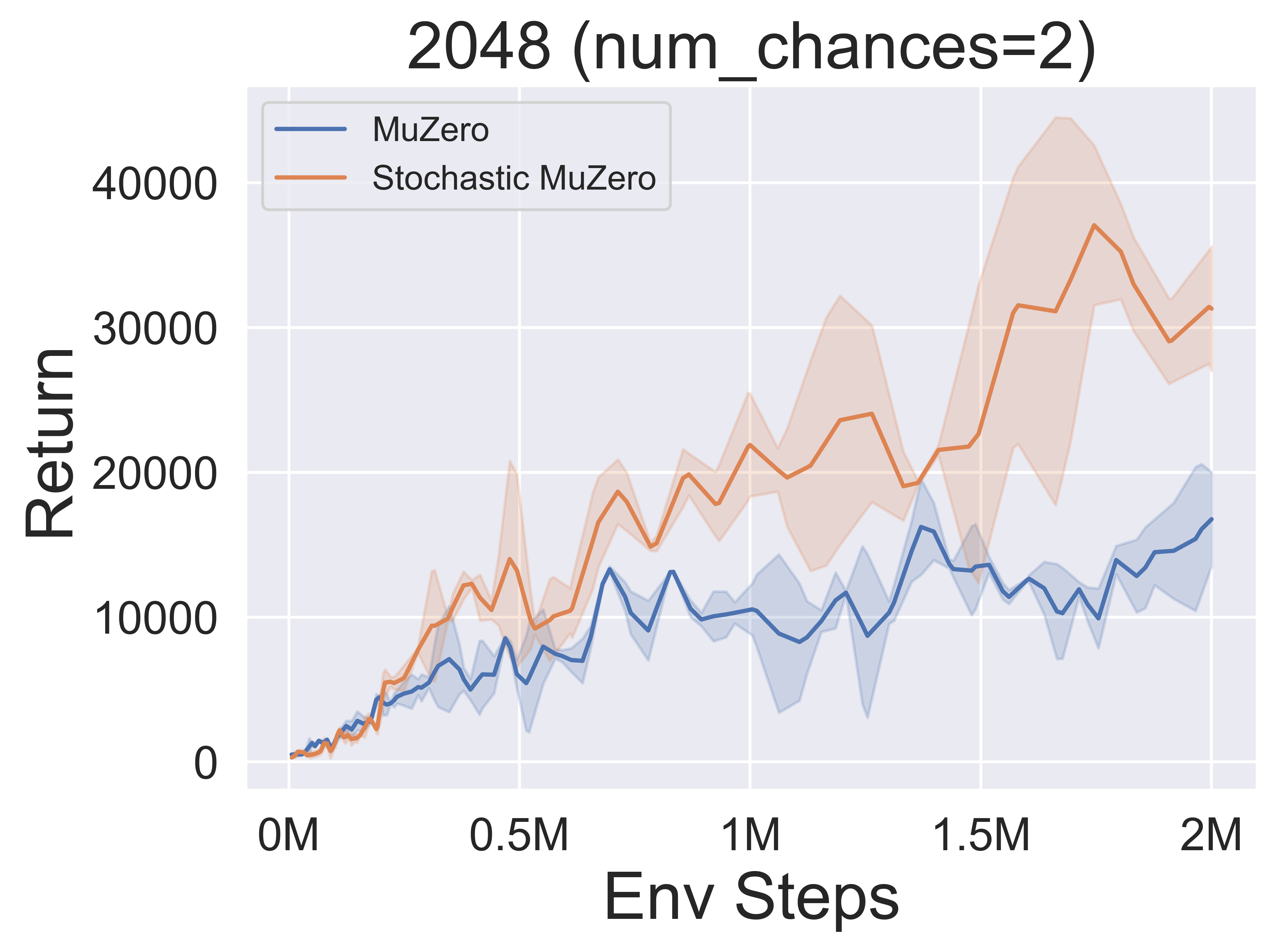
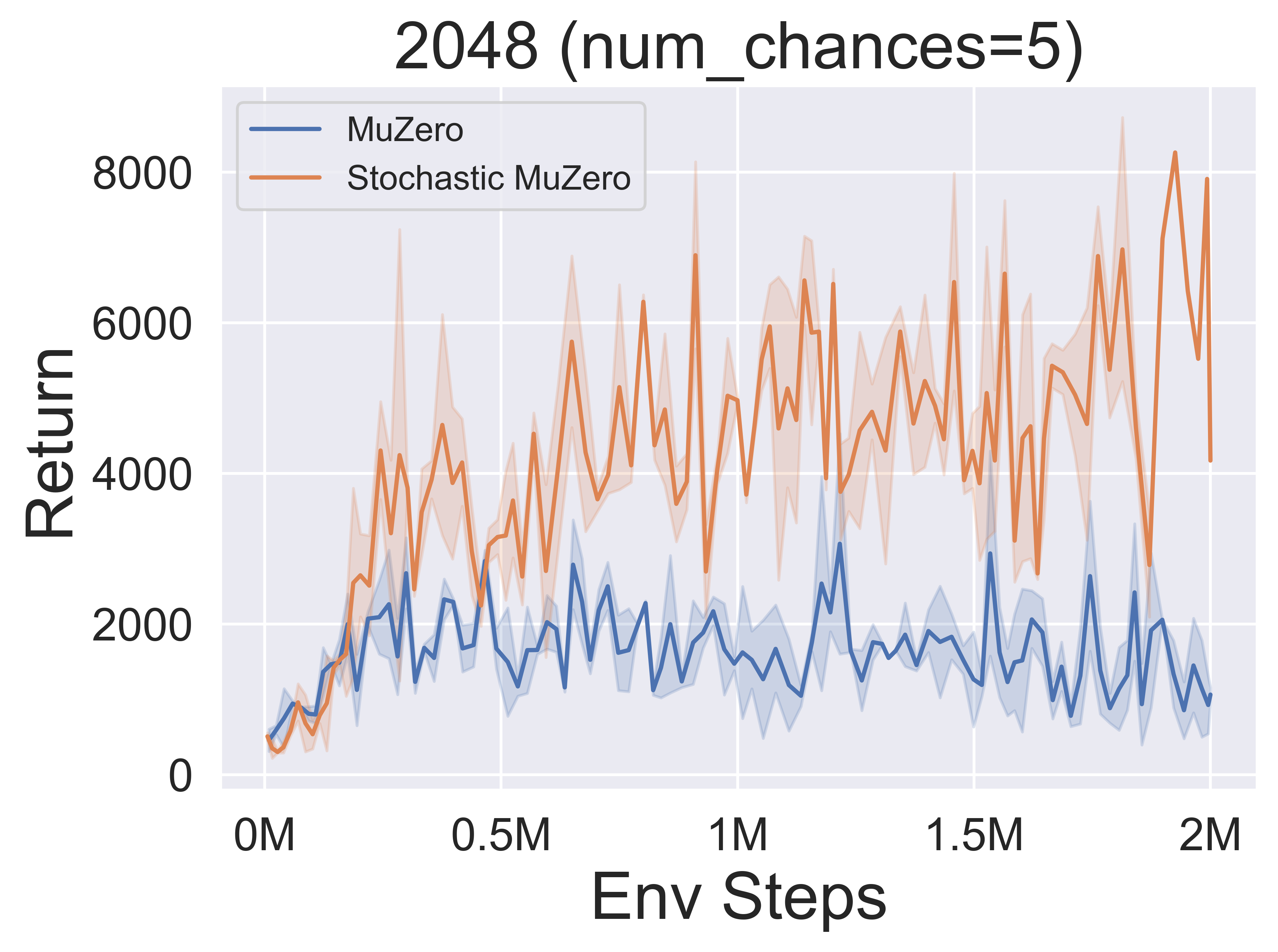
- A continuación se presentan los resultados de referencia de StocasticMuZero y Muzero en un entorno 2048 con diferentes niveles de azar (num_chances = 2 y 5).
