Periplus
v0.1.0-alpha.1
Periplus는 현재 알파에 있으며 생산 준비가되지 않습니다. 이 프로젝트는 활발한 개발 중이며 아직 생산 시스템에 사용하는 것이 권장되지 않습니다.
Periplus는 Meta의 벡터 유사성 검색 라이브러리 Faiss를 기반으로 구축 된 오픈 소스 인 메모리 벡터 데이터베이스 캐시입니다. 이 프로젝트는 "벡터 데이터베이스를위한 Redis"로 가장 잘 생각할 수 있습니다. 대형 벡터 컬렉션의 동적으로 업데이트 된 하위 집합을 메모리에 전적으로 저장하면서 쿼리 시간에 다른 노드와 상호 작용하지 않고 쿼리를 제공하도록 설계되었습니다. Periplus가 쿼리를 받으면 먼저 인덱스 내 거주지의 관련 부분이 있는지 여부를 평가합니다. 그렇다면 적절한 응답으로 쿼리를 해결합니다. 그렇지 않은 경우 캐시 미스를 반환하고 데이터베이스에서 데이터를 가져 오기 위해 쿼리를 남겨 둡니다. Periplus는 분리하여 기능하도록 설계되지 않았습니다. 대신, 그것은 영구 계층을 형성하는 별도의 벡터 데이터베이스에 대한 모듈 식 및 유연한 캐싱 레이어를 형성하기위한 것입니다. 이것의 목적은 처리량을 높이기 위해 낮은 대기 시간과 쉬운 수평 스케일링을 가능하게하는 것입니다. Periplus의 영감과 작동 방식에 대한 자세한 설명을 보려면 발표 블로그 : Periplus 소개 : 벡터 데이터베이스 캐싱에 대한 새로운 접근 방식을 읽을 수 있습니다.
Periplus는 캐시 관리의 기초로 반전 파일 인덱스 (IVF)를 사용합니다. 거꾸로 된 파일 색인 벡터 공간을 벡터 공간을 연속 셀로 분할하여 각 셀이 다른 중심보다 중심에 가까운 영역으로 정의되는 중심 벡터 세트에 의해 정의 된 연속 셀로 분할됩니다. 그런 다음 먼저 쿼리 벡터에서 중심 세트까지의 거리를 계산 한 다음 N_PROBE (검색 하이퍼 파라미터)에 의해 가장 가까운 중심에 의해 정의 된 셀 만 검색하여 쿼리가 해결됩니다. Periplus는 주어진 시간에 이들 셀의 서브 세트를 거주지에 유지하고 캐시가없는 것이 아닌 것을 거부하면서 해당 서브 세트와 관련된 쿼리 만 해결함으로써이를 활용합니다. Periplus는 한 번에 전체 IVF 셀을 부하 및 피하기 위해 인덱스의 무결성을 유지하고 표준 IVF 인덱스에 동등한 리콜 (캐시 히트)을 보장합니다. IVF 셀은 Periplus가 어떤 벡터가 어떤 셀을 차지하는지 추적하기 위해 유지 관리하는 벡터의 ID 목록과 함께 프록시를 통해 벡터 데이터베이스를 쿼리하여로드됩니다. 이러한 작업은 로드 , 검색 및 퇴거 명령을 사용하여 사용자가 호출 할 수 있습니다. 자세한 내용은 아래 Periplus 명령 섹션을 참조하십시오.
Periplus는 Docker 컨테이너로 실행되거나 소스에서 제작되어 실행 파일로 실행할 수 있습니다. 공식 바이너리는 현재 이용할 수 없습니다. Periplus를 컨테이너로 실행하는 것이 권장되는 접근 방식이지만 두 가지 모두 실행 가능한 옵션입니다.
