Periplus
v0.1.0-alpha.1
PERIPLUS se encuentra actualmente en alfa y no está listo para la producción. El proyecto está en desarrollo activo y aún no se recomienda su uso en los sistemas de producción.
PERIPLUS es una caché de base de datos vectorial en memoria de código abierto basado en la biblioteca de búsqueda de similitud vectorial de Meta FAISS. El proyecto se puede considerar mejor como "Redis para las bases de datos vectoriales". Está diseñado para almacenar un subconjunto actualizado dinámicamente de una gran colección de vectores en la memoria mientras sirve consultas sin interactuar con ningún otro nodo en el momento de la consulta. Cuando Periplus recibe una consulta, primero evalúa si tiene la parte relevante del índice en residencia. Si lo hace, resuelve la consulta con la respuesta apropiada. Si no es así, devuelve una memoria de caché y deja la consulta para obtener los datos de la base de datos. PERIPLUS no está diseñado para funcionar de forma aislada. En cambio, está destinado a formar una capa de almacenamiento de almacenamiento modular y flexible para una base de datos vectorial separada que forma la capa de persistencia. El propósito de esto es permitir una menor latencia y una escala horizontal fácil para aumentar el rendimiento. Para una descripción más detallada de la inspiración detrás de Periplus y cómo funciona, puede leer el blog de anuncios: Presentación de Periplus: un nuevo enfoque para el almacenamiento en caché de la base de datos vectorial.
PERIPLUS utiliza un índice de archivos invertido (FIV) como base para la administración de caché. Los índices de archivos invertidos dividen el espacio vectorial en celdas contiguas definidas por un conjunto de vectores centroides donde cada celda se define como la región que está más cerca de su centroide que a cualquier otro centroide. Las consultas se resuelven luego calculando primero las distancias del vector de consulta al conjunto de centroides y luego buscando solo las celdas definidas por los centroides más cercanos N_Probe (Search Hyperparameter). PERIPLUS aprovecha esto al mantener un subconjunto de estas celdas en residencia en un momento dado y solo resolviendo consultas que son relevantes para ese subconjunto mientras rechazan las que no son como caché fallan. PERIPLUS Cargue y desalienta las celdas completas de FIV a la vez para mantener la integridad del índice y garantizar el recuerdo equivalente (en los golpes de caché) a un índice de FIF estándar. Las celdas de FIV se cargan consultando la base de datos de vectores a través de un proxy con una lista de ID de vectores que PERIPLUS mantiene para rastrear qué vectores ocupan qué celdas. El usuario puede invocar estas operaciones utilizando comandos de carga , búsqueda y desalojo . Para obtener más detalles, consulte la sección de comandos de Periplus a continuación.
PERIPLUS se puede ejecutar como un contenedor Docker o se puede construir desde la fuente y ejecutar como ejecutable. No hay binarios oficiales disponibles actualmente. Ejecutar Periplus como contenedor es el enfoque recomendado, pero ambas son opciones viables.
Actualmente, la imagen de Docker solo admite arquitecturas AMD64. Esta restricción proviene de la imagen base, pero más arquitecturas serán compatibles con el futuro cercano. Hay 2 formas de ejecutar Periplus como contenedor: descargue la imagen oficial de Docker de Dockerhub (recomendado) o construya la imagen usted mismo. El primer paso en cualquier caso es instalar Docker si aún no lo ha hecho. Las instrucciones para hacerlo se pueden encontrar aquí.
docker image pull qdl123/periplus:latest .docker run -p 3000:3000 qdl123/periplus:latest git clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Periplusdocker build -t periplus-image .docker run -p 3000:3000 periplus-image .PERIPLUS utiliza CMake para su sistema de construcción. Espera que todas las dependencias tengan binarios precompilados instalados a través de Homebrew. Homebrew es compatible con MacOS, Ubuntu y WSL si está en Windows. PERIPLUS se ha construido en MacOS/ARM64 y Ubuntu/AMD64. Todas las demás combinaciones de sistema operativo y arquitectura no se han probado. Para construir Periplus a partir de la fuente, siga los siguientes pasos:
brew install faiss curl cpr rapidjson libomp catch2 cmakegit clone https://github.com/QDL123/Periplus.gitcd <path-to-periplus-repo>/Peripluscmake -S . -B buildcmake --build build./build/periplus -p 3000 Cualquier sistema que use Periplus consistirá en 4 componentes: la base de datos Vector, un proxy de la base de datos que permite que Periplus cargue datos de la base de datos, una instancia de Periplus y una aplicación cliente.