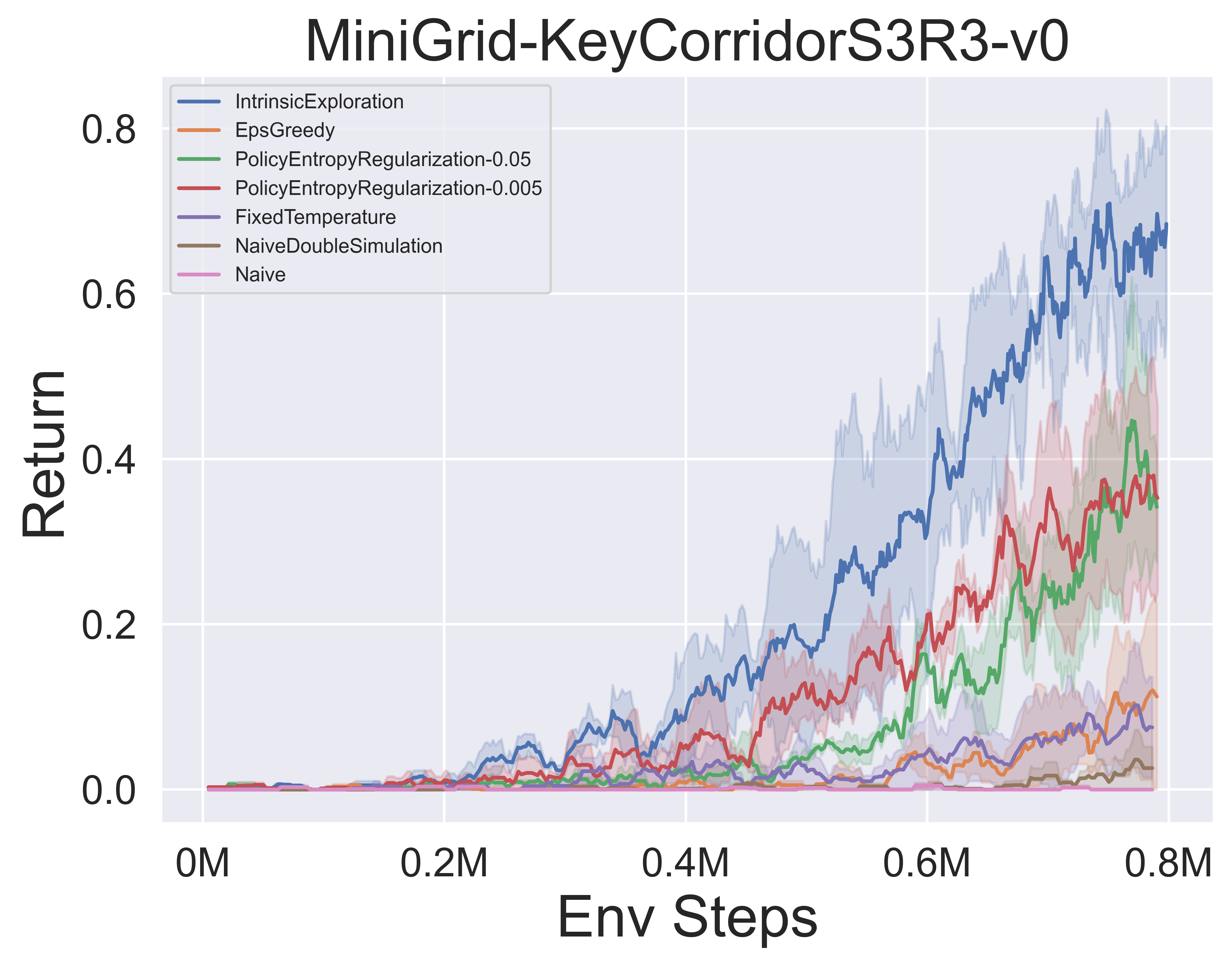
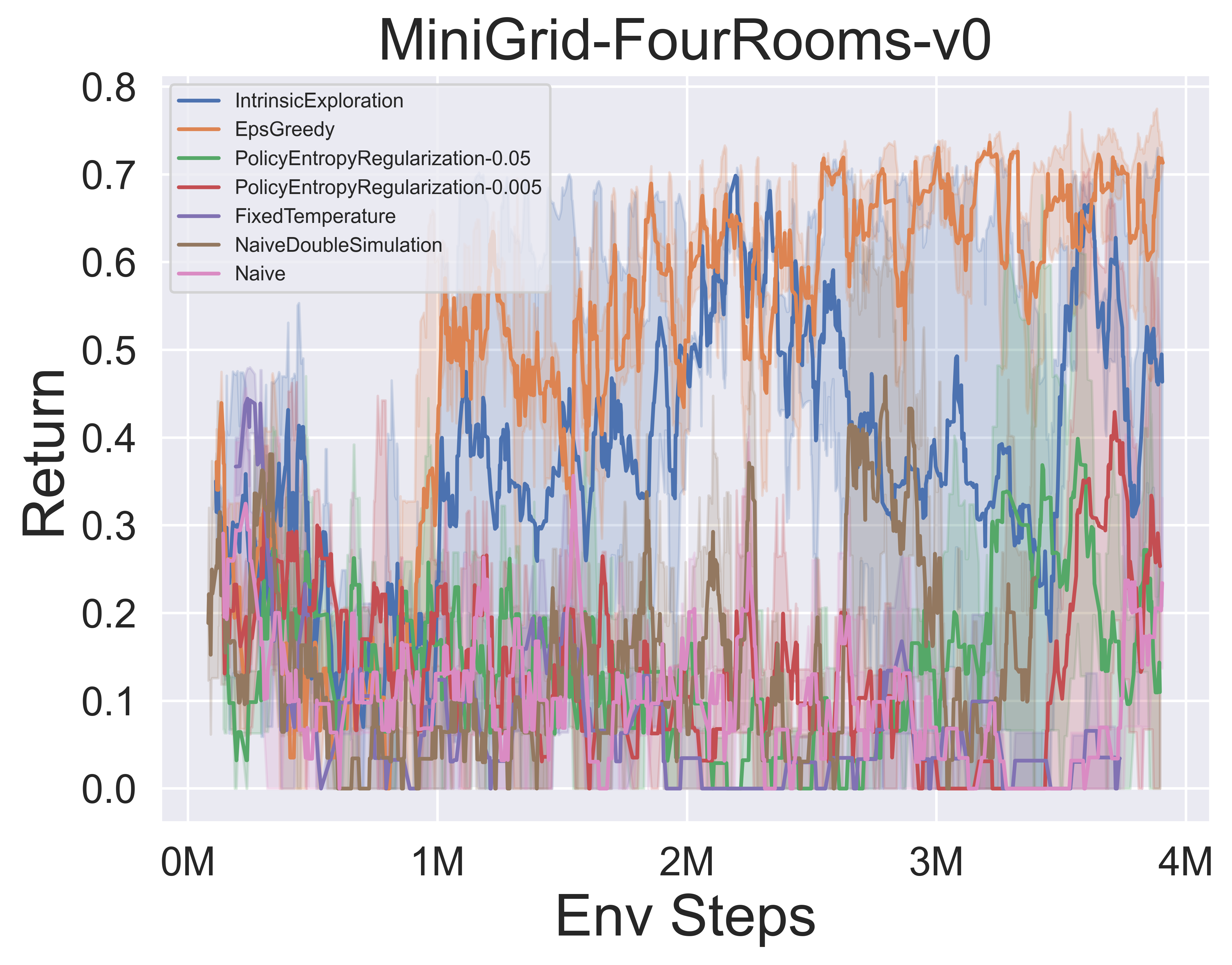
- A continuación se muestran los resultados de referencia de varios mecanismos de exploración de MCTS de MuZero con SSL en el entorno minigrid.
Notas impresionantes de mcts
Notas de papel
Las siguientes son las notas de papel detalladas (en chino) de los algoritmos anteriores:
Haga clic para colapsar
- Alphazero
- Muzero
- Eficientezero
- Muestreado
- Gumbelmumero
- Estocástico
- Titular de notación
También puede consultar la columna Zhihu relevante (en chino): análisis en profundidad de las teorías y aplicaciones de Frontier MCTS+RL.
Algo. Descripción general
Los siguientes son los diagramas principales MCTS de la descripción general de los algoritmos anteriores:
Haga clic para expandir
- MCTS
- Alphazero
- Muzero
- Eficientezero
- Muestreado
- Gumbelmumero
- Estocástico
Papeles impresionantes-mcts
Aquí hay una colección de trabajos de investigación sobre la búsqueda de árboles de Monte Carlo . Esta sección se actualizará continuamente para rastrear la frontera de MCTS.
Documentos clave
Haga clic para expandir
Serie implementada de Lightzero
- 2018 Science Alphazero: un algoritmo de aprendizaje de refuerzo general que domina el ajedrez, el shogi y pasan por sí mismo
- 2019 Muzero: Mastering Atari, Go, Chess and Shogi planificando con un modelo aprendido
- 2021 eficienteZero: dominar los juegos de Atari con datos limitados
- 2021 Muzero muestreado: aprendizaje y planificación en espacios de acción complejos
- 2022 Muzero estocástico: planificación en entornos estocásticos con un modelo aprendido
- 2022 Gumbel Múzero: Mejora de políticas mediante la planificación con Gumbel
Serie Alphago
- 2015 Nature Alphago Masando el juego de Go With Deep Neural Networks and Tree Search
- 2017 Nature Alphago Zero Mastering the Game of Go sin conocimiento humano
- 2019 Elf Opengo: un análisis y una reimplementación abierta de Alphazero
- 2023 Estudiante de juegos: un algoritmo de aprendizaje unificado para juegos de información perfectos e imperfectos
Serie Múzero
- 2022 Aprendizaje de refuerzo en línea y fuera de línea mediante la planificación con un modelo aprendido
- 2021 Modelos cuantizados vectoriales para la planificación
- 2021 muesli: combinación de mejoras en la optimización de políticas.