현재 Docker 이미지는 AMD64 아키텍처 만 지원합니다. 이 제약 조건은 기본 이미지에서 비롯되지만 가까운 시일 내에 더 많은 아키텍처가 지원됩니다. Periplus를 컨테이너로 실행하는 두 가지 방법이 있습니다. DockerHub (권장)에서 공식 Docker 이미지를 다운로드하거나 이미지를 직접 빌드하십시오. 두 경우 모두 첫 번째 단계는 아직하지 않은 경우 Docker를 설치하는 것입니다. 그렇게하는 지침은 여기에서 찾을 수 있습니다.
docker image pull qdl123/periplus:latest 이미지를 다운로드하십시오.docker run -p 3000:3000 qdl123/periplus:latest git clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Periplusdocker build -t periplus-image .docker run -p 3000:3000 periplus-image .Periplus는 빌드 시스템에 cmake를 사용합니다. 그것은 모든 종속성이 홈브류를 통해 사전 컴파일 된 바이너리를 설치할 것으로 기대합니다. Homebrew는 Windows에있는 경우 MacOS, Ubuntu 및 WSL의 지원을받습니다. Periplus는 MacOS/ARM64 및 Ubuntu/AMD64에 구축되었습니다. 다른 모든 운영 체제 및 아키텍처 조합은 테스트되지 않았습니다. 소스에서 Periplus를 구축하려면 다음 단계를 따르십시오.
brew install faiss curl cpr rapidjson libomp catch2 cmakegit clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Peripluscmake -S . -B buildcmake --build build./build/periplus -p 3000 Periplus를 사용하는 모든 시스템은 벡터 데이터베이스, 데이터베이스 프록시, Periplus가 데이터베이스에서 데이터를로드 할 수있는 데이터베이스 프록시, Periplus 인스턴스 및 클라이언트 응용 프로그램의 4 가지 구성 요소로 구성됩니다.
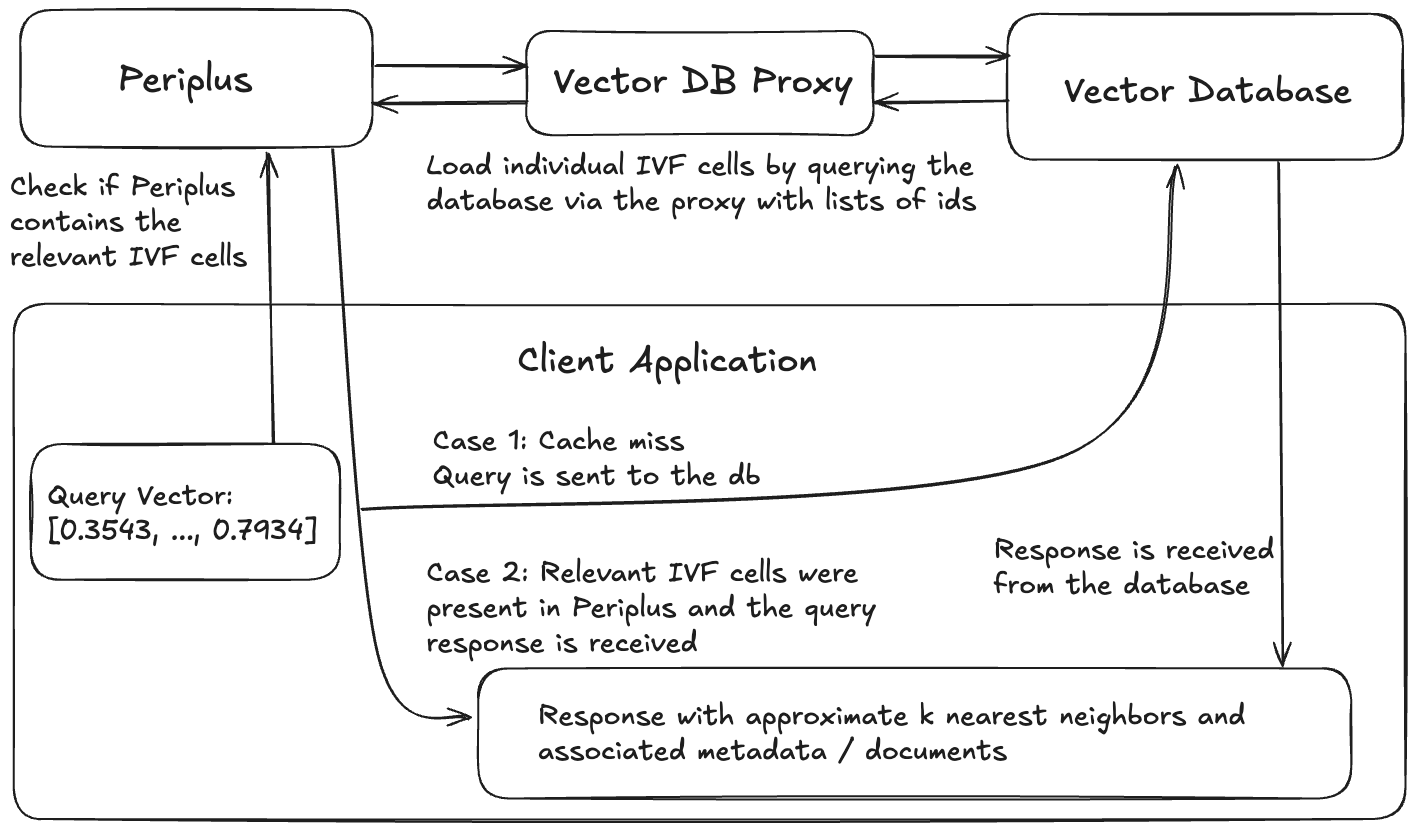
Periplus를 사용한 응용 프로그램의 예제.
