Periplus
v0.1.0-alpha.1
Periplus حاليًا في ألفا وليس جاهزًا للإنتاج. يخضع المشروع إلى تطوير نشط ، ولا ينصح به بعد للاستخدام في أنظمة الإنتاج.
Periplus هو ذاكرة التخزين المؤقت لقاعدة بيانات المتجهات مفتوحة المصدر مبنية على مكتبة البحث عن ناقلات Meta FAISS. من الأفضل اعتبار المشروع "redis لقواعد بيانات المتجهات". تم تصميمه لتخزين مجموعة فرعية محدثة ديناميكيًا من مجموعة متجه كبيرة بالكامل في الذاكرة أثناء تقديم الاستعلامات دون التفاعل مع أي عقد أخرى في وقت الاستعلام. عندما يتلقى Periplus استعلامًا ، يقوم أولاً بتقييم ما إذا كان لديه الجزء ذي الصلة من الفهرس الداخلي. إذا كان الأمر كذلك ، فإنه يحل الاستعلام مع الاستجابة المناسبة. إذا لم يكن الأمر كذلك ، فإنه يعيد تفويت ذاكرة التخزين المؤقت ويترك أكثر جلبًا لجلب البيانات من قاعدة البيانات. Periplus غير مصمم للعمل في عزلة. بدلاً من ذلك ، يهدف إلى تشكيل طبقة تخزين مؤقت وحداسية ومرنة لقاعدة بيانات متجه منفصلة تشكل طبقة الثبات. والغرض من ذلك هو تمكين انخفاض الكمون والتحجيم الأفقي السهل لزيادة الإنتاجية. للحصول على وصف أكثر تفصيلاً للإلهام وراء Periplus وكيف يعمل ، يمكنك قراءة مدونة الإعلان: تقديم Periplus: نهج جديد لتخزين Database للتخزين المؤقت.
يستخدم Periplus فهرس ملف مقلوب (IVF) كأساس لإدارة ذاكرة التخزين المؤقت. فهرسة الملفات المقلوبة تقسيم مساحة المتجه إلى خلايا متجاورة محددة من قبل مجموعة من متجهات النقطه الوسطى حيث يتم تعريف كل خلية على أنها المنطقة التي تكون أقرب إلى النقط الوسطى من أي نقطية وسط أخرى. ثم يتم حل الاستعلامات عن طريق حساب المسافات أولاً من متجه الاستعلام إلى مجموعة الأوسطات الوسطى ثم البحث فقط عن الخلايا المحددة من قبل N_Probe (Search Hyperparameter) أقرب الوسطى. يستفيد Periplus من هذا من خلال الحفاظ على مجموعة فرعية من هذه الخلايا في الإقامة في أي وقت معين وحل فقط الاستعلامات ذات الصلة بتلك المجموعة الفرعية مع رفض تلك التي لا تفوت ذاكرة التخزين المؤقت. يحمل Periplus وطرد خلايا التلقيح الاصطناعي بأكملها في وقت واحد للحفاظ على سلامة الفهرس وضمان استدعاء مكافئ (على زيارات ذاكرة التخزين المؤقت) إلى مؤشر IVF قياسي. يتم تحميل خلايا التلقيح الاصطناعي عن طريق الاستعلام عن قاعدة بيانات المتجه عبر وكيل مع قائمة من معرفات المتجهات التي تحتفظ بها Periplus لتتبع المتجهات التي تشغل الخلايا. يمكن استدعاء هذه العمليات من قبل المستخدم باستخدام أوامر التحميل والبحث والإخلاء . للحصول على التفاصيل ، راجع قسم أوامر Periplus أدناه.
يمكن تشغيل Periplus كحاوية Docker أو يمكن بناؤها من Source وتشغيلها على أنها قابلة للتنفيذ. لا توجد ثنائيات رسمية متاحة حاليا. إن تشغيل Periplus كحاوية هو النهج الموصى به ، ولكن كلاهما خيارات قابلة للحياة.