Análisis de MCTS
- 2020 Búsqueda de árboles de Monte-Carlo como optimización de políticas regularizada
- 2021 modelos y valores autoconsistentes
- 2022 Políticas adversas superan a los niveles profesionales AIS AIS
- 2022 PNAS Adquisición del conocimiento del ajedrez en Alphazero.
Aplicación MCTS
- 2023 Simbólico Física: Descubrimiento de ecuaciones de gobierno a través de la búsqueda de árboles de Monte Carlo
- 2022 Naturaleza Descubriendo algoritmos de multiplicación de matriz más rápido con aprendizaje de refuerzo
- 2022 Muzero con autocompetición para el control de tarifas en la compresión de video VP9
- 2021 DoUZero: Dominar a Doudizhu con un aprendizaje de refuerzo profundo
- 2019 Combinación de planificación y aprendizaje de refuerzo profundo en la toma de decisiones tácticas para conducir autónomo
Otros documentos
Haga clic para expandir
ICML
- Mejora de políticas seguras escalables a través de Monte Carlo Tree Search 2023
- Alberto Castellini, Federico Bianchi, Edoardo Zorzi, Thiago D. Simão, Alessandro Farinelli, Matthijs TJ Spaan
- Clave: Mejora de políticas seguras en línea utilizando una estrategia basada en MCTS, mejora de políticas seguras con arranque de línea de base
- Expenv: Gridworld y Sysadmin
- Aprendizaje eficiente para Alphazero a través de la consistencia de la ruta 2022
- Dengwei Zhao, Shikui Tu, Lei Xu
- Clave: Cantidad limitada de autopuestas, optimización de consistencia de ruta (PC)
- Expenv: Go, Othello, Gomoku
- Visualizando los modelos Muzero 2021
- Joery A. de Vries, Ken S. Voskuil, Thomas M. Moerland, Aske Plaat
- Clave: Visualización del modelo de dinámica equivalente de valor, las trayectorias de acción divergen, dos técnicas de regularización
- Expenv: Cartpole y Mountaincar.
- Regularización convexa en Monte-Carlo Tree Search 2021
- Tuan presa, Carlo d'Eramo, Jan Peters, Joni Pajarinen
- Clave: operadores de respaldo de regularización de entropía, análisis de arrepentimiento, Tsallis Etropy,
- Expenv: árbol sintético, Atari
- Información del árbol de filtro de partículas: un algoritmo en línea para POMDPS con recompensas basadas en creencias en dominios continuos 2020
- Johannes Fischer, Ömer Sahin Tas
- Clave: POMDP continuo, árbol de filtro de partículas, conformación de recompensa basada en información, recopilación de información.
- Expenv: Pomdps.jl Framework
- Código
- Retro*: Planificación retrosintética de aprendizaje con una guía neural A* Search 2020
- Binghong Chen, Chengtao Li, Hanjun Dai, Le Song
- Clave: Planificación retrosintética química, algoritmo similar a un*a base de neuros, Andor Tree
- Expenv: conjuntos de datos de USPTO
- Código
ICLR
- El marco de equivalencia de actualización para la planificación del tiempo de decisión 2024
- Samuel Sokota, Gabriele Farina, David J Wu, Hengyuan Hu, Kevin A. Wang, J Zico Kolter, Noam Brown
- Clave: juegos de información imperfecta, búsqueda, planificación en tiempo de decisión, equivalencia de actualización
- Expenv: Hanabi, 3x3 abrupto hexadecimal y phantom tic-tac-toe
- Aprendizaje eficiente de refuerzo de múltiples agentes por planificación 2024
- Qihan Liu, Jianing Ye, Xiaoteng MA, Jun Yang, Bin Liang, Chongjie Zhang
- Clave: aprendizaje de refuerzo de múltiples agentes, planificación, MCT de múltiples agentes
- Expenv: SMAC, Lunarlander, Mujoco y Google Research Football
- Conviértete en un jugador competente con datos limitados a través de la vista de videos puros 2023
- Weirui Ye, Yunsheng Zhang, Pieter Abbeel, Yang Gao
- Clave: Prerreinamiento de videos sin acciones, objetivo de consistencia del ciclo inverso (FICC) basado en la cuantización del vector, la fase de pre-entrenamiento, la fase de ajuste fino.
- Expenv: Atari
- Autocompetición basada en políticas para problemas de planificación 2023
- Jonathan Pirnay, Quirin Göttl, Jakob Burger, Dominik Gerhard Grimm
- Clave: autocompetición, encuentre trayectorias fuertes al planificar contra posibles estrategias de su yo pasado.