고유 식별자 (사실상 모든)가 데이터를 찾을 수있는 벡터 데이터베이스가 작동합니다. Periplus는 실제로 큰 벡터 수집금 (Billion-scale)으로 작업 할 때 가장 유익한 것으로 설계되었으며, 여기서 인덱스가 RAM과 달리 파일 시스템에서 살아야하지만 요구 사항은 아니지만 가장 유익합니다.
벡터 데이터베이스 프록시의 목적은 Periplus가 벡터 데이터베이스와 상호 작용할 수있는 일관된 인터페이스를 제공하는 것입니다. 프록시는 다음 양식의 사후 요청을 수락하는 REST 인터페이스를 구현해야합니다.
URL : 이것은 유연하며 Periplus 클라이언트가 지정할 수 있습니다.
헤더 : "Content-Type": "application/json
몸:
{
"ids" : [ " id-1 " , " id-2 " , " id-3 " ]
}응답:
{
"results" : [
{
"id" : " String " ,
"embedding" : [ 0.1 , 0.2 , 0.3 ],
"document" : " String " ,
"metdata" : " String "
}
]
}이 엔드 포인트를보다 쉽게 구현하려면 FastApi를 사용하여 모든 것을 설정하는 Periplus-Proxy Python 패키지를 사용할 수 있습니다. 사용자가해야 할 일은 다음 기능을 구현하고 인수로 전달하는 것입니다.
async def fetch_ids(request: Query) -> QueryResult
이 작업을 수행하는 방법에 대한 자세한 내용은 Periplus-Proxy 패키지 readme.md를 확인할 수 있습니다.
위의 지침을 따라 Periplus 인스턴스를 시작하십시오.
Periplus 인스턴스와 상호 작용하려면 Periplus 클라이언트 라이브러리를 사용하십시오. 현재 Python 만 지원됩니다. 클라이언트 라이브러리에 대한 자세한 내용은 readme.md를 볼 수 있습니다.
from periplus_client import Periplus
# host, port
client = Periplus ( "localhost" , 13 )
# vector dimensionality, database proxy url, options: (nTotal)
await client . initialize ( d = d , db_url = url , options = { "nTotal" : 50000 })
training_data = [[ 0.43456 , ..., 0.38759 ], ...]
await client . train ( training_data )
ids = [ "0" , ..., "n" ]
embeddings = [[ 0.43456 , ..., 0.38759 ], ...]
await client . add ( ids = ids , embeddings = embeddings )
load_options = { "n_load" : 2 }
# query_vector, optional: options object
await client . load ([ embeddings [ 0 ]] load_options )
# k, query_vector
response = await client . search ( 5 , [ embeddings [ 0 ]])
print ( response )
'''
[ // Results for each of the n query vectors in xq
[ // K nearest neighbors to this corresponding index in the xq list
(
id="n",
embedding=[0.43456, ..., 0.38759],
document="",
metadata="{}"
),
...
],
...
]
'''
# query_vector
await client . evict ( embeddings [ 0 ])우리는 Periplus에 대한 기여를 환영합니다! 시작하는 방법을 배우려면 기여 가이드를 살펴보십시오.
이 프로젝트는 MIT 라이센스에 따라 라이센스가 부여됩니다. 자세한 내용은 라이센스 파일을 참조하십시오.