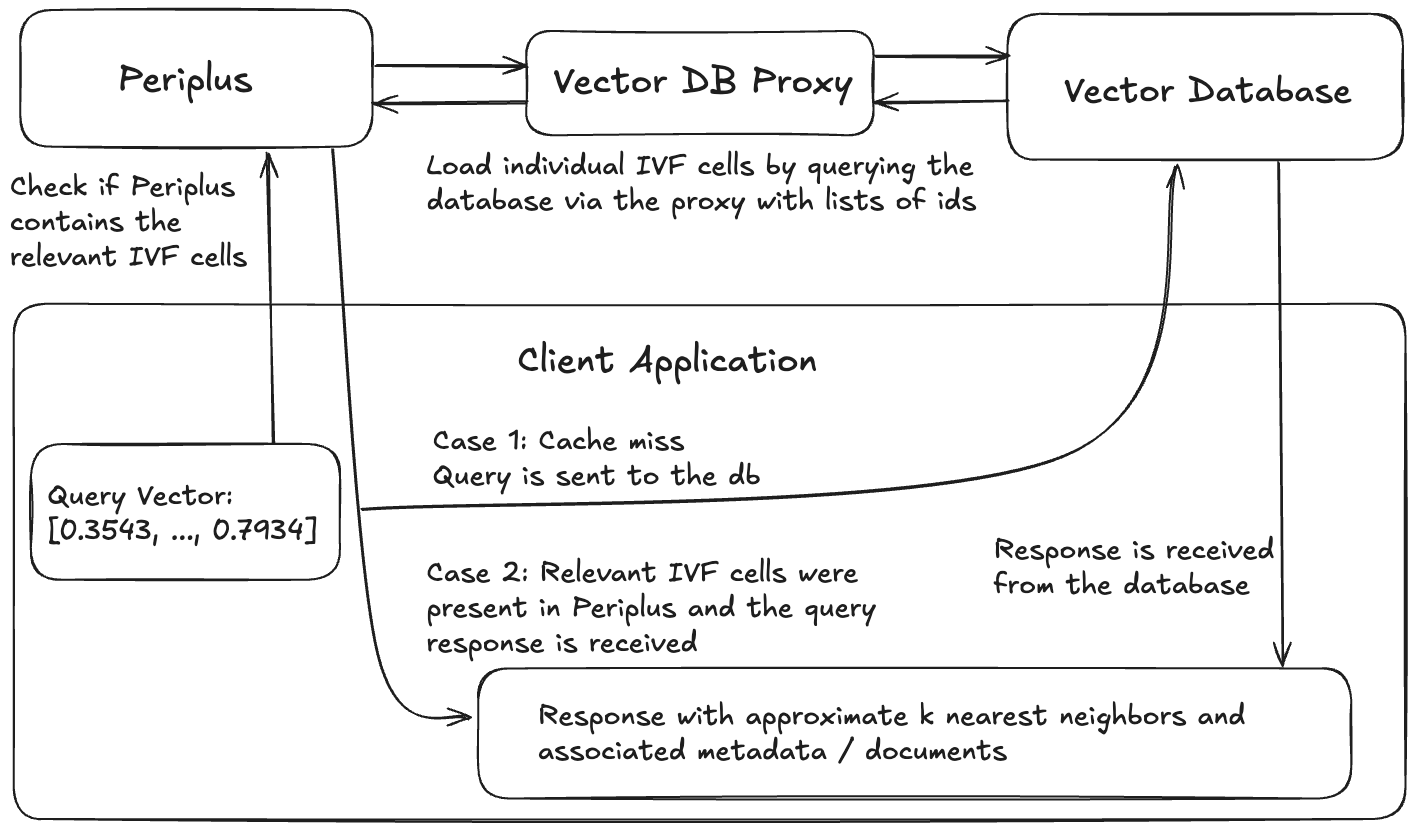
Ejemplo de arquitectura de una aplicación utilizando Periplus.
Cualquier base de datos vectorial que permita buscar datos de un identificador único (prácticamente todos) funcionará. PERIPLUS está diseñado para ser más beneficioso cuando se trabaja con Collectons vectoriales realmente grandes (mil millones de escala) donde el índice tiene que vivir en el sistema de archivos en lugar de RAM, aunque eso no es un requisito.
El propósito del proxy de la base de datos de Vector es proporcionar una interfaz consistente para que Periplus interactúe con la base de datos Vector. El proxy debe implementar una interfaz REST que acepte solicitudes de publicación del siguiente formulario:
URL: Esto es flexible y puede ser especificado por el cliente Periplus.
Encabezados: "Content-Type": "application/json
Cuerpo:
{
"ids" : [ " id-1 " , " id-2 " , " id-3 " ]
}Respuesta:
{
"results" : [
{
"id" : " String " ,
"embedding" : [ 0.1 , 0.2 , 0.3 ],
"document" : " String " ,
"metdata" : " String "
}
]
}Para facilitar la implementación de este punto final, puede usar el paquete Periplus-Proxy Python que usa FastAPI para configurar todo. Todo lo que el usuario tiene que hacer es implementar la siguiente función y pasarla como argumento:
async def fetch_ids(request: Query) -> QueryResult
Para obtener detalles sobre cómo hacer esto, puede consultar el paquete Periplus-Proxy ReadMe.md.
Siga las instrucciones anteriores para iniciar una instancia de Periplus.
Para interactuar con su instancia de Periplus, use la biblioteca del cliente Periplus. Actualmente, solo Python es compatible. Para obtener detalles en la biblioteca de clientes, puede ver su readme.md.
from periplus_client import Periplus
# host, port
client = Periplus ( "localhost" , 13 )
# vector dimensionality, database proxy url, options: (nTotal)
await client . initialize ( d = d , db_url = url , options = { "nTotal" : 50000 })
training_data = [[ 0.43456 , ..., 0.38759 ], ...]
await client . train ( training_data )
ids = [ "0" , ..., "n" ]
embeddings = [[ 0.43456 , ..., 0.38759 ], ...]
await client . add ( ids = ids , embeddings = embeddings )
load_options = { "n_load" : 2 }
# query_vector, optional: options object
await client . load ([ embeddings [ 0 ]] load_options )
# k, query_vector
response = await client . search ( 5 , [ embeddings [ 0 ]])
print ( response )
'''
[ // Results for each of the n query vectors in xq
[ // K nearest neighbors to this corresponding index in the xq list
(
id="n",
embedding=[0.43456, ..., 0.38759],
document="",
metadata="{}"
),
...
],
...
]
'''
# query_vector
await client . evict ( embeddings [ 0 ])¡Agradecemos las contribuciones a Periplus! Para aprender a comenzar, eche un vistazo a la guía de contribución.
Este proyecto tiene licencia bajo la licencia MIT; consulte el archivo de licencia para obtener más detalles.