- Expenv: problema de vendedor ambulante y el problema de programación de la tienda de empleo.
- Explicando modelos de gráficos temporales a través de un marco explorador-navegante 2023
- Wenwen Xia, Mincai Lai, Caihua Shan, Yao Zhang, Xinnan Dai, Xiang Li, Dongsheng Li
- Clave: Explicador de GNN temporal, un explorador para encontrar los subconjuntos de eventos con MCTS, un navegador que aprende las correlaciones entre los eventos y ayuda a reducir el espacio de búsqueda.
- Expenv: Wikipedia y Reddit, conjuntos de datos sintéticos
- Speedyzero: dominar Atari con datos limitados y tiempo 2023
- Yixuan Mei, Jiaxuan Gao, Weirui Ye, Shaohuai Liu, Yang Gao, Yi Wu
- Clave: sistema RL distribuido, actualización prioritaria, lars recortado
- Expenv: Atari
- Optimización eficiente de políticas fuera de línea con un modelo aprendido 2023
- Zichen Liu, Siyi Li, Wee Sun Lee, Shuicheng Yan, Zhongwen Xu
- Clave: algoritmo basado en modelos de un solo paso regularmente para fuera de línea-RL
- Expenv: Atari, Bsuite
- Código
- Habilitando objetivos de traducción arbitrarios con búsqueda de árbol adaptativo 2022
- Wang Ling, Wojciech Stokowiec, Domenic Donato, Chris Dyer, Lei Yu, Laurent Sartran, Austin Matthews
- Clave: búsqueda de árbol adaptativo, modelos de traducción, modelos autorregresivos,
- Expenv: tareas chinas -inglés y pashto -inglés de WMT2020, alemán - inglés de WMT2014
- ¿Qué pasa con el aprendizaje profundo en la búsqueda de árboles de la optimización combinatoria 2022
- Maximili1an Böther, Otto Kißig, Martin Taraz, Sarel Cohen, Karen Seidel, Tobias Friedrich
- Clave: optimización combinatoria, conjunto de referencia de código abierto para el problema de conjunto independiente máximo de NP-Hard, un análisis en profundidad del popular algoritmo de búsqueda de árboles guiados, compare las implementaciones de búsqueda de árboles con otros solucionadores
- Ejecución: conjunto máximo independiente de NP-Hard.
- Código
- Planificación y aprendizaje de Monte-Carlo con estimaciones de valor de acción del idioma 2021
- Youngsoo Jang, Seokin Seo, Jongmin Lee, Kee-Eung Kim
- Clave: Búsqueda de árboles de Monte-Carlo con exploración de lenguaje, estimaciones de valor de lenguaje localmente optimista.
- Expenv: juegos de ficción interactiva (IF)
- Práctica búsqueda de árboles de Monte-Carlo en masa paralelo aplicado al diseño molecular 2021
- Xiufeng Yang, Tanuj Kr Aasawat, Kazuki Yoshizoe
- Clave: Búsqueda de árboles de Monte-Carlo en masivo paralelo, diseño molecular, búsqueda paralela impulsada por el hash,
- Ejecución: coeficiente de partición de octanol-agua (LOGP) penalizado por la accesibilidad sintética (SA) y el puntaje de penalización de anillo grande.
- Observe lo no observado: un enfoque simple para paralelizar a Monte Carlo Tree Search 2020
- Anji Liu, JiAnshu Chen, Mingze Yu, Yu Zhai, Xuewen Zhou, Ji Liu
- Clave: la búsqueda paralela de árbol de Monte-Carlo, divide el árbol en sub-árboles de manera eficiente, compare la relación de observación de cada procesador.
- Expenv: comparación de aceleración y rendimiento en el juego de Joy-City, regreso promedio de episodios en el juego Atari
- Código
- Aprender a planificar en altas dimensiones a través de árboles de exploración neuronal-explotación 2020
- Binghong Chen, Bo Dai, Qinjie Lin, Guo Ye, Han Liu, Le Song
- Clave: Algoritmo de planificación de meta ruta, explota una nueva arquitectura neuronal que puede aprender direcciones prometedoras de búsqueda de estructuras problemáticas.
- Expenv: un espacio de trabajo en 2D con un robot de 2 DOF (grados de libertad), un robot de 3 dof y un robot de 5 dof serpiente
Neuros
- Lightzero: un punto de referencia unificado para la búsqueda de árboles de Monte Carlo en escenarios de decisión secuencial general 2023
- Yazhe Niu, Yuan PU, Zhenjie Yang, Xueyan Li, Tong Zhou, Jiyuan Ren, Shuai Hu, Hongsheng Li, Yu Liu
- Clave: El primer punto de referencia unificado para implementar MCTS/Muzero en escenarios de decisión secuencial general.