حاليًا ، تدعم صورة Docker فقط بنيات AMD64. ينبع هذا القيد من الصورة الأساسية ، ولكن سيتم دعم المزيد من الهياكل في المستقبل القريب. هناك طريقتان لتشغيل Periplus كحاوية: قم بتنزيل صورة Docker الرسمية من DockerHub (الموصى بها) أو بناء الصورة بنفسك. الخطوة الأولى في كلتا الحالتين هي تثبيت Docker إذا لم تقم بالفعل. يمكن العثور على التعليمات للقيام بذلك هنا.
docker image pull qdl123/periplus:latest .docker run -p 3000:3000 qdl123/periplus:latest git clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Periplusdocker build -t periplus-image .docker run -p 3000:3000 periplus-image .يستخدم Periplus cmake لنظام البناء. وتتوقع أن يتم تثبيت جميع التبعيات ثنائيات مسبقة من خلال Homebrew. يتم دعم Homebrew بواسطة MacOS و Ubuntu و WSL إذا كنت على Windows. تم بناء Periplus على MacOS/ARM64 و Ubuntu/AMD64. جميع مجموعات نظام التشغيل والهندسة المعمارية الأخرى غير مختبرة. لبناء periplus من المصدر ، اتبع الخطوات التالية:
brew install faiss curl cpr rapidjson libomp catch2 cmakegit clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Peripluscmake -S . -B buildcmake --build build./build/periplus -p 3000 سيتألف أي نظام يستخدم Periplus من 4 مكونات: قاعدة بيانات المتجه ، وكيل قاعدة البيانات الذي يسمح لـ Periplus بتحميل البيانات من قاعدة البيانات ، ومثيل Periplus ، وتطبيق العميل.
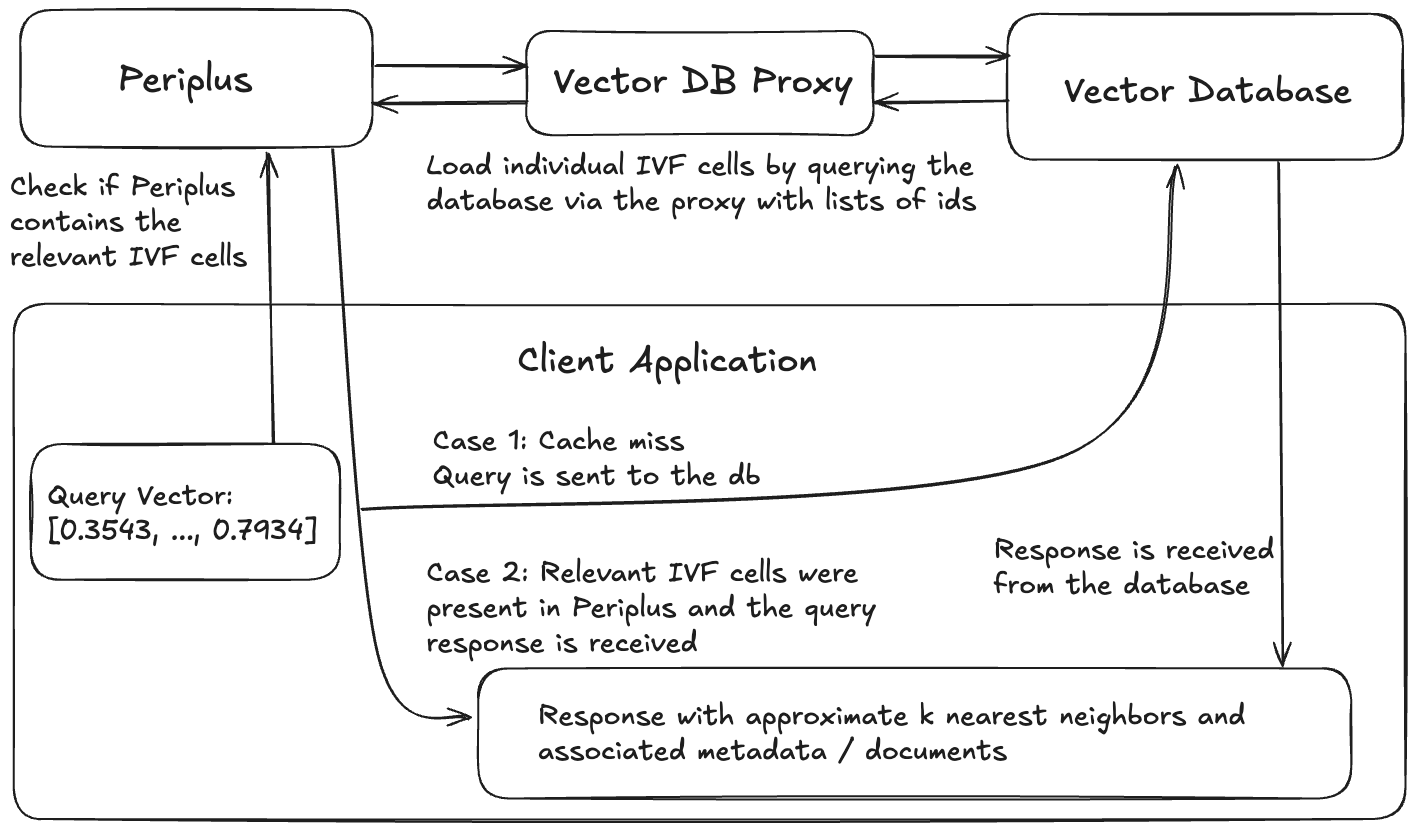
مثال بنية التطبيق باستخدام periplus.