- Expenv: ClassicControl, Box2d, Atari, Mujoco, Gobigger, Minigrid, Tictactoe, ConnectFour, Gomoku, 2048, etc.
- Modelos de idiomas grandes como conocimiento común para la planificación de tareas a gran escala 2023
- Zirui Zhao, Wee Sun Lee, David Hsu
- Clave: World Model (LLM) y la política inducida por LLM se pueden combinar en MCTS, para ampliar la planificación de tareas.
- Expenv: multiplicación, planificación de viajes, reordenamiento de objetos
- Búsqueda de árboles de Monte Carlo con Boltzmann Exploration 2023
- Michael Painter, Mohamed Bioumy, Nick Hawes, Bruno Lacerda
- Clave: la exploración de Boltzmann con MCTS, las acciones óptimas para el objetivo de entropía máxima no se corresponden necesariamente a acciones óptimas para el objetivo original, dos algoritmos mejorados.
- Expenv: el ambiente de lago congelado, el problema de navegación, ir
- Consistencia de ruta ponderada generalizada para dominar los Juegos Atari 2023
- Dengwei Zhao, Shikui Tu, Lei Xu
- Clave: consistencia de la ruta ponderada generalizada, un mecanismo de ponderación.
- Expenv: Atari
- Acelerar la búsqueda de árboles de Monte Carlo con probabilidad Estado de árbol Abstracción 2023
- Yangqing Fu, Ming Sun, Buqing Nie, Yue Gao
- Clave: Probabilidad Estado del árbol Abstracción, transitividad y error de agregación vinculado
- Expenv: Atari, Cartpole, Lunarlander, Gomoku
- Pasando el tiempo de pensamiento sabiamente: acelerando MCT con expansiones virtuales 2022
- Weirui Ye, Pieter Abbeel, Yang Gao
- Clave: Comprobación de compensación versus performance, expansiones virtuales, pasar el tiempo de pensamiento de forma adaptativa.
- Expenv: Atari, 9x9 Go
- Planificación de muestras de aprendizaje de imitación eficiente 2022
- Zhao-Heng Yin, Weirui Ye, Qifeng Chen, Yang Gao
- Clave: clonación conductual, aprendizaje de imitación adversaria (AIL), RL basada en MCTS.
- Expenv: profunda suite de control
- Código
- Evaluación más allá del rendimiento de la tarea: analizar conceptos en Alphazero en Hex 2022
- Charles Lovering, Jessica Zosa Forde, George Konidaris, Ellie Pavlick, Michael L. Littman
- Clave: Representaciones internas de Alphazero, sondeo de modelos y pruebas de comportamiento, cómo se capturan estos conceptos en la red.
- Expenv: Hex
- ¿Son robustos a los agentes de Alphazero a las perturbaciones adversas? 2022
- Li-Cheng Lan, Huan Zhang, Ti-Rong Wu, Meng-Yu Tsai, I-Chen Wu, 4 Cho-Jui Hsieh
- Clave: estados adversos, primer ataque adversario contra Go AIS.
- Expenv: ir
- Descenso de árbol de Monte Carlo para optimización de cajas negras 2022
- Yauguang zhai, Sicun Gao
- Clave: optimización de caja negra, cómo integrar aún más el descenso basado en la muestra para una optimización más rápida.
- Expenv: funciones sintéticas para la optimización no lineal, problemas de aprendizaje de refuerzo en entornos de locomoción de Mujoco y problemas de optimización en la búsqueda de arquitectura neural (NAS).
- Selección variable basada en la búsqueda de árboles de Monte Carlo para optimización bayesiana de alta dimensión 2022
- LEI CANCIÓN ∗, KE XUE ∗, Xiaobin Huang, Chao Qian
- Clave: un subespacio de baja dimensión a través de MCTS, se optimiza en el subespacio con cualquier algoritmo de optimización bayesiana.
- Expenv: problemas de bench y locomoción de Mujoco
- Búsqueda de árbol de Monte Carlo con abstracciones de estado de refinación iterativamente 2021
- Samuel Sokota, Caleb HO, Zaheen Ahmad, J. Zico Kolter
- Clave: entornos estocásticos, ampliación progresiva, refinación de abstracción
- Expenv: Blackjack, trampa, cinco por cinco Go.
- Planificación sinóptica profunda de Monte Carlo en el ajedrez ciego de reconocimiento 2021
- Gregory Clark
- Clave: información imperfecta, estado de creencia con un filtro de partículas no ponderado, una nueva abstracción estocástica de estados de información.
- Expenv: ajedrez ciego de reconocimiento
- Poly-hoot: planificación de Monte-Carlo en MDP de espacio continuo con análisis no asintótico 2020
- Weichao Mao, Kaiqing Zhang, Qiaomin Xie, Tamer Ba¸sar
- Clave: espacios continuos de acción estatal, optimización optimista jerárquica.
- Expenv: Cartpole, péndulo invertido, swing-up y lunarlander.
- Partición del espacio de búsqueda de aprendizaje para la optimización de la caja negra utilizando Monte Carlo Tree Search 2020
- Linnan Wang, Rodrigo Fonseca, Yuandong Tian
- Clave: aprende la partición del espacio de búsqueda utilizando algunas muestras, un límite de decisión no lineal y aprende un modelo local para elegir buenos candidatos.
- Expenv: tareas de locomoción de Mujoco, puntos de referencia a pequeña escala,
- Mezcle y coincida: un enfoque de búsqueda de árbol optimista para modelos de aprendizaje de las distribuciones de mezcla 2020
- Matthew Faw, Rajat Sen, Karthikeyan Shanmugam, Constantine Caramanis, Sanjay Shakkottai
- Clave: Problema de desplazamiento covariable, Mix & Match combina descenso de gradiente estocástico (SGD) con búsqueda optimista de árboles y reutilización del modelo (evolucionando modelos parcialmente entrenados con muestras de diferentes distribuciones de mezcla)
- Código
Otra conferencia o revista
- Aprendiendo a detener: Simulación dinámica Monte-Carlo Tree Search AAAI 2021.
- En Monte Carlo Tree Search and Reffure Learning Journal of Artificial Intelligence Research 2017.
- Búsqueda de arquitectura neuronal eficiente de muestra por acciones de aprendizaje para la búsqueda de árboles de Monte Carlo IEEE Transacciones en Análisis de patrones e Inteligencia Machine 2022.
Retroalimentación y contribución
Presentar un problema en GitHub
Abrir o participar en nuestro foro de discusión
Discuta en Lightzero Discord Server
Póngase en contacto con nuestro correo electrónico ([email protected])
Apreciamos todos los comentarios y contribuciones para mejorar Lightzero, tanto los algoritmos como los diseños de sistemas.
? Citación
@article{niu2024lightzero,
title={LightZero: A Unified Benchmark for Monte Carlo Tree Search in General Sequential Decision Scenarios},
author={Niu, Yazhe and Pu, Yuan and Yang, Zhenjie and Li, Xueyan and Zhou, Tong and Ren, Jiyuan and Hu, Shuai and Li, Hongsheng and Liu, Yu},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
@article{pu2024unizero,
title={UniZero: Generalized and Efficient Planning with Scalable Latent World Models},
author={Pu, Yuan and Niu, Yazhe and Ren, Jiyuan and Yang, Zhenjie and Li, Hongsheng and Liu, Yu},
journal={arXiv preprint arXiv:2406.10667},
year={2024}
}
@article{xuan2024rezero,
title={ReZero: Boosting MCTS-based Algorithms by Backward-view and Entire-buffer Reanalyze},
author={Xuan, Chunyu and Niu, Yazhe and Pu, Yuan and Hu, Shuai and Liu, Yu and Yang, Jing},
journal={arXiv preprint arXiv:2404.16364},
year={2024}
}? Expresiones de gratitud
Este proyecto se ha desarrollado parcialmente en base a los siguientes trabajos pioneros en repositorios de GitHub. Expresamos nuestra profunda gratitud por estos recursos fundamentales:
- https://github.com/opendilab/di-ingine
- https://github.com/deepmind/mctx
- https://github.com/yewr/eficientezero
- https://github.com/werner-duvaud/muzero-general
Nos gustaría extender nuestro agradecimiento especial a los siguientes colaboradores @Paparazz1, @karroyan, @nighood, @jayyoung0802, @timothijoe, @tutuhuss, @harryxuancy, @Puyuan1996, @hansbug por sus valiosas contribuciones y apoyo a esta biblioteca de algorithm.
Gracias a todos los que contribuyeron a este proyecto:
? ️ Licencia
Todo el código dentro de este repositorio está bajo la licencia APACHE 2.0.
(De vuelta a la cima)