أي قاعدة بيانات متجه تسمح بالبحث عن البيانات من خلال معرف فريد (جميعها فعليًا) ستعمل. تم تصميم Periplus ليكون أكثر فائدة عند العمل مع Collections vector كبيرة حقًا (على نطاق مليار) حيث يتعين على الفهرس أن يعيش على نظام الملفات بدلاً من ذاكرة الوصول العشوائي ، على الرغم من أن هذا ليس شرطًا.
الغرض من وكيل قاعدة بيانات Vector هو توفير واجهة متسقة لـ Periplus للتفاعل مع قاعدة بيانات المتجه من خلال. يجب على الوكيل تنفيذ واجهة REST التي تقبل طلبات النموذج التالي:
عنوان URL: هذا مرن ويمكن تحديده بواسطة عميل Periplus.
الرؤوس: "Content-Type": "application/json
جسم:
{
"ids" : [ " id-1 " , " id-2 " , " id-3 " ]
}إجابة:
{
"results" : [
{
"id" : " String " ,
"embedding" : [ 0.1 , 0.2 , 0.3 ],
"document" : " String " ,
"metdata" : " String "
}
]
}لجعل تنفيذ نقطة النهاية هذه أسهل ، يمكنك استخدام حزمة Periplus-proxy Python التي تستخدم Fastapi لإعداد كل شيء. كل ما يتعين على المستخدم القيام به هو تنفيذ الوظيفة التالية وتمريرها كوسيطة:
async def fetch_ids(request: Query) -> QueryResult
للحصول على تفاصيل حول كيفية القيام بذلك ، يمكنك التحقق من حزمة Periplus-proxy readme.md.
اتبع الإرشادات أعلاه لبدء مثيل Periplus.
للتفاعل مع مثيل Periplus الخاص بك ، استخدم مكتبة عميل Periplus. حاليا فقط Python مدعوم. للحصول على تفاصيل حول مكتبة العميل ، يمكنك عرضها readMe.md.
from periplus_client import Periplus
# host, port
client = Periplus ( "localhost" , 13 )
# vector dimensionality, database proxy url, options: (nTotal)
await client . initialize ( d = d , db_url = url , options = { "nTotal" : 50000 })
training_data = [[ 0.43456 , ..., 0.38759 ], ...]
await client . train ( training_data )
ids = [ "0" , ..., "n" ]
embeddings = [[ 0.43456 , ..., 0.38759 ], ...]
await client . add ( ids = ids , embeddings = embeddings )
load_options = { "n_load" : 2 }
# query_vector, optional: options object
await client . load ([ embeddings [ 0 ]] load_options )
# k, query_vector
response = await client . search ( 5 , [ embeddings [ 0 ]])
print ( response )
'''
[ // Results for each of the n query vectors in xq
[ // K nearest neighbors to this corresponding index in the xq list
(
id="n",
embedding=[0.43456, ..., 0.38759],
document="",
metadata="{}"
),
...
],
...
]
'''
# query_vector
await client . evict ( embeddings [ 0 ])نرحب بالمساهمات في Periplus! لمعرفة كيفية البدء ، ألق نظرة على دليل المساهمة.
تم ترخيص هذا المشروع بموجب ترخيص معهد ماساتشوستس للتكنولوجيا - راجع ملف الترخيص للحصول على التفاصيل.


